MLflow 模型是一种用于将机器学习模型打包的标准格式,可在多种不同下游工具(例如 Apache Spark 上的批量推理或通过 REST API 提供实时服务)中使用。 该格式定义了一种约定,可以将模型保存在不同的风格(python-function、pytorch、sklearn,等等),这些风格可以被不同的模型服务和推理平台理解。
若要了解如何记录流模型并为其评分,请参阅如何保存和加载流式处理模型。
MLflow 3 通过引入具有自己的元数据(如指标和参数)的新专用 LoggedModel 对象,为 MLflow 模型引入了重要的增强功能。 有关更多详细信息,请参阅 使用 MLflow Logged Models 跟踪和比较模型。
日志和加载模型
当你记录模型时,MLflow 会自动记录 requirements.txt 和 conda.yaml 文件。 可以使用这些文件重新创建模型开发环境并使用 virtualenv(推荐)或 conda 重新安装依赖项。
重要
Anaconda Inc. 为 anaconda.org 通道更新了其服务条款。 根据新的服务条款,如果依赖 Anaconda 的打包和分发,则可能需要商业许可证。 有关详细信息,请参阅 Anaconda Commercial Edition 常见问题解答。 您对任何 Anaconda 频道的使用都受其服务条款的约束。
在 v1.18(Databricks Runtime 8.3 ML 或更低版本)之前记录的 MLflow 模型默认以 conda defaults 通道 (https://repo.anaconda.com/pkgs/) 作为依赖项进行记录。 由于许可证的变更,Databricks 已停止使用 defaults 通道来记录使用 MLflow v1.18 及以上版本的模型。 记录的默认通道现在为 conda-forge,它指向社区管理的 https://conda-forge.org/。
如果在 MLflow v1.18 之前记录了一个模型,但没有从模型的 conda 环境中排除 defaults 通道,则该模型可能依赖于你可能没有预期到的 defaults 通道。
若要手动确认模型是否具有此依赖项,可以检查与记录的模型一起打包的 channel 文件中的 conda.yaml 值。 例如,具有 conda.yaml 通道依赖项的模型 defaults 可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由于 Databricks 无法确定是否允许你根据你与 Anaconda 的关系使用 Anaconda 存储库来与模型交互,因此 Databricks 不会强制要求其客户进行任何更改。 如果允许你根据 Anaconda 的条款通过 Databricks 使用 Anaconda.com 存储库,则你不需要采取任何措施。
若要更改模型环境中使用的通道,可以使用新的 conda.yaml 将模型重新注册到模型注册表。 为此,可以在 conda_env 的 log_model() 参数中指定该通道。
有关 log_model() API 的详细信息,请参阅所用模型风格的 MLflow 文档,例如用于 scikit-learn 的 log_model。
有关 conda.yaml 文件的详细信息,请参阅 MLflow 文档。
API 命令
若要将模型记录到 MLflow 跟踪服务器,请使用 mlflow.<model-type>.log_model(model, ...)。
若要加载先前记录的模型用于推理或进一步的开发,请使用 mlflow.<model-type>.load_model(modelpath),其中 modelpath 是以下项之一:
- 模型路径(例如
models:/{model_id},仅用于 MLflow 3) - 运行相对路径(例如
runs:/{run_id}/{model-path}) - Unity Catalog 存储卷路径(例如
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - 以
dbfs:/databricks/mlflow-tracking/开头的 MLflow 管理的工件存储路径 -
已注册的模型路径(例如
models:/{model_name}/{model_stage})。
有关用于加载 MLflow 模型的完整选项的列表,请参阅MLflow 文档中的“引用项目”。
对于 Python MLflow 模型,一个附加选项是使用 mlflow.pyfunc.load_model() 将模型加载为泛型 Python 函数。
可使用以下代码片段来加载模型并为数据点评分。
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
或者,您可以将模型导出为 Apache Spark UDF,以便在 Spark 集群上进行评分,无论是作为批处理作业还是实时 Spark 流式处理作业。
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
日志模型依赖项
若要准确加载模型,应确保模型依赖项以正确的版本加载到笔记本环境中。 在 Databricks Runtime 10.5 ML 及更高版本中,MLflow 会在检测到当前环境和模型的依赖项之间不匹配时发出警告。
Databricks Runtime 11.0 ML 及更高版本中包含用于简化还原模型依赖项的其他功能。 在 Databricks Runtime 11.0 ML 及更高版本中,对于 pyfunc 风格模型,可以调用 mlflow.pyfunc.get_model_dependencies 来检索和下载模型依赖项。 此函数返回依赖项文件的路径,然后可以使用 %pip install <file-path> 安装该文件。 将模型加载为 PySpark UDF 时,请在 env_manager="virtualenv" 调用中指定 mlflow.pyfunc.spark_udf。 这会在 PySpark UDF 的上下文中还原模型依赖项,并且不会影响外部环境。
在 Databricks Runtime 10.5 或更早版本中,还可通过手动安装 MLflow 版本 1.25.0 或更高版本来使用此功能:
%pip install "mlflow>=1.25.0"
有关如何记录模型依赖性(Python 和非 Python)和项目的更多信息,请参阅记录模型依赖性。
了解如何为模型服务记录模型依赖项和自定义项目:
MLflow UI 中自动生成的代码片段
在 Azure Databricks 笔记本中记录模型时,Azure Databricks 会自动生成代码片段,你可以复制这些代码片段并使用它们来加载和运行模型。 若要查看这些代码片段,请执行以下操作:
请导航到生成模型的实验运行页面。 (有关如何显示“运行”屏幕,请参阅查看笔记本试验。)
滚动到“工件”部分。
单击已记录的模型的名称。 右侧会打开一个面板,其中显示了可用于加载已记录的模型并在 Spark 或 Pandas 数据帧上进行预测的代码。
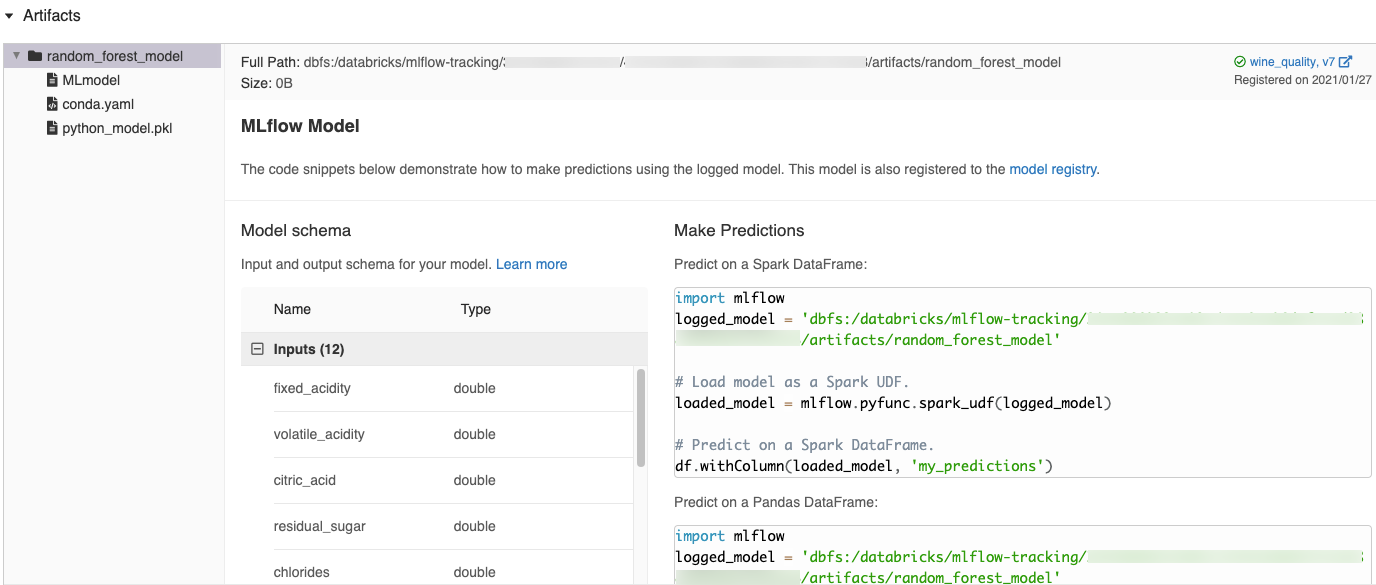
示例
有关日志记录模型的示例,请参阅跟踪机器学习训练运行示例中的示例。
在模型注册表中注册模型
可以在 MLflow 模型注册表中注册模型,该注册表是一个集中的模型存储,它提供了 UI 和一组 API 来管理 MLflow 模型的完整生命周期。 有关如何使用模型注册表管理 Azure Databricks Unity Catalog 中的模型的说明,请参阅在 Unity Catalog 中管理模型生命周期。 若要使用工作区模型注册表,请参阅使用工作区模型注册表(旧版)管理模型生命周期。
使用 MLflow 3 创建的模型注册到 Unity 目录模型注册表时,可以在一个中心位置查看所有试验和工作区中的参数和指标等数据。 有关信息,请参阅 MLflow 3 的模型注册表改进。
若要使用 API 注册模型,请使用以下命令:
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
将模型保存到 Unity Catalog 卷
若要在本地保存模型,请使用 mlflow.<model-type>.save_model(model, modelpath)。
modelpath 必须是 Unity Catalog 卷 的路径。 例如,如果使用 Unity Catalog 卷位置 dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models 来存储项目工作,则必须使用模型路径 /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
对于 MLlib 模型,请使用 ML 管道。
下载模型工件
可以使用各种 API 下载已注册的模型的已记录模型项目(例如模型文件、绘图和指标)。
Python API 示例:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Java API 示例:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI 命令示例:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
部署用于在线服务的模型
注释
在部署模型之前,验证模型是否能够提供服务是有益的。 请参阅 MLflow 文档,了解如何在部署 之前使用 mlflow.models.predict 来验证模型。