本文通过添加特定于 LLMOps 工作流的信息,对 Databricks 上的 MLOps 工作流进行了补充。 有关详细信息,请参阅 MLOps 全书。
对于 LLM,MLOps 工作流如何变化?
LLM 是一类自然语言处理 (NLP) 模型,在各种任务(如开放式问答、汇总和指令执行)中,其规模和性能都明显超过其之前的模型。
LLM 的开发和评估在一些重要方面与传统 ML 模型有所不同。 本部分简要总结了 LLM 的一些关键属性及其对 MLOps 的影响。
| LLM 的关键属性 | 对 MLOps 的影响 |
|---|---|
LLM 有多种形式。
|
开发过程:项目通常以增量方式进行开发,从现有模型、第三方模型或开源模型开始,到自定义微调模型结束。 |
| 许多 LLM 将常规自然语言查询和指令作为输入。 这些查询可以包含精心设计的提示,以引出所需的答复。 |
开发过程:设计用于查询 LLM 的文本模板通常是开发新 LLM 管道的重要组成部分。 打包 ML 工件:许多 LLM 管道使用现有的 LLM 或 LLM 服务端点。 为这些管道开发的 ML 逻辑可能侧重于提示模板、代理或链,而不是模型本身。 打包并提升到生产环境中的 ML 工件可能是这些管道,而不是模型。 |
| 可以向许多 LLM 提供包含示例、上下文或其他信息的提示来帮助回答查询。 | 提供基础结构: 使用上下文扩充 LLM 查询时,可以使用其他工具(如矢量索引)来搜索相关上下文。 |
| 第三方 API 提供专有和开源模型。 | API 治理:使用集中式 API 治理可以在 API 提供商之间轻松切换。 |
| LLM 是非常庞大的深度学习模型,通常从数千兆字节到数百千兆字节不等。 |
服务基础结构:LLM 可能需要 GPU 来实现实时模型服务,对于动态加载的模型,还需要快速存储。 成本/性能权衡:由于较大的模型需要更多的计算,并且服务成本更高,因此可能需要一些技术来减少模型大小和计算。 |
| LLM 很难使用传统的 ML 指标进行评估,因为通常没有一个“正确”答案。 | 人工反馈:人工反馈对于评估和测试 LLM 至关重要。 应将用户反馈直接纳入 MLOps 流程,以用于测试、监视和将来的微调等。 |
MLOps 和 LLMOps 之间的共同点
MLOps 流程的许多方面对于 LLM 来说并没有变化。 例如,以下准则也适用于 LLM:
- 使用单独的环境进行开发、过渡和生产。
- 使用 Git 进行版本控制。
- 使用 MLflow 管理模型开发,并使用 Unity Catalog 中的模型来管理模型生命周期。
- 使用 Delta 表将数据存储在湖屋体系结构中。
- 现有的 CI/CD 基础结构不应需要进行任何更改。
- MLOps 的模块化结构保持不变,包括特征化、模型训练、模型推理等管道。
参考体系结构示意图
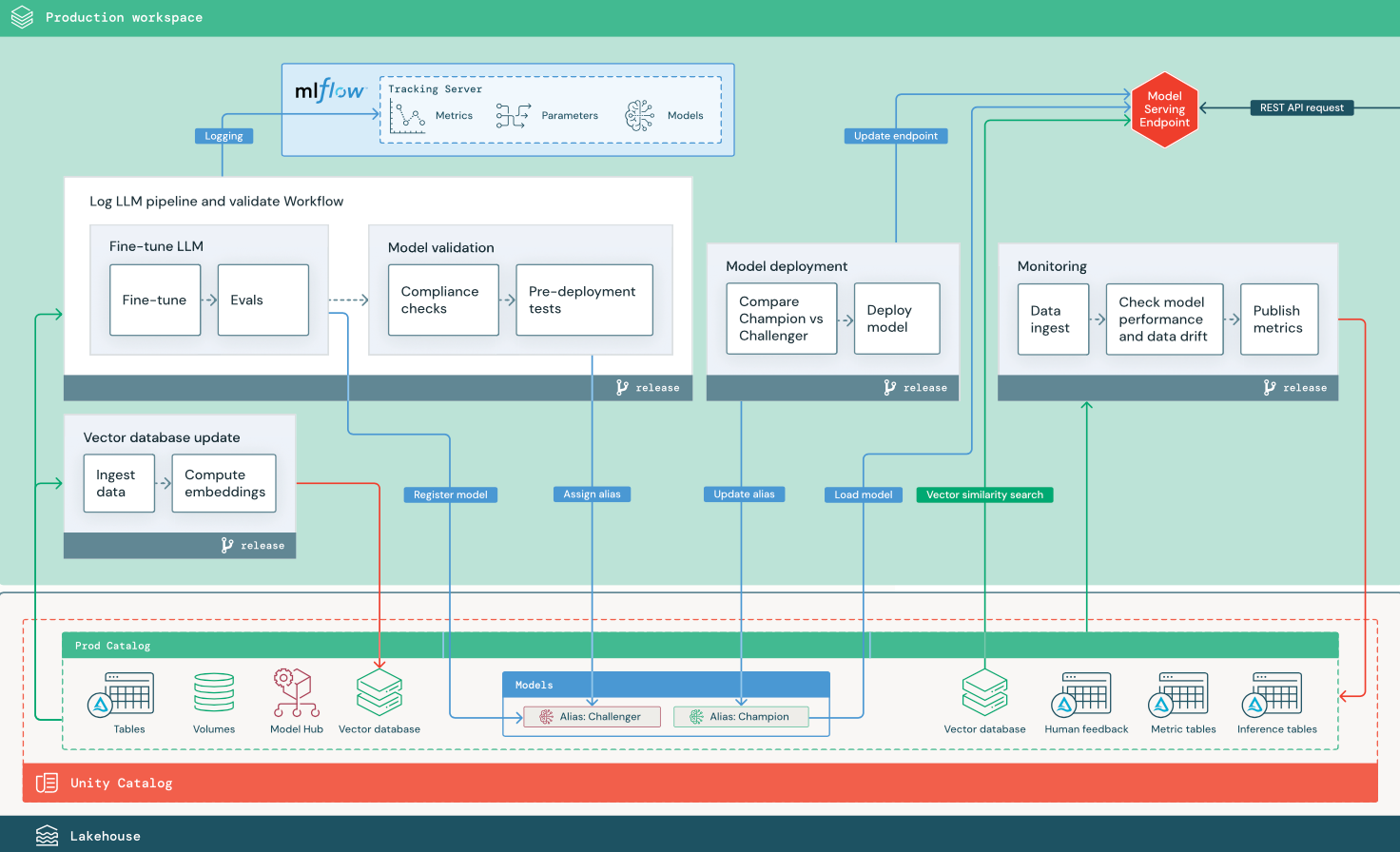
本部分使用两个基于 LLM 的应用程序来说明对传统 MLOps 参考体系结构的一些调整。 示意图显示了两种生产体系结构:1) 使用第三方 API 的检索增强生成 (RAG) 应用程序,以及 2) 使用自承载微调模型的 RAG 应用程序。 这两个示意图都显示了一个可选的矢量数据库,可以通过模型服务终结点直接查询 LLM 来替换此项。
使用第三方 LLM API 的 RAG
示意图显示了使用 Databricks 外部模型连接到第三方 LLM API 的 RAG 应用程序的生产体系结构。
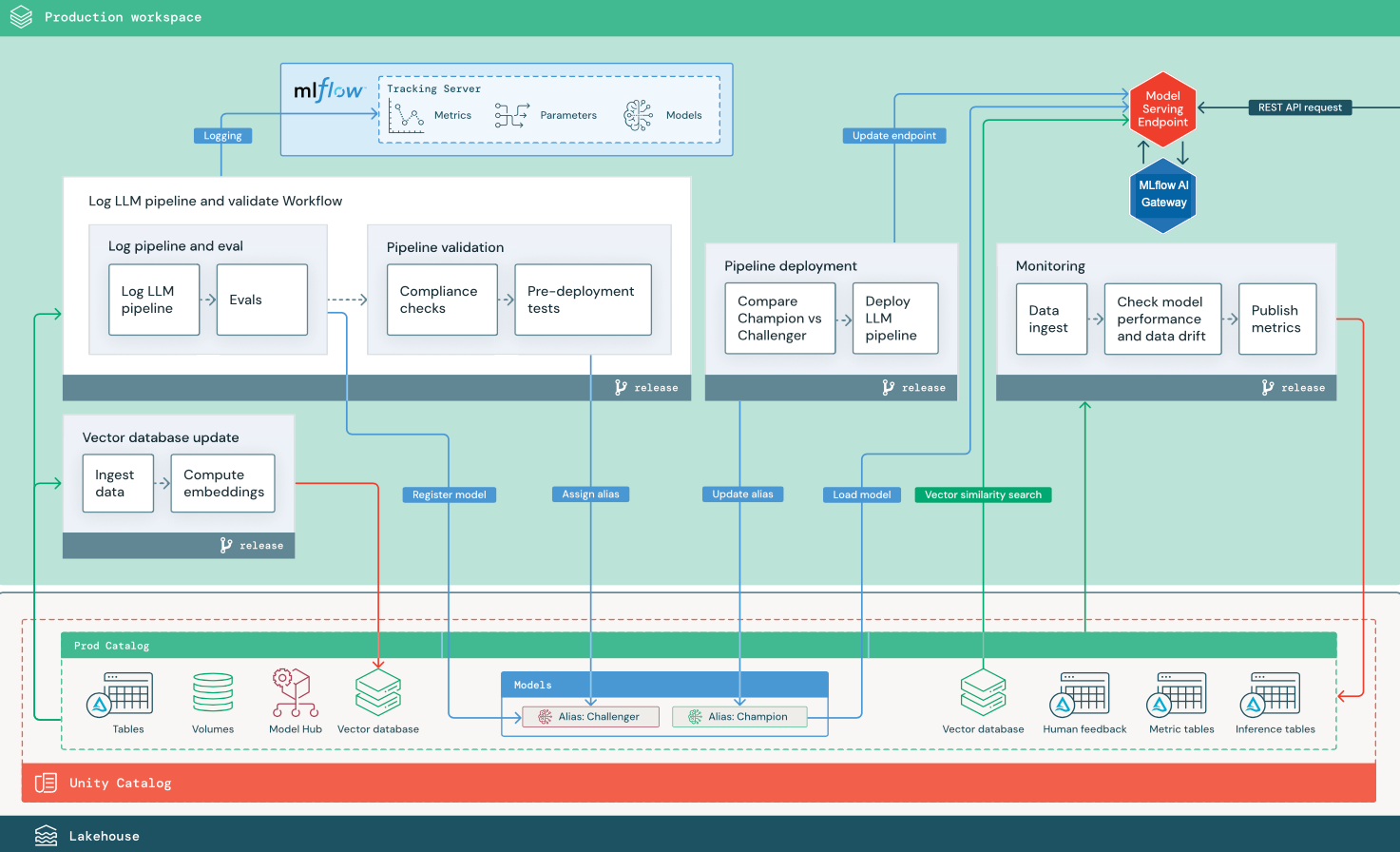
使用微调开源模型的 RAG
示意图显示了对开源模型进行微调的 RAG 应用程序的生产体系结构。