Azure Databricks 具有多个实用工具和 API,用于与以下位置中的文件进行交互:
- Unity Catalog 卷
- 工作区文件
- 云对象存储
- DBFS 装载和 DBFS 根
- 附加到群集驱动程序节点的临时存储
本文提供了以下工具在这些位置与文件交互的示例:
- Apache Spark
- Spark SQL 和 Databricks SQL
- Databricks 文件系统实用工具(
dbutils.fs或%fs) - Databricks 命令行界面 (CLI)
- Databricks REST API
- Bash shell 命令 (
%sh) - 使用
%pip安装笔记本范围的库 - 熊猫
- OSS Python 文件管理和处理实用工具
重要
Databricks 中的一些操作(尤其是使用 Java 或 Scala 库的操作)作为 JVM 进程运行,例如:
- 在 Spark 配置中使用
--jars指定 JAR 文件依赖项 - 在 Scala 笔记本中调用
cat或java.io.File - 自定义数据源,例如
spark.read.format("com.mycompany.datasource") - 使用 Java 的
FileInputStream或Paths.get()加载文件的库
这些操作不支持使用标准文件路径读取或写入 Unity Catalog 卷或工作区文件,例如 /Volumes/my-catalog/my-schema/my-volume/my-file.csv。 如果需要从 JAR 依赖项或基于 JVM 的库访问卷文件或工作区文件,请先使用 Python 或 %sh 命令将文件复制到计算本地存储,例如 %sh mv.。 请勿使用依赖 JVM 的 %fs 和 dbutils.fs。 若要访问本地复制的文件,请使用特定于语言的命令,如 Python shutil 或使用 %sh 命令。 如果在群集启动时文件需要存在,请使用初始化脚本首先移动文件。 请参阅什么是 init 脚本?。
是否需要提供用于访问数据的 URI 方案?
Azure Databricks 中的数据访问路径遵循以下标准之一:
URI 样式路径包括 URI 方案。 对于 Databricks 本机数据访问解决方案,对于大多数用例,URI 方案是可选的。 直接访问云对象存储中的数据时,必须为存储类型提供正确的 URI 方案。
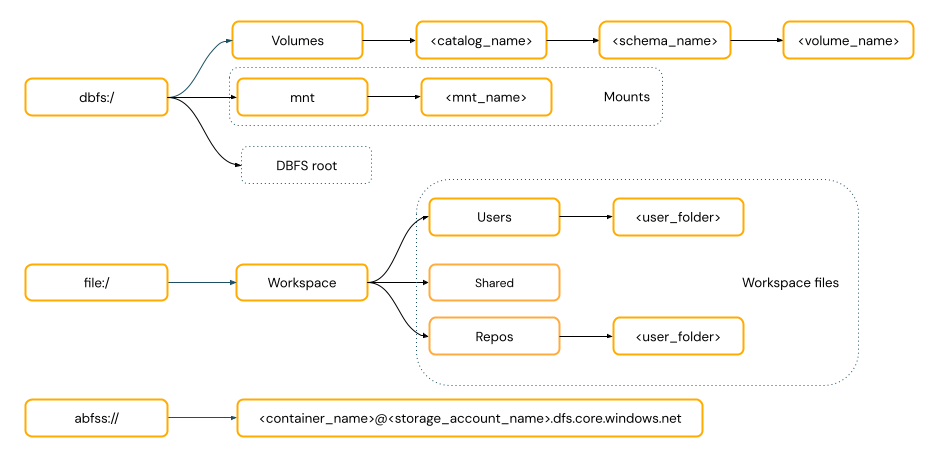
POSIX 样式的路径 提供相对于驱动程序根(
/)的数据访问。 POSIX 样式路径从不需要方案。 可以使用 Unity Catalog 卷或 DBFS 装载来提供对云对象存储中数据的 POSIX 样式访问。 许多 ML 框架和其他 OSS Python 模块都需要 FUSE,并且只能使用 POSIX 样式的路径。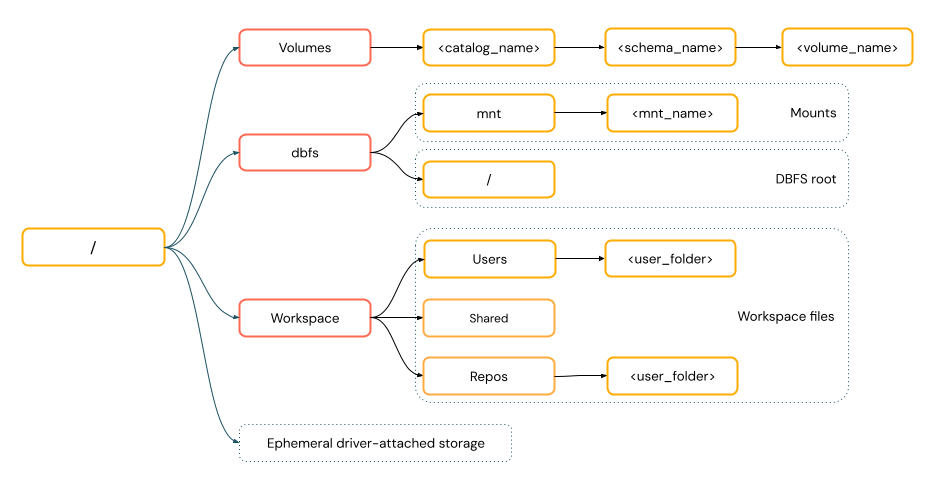
注释
需要 FUSE 数据访问的文件操作无法使用 URI 直接访问云对象存储。 Databricks 建议使用 Unity 目录卷为 FUSE 配置对这些位置的访问。
在配置了专用访问模式(以前称为单用户访问模式)和 Databricks Runtime 14.3 及更高版本的计算环境中,Scala 支持 Unity 目录存储卷和工作区文件的 FUSE功能,但不包括那些由 Scala 生成的子进程,例如 Scala 命令 "cat /Volumes/path/to/file".!!。
使用 Unity Catalog 卷中的文件
Databricks 建议使用 Unity 目录卷来配置对存储在云对象存储中的非表格数据文件的访问。 有关在卷中管理文件的完整文档,包括详细说明和最佳做法,请参阅 使用 Unity 目录卷中的文件。
以下示例展示了使用不同工具和接口的常见操作:
| 工具 | 示例: |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Databricks 文件系统实用工具 | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks 命令行界面 (CLI) | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash shell 命令 | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| 库安装 | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| 开源软件 Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
关于处理卷中的文件的限制及其解决方案的信息,请参阅 卷处理文件的限制。
使用工作区文件
Databricks 工作区文件 是工作区中的文件,存储在 工作区存储帐户中。 可以使用工作区文件来存储和访问笔记本、源代码文件、数据文件和其他工作区资产等文件。
| 工具 | 示例: |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Databricks 文件系统实用工具 | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks 命令行界面 (CLI) | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash shell 命令 | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| 库安装 | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| 开源软件 Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
注释
使用 Databricks Utilities、Apache Spark 或 SQL 时,需要 file:/ 架构。
在禁用 DBFS 根和装载的工作区中,还可以使用 dbfs:/Workspace Databricks 实用工具访问工作区文件。 这需要 Databricks Runtime 13.3 LTS 或更高版本。 请参阅 禁用对现有 Azure Databricks 工作区中 DBFS 根目录和挂载点的访问。
有关使用工作区文件的限制,请参阅 限制。
删除的工作区文件在何处?
删除工作区文件会将其发送到回收站。 可以使用 UI 从回收站恢复或永久删除文件。
请参阅删除对象。
处理云对象存储中的文件
Databricks 建议使用 Unity 目录卷配置对云对象存储中的文件的安全访问。 如果选择使用 URI 直接访问云对象存储中的数据,则必须配置权限。 请参阅托管卷和外部卷。
以下示例使用 URI 访问云对象存储中的数据:
| 工具 | 示例: |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path/file.json").show() |
| Spark SQL 和 Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path';
|
| Databricks 文件系统实用工具 |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path/
|
| Databricks 命令行界面 (CLI) | 不支持 |
| Databricks REST API | 不支持 |
| Bash shell 命令 | 不支持 |
| 库安装 | %pip install abfss://container-name@storage-account-name.dfs.core.chinacloudapi.cn/path/to/library.whl |
| Pandas | 不支持 |
| 开源软件 Python | 不支持 |
使用 DBFS 装载和 DBFS 根目录中的文件
重要
DBFS 根和 DBFS 挂载点均已弃用,Databricks 不推荐使用这些功能。 无需访问这些功能即可预配新帐户。 Databricks 建议改用 Unity 目录 卷、 外部位置或 工作区文件 。
| 工具 | 示例: |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL 和 Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Databricks 文件系统实用工具 | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Databricks 命令行界面 (CLI) | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash shell 命令 | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| 库安装 | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| 开源软件 Python | os.listdir('/dbfs/mnt/path/to/directory') |
注释
使用 Databricks CLI 时,需要 dbfs:/ 架构。
在连接到驱动节点的临时存储中处理文件
附加到驱动程序节点的临时存储是支持基于 POSIX 的内置路径访问的块存储。 当群集终止或重启时,此位置中存储的任何数据都消失。
| 工具 | 示例: |
|---|---|
| Apache Spark | 不支持 |
| Spark SQL 和 Databricks SQL | 不支持 |
| Databricks 文件系统实用工具 | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Databricks 命令行界面 (CLI) | 不支持 |
| Databricks REST API | 不支持 |
| Bash shell 命令 | %sh curl http://<address>/text.zip > /tmp/text.zip |
| 库安装 | 不支持 |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| 开源软件 Python | os.listdir('/path/to/directory') |
注释
使用 Databricks Utilities 时,需要 file:/ 架构。
将数据从临时存储移到卷
你可能想要使用 Apache Spark 访问下载或保存到临时存储的数据。 由于临时存储附加到驱动程序,Spark 是分布式处理引擎,因此并非所有操作都可以直接访问此处的数据。 假设必须将数据从驱动程序文件系统移动到 Unity 目录卷。 在这种情况下,可以使用 magic 命令 或 Databricks 实用工具复制文件,如以下示例所示:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>