Delta 表流式读取和写入
Delta Lake 通过 readStream 和 writeStream 与 Spark 结构化流式处理深度集成。 Delta Lake 克服了通常与流式处理系统和文件相关的许多限制,包括:
- 合并低延迟引入生成的小文件。
- 保持对多个流(或并发批处理作业)执行“仅一次”处理。
- 使用文件作为流源时,可以有效地发现哪些文件是新文件。
有关 Delta Lake 的流静态联接的信息,请参阅流静态联接。
用作源的 Delta 表
结构化流式处理以增量方式读取 Delta 表。 当流式处理查询针对 Delta 表处于活动状态时,新表版本提交到源表时,新记录会以幂等方式处理。
下面的代码示例演示如何使用表名或文件路径配置流式读取。
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
重要
如果在开始针对表进行流式读取后 Delta 表的架构发生更改,查询将会失败。 对于大多数架构更改,可以重启流以解决架构不匹配问题并继续处理。
在 Databricks Runtime 12.2 LTS 及更低版本中,无法从启用了列映射且经历了非累加架构演变(例如重命名或删除列)的 Delta 表进行流式处理。 有关详情,请参阅使用列映射和架构更改进行流式处理。
限制输入速率
以下选项可用于控制微批处理:
maxFilesPerTrigger:每个微批处理中要考虑的新文件数。 默认值为 1000。maxBytesPerTrigger:每个微批处理中处理的数据量。 此选项设置一个“柔性最大值”,这意味着批处理大约处理此数量的数据,并且可能会超过此限制,以便在最小输入单元大于此限制的情况下,继续处理流式查询。 默认情况下,未设置此项。
如果将 maxBytesPerTrigger 与 maxFilesPerTrigger 结合使用,则微批处理将处理数据,直到达到 maxFilesPerTrigger 或 maxBytesPerTrigger 限制。
注意
如果由于 logRetentionDuration 配置和流式处理查询尝试处理这些版本而清理源表事务,默认情况下查询无法避免数据丢失。 可以将选项 failOnDataLoss 设置为 false,忽略丢失的数据并继续处理。
流式传输 Delta Lake 变更数据捕获 (CDC) 提要
Delta Lake 变更数据馈送记录对 Delta 表的更改,包括更新和删除。 启用后,可以从变更数据馈送进行流式传输并编写逻辑来处理针对下游表的插入、更新和删除操作。 尽管变更数据馈送数据输出与其描述的 Delta 表略有不同,但这提供了一种解决方案,用于将增量更改传播到奖牌体系结构中的下游表。
重要
在 Databricks Runtime 12.2 LTS 及更低版本中,无法从启用了列映射且经历了非累加架构演变(例如重命名或删除列)的 Delta 表的变更数据馈送进行流式处理。 请参阅使用列映射和架构更改进行流式处理。
忽略更新和删除
结构化流式处理不处理非追加的输入,并且会在对用作源的表进行了任何修改时引发异常。 可以通过两种主要策略处理无法自动向下游传播的更改:
- 可以删除输出和检查点,并从头开始重启流。
- 可以设置以下两个选项之一:
ignoreDeletes:忽略在分区边界删除数据的事务。skipChangeCommits:忽略删除或修改现有记录的事务。skipChangeCommits包括ignoreDeletes。
注意
在 Databricks Runtime 12.2 LTS 及更高版本中,skipChangeCommits 弃用了之前的设置 ignoreChanges。 在 Databricks Runtime 11.3 LTS 及更低版本中,ignoreChanges 是唯一受支持的选项。
ignoreChanges 的语义与 skipChangeCommits 有很大不同。 启用 ignoreChanges 后,源表中重写的数据文件会在执行 UPDATE、MERGE INTO、DELETE(在分区内)或 OVERWRITE 等数据更改操作后重新发出。 未更改的行通常与新行一起发出,因此下游使用者必须能够处理重复项。 删除不会传播到下游。 ignoreChanges 包括 ignoreDeletes。
skipChangeCommits 完全忽略文件更改操作。 将完全忽略源表中因执行 UPDATE、MERGE INTO、DELETE、OVERWRITE 等数据更改操作而重写的数据文件。 若要反映上游源表中的更改,必须实现单独的逻辑来传播这些更改。
配置了 ignoreChanges 的工作负载继续使用已知语义进行操作,但 Databricks 建议对所有新工作负载使用 skipChangeCommits。 使用 ignoreChanges 将工作负载迁移到 skipChangeCommits 需要重构逻辑。
示例
例如,假设你有一个表 user_events,其中包含 date、user_email 和 action 列,并按 date 对该表进行了分区。 从 user_events 表向外进行流式处理,由于 GDPR 的原因,需要从中删除数据。
在分区边界(即 WHERE 位于分区列上)执行删除操作时,文件已经按值进行了分段,因此删除操作直接从元数据中删除这些文件。 删除整个数据分区时,可以使用以下语法:
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
如果删除多个分区中的数据(在此示例中,基于 user_email 进行筛选),请使用以下语法:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
如果使用 UPDATE 语句更新 user_email,则包含相关 user_email 的文件将被重写。 使用 skipChangeCommits 忽略更改的数据文件。
指定初始位置
可以使用以下选项来指定 Delta Lake 流式处理源的起点,而无需处理整个表。
startingVersion:要从其开始的 Delta Lake 版本。 Databricks 建议为大多数工作负载省略此选项。 如果未设置,流将从最新的可用版本开始,包括当时表的完整快照。如果指定,流将读取从指定版本(包含)开始对 Delta 表的所有更改。 如果指定的版本不再可用,则流无法启动。 可以从 DESCRIBE HISTORY 命令输出的
version列中获取提交版本。若仅返回最新更改,请指定
latest。startingTimestamp:要从其开始的时间戳。 在该时间戳(含)或之后提交的所有表更改都由流式读取器读取。 如果提供的时间戳位于所有表提交之前,则流式读取按最早的可用时间戳开始。 下列其中一项:- 时间戳字符串。 例如
"2019-01-01T00:00:00.000Z"。 - 日期字符串。 例如
"2019-01-01"。
- 时间戳字符串。 例如
不能同时设置两个选项。 这两个选项仅在启动新的流式处理查询时才生效。 如果流式处理查询已启动且已在其检查点中记录进度,这些选项将被忽略。
重要
虽然可以从指定的版本或时间戳启动流式处理源,但流式处理源的架构始终是 Delta 表的最新架构。 必须确保在指定版本或时间戳之后,不对 Delta 表进行任何不兼容的架构更改。 否则,使用错误的架构读取数据时,流式处理源可能会返回不正确的结果。
示例
例如,假设你有一个表 user_events。 如果要从版本 5 开始读取更改,请使用:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
如果想了解自 2018 年 10 月 18 日以来进行的更改,可使用:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
在不删除数据的情况下处理初始快照
注意
此功能在 Databricks Runtime 11.3 LTS 及更高版本上可用。 此功能目前以公共预览版提供。
将 Delta 表用作流源时,查询首先处理表中存在的所有数据。 此版本的 Delta 表称为初始快照。 默认情况下,Delta 表的数据文件将基于上次修改的文件进行处理。 但是,上次修改时间不一定表示记录事件时间顺序。
在具有定义的水印的监控状态流式处理查询中,通过修改时间处理文件可能会导致按错误顺序处理记录。 这可能导致记录被水印作为延迟事件删除。
可以通过启用以下选项来避免数据删除问题:
- withEventTimeOrder:是否应使用事件时间顺序处理初始快照。
启用事件时间顺序后,初始快照数据的事件时间范围划分为时间桶。 每个微批处理通过筛选时间范围内的数据来处理桶。 maxFilesPerTrigger 和 maxBytesPerTrigger 配置选项仍适用于控制微批处理大小,但由于处理的性质,只能大概控制。
下图显示了此过程:
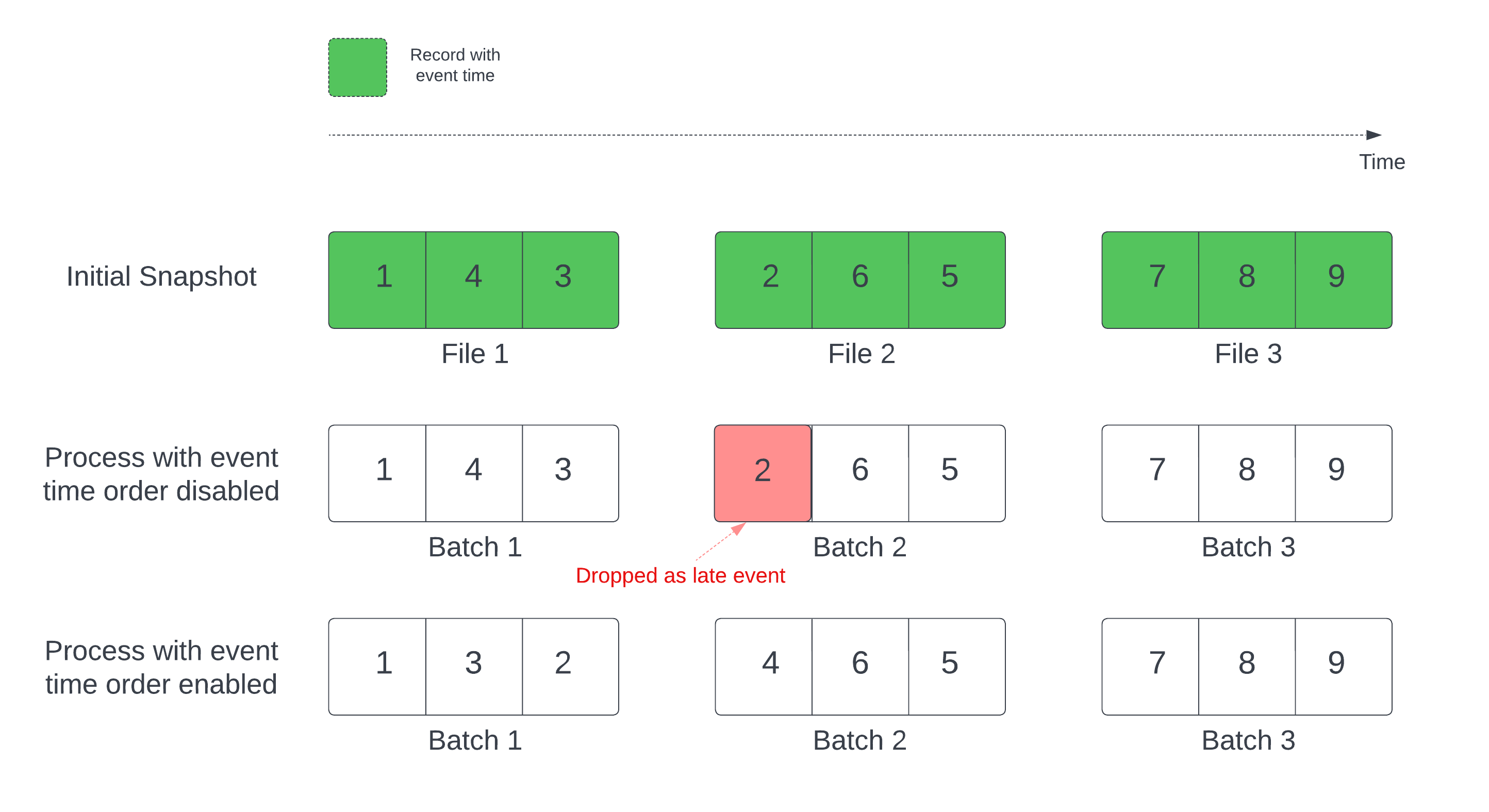
有关此功能的重要信息:
- 仅当按默认顺序处理监控状态的流式处理查询的初始 Delta 快照时,才会发生数据删除问题。
- 当初始快照仍在进行处理时,一旦流查询开始,便无法更改
withEventTimeOrder。 要在withEventTimeOrder已更改的情况下重启,需要删除检查点。 - 如果运行启用了 withEventTimeOrder 的流查询,则在完成初始快照处理之前,无法将其降级到不支持此功能的 DBR 版本。 如果需要降级,可以等待初始快照完成,或删除检查点并重启查询。
- 以下特殊情况不支持此功能:
- 事件时间列是生成的列,Delta 源和水印之间有非投影转换。
- 流查询中存在具有多个 Delta 源的水印。
- 启用事件时间顺序后,Delta 初始快照处理的性能可能会降低。
- 每个微批处理扫描初始快照,以便筛选相应事件时间范围内的数据。 为了更快地执行筛选操作,建议使用 Delta 源列作为事件时间,以便可以跳过数据(请查看跳过 Delta Lake 的数据了解何时适用)。 此外,沿事件时间列进行表分区的表可以进一步加快处理速度。 可以检查 Spark UI 以查看为特定微批处理扫描的差异文件数。
示例
假设你有一个包含 event_time 列的 user_events 表。 流式处理查询是一个聚合查询。 如果要确保在初始快照处理期间不会删除任何数据,可以使用:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
注意
还可以在群集上使用 Spark 配置启用此功能,该功能将适用于所有流式处理查询:spark.databricks.delta.withEventTimeOrder.enabled true
用作接收器的 Delta 表
你也可以使用结构化流式处理将数据写入 Delta 表。 即使有针对表并行运行的其他流或批处理查询,Delta Lake 也可通过事务日志确保“仅一次”处理。
注意
Delta Lake VACUUM 函数会删除所有不由 Delta Lake 管理的文件,但会跳过所有以 _ 开头的目录。 可以使用 <table-name>/_checkpoints 等目录结构将检查点与 Delta 表的其他数据和元数据一起安全地存储。
指标
可以将流式处理查询过程中待处理字节数和文件数作为 numBytesOutstanding 和 numFilesOutstanding 指标。 其他指标包括:
numNewListedFiles:为计算此批的积压工作 (backlog) 而列出的 Delta Lake 文件数。backlogEndOffset:用于计算积压工作 (backlog) 的表版本。
如果在笔记本中运行流,可在流式处理查询进度仪表板中的“原始数据”选项卡下查看这些指标:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
追加模式
默认情况下,流在追加模式下运行,这会将新记录添加到表中。
流式传输到表时,请使用 toTable 方法,如以下示例所示:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
完整模式
你还可以使用结构化流式处理将整个表替换为每个批。 一个示例用例是使用聚合来计算摘要:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
上述示例持续更新包含按客户划分的事件总数的表。
对于延迟要求较为宽松的应用程序,可以使用一次性触发器来节省计算资源。 使用这些触发器按给定计划更新汇总聚合表,从而仅处理自上次更新以来收到的新数据。
使用 foreachBatch 从流式处理查询中更新插入
可以使用 merge 和 foreachBatch 的组合,将复杂的 upsert 操作从流式处理查询写入 Delta 表。 请参阅使用 foreachBatch 将内容写入到任意数据接收器。
此模式有许多应用程序,包括:
- 在更新模式下写入流式处理聚合:这比完整模式更有效。
- 将数据库更改流写入 Delta 表:用于写入更改数据的合并查询可在
foreachBatch中用于连续将更改流应用到 Delta 表。 - 使用重复数据删除将数据流写入 Delta 表:用于重复数据删除的仅插入的合并查询可以在
foreachBatch中用来通过自动重复数据删除将数据(包含重复项)连续写入到 Delta 表中。
注意
- 请确保
foreachBatch中的merge语句是幂等的,因为重启流式处理查询可以将操作多次应用于同一批数据。 - 在
foreachBatch中使用merge时,流式处理查询的输入数据速率(通过StreamingQueryProgress报告并在笔记本计算机速率图中可见)可以报告为源处生成数据的实际速率的倍数。 这是因为merge多次读取输入数据,导致输入指标倍增。 如果这是一个瓶颈,则可以在merge之前缓存批处理 DataFrame,然后在merge之后取消缓存。
以下示例演示如何在 foreachBatch 中使用 SQL 来完成此任务:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
还可以选择使用 Delta Lake API 来执行流式 upsert,如以下示例所示:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
foreachBatch 中的幂等表写入
注意
Databricks 建议为每个要更新的接收器配置单独的流式写入。 使用 foreachBatch 写入多个表可序列化写入,从而减少并行操作并增加整体延迟。
Delta 表支持以下 DataFrameWriter 选项对 foreachBatch 幂等内的多个表进行写入:
txnAppId:可以在每次 DataFrame 写入时传递的唯一字符串。 例如,可以使用 StreamingQuery ID 作为txnAppId。txnVersion:充当事务版本的单调递增数字。
Delta Lake 使用 txnAppId 和 txnVersion 的组合来识别重复写入并忽略它们。
如果批量写入因失败而中断,则重新运行该批次将使用相同的应用程序和批次 ID,以帮助运行时正确识别重复写入并忽略它们。 应用程序 ID (txnAppId) 可以是任何用户生成的唯一字符串,不必与流 ID 相关。 请参阅使用 foreachBatch 将内容写入到任意数据接收器。
警告
如果删除流式处理检查点并使用新检查点重新启动查询,则必须提供其他 txnAppId。 新检查点以 0 的批 ID 开头。 Delta Lake 使用批 ID 和 txnAppId 作为唯一键,并跳过具有已看过值的批处理。
以下代码示例演示了此模式:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}