确保时间点正确性会生成一个训练数据集,该数据集反映每条标签观测记录时的特征值。 这对于防止数据泄露非常重要,当你使用在记录标签时不可用的特征值进行模型训练时,就会发生数据泄露。 这种类型的错误很难检测,并且会对模型的性能产生负面影响。
时序特征表包括一个时间戳键列,该列确保训练数据集中的每一行代表截至该行的时间戳的最新已知特征值。 只要特征值会不断变化(例如,在使用时序数据、基于事件的数据或时间聚合数据时),就应该使用时序特征表。
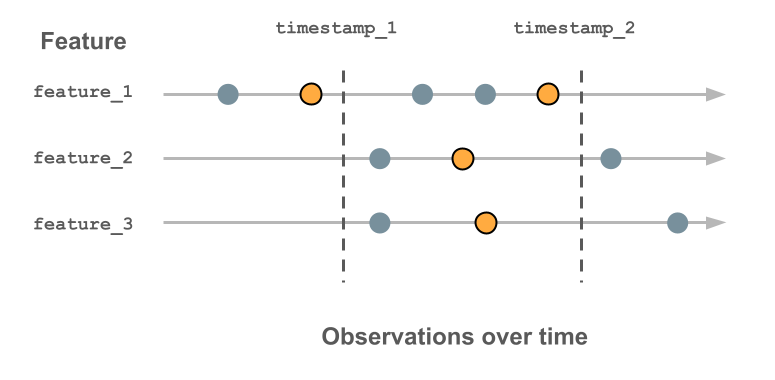
下图显示了 timestamp 键的使用方式。 每个 timestamp 记录的特征值是该 timestamp 之前的最新值,以橙色圆圈表示。 如果未记录任何值,则特征值为 null。 有关更多详细信息,请参阅时序特征表的工作原理。
注意
- 使用 Databricks Runtime 13.3 LTS 及更高版本时,Unity Catalog 中具有主键和时间戳键的任何 Delta 表都可以用作时序特征表。
- 为了提高时间点查找的性能,Databricks 建议对时序表进行液体聚类分析(
databricks-feature-engineering0.6.0 及更高)。 请参阅对表使用液体聚类和数据跳过。 - 时间点查找功能有时称为“时间旅行”。 Databricks 特征存储中的时间点功能与 Delta Lake 时间旅行无关。
时序特征表的工作原理
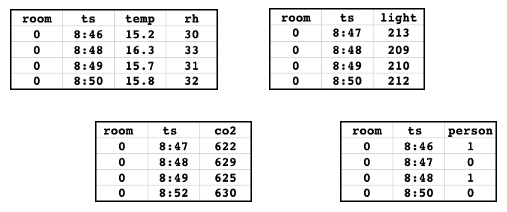
假设你有以下特征表。 此数据摘自示例笔记本。
这些表包含房间内温度、相对湿度、环境光和二氧化碳的传感器测量数据。 地面实况表指示房间内是否有人。 每个表包含一个主键(“room”)和一个时间戳键(“ts”)。 为简单起见,仅显示了主键(“0”)的单个值的数据。
下图演示了如何使用时间戳键来确保训练数据集中的时间点正确性。 特征值是使用 AS OF 联接根据主键(图中未显示)和时间戳键匹配的。 AS OF 联接确保在训练集中使用在时间戳时间提供的最新特征值。
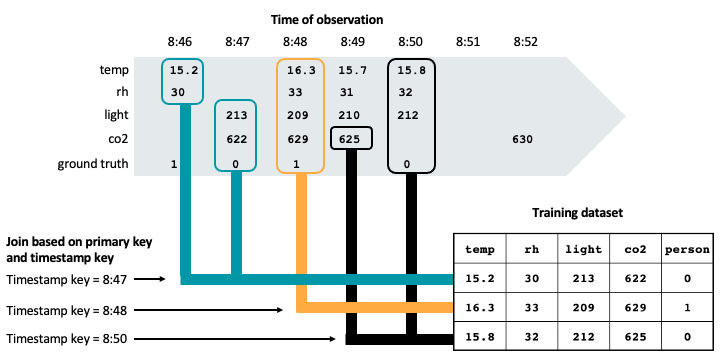
如图所示,训练数据集包括该时间戳之前每个传感器在地面实况上观测的最新特征值。
如果在不考虑时间戳键的情况下创建训练数据集,可能会有一行包含这些特征值和观测的地面实况:
| temp | rh | 光 | co2 | 地面实况 |
|---|---|---|---|---|
| 15.8 | 32 | 212 | 630 | 0 |
但是,这并不是对训练有效的观测数据,因为 630 的 co2 读数是在 8:50 测得的,而此时间戳在地面实况观测时间戳 (8:52) 之后。 将来的数据会“泄漏”到训练集,这会损害模型的性能。
要求
- 对于 Unity Catalog 中的特征工程:Unity Catalog 客户端中的特征工程(任何版本)。
- 对于工作区特征存储(旧版):特征存储客户端 v0.3.7 及更高版本。
如何指定与时间相关的键
若要使用时间点功能,必须使用 timeseries_columns 参数(适用于 Unity Catalog 中的特征工程)或 timestamp_keys 参数(适用于工作区特征存储)指定与时间相关的键。 这指示应该通过匹配不晚于 timestamps_keys 列值的特定主键的最新值来联接特征表行,而不是基于精确时间匹配进行联接。
如果不使用 timeseries_columns 或 timestamp_keys,并且仅将时序列指定为主键列,则功能存储不会在联接期间将时间点逻辑应用于时序列。 它只匹配具有精确时间匹配项的行,而不匹配时间戳之前的所有行。
在 Unity Catalog 中创建时序功能表
在 Unity 目录中,具有 TIMESERIES 主键的任何表都是时序功能表。 若要创建时序功能表,请参阅 在 Unity 目录中创建功能表。 以下示例演示不同类型的时序表。
将时序表发布到在线商店
在使用包含时间戳数据的功能表时,需要根据您的联机服务需求来决定是将时间戳列指定为 timeseries_column,还是将其作为常规列处理。
用时序指定标记 的 时间戳列
timeseries_column通常用在需要为训练数据集获取实时正确性,并希望在联机应用程序中按特定时间戳查找最新特征值的情况下。 时序特征表必须有一个时间戳键,并且不能包含任何分区列。 时间戳键列必须为 TimestampType 或 DateType。
Databricks 建议不要在时序特征表中包含两个以上的主键列,以确保高性能的写入和查找。
FeatureEngineeringClient API
fe = FeatureEngineeringClient()
# Create a time series table for point-in-time joins
fe.create_table(
name="catalog.schema.user_behavior_features",
primary_keys=["user_id", "event_timestamp"],
timeseries_columns="event_timestamp", # Enables point-in-time logic
df=features_df # DataFrame must contain primary keys and time series columns
)
SQL API
-- Create table with time series constraint for point-in-time joins
CREATE TABLE catalog.schema.user_behavior_features (
user_id STRING NOT NULL,
event_timestamp TIMESTAMP NOT NULL, -- part of primary key and designated as TIMESERIES
purchase_amount DOUBLE,
page_views_last_hour INT,
CONSTRAINT pk_user_behavior PRIMARY KEY (user_id, event_timestamp TIMESERIES)
) USING DELTA
TBLPROPERTIES (
'delta.enableChangeDataFeed' = 'true'
);
重要
如果特征表具有DATE或TIMESTAMP列作为主键,但没有使用timeseries_columns将其声明为时间序列列,则不能将该表用于create_feature_spec()、create_training_set()或publish_table()。 这些 API 要求所有 DATE 列和 TIMESTAMP 主键列都声明为时间序列列。
如果你的用例需要日期或时间戳值作为纯查找键(完全匹配语义,没有时间点逻辑),请将列类型改为 STRING 。
更新时序功能表
将特征写入时序特征表时,数据帧必须为特征表的所有特征提供值,这与常规特征表不同。 此约束减少了时序特征表中不同时间戳的特征值的稀疏性。
Unity Catalog 中的特征工程
fe = FeatureEngineeringClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fe.write_table(
"ml.ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
工作区特征存储客户端 v0.13.4 及更高版本
fs = FeatureStoreClient()
# daily_users_batch_df DataFrame contains the following columns:
# - user_id
# - ts
# - purchases_30d
# - is_free_trial_active
fs.write_table(
"ads_team.user_features",
daily_users_batch_df,
mode="merge"
)
支持流式写入时序特征表。
使用时序特征表创建训练集
若要对时序特征表中的特征值执行时间点查找,必须在特征的 timestamp_lookup_key 中指定一个指示数据帧列名称的 FeatureLookup,该列包含查找时序特征时所依据的时间戳。 Databricks 特征存储检索在数据帧的 timestamp_lookup_key 列中指定的时间戳之前的、其主键(不包括时间戳键)与数据帧的 lookup_key 列中的值匹配的最新特征值,如果不存在此类特征值,则检索 null。
Unity Catalog 中的特征工程
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ml.ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fe.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
提示
为了在启用 Photon 时提高查找性能,请将 use_spark_native_join=True 传递给 FeatureEngineeringClient.create_training_set。 这需要 databricks-feature-engineering 0.6.0 或更高版本。
工作区特征存储
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts"
),
FeatureLookup(
table_name="ads_team.ad_features",
feature_names=["sports_relevance", "food_relevance"],
lookup_key="ad_id",
)
]
# raw_clickstream DataFrame contains the following columns:
# - u_id
# - ad_id
# - ad_impression_ts
training_set = fs.create_training_set(
df=raw_clickstream,
feature_lookups=feature_lookups,
exclude_columns=["u_id", "ad_id", "ad_impression_ts"],
label="did_click",
)
training_df = training_set.load_df()
对时序特征表执行的任何 FeatureLookup 必须是时间点查找,因此它必须指定要在 DataFrame 中使用的 timestamp_lookup_key 列。 时间点查找不会跳过包含时序特征表中存储的 null 特征值的行。
为历史特征值设置时间限制
使用特征存储客户端 v0.13.0 或更高版本,或者 Unity Catalog 客户端中的任何特征工程版本,可以从训练集中排除时间戳较旧的特征值。 若要执行此操作,请使用 lookback_window 中的 FeatureLookup 参数。
lookback_window 的数据类型必须为 datetime.timedelta,默认值为 None(使用所有特征值,而不考虑年龄)。
例如,以下代码排除超过 7 天的任何功能值:
Unity Catalog 中的特征工程
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ml.ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
工作区特征存储
from datetime import timedelta
feature_lookups = [
FeatureLookup(
table_name="ads_team.user_features",
feature_names=["purchases_30d", "is_free_trial_active"],
lookup_key="u_id",
timestamp_lookup_key="ad_impression_ts",
lookback_window=timedelta(days=7)
)
]
使用上述 create_training_set 调用 FeatureLookup 时,它会自动执行时间点联接,并排除早于 7 天的功能值。
回溯窗口在训练和批量推理期间应用。 在联机推理期间,始终使用最新的功能值,而不考虑回溯窗口。
使用时序特征表为模型评分
当你使用时序特征表中的特征为训练的模型评分时,Databricks 特征存储将使用在训练期间与模型一起打包的元数据通过时间点查找来检索适当的特征。 提供给 FeatureEngineeringClient.score_batch(对于 Unity Catalog 中的特征工程)或 FeatureStoreClient.score_batch(对于工作区特征存储)的 DataFrame 必须包含一个时间戳列,其名称和 DataType 必须与提供给 timestamp_lookup_key 或 FeatureLookup 的 FeatureEngineeringClient.create_training_set 的 FeatureStoreClient.create_training_set 相同。
提示
为了在启用 Photon 时提高查找性能,请将 use_spark_native_join=True 传递给 FeatureEngineeringClient.score_batch。 这需要 databricks-feature-engineering 0.6.0 或更高版本。
将时序特征发布到联机存储
可以使用 FeatureEngineeringClient.publish_table(适用于 Unity Catalog 中的特征工程)或 FeatureStoreClient.publish_table (适用于工作区特征存储)将时序特征表发布到在线商店。 Databricks 特征存储将特征表中每个主键的最新特征值的快照发布到联机存储。 联机存储支持主键查找,但不支持时间点查找。
笔记本示例:时序特征表
这些示例笔记本演示了对时序特征表的时间点查找。
在启用了 Unity Catalog 的工作区中使用此笔记本。
时序特征表示例笔记本 (Unity Catalog)
以下笔记本旨在用于未启用 Unity Catalog 的工作区。 它使用工作区特征存储。