Azure Databricks 使用两个主要安全对象来存储和访问数据。
- 表控制对表格数据的访问。
- 卷控制对非表格数据的访问。
本文介绍这些数据库对象如何与 Azure Databricks 中的目录、架构、视图和其他数据库对象相关联。 本文还简要介绍了数据库对象在整个平台体系结构的上下文中如何工作。
Azure Databricks 中的数据库对象是什么?
数据库对象是有助于组织、访问和管理数据的实体。 Azure Databricks 使用三层层次结构来组织数据库对象:
目录:顶级容器,包含架构。 请参阅 Azure Databricks 中的目录是什么?。
架构或数据库:包含数据对象。 请参阅 Azure Databricks 中的架构是什么?。
可包含在架构中的数据对象:
- 卷:云对象存储中非表格数据的逻辑卷。 请参阅什么是 Unity Catalog 卷?。
- 表:按行和列组织的数据的集合。 请参阅 Azure Databricks 表。
- 视图:针对一个或多个表保存的查询。 请参阅什么是视图?。
- 函数:保存的逻辑返回标量值或行集。 请参阅 Unity Catalog 中的用户定义函数 (UDF)。
- 模型:使用 MLflow 打包的机器学习模型。 请参阅在 Unity Catalog 中管理模型生命周期。
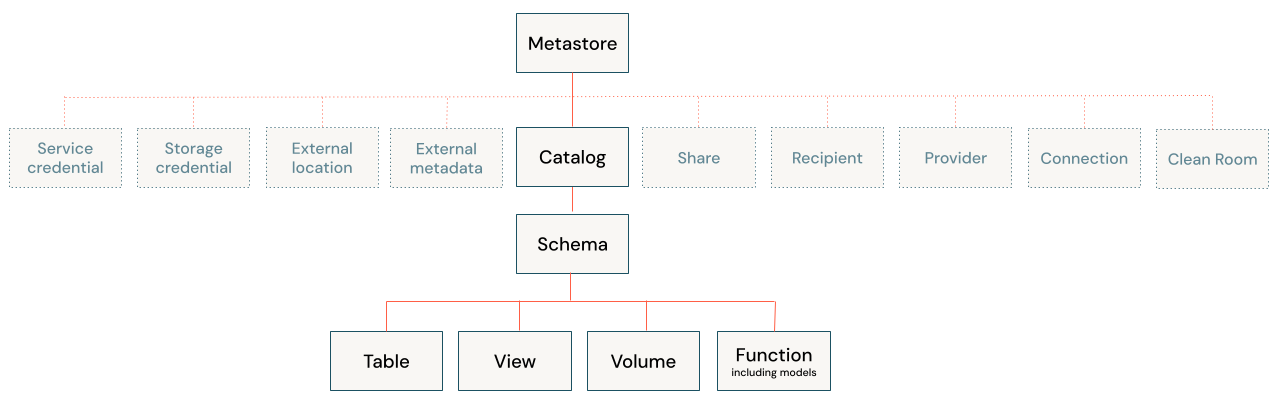
目录在帐户级别管理的元存储中注册。 只有管理员才能直接与元存储交互。 请参阅元存储。
Azure Databricks 提供用于处理数据的其他资产,所有这些资产都可以使用工作区级别的访问控制或 Unity Catalog(Databricks 数据治理解决方案)进行管理:
- 工作区级别的数据资产,例如笔记本、作业和查询。
- Unity Catalog 安全对象,如存储凭据和 Delta Sharing 共享,主要控制对存储或安全共享的访问。
有关详细信息,请参阅数据库对象与工作区安全数据资产和 Unity Catalog 安全凭据和基础结构。
使用 Unity Catalog 管理对数据库对象的访问
可以在层次结构中的任何级别(包括元存储本身)授予和撤销对数据库对象的访问权限。 除非撤销访问权限,否则对对象的访问会隐式授予该对象的所有子对象的相同访问权限。
可以使用典型的 ANSI SQL 命令授予和撤销对 Unity Catalog 中对象的访问权限。 还可以使用目录资源管理器对数据对象特权进行 UI 驱动的管理。
有关 Unity Catalog 中的安全对象的详细信息,请参阅 Unity Catalog 中的安全对象。
Unity Catalog 中的默认对象权限
根据为 Unity Catalog 创建和启用工作区的方式,用户可能对自动预配的目录拥有默认权限,包括 main 目录或工作区目录 ()。<workspace-name> 有关详细信息,请参阅默认用户权限。
如果手动为你的工作区启用了 Unity Catalog,则你的工作区在 default 目录中包括一个名为 main 的默认架构,该架构可供你的工作区中的所有用户访问。 如果自动为你的工作区启用了 Unity Catalog,并且该工作区包含 <workspace-name> 目录,则该包括一个名为 default 的架构,该架构可供你的工作区中的所有用户访问。
数据库对象与工作区安全数据资产
使用 Azure Databricks,可以管理多个数据工程、分析、ML 和 AI 资产以及数据库对象。 你不会在 Unity Catalog 中注册这些数据资产。 相反,这些资产在工作区级别进行管理,使用控制列表来管理权限。 这些数据资产包括以下内容:
- Notebooks
- 仪表板
- 作业
- Pipelines
- 工作区文件
- SQL 查询
- 实验
大多数数据资产包含与数据库对象交互的逻辑,用于查询数据、使用函数、注册模型或其他常见任务。 若要详细了解如何保护工作区数据资产,请参阅访问控制列表。
注意
对计算的访问由访问控制列表控制。 使用访问模式配置计算,并可以添加其他云权限,从而控制用户如何访问数据。 Databricks 建议使用计算策略并限制群集创建特权作为数据管理最佳做法。 请参阅访问模式。
Unity Catalog 安全凭据和基础结构
Unity Catalog 使用在元存储级别注册的安全对象管理对云对象存储、数据共享和查询联合的访问。 以下是这些非数据安全对象的简要说明。
将 Unity Catalog 连接到云对象存储
必须定义存储凭据和外部位置才能创建新的托管存储位置或注册外部表或外部卷。 这些安全对象在 Unity Catalog 中注册:
- 存储凭据:提供对云存储的访问权限的长期云凭据。
- 外部位置:对可使用配对存储凭据访问的云对象存储路径的引用。
请参阅 使用 Unity 目录连接到云对象存储。
增量共享
Azure Databricks 在 Unity Catalog 中注册以下 Delta Sharing 安全对象:
- 共享:表、卷和其他数据资产的只读集合。
- 提供方:共享数据的组织或实体。 在“Databricks 到 Databricks”共享模型中,提供方在接收方的 Unity Catalog 元存储中注册为由其元存储 ID 标识的唯一实体。
- 接收方:从提供方处接收共享的实体。 在“Databricks 到 Databricks”共享模型中,通过唯一的元存储 ID 为提供方标识接收方。
Lakehouse 联邦
Lakehouse Federation 允许创建外部目录来提供对驻留在其他系统(如 PostgreSQL、MySQL 和 Snowflake)中的数据的只读访问权限。 必须定义与外部系统的连接才能创建外部目录。
连接:Unity Catalog 安全对象指定用于在 Lakehouse Federation 方案中访问外部数据库系统的路径和凭据。
请参阅“什么是 Lakehouse Federation?”。
托管卷和表的托管存储位置
创建 Azure Databricks 表和卷时,可以选择将其设为托管还是外部。 Unity Catalog 管理对 Azure Databricks 中外部表和卷的访问,但不控制基础文件或完全管理这些文件的存储位置。 另一方面,托管表和卷由 Unity Catalog 完全托管,并存储在与包含架构关联的托管存储位置。 请参阅在 Unity Catalog 中指定托管存储位置。
Databricks 建议对大多数工作负载使用托管卷和托管表,因为它们简化了配置、优化和管理工作。
Unity Catalog 与旧版 Hive 元存储
Databricks 建议使用 Unity Catalog 来注册和管理所有数据库对象,但也为用于管理架构、表、视图和函数的 Hive 元存储提供旧版支持。
如果要与使用 Hive 元存储注册的数据库对象进行交互,请参阅旧版 Hive 元存储中的数据库对象。