注意
本文档介绍工作区特征存储。 Databricks 建议使用 Unity Catalog 中的特征工程。 工作区特征存储将在未来弃用。
有关在 Unity 目录中使用功能表的信息,请参阅 Unity 目录中的功能表。
本页介绍如何在工作区特征存储中创建和使用特征表。
注意
如果工作区已启用 Unity Catalog,则由 Unity Catalog 管理的任何具有主键的表都将自动成为可用于模型训练和推理的特征表。 所有 Unity Catalog 功能(例如安全性、数据血缘、标记和跨工作区访问)都自动应用于特征表。 有关在启用了 Unity 目录的工作区中使用功能表的信息,请参阅 Unity 目录中的功能表。
要了解跟踪特征谱系和新鲜度的信息,请参阅探索特征和谱系(旧版)。
注意
数据库和特征表名称只能包含字母数字字符和下划线 (_)。
为特征表创建数据库
在创建任何特征表之前,必须创建一个数据库用于存储特征表。
%sql CREATE DATABASE IF NOT EXISTS <database-name>
特征表是作为Delta 表来存储的。 使用 create_table(特征存储客户端 v0.3.6 及更高版本)或 create_feature_table(v0.3.5 及更低版本)创建特征表时,必须指定数据库名称。 例如,此参数在数据库 customer_features 中创建名为 recommender_system 的增量表。
name='recommender_system.customer_features'
将特征表发布到联机存储时,默认的表和数据库名称是创建该表时指定的名称;可以使用 publish_table 方法指定其他名称。
Databricks 功能存储 UI 会显示联机存储中表和数据库的名称,以及其他元数据。
在 Databricks 特征存储中创建特征表
注意
还可以将现有的 Delta 表注册为特征表。 请参阅将现有的 Delta 表注册为特征表。
创建特征表的基本步骤为:
编写 Python 函数来计算特征。 每个函数的输出应是具有唯一主键的 Apache Spark 数据帧。 主键可由一个或多个列组成。
通过实例化
FeatureStoreClient并使用create_table(v0.3.6 及更高版本)或create_feature_table(v0.3.5 及更低版本)创建特征表。使用
write_table填充特征表。
有关以下示例中使用的命令和参数的详细信息,请参阅特征存储 Python API 参考。
V0.3.6 及更高版本
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 及更低版本
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
将现有的 Delta 表注册为特征表
使用 v0.3.8 和更高版本,可将现有的 Delta 表注册为特征表。 该 Delta 表必须在元存储中。
注意
若要更新已注册的特征表,必须使用特征存储 Python API。
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
控制对特征表的访问
请参阅访问控制(旧版)。
更新特征表
可以通过添加新特征或基于主键修改特定的行来更新特征表。
无法更新以下特征表元数据:
- 主密钥
- 分区键
- 现有特征的名称或类型
将新特征添加到现有的特征表
可通过以下两种方式之一将新特征添加到现有的特征表:
- 更新现有的特征计算函数,并使用返回的数据帧作为参数来运行
write_table。 这会更新特征表架构,并基于主键合并新的特征值。 - 创建新的特征计算函数来计算新的特征值。 此新计算函数返回的数据帧必须包含特征表的主键和分区键(如果已定义)。 使用数据帧作为参数来运行
write_table,以使用同一主键将新特征写入现有的特征表。
仅更新特征表中的特定行
在 mode = "merge" 中使用 write_table。 在write_table调用中发送的数据帧内,那些其主键不存在的行将会保持不变。
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
安排一个任务来更新特征表
为确保特征表中的特征始终采用最新值,Databricks 建议创建一个作业,以便定期(例如每天)运行某个笔记本来更新特征表。 如果你已创建一个非计划作业,可将其转换为计划作业,以确保特征值始终是最新的。 请参阅 Lakeflow Jobs。
用于更新特征表的代码使用 mode='merge',如以下示例所示。
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
存储每日特征的历史值
定义一个带有复合主键的特征表。 在主键中包含日期。 例如,对于特征表 store_purchases,可以使用复合主键 (date, user_id) 和分区键 date 实现高效的读取。
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
然后,可以创建代码以从特征表中读取数据并将 date 筛选到所需的时间段。
还可以通过使用 参数将date列指定为时间戳键来创建timestamp_keys。
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer time series features'
)
这样就可以在使用 create_training_set 或 score_batch 时启用时点查找。 系统使用你指定的 timestamp_lookup_key 执行基于时间戳的连接。
为使特征表保持最新,请设置按计划定期运行的作业以写入特征,或将新特征值流式传输到特征表。
创建一个流媒体特征计算管道以更新特征
若要创建流式处理特征计算管道,请将流式处理 DataFrame 作为参数传递给 write_table。 此方法将返回 StreamingQuery 对象。
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
从特征表读取
使用 read_table 读取特征值。
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
搜索和浏览特征表
使用特征存储 UI 搜索或浏览特征表。
在侧栏中的 AI/ML 下,单击 “功能 ”以显示功能存储 UI。
在搜索框中,输入特征表、特征或用于特征计算的数据源的完整或部分名称。 你也可以输入标记的全部或部分键或值。 搜索文本不区分大小写。

获取特征表元数据
用于获取特征表元数据的 API 取决于所用的 Databricks Runtime 版本。 使用 v0.3.6 和更高版本时,请使用 get_table。 使用 v0.3.5 和更低版本时,请使用 get_feature_table。
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
处理特征表标记
标记是键值对,可创建并使用它们来搜索特征表。 可以使用特征存储 UI 或特征存储 Python API 创建、编辑和删除标记。
在 UI 中处理特征表标记
使用特征存储 UI 搜索或浏览特征表。 若要访问 UI,请在侧栏中的 AI/ML 下单击 “功能”。
通过功能存储库 UI 添加标记
单击
 (如果尚未打开)。 显示标记表。
(如果尚未打开)。 显示标记表。
单击“名称”和“值”字段,然后输入标记的键和值。
单击“添加” 。
使用特征存储 UI 编辑或删除标记
要编辑或删除现有标签,请使用“操作”列中的图标。
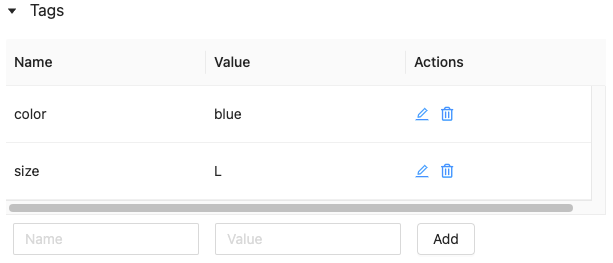
使用特征存储 Python API 处理特征表标记
在运行 v0.4.1 及更高版本的群集上,可以使用功能存储 Python API 创建、编辑和删除标记。
要求
功能存储客户端 v0.4.1 及更高版本
使用特征存储 Python API 创建带有标记的特征表
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
使用特征存储 Python API 添加、更新和删除标记
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
更新特征表的数据源
特征存储会自动跟踪用于计算要素的数据源。 还可使用特征存储 Python API 手动更新数据源。
要求
功能存储客户端 v0.5.0 及更高版本
使用特征存储 Python API 添加数据源
下面提供了一些命令示例。 有关详细信息,请参阅 API 文档。
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
使用特征存储 Python API 删除数据源
有关详细信息,请参阅 API 文档。
注意
以下命令删除与源名称匹配的所有类型(“table”、“path”和“custom”)的数据源。
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
删除特征表
可以使用特征存储 UI 或特征存储 Python API 删除特征表。
注意
- 删除特征表可能会导致上游创建者和下游使用者(模型、终结点和计划作业)出现意外故障。 必须与您的云提供商配合删除已发布的在线商店。
- 使用 API 删除特征表时,底层 Delta 表也会被删除。 从 UI 中删除特征表时,必须单独删除底层 Delta 表。
使用 UI 删除特征表
在特征表页上,单击特征表名称右侧的
 ,然后选择“删除”。 如果你对特征表不拥有“可管理”权限,则看不到此选项。
,然后选择“删除”。 如果你对特征表不拥有“可管理”权限,则看不到此选项。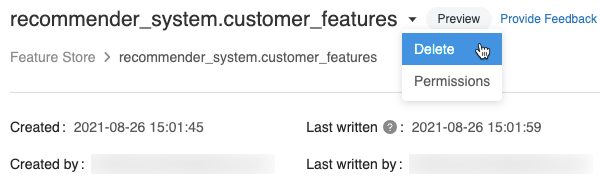
在“删除特征表”对话框中,单击“删除”进行确认。
如果还想删除基础 Delta 表,请在笔记本中运行以下命令。
%sql DROP TABLE IF EXISTS <feature-table-name>;
使用特征存储 Python API 删除特征表
在特征存储客户端 v0.4.1 及更高版本中,可以使用 drop_table 删除特征表。 使用 drop_table 删除表时,底层的 Delta 表也会被删除。
fs.drop_table(
name='recommender_system.customer_features'
)