了解如何使用 Lakeflow Spark 声明式管道 (SDP) 为数据编排和自动加载器创建和部署包含变更数据捕获 (CDC) 的 ETL(提取、转换和加载)管道。 ETL 管道实现从源系统读取数据、根据要求转换数据(如数据质量检查和记录重复数据)以及将数据写入目标系统(如数据仓库或数据湖)的步骤。
在本教程中,你将使用 MySQL 数据库中的数据表customers来执行以下操作:
- 使用 Debezium 或其他工具从事务数据库中提取更改,并将其保存到云对象存储(ADLS)。 在本教程中,将跳过设置外部 CDC 系统并生成假数据以简化本教程。
- 使用自动加载程序以增量方式从云对象存储加载消息,并将原始消息
customers_cdc存储在表中。 自动加载程序推断架构并处理架构演变。 - 创建表
customers_cdc_clean以使用预期检查数据质量。 例如,id不应该null,因为它用于执行 upsert 操作。 - 对已清理的 CDC 数据执行
AUTO CDC ... INTO,以插入更新至最终customers表中。 - 显示管道如何创建类型 2 渐变维度(SCD2)表来跟踪所有更改。
目标是近乎实时地引入原始数据,并为分析师团队构建一个表,同时确保数据质量。
本教程使用 Medallion Lakehouse 体系结构,在该体系结构中,它通过铜层引入原始数据,使用银层清理和验证数据,并使用黄金层应用维度建模和聚合。 有关详细信息,请参阅什么是奖牌湖屋体系结构?
实现的流如下所示:
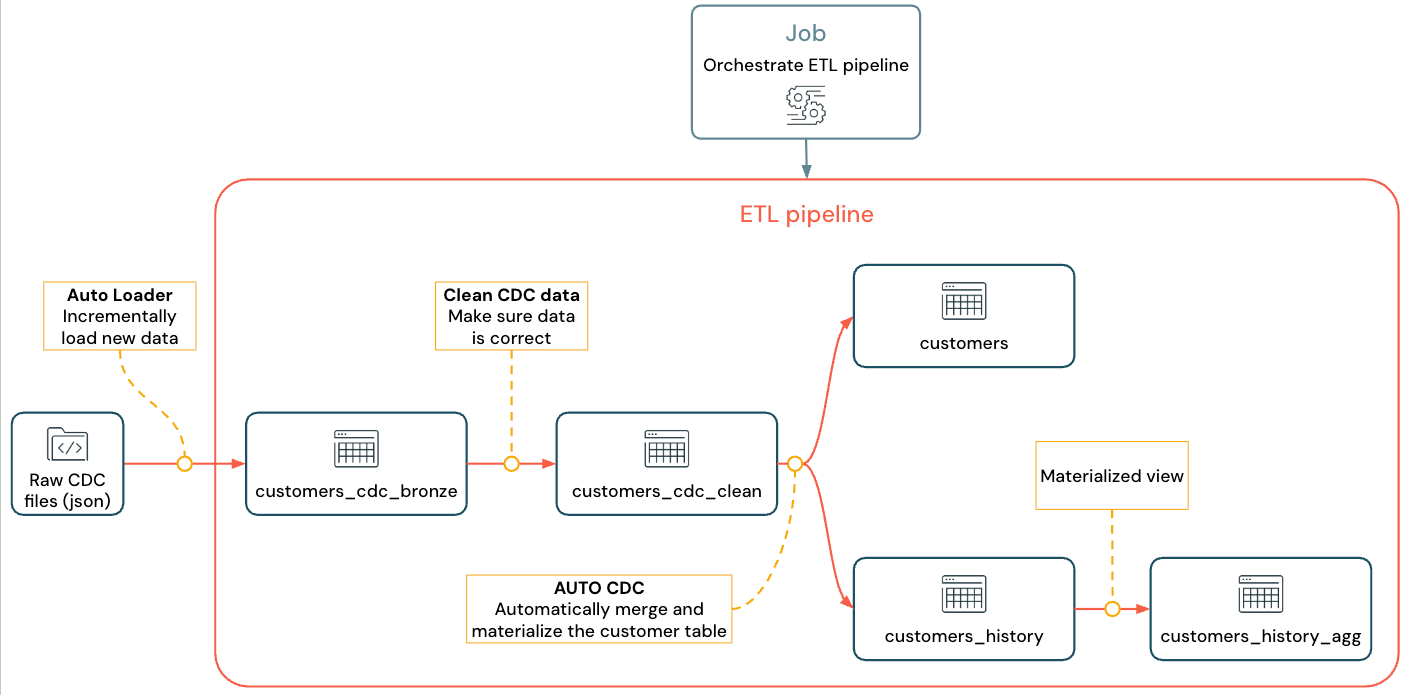
有关管道、自动加载器和 CDC 的详细信息,请参阅 Lakeflow Spark 声明性管道、 什么是自动加载程序?以及 更改数据捕获和快照
要求
若要完成此教程,必须满足以下要求:
- 登录到 Azure Databricks 工作区。
- 为工作区启用 Unity 目录 。
- 在工作区中提供 无服务器计算 (在具有 Unity 目录的工作区中默认启用)。 无服务器 Lakeflow Spark 声明性管道并非在所有工作区区域都可用。 有关可用的区域,请参阅具有有限区域可用性的功能。 如果无服务器架构不可用,则这些步骤应适用于工作区的默认计算环境。
- 有权 创建计算资源 或 访问计算资源。
- 有权 在目录中创建新架构。 所需的权限是
USE CATALOG和CREATE SCHEMA。 - 有权在现有架构中创建新卷。 所需的权限是
USE SCHEMA和CREATE VOLUME。
在 ETL 管道中更改数据捕获
变更数据捕获(CDC)是捕获对事务数据库(例如 MySQL 或 PostgreSQL)或数据仓库所做记录的更改的过程。 CDC 捕获数据删除、追加和更新等操作,通常以流的形式处理,以便在外部系统中重新生成表。 CDC 支持增量加载,同时无需批量加载更新。
注释
若要简化本教程,请跳过设置外部 CDC 系统。 假设它在云对象存储(ADLS)中以 JSON 文件的形式运行和保存 CDC 数据。 本教程使用 Faker 库生成教程使用的数据。
捕获 CDC
各种 CDC 工具可以使用。 主要的开源解决方案之一是 Debezium,但简化数据源的其他实现存在,例如 Fivetran、Qlik Replicate、StreamSets、Talend、Oracle GoldenGate 和 AWS DMS。
在本教程中,你将使用来自外部系统(如 Debezium 或 DMS)的 CDC 数据。 Debezium 捕获每个已更改的数据行。 它通常向 Kafka 主题发送数据更改的历史记录,或将它们保存为文件。
必须从 customers 表(JSON 格式)引入 CDC 信息,检查它是否正确,然后在 Lakehouse 中具体化客户表。
Debezium 的 CDC 输入
对于每次更改,你都会收到一条 JSON 消息,其中包含正在更新的行的所有字段(id、、firstname、lastnameemailaddress、 。 该消息还包括其他元数据:
-
operation:一个操作码,通常(DELETE、APPEND、UPDATE)。 -
operation_date:每个操作记录的日期和时间戳。
Debezium 等工具可以生成更高级的输出,例如更改前的行值,但本教程会省略它们,以便于简单。
步骤 1:创建管道
创建新的 ETL 管道以查询 CDC 数据源并在工作区中生成表。
在工作区中,单击
 在边栏中新建,然后选择“ETL 管道”。 这将打开包含默认管道名称的管道编辑器,如下所示
在边栏中新建,然后选择“ETL 管道”。 这将打开包含默认管道名称的管道编辑器,如下所示 New Pipeline <date> <time>。选择名称并输入描述性名称,例如
Pipelines with CDC tutorial。在名称右侧,点击目录和架构,选择你具有写入权限的项作为默认设置。
如果未在代码中指定目录或架构,则默认使用此目录和架构。 代码可以通过指定完整路径写入任何目录或架构。 本教程使用此处指定的默认值。
(可选)在为你创建的
my_transformation源文件中,从语言下拉列表中选择 Python 或 SQL 以设置文件的语言。单击
 使用示例代码。
使用示例代码。
Lakeflow 管道编辑器打开时,您的管道中会包含示例文件。 将在后续步骤中添加自己的转换文件。 接下来,设置在本教程中导入的示例数据。
步骤 2:创建在本教程中导入的示例数据
如果要从现有源导入自己的数据,则不需要执行此步骤。 对于本教程,请生成假数据作为本教程的示例。 创建笔记本以运行 Python 数据生成脚本。 此代码只需运行一次即可生成示例数据,因此在管道的 explorations 文件夹中创建它,该文件夹不会作为管道更新的一部分运行。
注释
此代码使用 Faker 生成示例 CDC 数据。 Faker 可用于自动安装,因此本教程使用 %pip install faker。 还可以为笔记本设置对 faker 的依赖项。 请参阅 向笔记本添加依赖项。
在 Lakeflow 管道编辑器中,在编辑器左侧的资产浏览器侧栏中,单击
添加,然后选择探索。为它指定 一个名称,例如
Setup data,选择 Python。 可以保留默认目标文件夹,即新explorations文件夹。单击 “创建” 。 这会在新文件夹中创建笔记本。
在第一个单元格中输入以下代码。 必须将
<my_catalog>和<my_schema>的定义更改为匹配您在上一过程中选择的默认目录和架构。%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")若要生成本教程中使用的数据集,请键入 Shift + Enter 以运行代码:
可选。 若要预览本教程中使用的数据,请在下一个单元格中输入以下代码并运行代码。 更新目录和架构以匹配上一个代码的路径。
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
这会生成可在本教程的其余部分使用的大型数据集(包含虚假 CDC 数据)。 在下一步中,使用自动加载程序引入数据。
步骤 3:使用自动加载程序以增量方式引入数据
下一步是将原始数据从伪造的云存储引入到青铜层。
出于多种原因,这很有挑战性,因为必须:
- 大规模运行,可能引入数百万个小文件。
- 推断架构和 JSON 类型。
- 使用不正确的 JSON 架构处理错误的记录。
- 负责架构演变(例如,客户表中的新列)。
自动加载程序简化了此引入,包括架构推理和架构演变,同时扩展到数百万个传入文件。 自动加载程序可通过 cloudFiles 在 Python 中使用,通过 SELECT * FROM STREAM read_files(...) 在 SQL 中使用,并支持多种格式(JSON、CSV、Apache Avro 等):
将表定义为流式处理表可确保您仅处理新的传入数据。 如果不将其定义为流式处理表,它将扫描并引入所有可用数据。 有关详细信息,请参阅 流式处理表 。
若要使用 Auto Loader 引入即将到来的 CDC 数据,请将以下代码复制并粘贴到通过管道创建的代码文件(称为
my_transformation.py或my_transformation.sql)中。 可以根据创建管道时选择的语言使用 Python 或 SQL。 请务必将<catalog>和<schema>替换为您为管道设置的默认值。Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )单击“
 运行文件 或 运行管道 以启动连接的管道的更新。 在管道中只有一个源文件时,这些在功能上是等效的。
运行文件 或 运行管道 以启动连接的管道的更新。 在管道中只有一个源文件时,这些在功能上是等效的。
更新完成后,编辑器将被更新,以包含关于您的管道的信息。
- 位于代码右侧边栏中的管道图(也称为定向无环图(DAG))显示一个表:
customers_cdc_bronze。 - 更新摘要显示在管道资产浏览器顶部。
- 生成的表的详细信息显示在底部窗格中,可以通过选择表来浏览该表中的数据。
这是从云存储导入的原始铜层数据。 在下一步中,清理数据以生成银层表。
步骤 4:清理和设定期望以跟踪数据质量
定义铜层后,通过添加控制数据质量的预期来创建银层。 检查以下条件:
- ID 不得为
null. - CDC操作类型必须有效。
- 自动加载程序必须正确读取 JSON。
删除不符合这些条件的行。
有关详细信息,请参阅 通过管道预期管理数据质量。
在管道资产浏览器侧边栏中,单击
添加,然后单击 转换。输入 Name(例如,
customers_silver),并为源代码文件选择语言(Python或 SQL)。 根据您的语言选择,会附加.py或.sql扩展。 可以在管道中混合和匹配语言,以便为此步骤选择任一语言。若要使用清理表创建银层并施加约束,请将以下代码复制并粘贴到新文件中(根据文件的语言选择 Python 或 SQL)。
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;单击“
运行文件 或 运行管道 以启动连接的管道的更新。由于现在有两个源文件,因此它们不执行相同的作,但在这种情况下,输出是相同的。
- 运行管道 运行整个管道,包括步骤 3 中的代码。 如果输入数据正在更新,系统将从该源中拉取任何更改到铜层。 这不会从数据设置步骤中运行代码,因为该代码位于浏览文件夹中,而不是管道源的一部分。
- 运行文件 仅运行当前源文件。 在这种情况下,即使不用更新输入数据,也可从缓存的青铜表中生成银数据。 创建或编辑管道代码时,只需运行此文件即可加快迭代速度。
更新完成后,可以看到管道图现在显示两个表(银层取决于青铜层),底部面板显示这两个表的详细信息。 管道资产浏览器顶部现在会显示多个运行的时间,但仅显示最近一次运行的详细信息。
接下来,创建 customers 表的最终的黄金层版本。
步骤 5:使用 AUTO CDC 流具体化客户表
到目前为止,表格在每个步骤中仅传递了 CDC 数据。 现在,创建表 customers,以同时包含最新视图和原始表的副本,而不是包含生成该表的 CDC 操作列表。
手动实现这一点并不容易。 必须考虑重复数据删除等事项才能保留最新的行。
但是,Lakeflow Spark 声明性管道使用 AUTO CDC 操作解决了这些难题。
在管道资产浏览器侧边栏中,单击
,然后单击 添加 和 转换。输入 名称 并选择新源代码文件的语言(Python 或 SQL)。 可以再次选择此步骤的任一语言,但使用以下正确的代码。
若要使用
AUTO CDCLakeflow Spark 声明性管道处理 CDC 数据,请将以下代码复制并粘贴到新文件中。Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;单击“
运行文件 以启动连接的管道的更新。
当更新完成后,您可以看到您的流水线图显示 3 个表,从青铜到白银再到黄金。
步骤 6:使用渐变维度类型 2 跟踪更新历史记录(SCD2)
通常需要创建一张表来跟踪由APPEND、UPDATE和DELETE引起的所有更改。
- 历史记录:您希望保留关于表格所有更改的记录。
- 可跟踪性:你希望查看发生了哪些操作。
将 SCD2 与 Lakeflow SDP 配合使用
Delta 支持更改数据流(CDF),并且可以在 SQL 和 Python 中 table_change 查询表的修改。 但是,CDF 的主要用例是在管道中捕获更改,而不是从头开始创建表更改的完整视图。
如果有无序事件,则处理起来会变得特别复杂。 如果必须按时间戳对更改进行排序并接收过去发生的修改,则必须在 SCD 表中追加新条目并更新以前的条目。
Lakeflow SDP 消除了这种复杂性。 可以创建一个单独的表,其中包含从时间开始的所有修改,Lakeflow SDP 会自动维护该表。 此表支持数据布局优化,例如基于_sequence_by的动态聚类分析,并自动处理无序记录。 请参阅对表使用 liquid 聚类分析。
要创建 SCD2 表,请在 SQL 中使用选项STORED AS SCD TYPE 2 或在 Python 中使用选项stored_as_scd_type="2"。
注释
您还可以使用选项限制功能所跟踪的列:TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
在管道资产浏览器侧边栏中,单击
,然后单击 添加 和 转换。输入 名称 并选择新源代码文件的语言(Python 或 SQL)。
将以下代码复制并粘贴到新文件中。
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;单击“
运行文件 以启动连接的管道的更新。
更新完成后,管道图表包括新的 customers_history 表,并依赖于银层表,底部面板显示所有四个表的详细信息。
步骤 7:创建具体化视图,用于跟踪已更改其信息最多的人员
该表 customers_history 包含用户对其信息所做的所有历史更改。 在黄金层中创建一个简单的具体化视图,以跟踪谁更改了最多的信息。 这可用于真实场景中的欺诈检测分析或用户建议。 此外,对 SCD2 应用更改已删除重复项,因此可以直接对每个用户 ID 的行进行计数。
在管道资产浏览器侧边栏中,单击
,然后单击 添加 和 转换。输入 名称 并选择新源代码文件的语言(Python 或 SQL)。
将以下代码复制并粘贴到新的源文件中。
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count_distinct("address").alias("address_count"), count_distinct("email").alias("email_count"), count_distinct("firstname").alias("firstname_count"), count_distinct("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count(distinct address) as address_count, count(distinct email) AS email_count, count(distinct firstname) AS firstname_count, count(distinct lastname) AS lastname_count FROM customers_history GROUP BY id单击“
运行文件 以启动连接的管道的更新。
更新完成后,管道图中会有一个新的表格,该表依赖于customers_history表,并且可以在底部面板中查看。 管道现已完成。 可以通过执行完整的 运行管道来测试它。 剩下的唯一步骤是计划管道定期更新。
步骤 8:创建用于运行 ETL 管道的作业
接下来,创建一个工作流,以使用 Databricks 作业自动执行管道中的数据引入、处理和分析步骤。
- 在编辑器顶部,选择“ 计划 ”按钮。
- 如果出现“ 计划 ”对话框,请选择“ 添加计划”。
- 这将打开 “新建计划 ”对话框,可在其中创建作业以按计划运行管道。
- (可选)为作业命名。
- 默认情况下,计划设置为每天运行一次。 可以接受此默认值,也可以设置自己的计划。 选择 “高级 ”可让你选择设置作业将运行的特定时间。 选择 “更多”选项 可在作业运行时创建通知。
- 选择 “创建 ”以应用更改并创建作业。
现在,该作业将每日运行,以确保管道始终保持最新状态。 可以再次选择 “计划” 以查看计划列表。 可以从该对话框管理管道的计划,包括添加、编辑或删除计划。
单击计划(或作业)的名称会将你转到 “作业和管道 ”列表中的作业页面。 在此处可以查看有关作业运行的详细信息,包括运行历史记录,或使用“ 立即运行” 按钮立即运行作业。
有关作业运行的详细信息,请参阅 Lakeflow 作业的监视和可观测性 。