本文介绍了如何使用 MLflow 运行来查看与分析模型训练试验的结果,以及如何管理和组织运行。 有关 MLflow 试验的详细信息,请参阅使用 MLflow 试验组织训练运行。
一个 MLflow 运行对应于模型代码的单次执行。 每个运行记录的信息包括启动运行的笔记本、运行创建的任何模型、保存为键值对的模型参数和指标、运行元数据标签,以及运行创建的任何项目或输出文件。
所有 MLflow 运行都会记录到活动试验中。 如果尚未将某个试验显式设置为活动试验,则会将运行记录到笔记本试验。
查看运行详细信息
可以从运行的试验详细信息页访问运行,或直接从创建运行的笔记本访问运行。
从实验详情页的运行记录表中,单击运行名称。
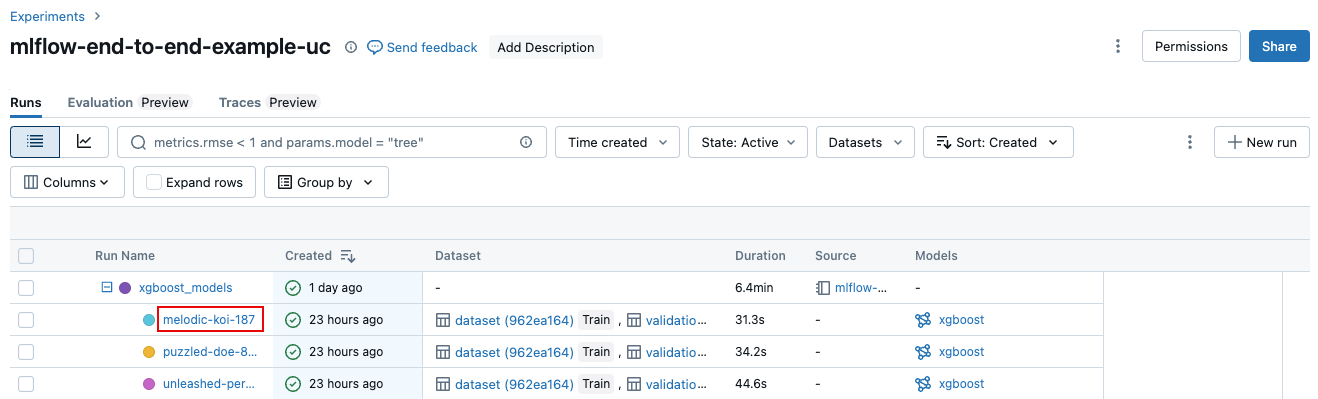
在笔记本的“试验运行”边栏中,单击运行名称。
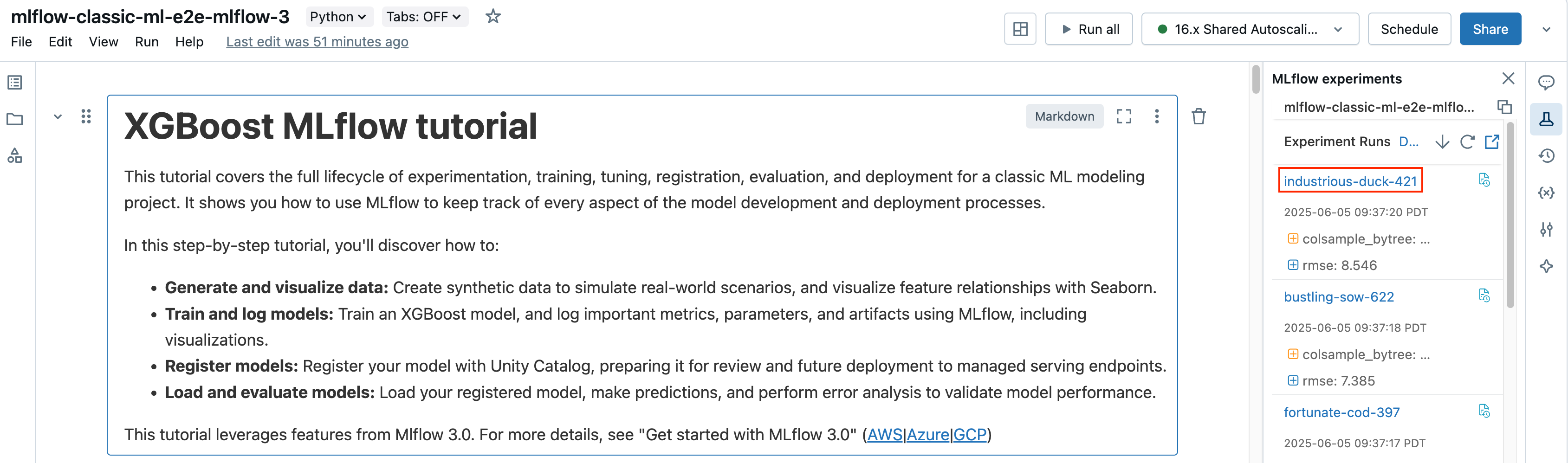
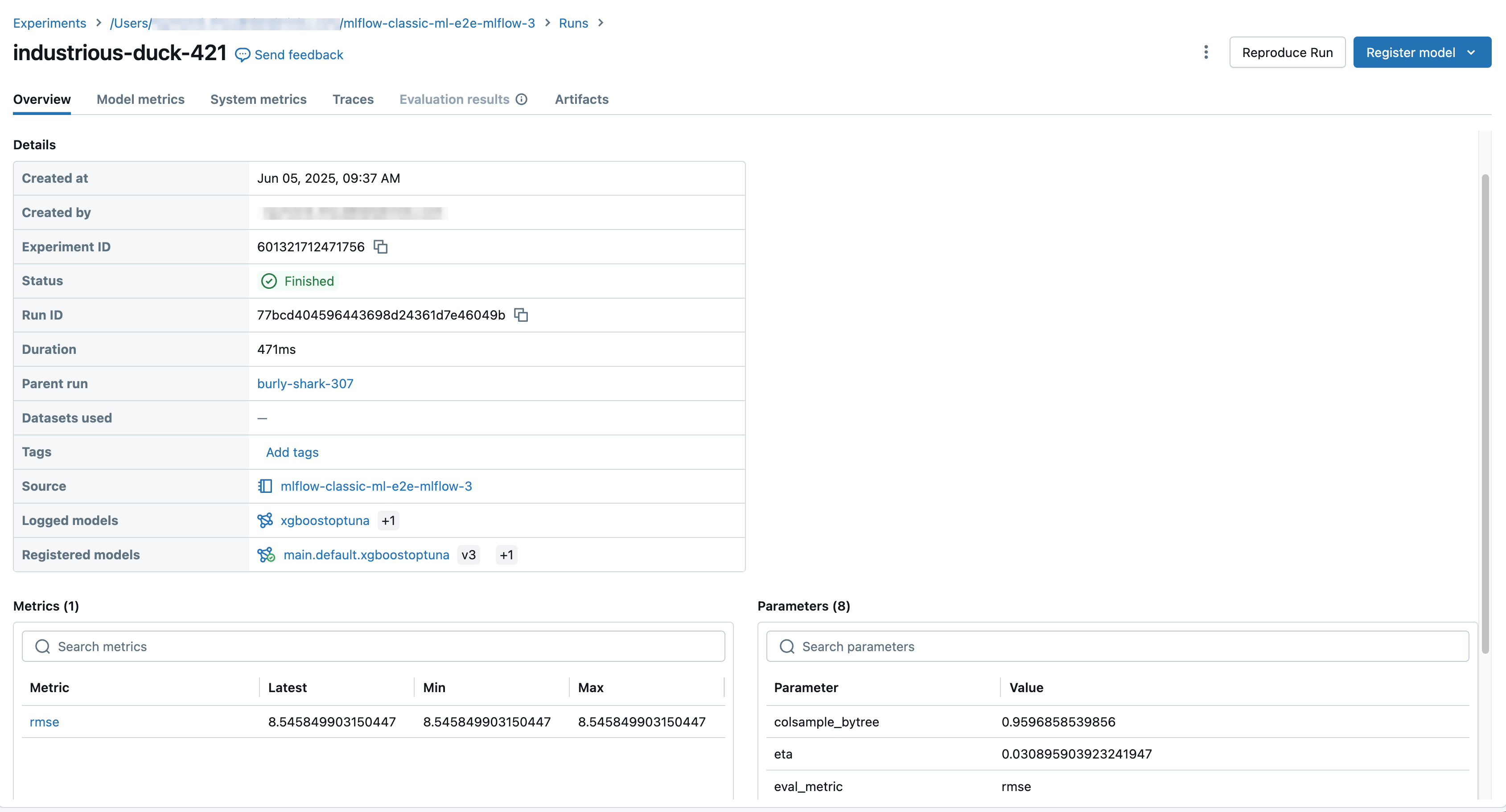
运行屏幕显示运行 ID、用于运行的参数、运行生成的指标,以及有关运行的详细信息,包括指向源笔记本的链接。 从运行中保存的构件可在“构件”选项卡中查看。
用于预测的代码片段
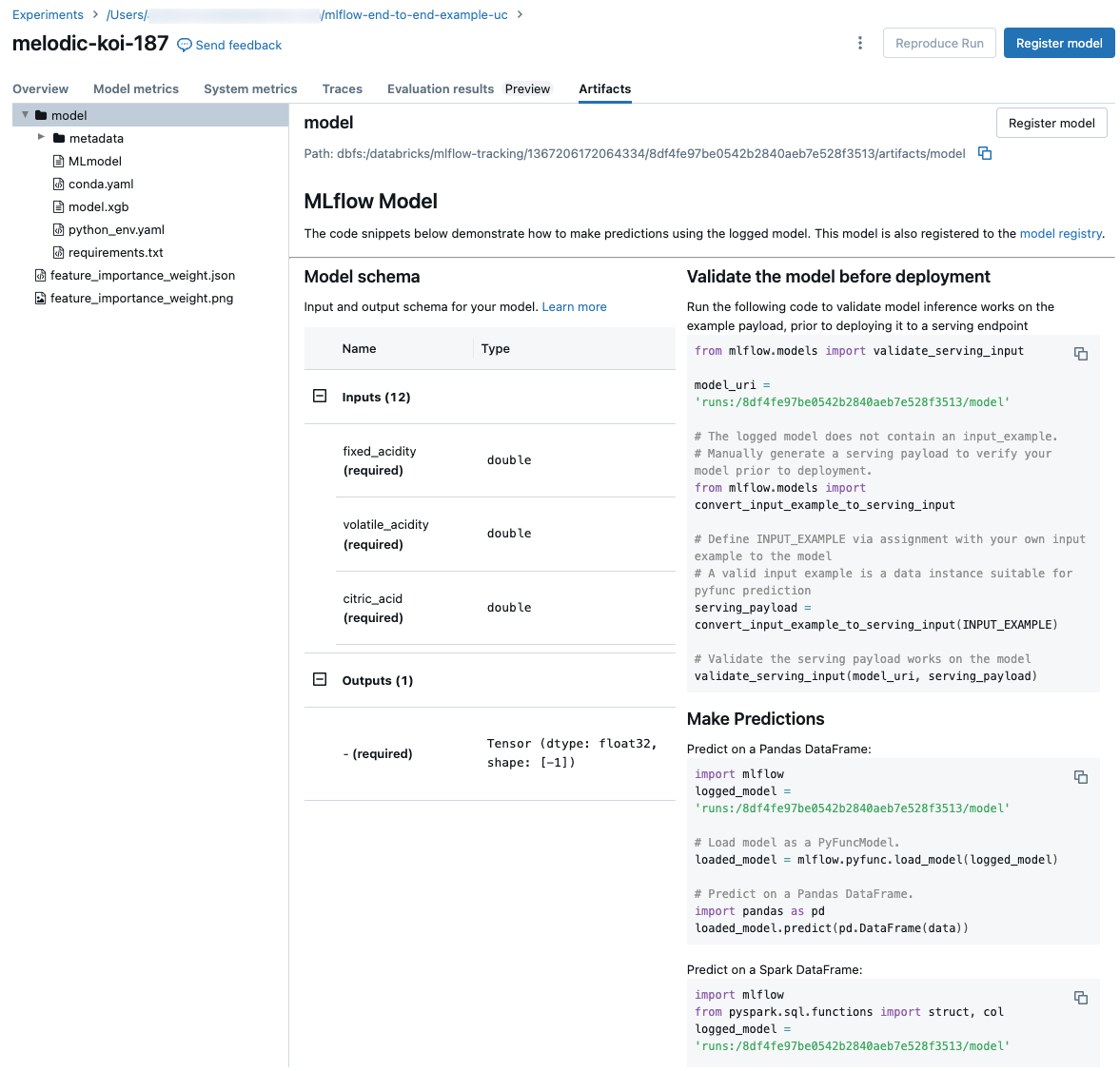
如果从运行中记录模型,该模型就会出现在“项目”选项卡中,并附有代码片段,说明如何加载和使用该模型在 Spark 和 Pandas DataFrames 上进行预测。 在 MLflow 3 中,模型现在是其独特的第一类对象,而不是作为运行项目进行记录。 有关详细信息,请参阅 适用于模型的 MLflow 3 入门。
查看用于运行的笔记本
若要查看用于创建运行的笔记本的版本,请执行以下操作:
- 在试验详细信息页上,单击“源”列中的链接。
- 在运行页上,单击“源”旁边的链接。
- 从笔记本里,在“实验运行”边栏中,单击该实验运行框中的笔记本图标
 。
。
与该运行关联的笔记本版本会在主窗口中显示,并有一个高亮条显示运行日期和时间。
向某个运行实例添加标签
标签是键值对,你可以创建这些键值对,并在以后使用这些键值对来搜索运行。
在运行页上的“详细信息”表中,单击“标记”旁边的“添加标记”。
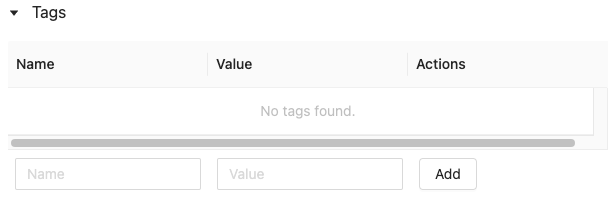
添加/编辑标记对话将打开。 在“键”字段中,输入键的名称,然后单击“添加标记”。
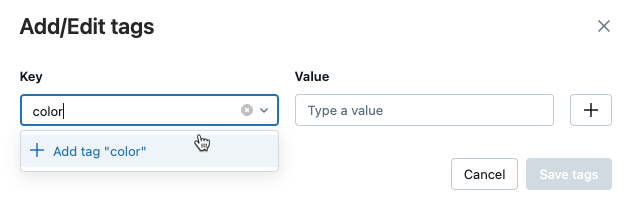
在“值”字段中,输入变量的值。
单击加号,以保存刚输入的键值对。
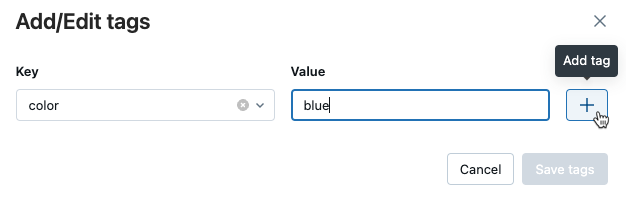
重复步骤 2 至步骤 4,以添加其他标记。
完成后,单击“保存标记”。
编辑或删除执行过程中的标签
在运行页上的“详细信息”表中,单击
 现有标记旁边。
现有标记旁边。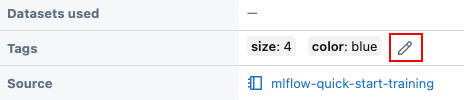
添加/编辑标记对话将打开。
要删除标记,请单击该标记上的 X。
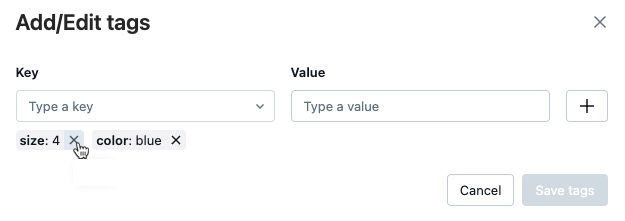
要编辑标记,从下拉菜单中选择键,然后在“值”字段中编辑值。 单击加号来保存更改。
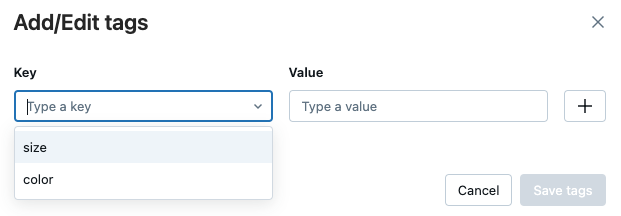
完成后,单击“保存标记”。
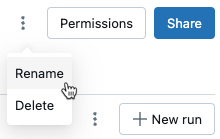
重命名运行
若要重命名运行,请单击 ![]() 在运行页面右上角( “权限 ”按钮旁)并选择“ 重命名”。
在运行页面右上角( “权限 ”按钮旁)并选择“ 重命名”。
选择要显示的列
要控制试验详细信息页上运行表中显示的列,请单击“列”,然后从下拉菜单中进行选择。
筛选运行
可在实验详情页的表格中,根据参数或指标值搜索实验运行。 你还可以按标记搜索运行。
若要搜索与包含参数和指标值的表达式匹配的运行,请在搜索字段中输入查询并按 Enter。 查询的部分语法示例如下:
metrics.r2 > 0.3params.elasticNetParam = 0.5params.elasticNetParam = 0.5 AND metrics.avg_areaUnderROC > 0.3MIN(metrics.rmse) <= 1MAX(metrics.memUsage) > 0.9LATEST(metrics.memUsage) = 0 AND MIN(metrics.rmse) <= 1默认情况下,指标值是根据上次记录的值进行筛选的。 使用
MIN或MAX可以分别根据最小或最大指标值搜索运行。 只有在 2024 年 8 月之后记录的运行才具有最小和最大指标值。要按标记搜索运行,请按以下格式输入标记:
tags.<key>="<value>"。 字符串值必须用引号括起来,如图所示。tags.estimator_name="RandomForestRegressor"tags.color="blue" AND tags.size=5键和值都可以包含空格。 如果键包含空格,则必须将其括在反引号中,如下所示。
tags.`my custom tag` = "my value"
还可根据运行状态(活动或已删除)筛选运行、创建运行的时间以及使用哪些数据集。 为此,请分别在“创建时间”、“状态”和“数据集”下拉菜单中做出选择。
下载运行结果
可从试验详细信息页下载运行,如下所示:
单击
 打开烤肉串菜单。
打开烤肉串菜单。
要下载 CSV 格式的文件,其中包含显示的所有运行(最多 100 个),请选择
下载运行 。 MLflow 会下载一个文件,该文件每行对应一个运行,每个运行包含以下字段: Start Time, Duration, Run ID, Name, Source Type, Source Name, User, Status, <parameter1>, <parameter2>, ..., <metric1>, <metric2>, ...如果您想下载超过 100 个运行,或者想以编程方式下载运行,请选择“下载所有运行”。 此时会打开一个对话框,其中显示可在笔记本中复制或打开的代码片段。 在笔记本单元格中运行此代码后,在单元格输出中选择下载所有行。
删除运行
您可以按照以下步骤从实验详细信息页中删除实验运行:
在试验中,通过单击运行左侧的复选框来选择一个或多个运行。
单击 “删除” 。
如果该运行是父运行,请决定是否也要删除子运行。 默认情况下选择此选项。
单击“删除”进行确认。 删除的运行将保存 30 天。 若要显示删除的运行,请选择“状态”字段中的“已删除”。
基于创建时间批量删除任务
可以使用 Python 批量删除在某个 UNIX 时间戳之前或等于该时间戳创建的实验运行。
使用 Databricks Runtime 14.1 或更高版本,可以调用 mlflow.delete_runs API 来删除运行并返回已删除的运行数。
以下是 mlflow.delete_runs 参数:
-
experiment_id:包含要删除的运行的试验 ID。 -
max_timestamp_millis:用于删除运行的最大创建时间戳(以毫秒为单位),自 UNIX 纪元以来计算。 仅删除在此时间戳或之前创建的运行。 -
max_runs:可选。 一个正整数,表示要删除的最大运行数。 max_runs 允许的最大值为 10000。 如果未指定,则max_runs默认为 10000。
import mlflow
# Replace <experiment_id>, <max_timestamp_ms>, and <max_runs> with your values.
runs_deleted = mlflow.delete_runs(
experiment_id=<experiment_id>,
max_timestamp_millis=<max_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_deleted = mlflow.delete_runs(
experiment_id="4183847697906956",
max_timestamp_millis=1711990504000,
max_runs=10
)
使用 Databricks Runtime 13.3 LTS 或更早版本,可以在 Azure Databricks Notebook 中运行以下客户端代码。
from typing import Optional
def delete_runs(experiment_id: str,
max_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk delete runs in an experiment that were created prior to or at the specified timestamp.
Deletes at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to delete.
:param max_timestamp_millis: The maximum creation timestamp in milliseconds
since the UNIX epoch for deleting runs. Only runs
created prior to or at this timestamp are deleted.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to delete. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs deleted.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "max_timestamp_millis": max_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/delete-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_deleted"]
有关基于创建时间删除运行的参数和返回值规范,请参阅 Azure Databricks 试验 API 文档。
还原运行
您可以通过用户界面还原之前删除的运行,方法如下:
在“试验”页上的“状态”字段中选择“已删除”以显示已删除的运行。
通过单击运行左侧的复选框来选择一个或多个运行。
请单击“还原”。
单击“还原”进行确认。 在“状态”字段中选择“活动”时,现在会显示还原的运行。
基于删除时间批量还原运行
还可以使用 Python 批量还原在 UNIX 时间戳或之后删除的实验运行。
使用 Databricks Runtime 14.1 或更高版本,可以调用 mlflow.restore_runs API 来还原运行并返回已还原的运行数。
以下是 mlflow.restore_runs 参数:
-
experiment_id:包含要还原的运行的实验 ID。 -
min_timestamp_millis:用于还原运行的最小删除时间戳(以毫秒为单位),从 UNIX 纪元开始。 只有在此时间戳或之后删除的运行将被还原。 -
max_runs:可选。 一个正整数,表示要恢复的最大运行次数。 max_runs 允许的最大值为 10000。 如果未指定,则 max_runs 默认为 10000。
import mlflow
# Replace <experiment_id>, <min_timestamp_ms>, and <max_runs> with your values.
runs_restored = mlflow.restore_runs(
experiment_id=<experiment_id>,
min_timestamp_millis=<min_timestamp_ms>,
max_runs=<max_runs>
)
# Example:
runs_restored = mlflow.restore_runs(
experiment_id="4183847697906956",
min_timestamp_millis=1711990504000,
max_runs=10
)
使用 Databricks Runtime 13.3 LTS 或更早版本,可以在 Azure Databricks Notebook 中运行以下客户端代码。
from typing import Optional
def restore_runs(experiment_id: str,
min_timestamp_millis: int,
max_runs: Optional[int] = None) -> int:
"""
Bulk restore runs in an experiment that were deleted at or after the specified timestamp.
Restores at most max_runs per request.
:param experiment_id: The ID of the experiment containing the runs to restore.
:param min_timestamp_millis: The minimum deletion timestamp in milliseconds
since the UNIX epoch for restoring runs. Only runs
deleted at or after this timestamp are restored.
:param max_runs: Optional. A positive integer indicating the maximum number
of runs to restore. The maximum allowed value for max_runs
is 10000. If not specified, max_runs defaults to 10000.
:return: The number of runs restored.
"""
from mlflow.utils.databricks_utils import get_databricks_host_creds
from mlflow.utils.request_utils import augmented_raise_for_status
from mlflow.utils.rest_utils import http_request
json_body = {"experiment_id": experiment_id, "min_timestamp_millis": min_timestamp_millis}
if max_runs is not None:
json_body["max_runs"] = max_runs
response = http_request(
host_creds=get_databricks_host_creds(),
endpoint="/api/2.0/mlflow/databricks/runs/restore-runs",
method="POST",
json=json_body,
)
augmented_raise_for_status(response)
return response.json()["runs_restored"]
有关基于删除时间还原运行的参数和返回值规范,请参阅 Azure Databricks 试验 API 文档。
比较运行
可以比较单个试验或多个试验中的运行。 “ 比较运行 ”页以表格格式显示有关所选运行的信息。 还可以创建运行结果的可视化效果,以及运行信息、运行参数和指标的表。 请参阅 使用图形和图表比较 MLflow 运行和模型。
“参数”和“指标”表显示所有选定运行中的运行参数和指标。 这些表中的列由紧接上方的“运行详细信息”表标识。 为了简化操作,可以通过切换  ,将所有选定运行中相同的参数和指标隐藏。
,将所有选定运行中相同的参数和指标隐藏。
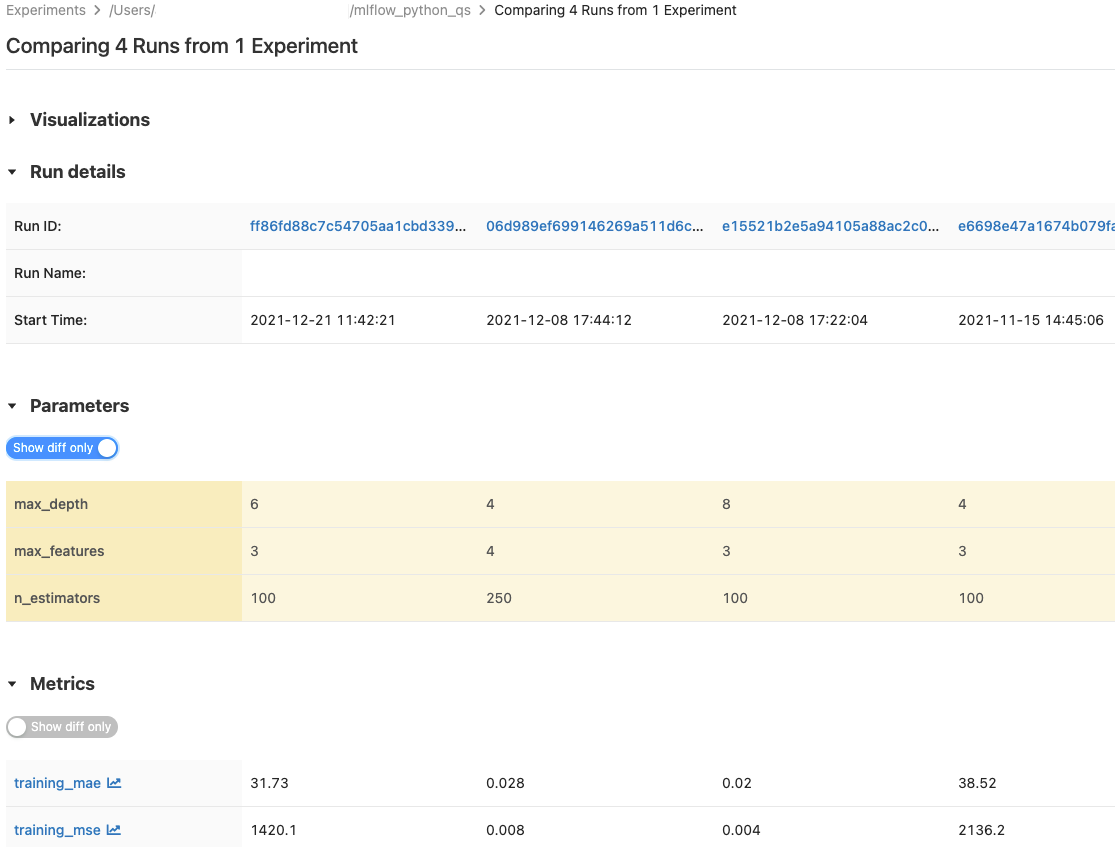
比较单个试验中的运行
在试验详细信息页上,通过单击运行记录左侧的复选框来选择两个或更多个运行记录,或者通过选中列顶部的框来选择所有运行记录。
单击“比较”。 “比较
<N>运行”屏幕将出现。
比较多个实验中的运行结果
在试验页上,通过单击试验名称左侧的框来选择要比较的试验。
单击“比较(n)”(n 是您选择的试验)。 此时将出现一个屏幕,其中显示了所选试验中的所有运行。
通过单击运行左侧的复选框来选择两个或多个运行,或通过选中运行列表顶部的复选框来选择所有运行。
单击“比较”。 “比较
<N>运行”屏幕将出现。
使用系统表比较运行情况
试验和运行的 MLflow 元数据也可以在系统表中获取,在那里你可以利用 Databricks SQL 和 Databricks 提供的所有 Lakehouse 工具来分析你的试验数据。 有关更多详细信息,请参阅 MLflow 系统表参考。
在工作区之间复制运行
若要将 MLflow 运行导入或导出 Databricks 工作区,可以使用社区驱动的开放源代码项目 MLflow Export-Import。