注意
本文档介绍工作区模型注册表。 Azure Databricks 建议使用 Unity Catalog 中的模型。 Unity Catalog 中的模型集模型治理、跨工作区访问、数据世系和部署于一体。 工作区模型注册表将在未来弃用。
此示例演示如何使用工作区模型注册表,以生成机器学习应用程序来预测风力发电场的每日电力输出。 该示例演示如何:
- 使用 MLflow 跟踪和记录模型
- 使用模型注册表注册模型
- 描述模型并进行模型版本阶段转换
- 将注册模型与生产应用程序集成
- 在模型注册表中搜索和发现模型
- 存档和删除模型
本文介绍如何使用 MLflow 跟踪和 MLflow 模型注册表 UI 和 API 来执行这些步骤。
有关使用 MLflow 跟踪功能和注册表 API 来执行所有这些步骤的笔记本,请参阅模型注册表示例笔记本。
使用 MLflow 跟踪功能加载数据集、训练模型和进行跟踪
需要先在试验运行期间训练并记录模型,才能在模型注册表中注册模型。 本部分介绍如何加载风电场数据集、训练模型并将训练运行记录到 MLflow。
加载数据集
以下代码加载一个数据集,其中包含美国风电场的天气数据和电力输出信息。 数据集包含 wind direction、wind speed 和 air temperature 功能,每六小时采样一次(在 00:00、08:00、16:00 各采集一次),以及过去几年来的每日总电力输出 (power)。
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
训练模型
下面的代码使用 TensorFlow Keras 来训练神经网络,以便根据数据集中的天气功能预测电力输出。 MLflow 用于跟踪模型的超参数、性能指标、源代码和项目。
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
使用 MLflow UI 注册和管理模型
本部分内容:
创建新的已注册模型
通过单击 Azure Databricks 笔记本右侧边栏中的“试验”图标 ,导航到 MLflow 试验运行边栏。

找到对应于 TensorFlow Keras 模型训练会话的 MLflow 运行,并通过单击“查看运行细节”图标在 MLflow 运行 UI 中打开它。
在 MLflow UI 中,向下滚动到“项目”部分,然后单击名为“模型”的目录 。 单击显示的“注册模型”按钮。

从下拉菜单中选择“创建新模型”,然后输入以下模型名称:。
单击“注册”。 这将注册一个名为
power-forecasting-model的新模型,并创建一个新的模型版本:Version 1。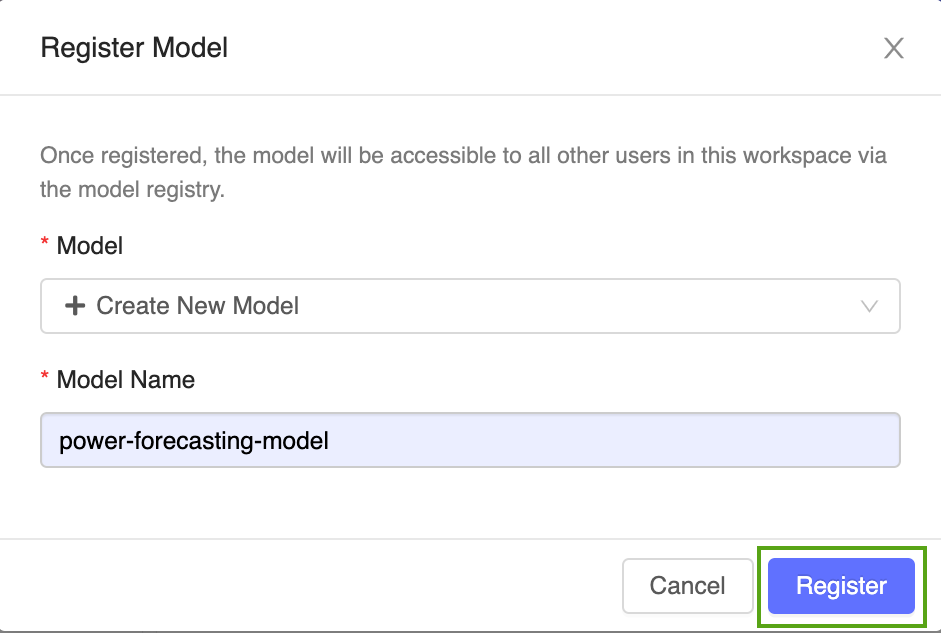
几分钟后,MLflow UI 显示一个指向新注册模型的链接。 按照此链接在 MLflow 模型注册表 UI 中打开新的模型版本。
查看模型注册表用户界面
MLflow 模型注册表 UI 中的模型版本页面提供了关于已注册的预测模型 Version 1 的信息,包括其作者、创建时间和当前阶段。
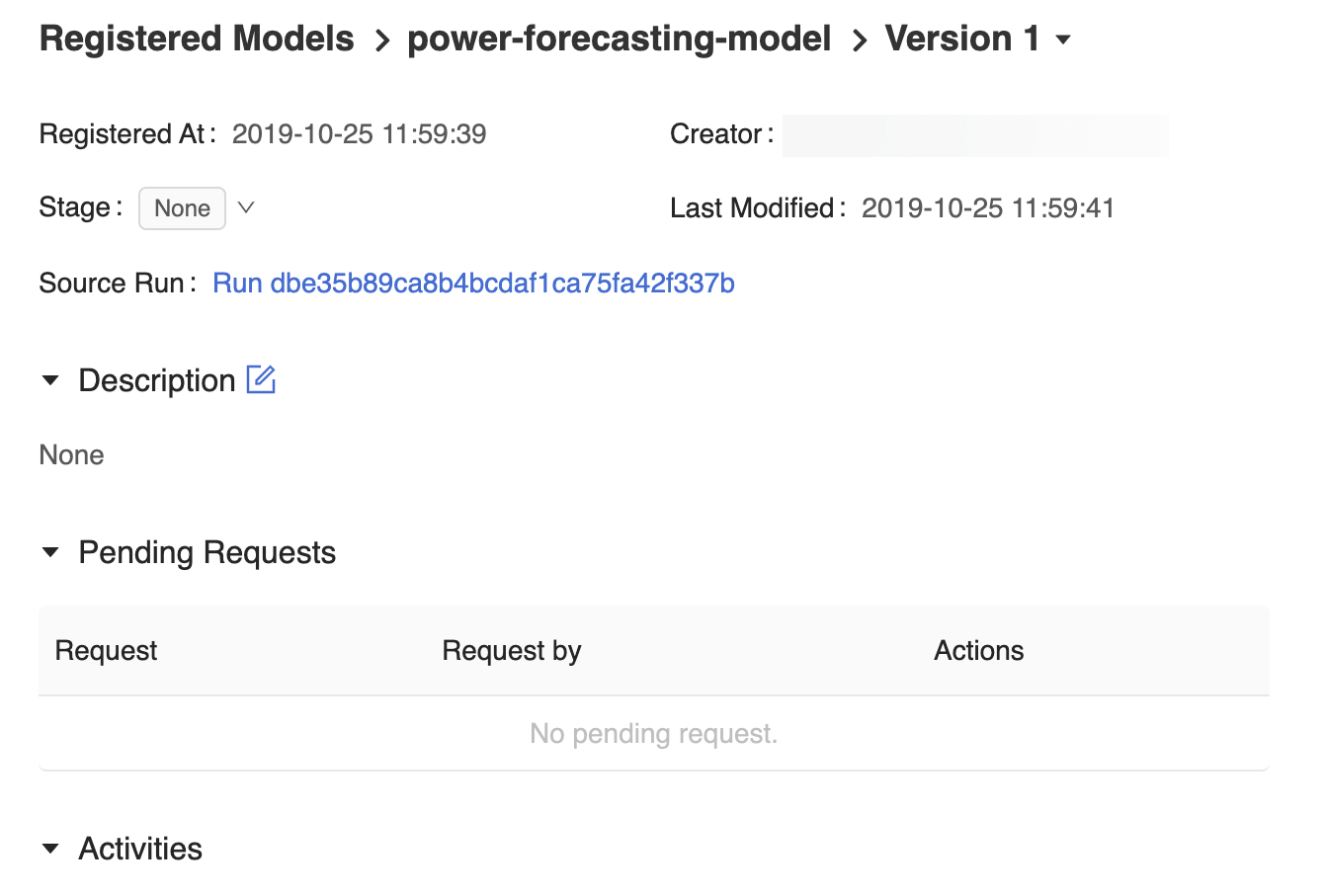
模型版本页面还提供了“源运行”链接,该链接将打开 MLflow 运行,该运行用于在 MLflow 运行 UI 中创建模型。 在 MLflow 运行 UI 中,你可以访问“源”笔记本链接,以查看用于训练模型的 Azure Databricks 笔记本的快照。


若要导航回到 MLflow 模型注册表,请单击边栏中的 ![]() “模型”。
“模型”。
生成的 MLflow 模型注册表主页会显示 Azure Databricks 工作区中所有已注册模型的列表,包括它们的版本和阶段。
单击“电力预测模型”链接打开注册模型页面,其中显示预测模型的所有版本。
添加模型说明
可以向已注册的模型和模型版本中添加说明。 注册模型说明信息有助于记录适用于多个模型版本的信息(例如,建模问题和数据集的概述)。 模型版本说明信息有助于详细说明特定模型版本的独特属性(例如,用于开发模型的方法和算法)。
添加高级描述到已注册的电力预测模型中。 单击
 图标并输入以下说明:
图标并输入以下说明:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.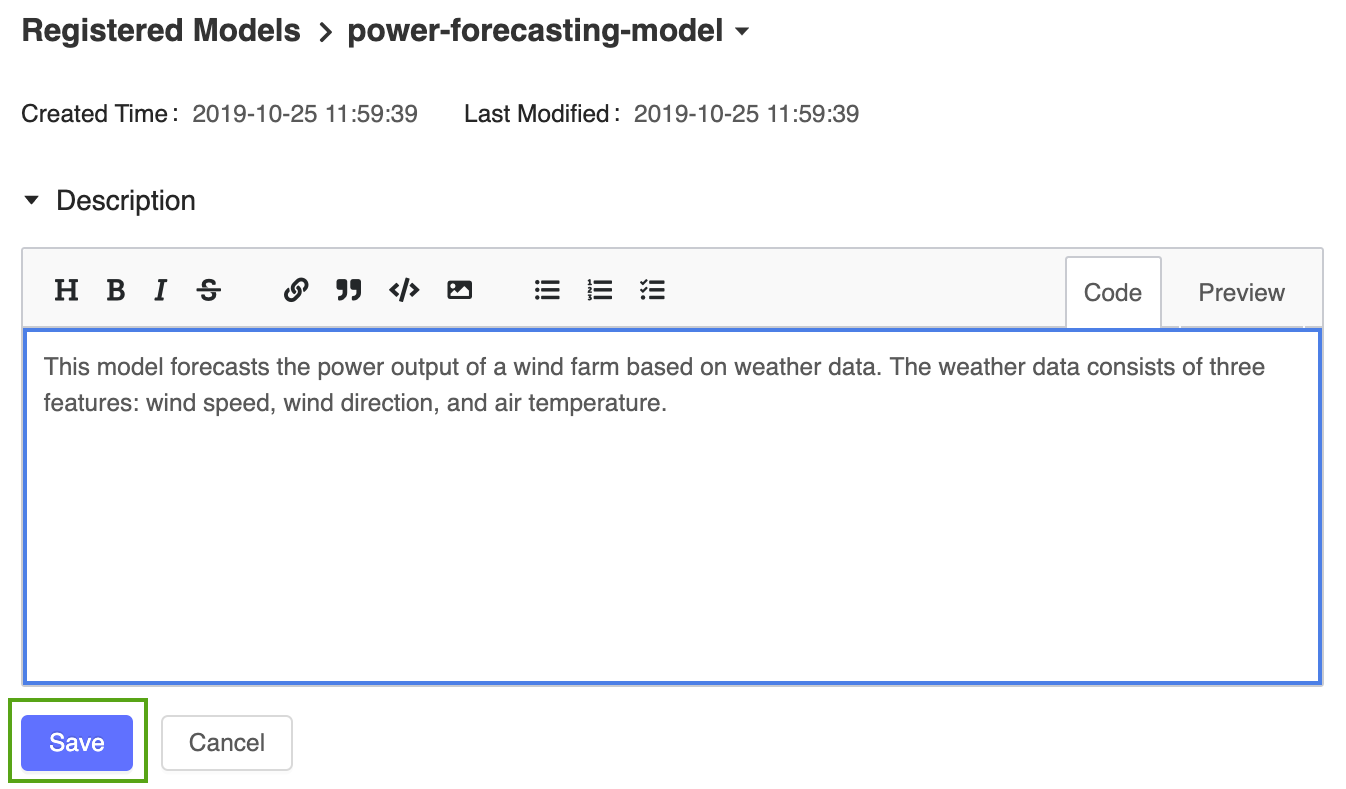
单击“保存” 。
从已注册的模型页面中单击“版本 1”链接返回到模型版本页面。
单击
图标并输入以下说明:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.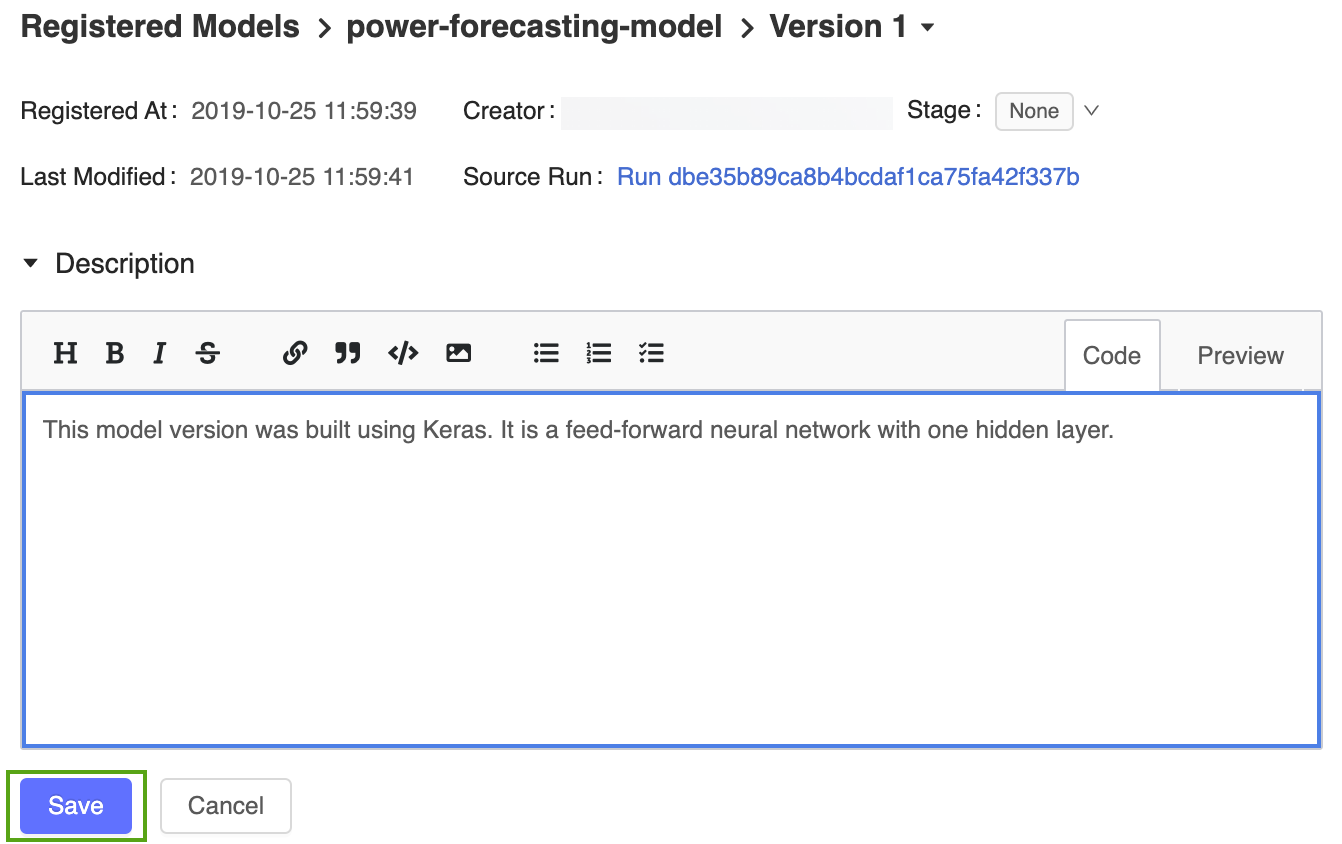
单击“保存” 。
转换模型版本
MLflow 模型注册表定义了几个模型阶段:“无指定”、“测试”、“生产”和“Archived”。 每个阶段都有唯一的含义。 例如,“暂存”指模型处于测试阶段,“生产”指模型已完成测试或审核流程,并已部署到应用程序 。
单击“阶段”按钮以显示可用模型阶段和可用阶段转换选项的列表。
选择“转换到 -> 生产”,然后在阶段转换确认窗口中按“确定”,将模型转换到“生产”。
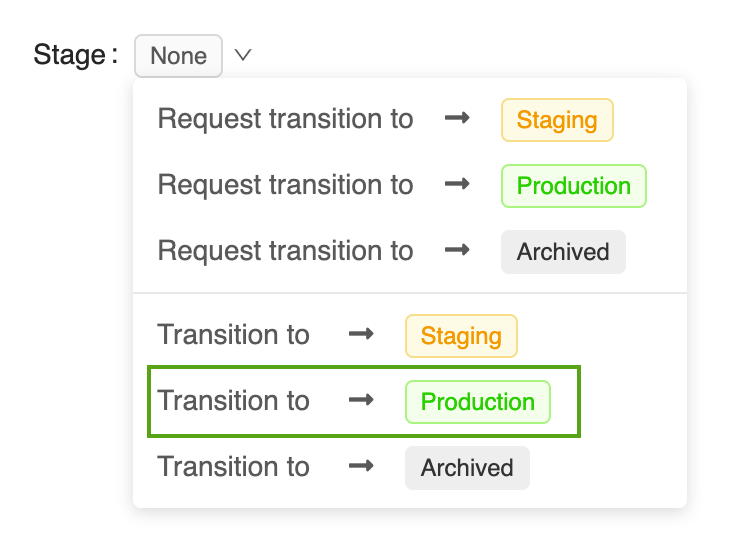
在模型版本转换到“生产”之后,当前阶段将在 UI 中显示,并在活动日志中添加一个条目以反映转换。


MLflow 模型注册表允许多个模型版本共享同一阶段。 当按阶段引用模型时,模型注册表使用最新的模型版本(版本 ID 最大的模型版本)。 注册模型页面显示特定模型的所有版本。
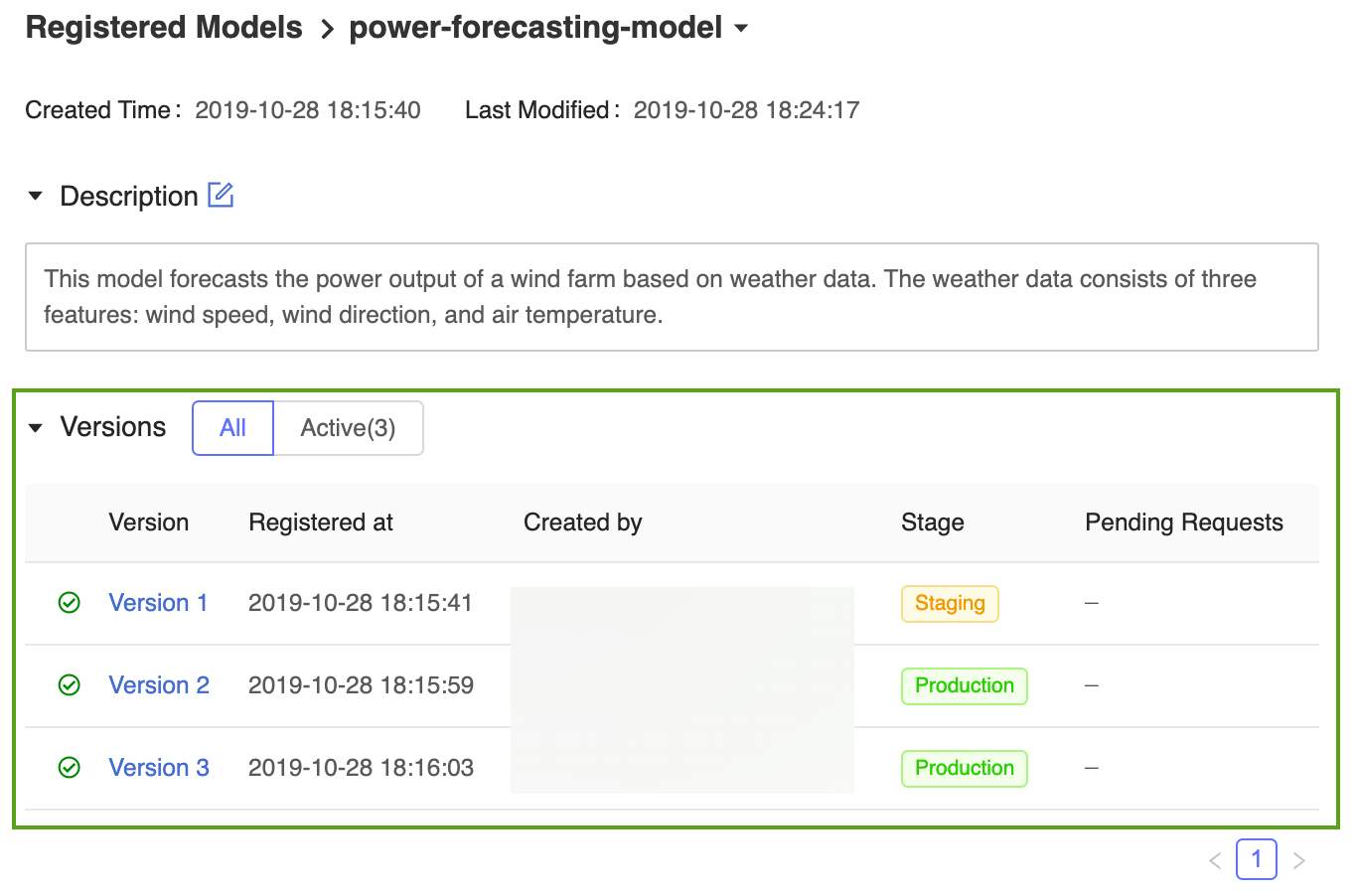
使用 MLflow API 注册和管理模型
本部分内容:
以编程方式定义模型的名称
现在模型已经注册并转换为“生产”,你可以使用 MLflow 编程 API 来引用它。 定义已注册模型的名称,如下所示:
model_name = "power-forecasting-model"
注册模型
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
使用 API 添加模型和模型版本描述
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
使用 API 转换模型版本并检索详细信息
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
使用 API 加载已注册模型的版本
MLflow 模型组件定义从多个机器学习框架加载模型的函数。 例如,mlflow.tensorflow.load_model() 用于加载以 MLflow 格式保存的 TensorFlow 模型,mlflow.sklearn.load_model() 用于加载以 MLflow 格式保存的 scikit-learn 模型。
这些函数可以从 MLflow 模型注册表加载模型。
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
用生产模型预测电力输出
在本部分中,生产模型用于评估风电场的天气预报数据。
forecast_power() 应用程序从指定的阶段加载预测模型的最新版本,并使用它来预测未来五天的发电量。
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
创建新模型版本
经典的机器学习技术对电力预测也是有效的。 下面的代码使用 scikit learn 训练随机林模型,并通过 mlflow.sklearn.log_model() 函数将其注册到 MLflow 模型注册表中。
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
使用 MLflow 模型注册表搜索获取新模型版本 ID
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
向新模型版本添加说明
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
将新模型版本转换到“暂存”阶段并测试模型
在将模型部署到生产应用程序之前,最好在暂存环境中对其进行测试。 下面的代码将新模型版本转换为“暂存”,并评估其性能。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
将新模型版本部署到生产环境
验证新模型版本在暂存中的性能良好之后,下面的代码将模型转换到“生产”阶段,并使用与用生产模型预测电力输出部分完全相同的应用程序代码生成电力预测。
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
现在,“生产”阶段的预测模型有两个版本:在 Keras 模型中训练的模型版本和在 scikit-learn 中训练的版本。
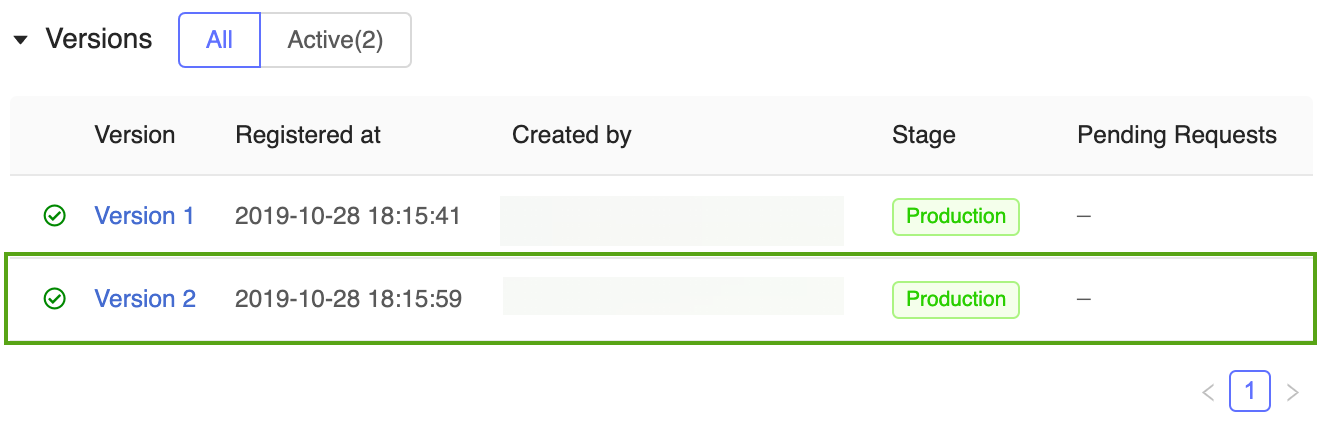
注意
当按阶段引用模型时,MLflow 模型注册表会自动使用最新的生产版本。 这使你能够在不更改任何应用程序代码的情况下更新生产模型。
存档和删除模型
当不再使用模型版本时,可以将其存档或删除。 还可以删除整个已注册模型;这将删除其所有关联的模型版本。
电力预测模型的 Version 1 存档
将电力预测模型的 Version 1 进行存档,因为不再使用。 你可以在 MLflow 模型注册表 UI 中或通过 MLflow API 对模型进行存档。
在 MLflow UI 中将 Version 1 进行存档
若要对电力预测模型的 Version 1 进行存档:
在 MLflow 模型注册表 UI 中打开其对应的模型版本页面:
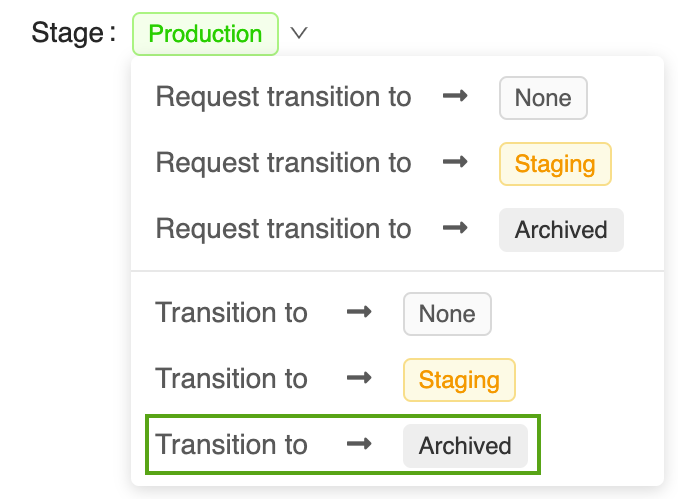
单击阶段按钮,选择转换为 -> 存档:
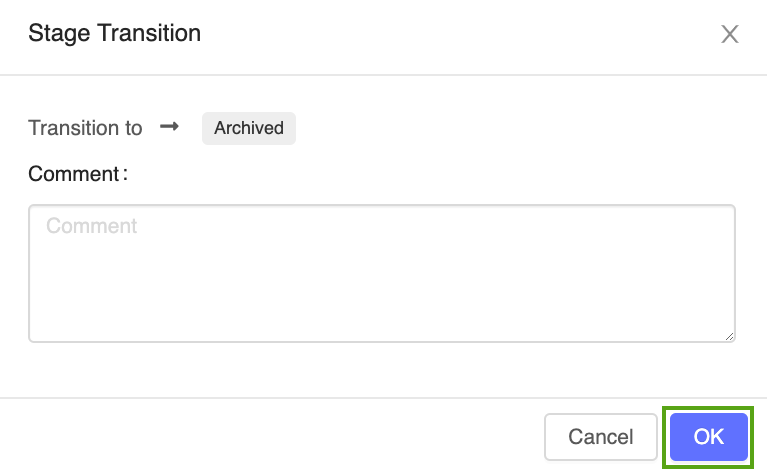
在阶段转换确认窗口中按“确定”。

使用 MLflow API 将 Version 1 进行存档
下面的代码使用 MlflowClient.update_model_version() 函数将电力预测模型的 Version 1 进行存档。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
请删除电力预测模型中的 Version 1
还可以使用 MLflow UI 或 MLflow API 删除模型版本。
警告
模型版本删除是永久性的,不能撤消。
删除 MLflow UI 中的 Version 1
删除电力预测模型的 Version 1:
在 MLflow 模型注册表 UI 中打开其对应的模型版本页面。
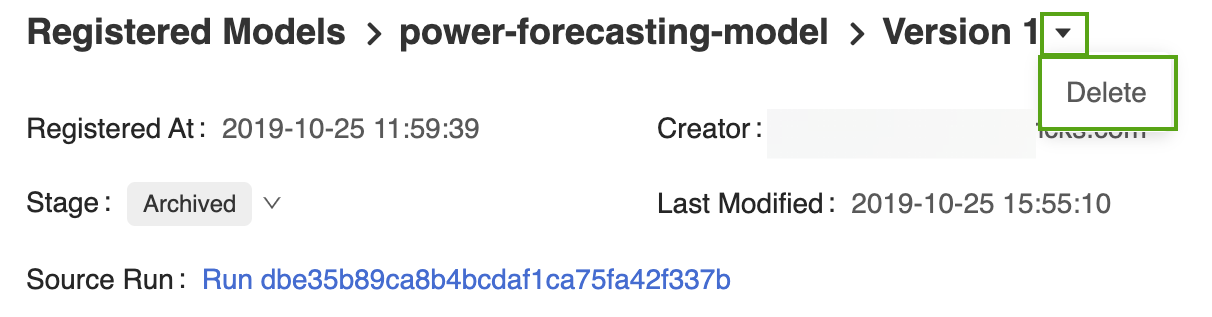
选择版本标识符旁边的下拉箭头并单击“删除”。
使用 MLflow API 删除 Version 1
client.delete_model_version(
name=model_name,
version=1,
)
使用 MLflow API 删除模型
需要首先将所有剩余的模型版本阶段转换为“无”或“已存档” 。
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)