本文包括 Azure Databricks 上基于深度学习的推荐模型的两个示例。 与传统的推荐模型相比,深度学习模型能获得更高质量的结果,并能缩放到更大的数据量。 随着这些模型的不断发展,Databricks 提供了一个框架,用于有效地训练能够处理数亿用户的大规模推荐模型。
一般的推荐系统可以看作是一个漏斗,其各个阶段如图所示。
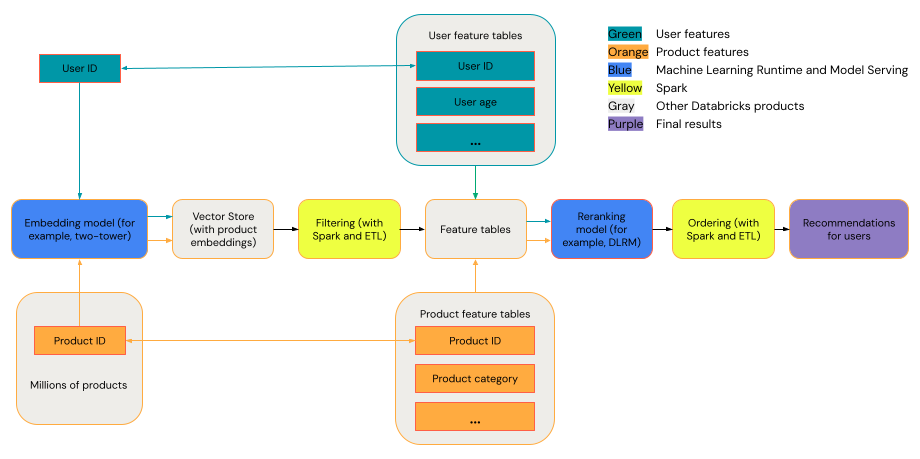
有些模型(如双塔模型)作为检索模型表现更好。 这些模型规模较小,可有效处理数百万个数据点。 其他模型(如 DLRM 或 DeepFM)作为重新排序模型表现更好。 这些模型可以处理更多数据,规模更大,并能提供精细的推荐。
要求
Databricks Runtime 14.3 LTS ML
工具
本文中的示例演示了以下工具:
- TorchDistributor:TorchDistributor 是一个框架,可用于在 Databricks 上运行大规模 PyTorch 模型训练。 它使用 Spark 进行编排,并且可以缩放到群集中可用的任意数量的 GPU。
- MLflow:MLflow 允许跟踪参数、指标和模型检查点。
- TorchRec:新式推荐器系统使用嵌入查阅表格来处理数百万用户和项目,以生成高质量的建议。 较大的嵌入大小可以提高模型性能,但需要大量 GPU 内存和多 GPU 设置。 TorchRec 提供了一个可在多个 GPU 中缩放推荐模型和查找表的框架,因此非常适合大型嵌入。
示例:使用双塔模型体系结构的电影推荐
双塔模型旨在处理大规模个性化任务,它先分别处理用户数据和商品数据,然后再将其合并。 它能够高效地生成成百上千条优质推荐。 该模型通常需要三个输入:一个 user_id 特征、一个 product_id 特征和一个二进制标签,二进制标签定义了<用户、产品>交互是积极的(用户购买了产品)还是消极的(用户给产品打了一星)。 模型的输出是用户和物品两者的嵌入,这些嵌入随后通常会组合起来(通常使用点积或余弦相似度),以预测用户与物品之间的交互。
由于双塔模型为用户和产品提供了嵌入,因此可以将这些嵌入内容放置在矢量索引(如 Databricks AI 搜索)中,并针对用户和项执行类似搜索的操作。 例如,可以将所有项放在向量存储中,并且对于每个用户,查询向量存储以查找其嵌入内容与用户的相似的前百个项。
以下示例笔记本使用“从项集学习”数据集实现双塔模型训练,以预测用户给予某部电影高度评价的可能性。 它使用马赛克 StreamingDataset 进行分布式数据加载,将 TorchDistributor 用于分布式模型训练,使用 MLflow 进行模型跟踪和日志记录。
双塔推荐模型笔记本
此笔记本在 Databricks 市场中也有售:双塔模型笔记本
注意
- 双塔模型最常见的输入是类别特征 user_id 和 product_id。 可以修改模型以支持用户和产品的多个特征向量。
- 双塔模型的输出通常是二进制值,指示用户与产品的交互是积极的还是消极的。 可以修改该模型以进行其他应用,例如回归、多类分类和多个用户操作(例如,摒弃或购买)的概率。 复杂输出的实现应当谨慎进行,因为相互竞争的目标可能会降低模型生成的嵌入质量。
示例:使用虚构数据集训练 DLRM 体系结构
DLRM 是一种先进的神经网络体系结构,专为个性化和推荐系统而设计。 它结合了分类和数字输入,可有效地对用户与商品之间的交互建模,并预测用户的偏好。 DLRM 通常需要输入包括稀疏特征(如用户 ID、商品 ID、地理位置或产品类别)和密集特征(如用户年龄或商品价格)。 DLRM 的输出通常是对用户参与的预测,如点击率或购买可能性。
DLRM 提供了一个高度可自定义的框架,能够处理大规模数据,因此适用于各种领域的复杂推荐任务。 由于该模型比双塔体系结构更大,因此经常在重新排序阶段使用。
以下示例笔记本生成一个 DLRM 模型,以使用密集(数字)特征和稀疏(分类)特征来预测二进制标签。 它使用合成数据集来训练模型,使用 Mosaic StreamingDataset 进行分布式数据加载,使用 TorchDistributor 进行分布式模型训练,并使用 MLflow 进行模型跟踪和日志记录。
DLRM 笔记本
Databricks Marketplace 中也提供了此 DLRM 笔记本。
双塔模型和 DLRM 模型的比较
下表列出了有关选择使用哪种推荐模型的一些指导原则。
| 模型类型 | 训练所需的数据集大小 | 模型大小 | 支持的输入类型 | 支持的输出类型 | 用例 |
|---|---|---|---|---|---|
| 双塔 | 缩小 | 缩小 | 通常有两个特征(user_id、product_id) | 主要是二进制分类和嵌入生成 | 生成成百上千个可能的推荐 |
| DLRM | 更大 | 更大 | 各类类别特征和稠密特征(user_id、gender、geographic_location、product_id、product_category,…) | 多类分类、回归等 | 细粒度检索(推荐数十个高度相关的条目) |
总之,双塔模型最适合用于高效生成数千条高质量的推荐。 例如,有线电视提供商的电影推荐。 DLRM 模型最适合用于根据较多数据生成非常具体的推荐。 例如,零售商希望向客户展示数量较少的客户极有可能购买的商品。