MLflow 中的评估数据集定义用于评估 GenAI 应用的结构化测试数据: inputs、可选的地实 expectations和世系字段,例如源和标记。 此页面记录数据集架构,并链接到最常用的 SDK 方法和类。
有关如何使用评估数据集的一般信息和示例,请参阅 开发期间评估 GenAI 应用。
评估数据集架构
评估数据集必须使用本节中所述的架构。
核心字段
评估数据集抽象或直接传递数据时使用以下字段。
| 列 | 数据类型 | Description | 必选 |
|---|---|---|---|
inputs |
dict[Any, Any] |
应用的输入(例如用户问题、上下文),存储为 JSON 可序列化的dict。 |
是的 |
expectations |
dict[Str, Any] |
真实数据标签,存储为 JSON 可序列化的 dict。 |
可选 |
expectations 保留密钥
expectations 具有由内置 LLM 法官使用的多个保留密钥: guidelines, expected_facts以及 expected_response。
| 领域 | 使用者 | Description |
|---|---|---|
expected_facts |
Correctness 法官 |
应显示的事实列表 |
expected_response |
Correctness 法官 |
确切或类似的预期输出 |
guidelines |
Guidelines 法官 |
要遵循的自然语言规则 |
expected_retrieved_context |
document_recall 得分手 |
应检索的文档 |
其他字段
评估数据集抽象使用以下字段来跟踪世系和版本历史记录。
| 列 | 数据类型 | Description | 必选 |
|---|---|---|---|
dataset_record_id |
字符串 | 记录的唯一标识符。 | 如果未提供,则自动设置。 |
create_time |
时间戳 | 创建记录的时间。 | 插入或更新时自动设置。 |
created_by |
字符串 | 创建记录的用户。 | 插入或更新时自动设置。 |
last_update_time |
时间戳 | 上次更新记录的时间。 | 插入或更新时自动设置。 |
last_updated_by |
字符串 | 上次更新记录的用户。 | 插入或更新时自动设置。 |
source |
结构 | 数据集记录的源。 请参阅 “源”字段。 | 可选 |
tags |
dict[str, Any] | 数据集记录的键值标记。 | 可选 |
源字段
字段 source 跟踪数据集记录来自何处。 每个记录只能有 一个 源类型。
人源:人员手动创建的记录
{
"source": {
"human": {
"user_name": "jane.doe@company.com" # user who created the record
}
}
}
文档源:从文档合成的记录
{
"source": {
"document": {
"doc_uri": "s3://bucket/docs/product-manual.pdf", # URI or path to the source document
"content": "The first 500 chars of the document..." # Optional, excerpt or full content from the document
}
}
}
跟踪源:从生产跟踪创建的记录
{
"source": {
"trace": {
"trace_id": "tr-abc123def456". # unique identifier of the source trace
}
}
}
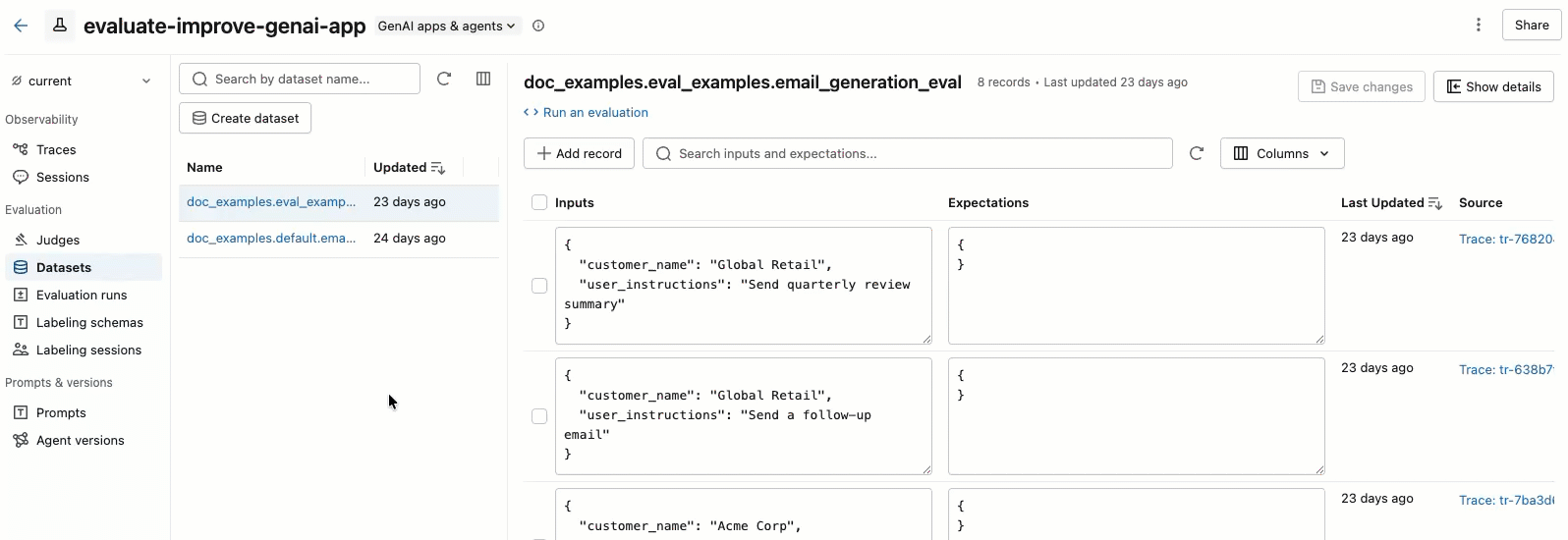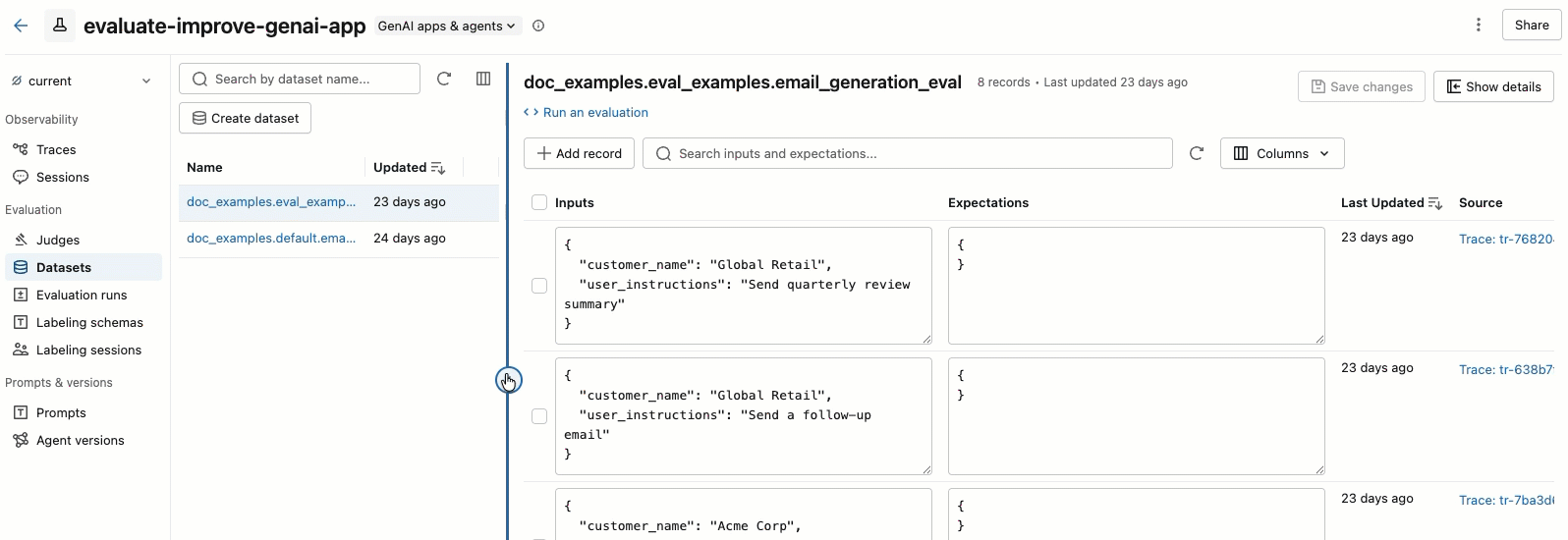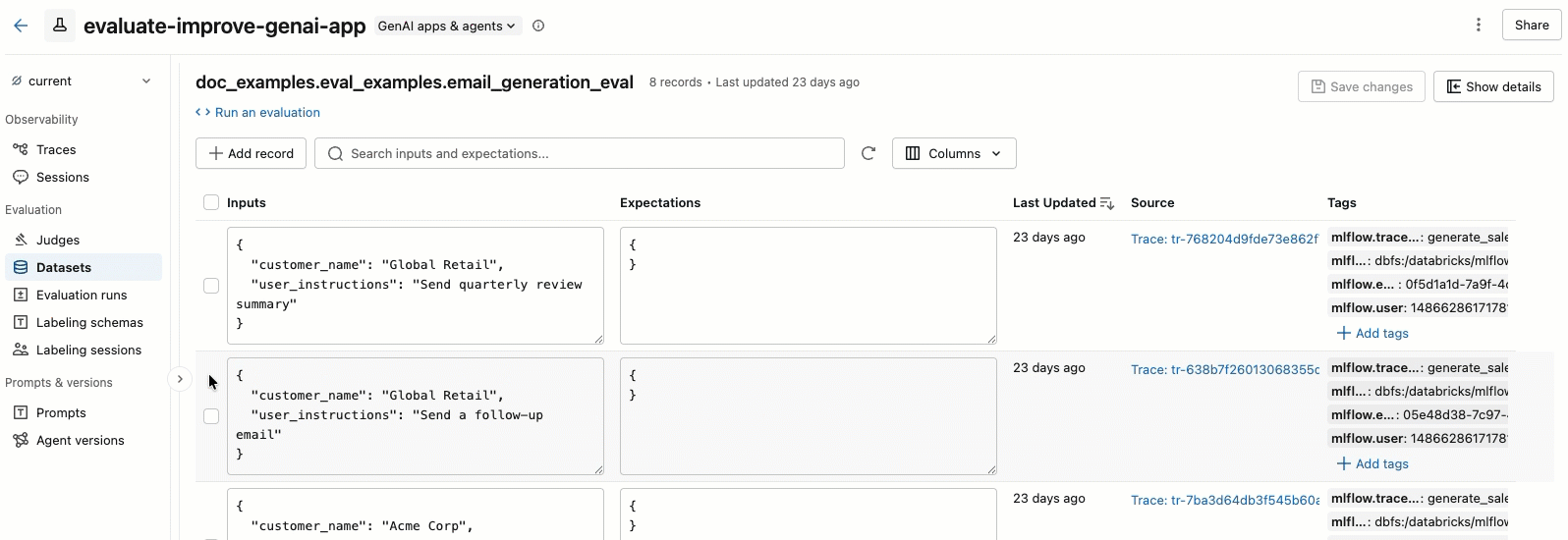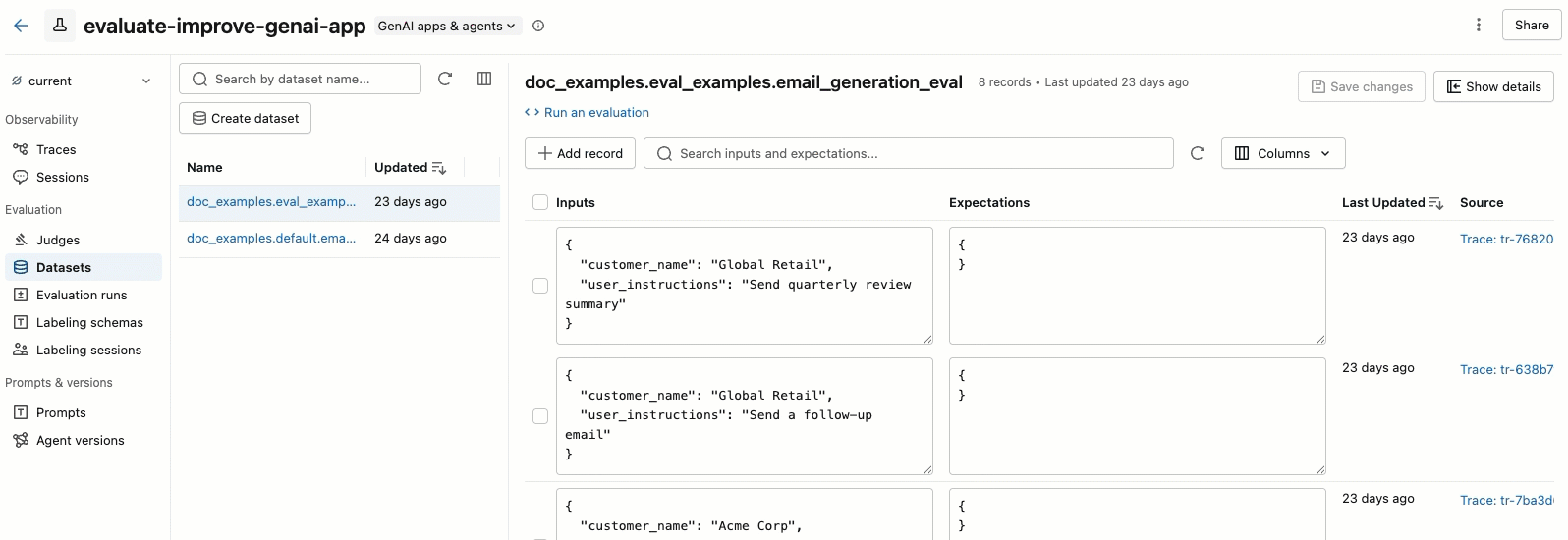
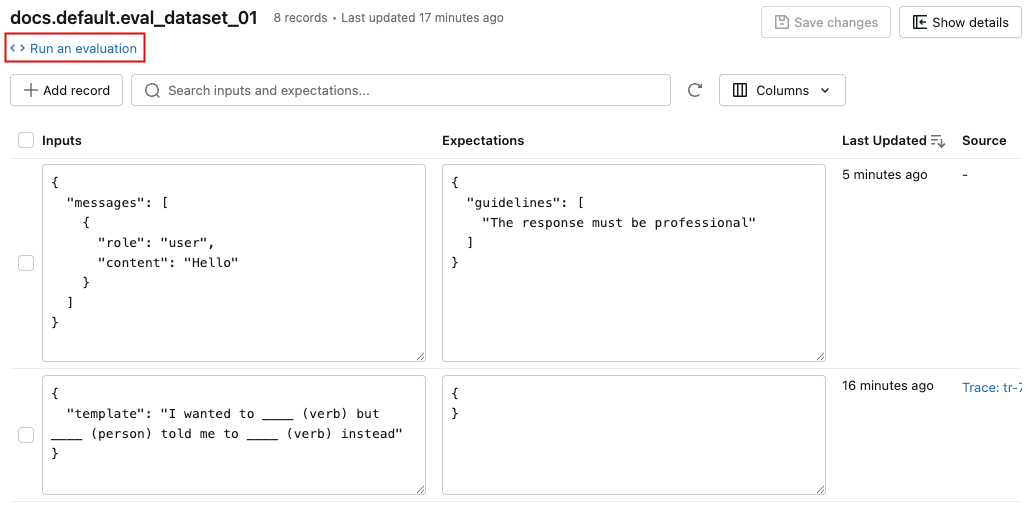
MLflow 评估数据集 UI
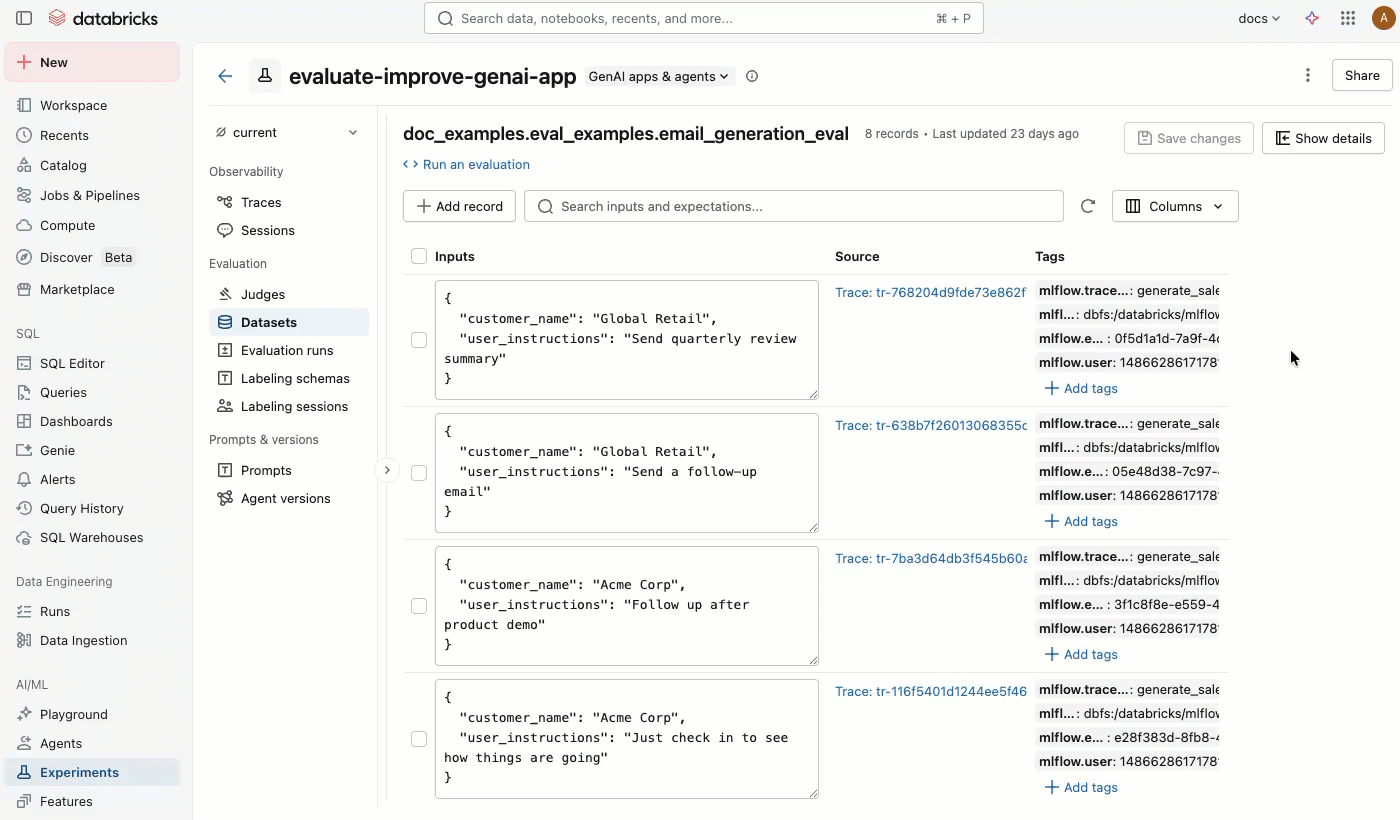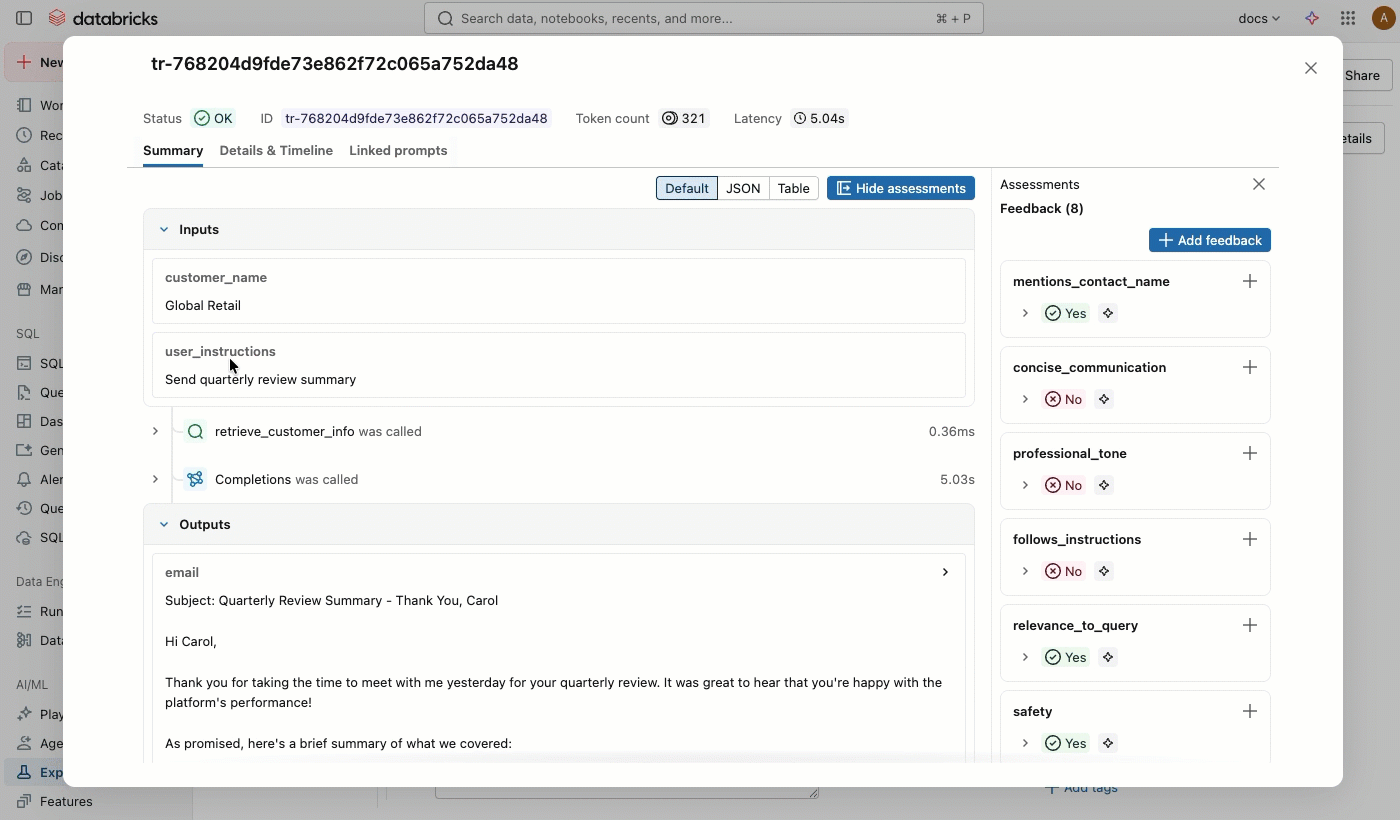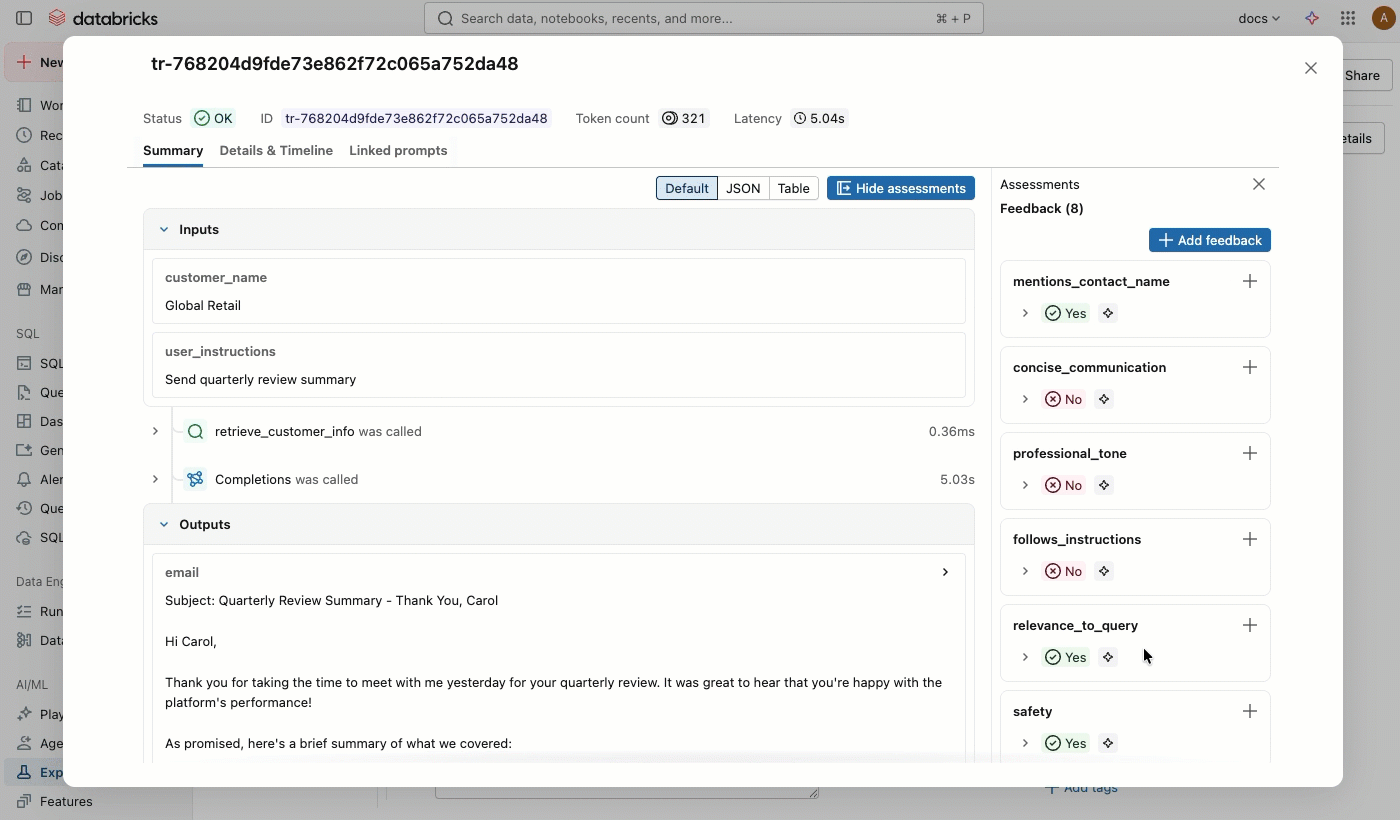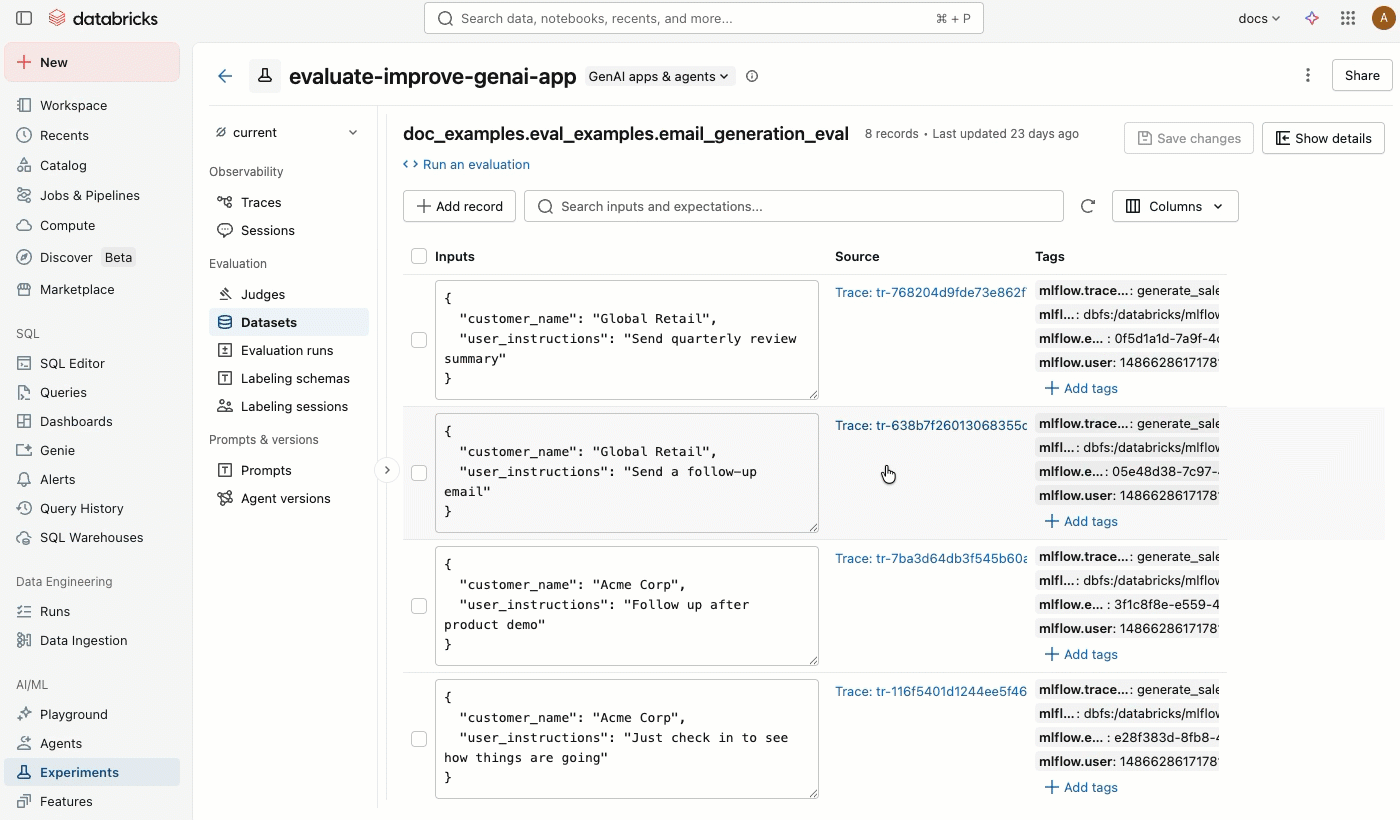
MLflow 试验页中的 “数据集 ”选项卡提供用于管理评估数据集及其记录的可视化界面。 页面使用拆分窗格布局:左窗格列出与试验关联的所有评估数据集,右窗格显示所选数据集的记录。 可以直接从 UI 搜索、排序、创建、编辑和删除数据集和记录,而无需编写任何代码。
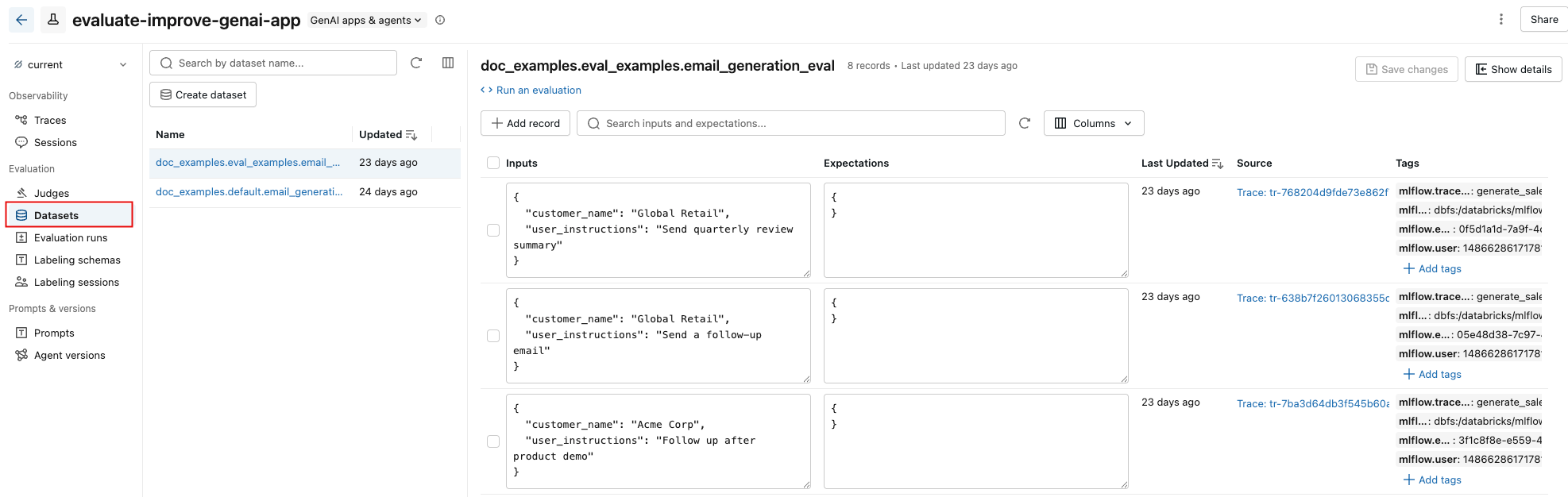
在右窗格中,可以编辑记录输入和期望,将标记添加到单个记录,查看从生产跟踪创建的记录的源跟踪,并获取一个现成的 Python 代码片段,以便针对数据集运行评估。
评估数据集 UI 概述
在边栏中,单击“ 试验 ”并打开实验。
单击“ 数据集 ”选项卡。左窗格显示此试验的所有评估数据集。 默认情况下,数据集按上次更新时间进行排序。 使用搜索栏按数据集名称进行筛选。
单击数据集名称,在右窗格中查看其记录。 可能需要向右和向左滚动才能查看所有列。
若要放大右窗格,请将鼠标悬停在窗格分隔符上,然后单击向左箭头。 再次单击箭头以返回到默认视图。
若要选择显示的列,请单击“ 列” 按钮。 选中或取消选中复选框。 完成后,单击下拉菜单中的任意位置。

创建评估数据集
在“ 数据集 ”选项卡上,单击“ 创建数据集”。
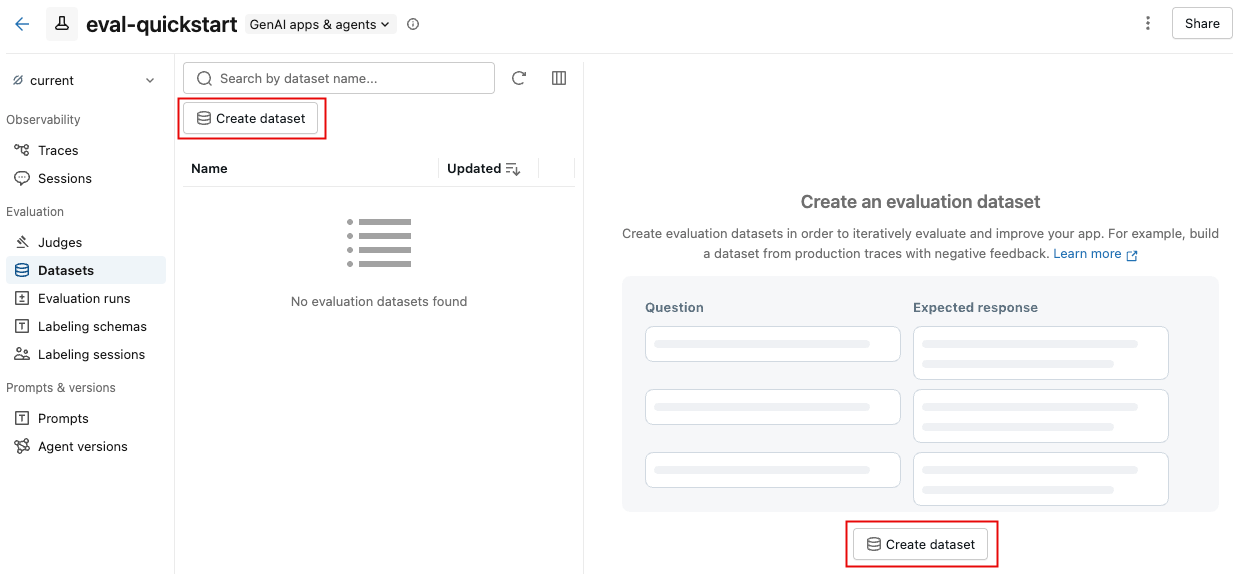
在对话框中,单击 “选择架构” 以选择你拥有
CREATE TABLE权限的 Unity 目录架构。输入数据集的表名称。 完整数据集名称(
catalog.schema.table_name)的预览显示在输入下方。单击“ 创建数据集”。
添加数据集记录
若要将现有跟踪添加到评估数据集,请参阅 使用 UI 创建数据集。
编辑数据集记录
视频演示以下步骤:
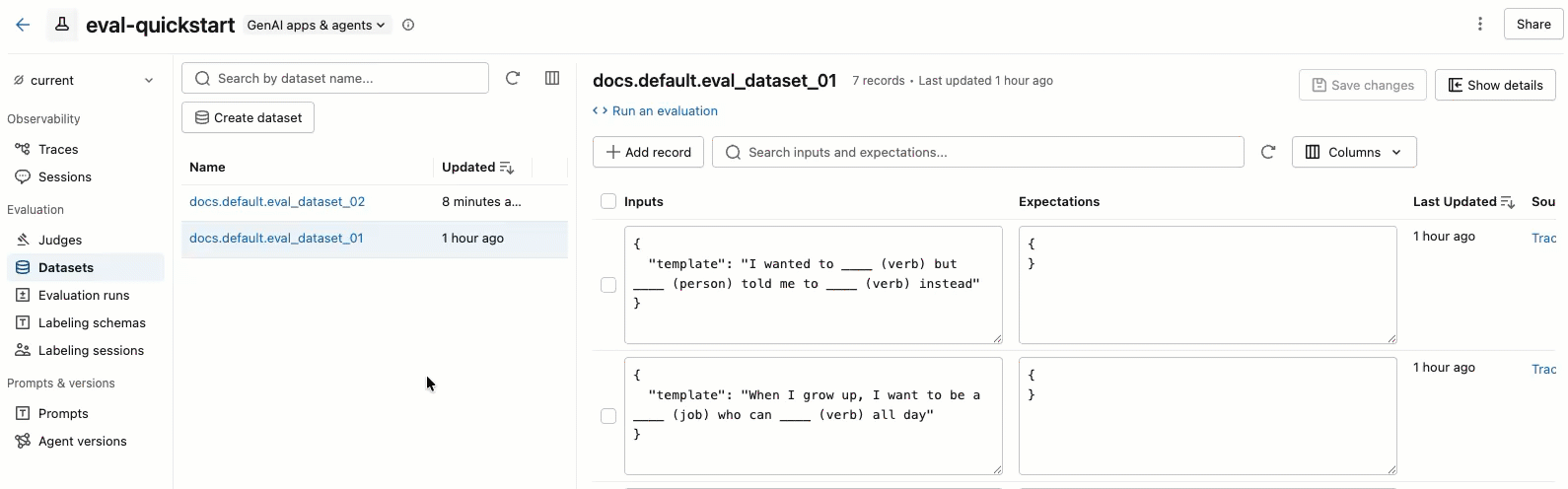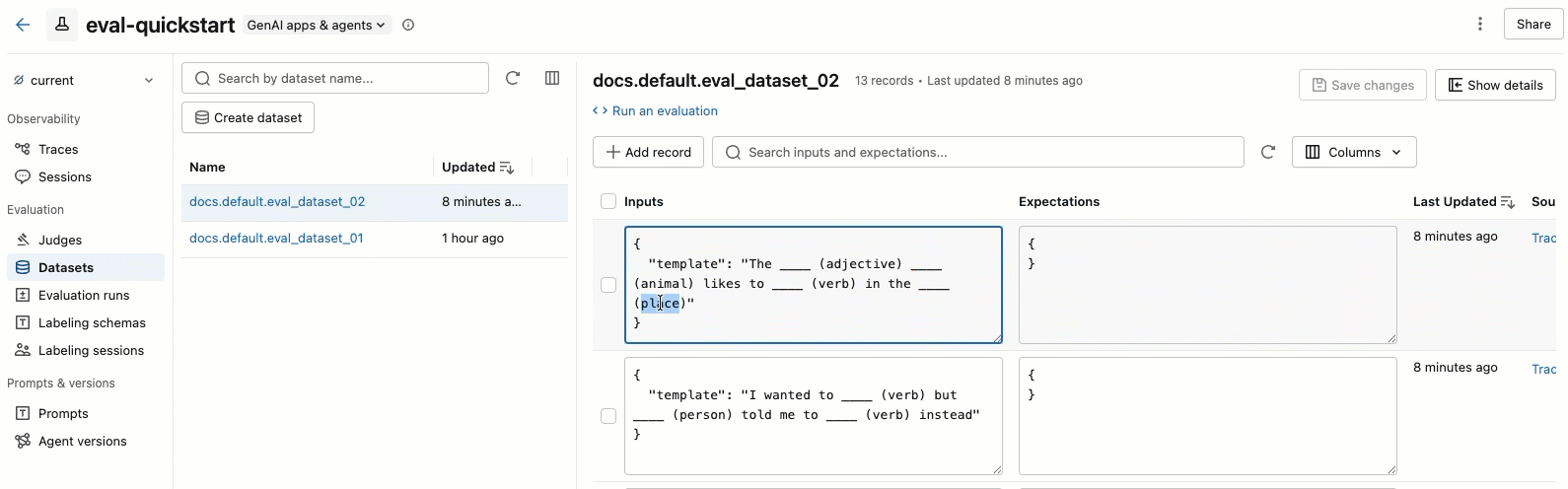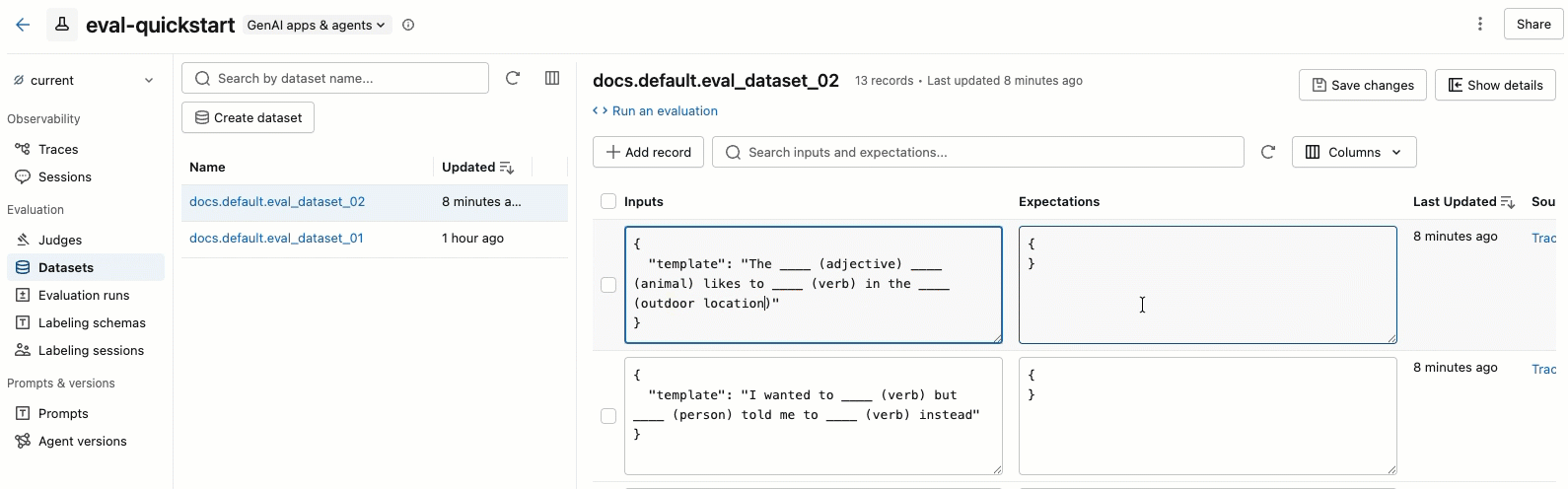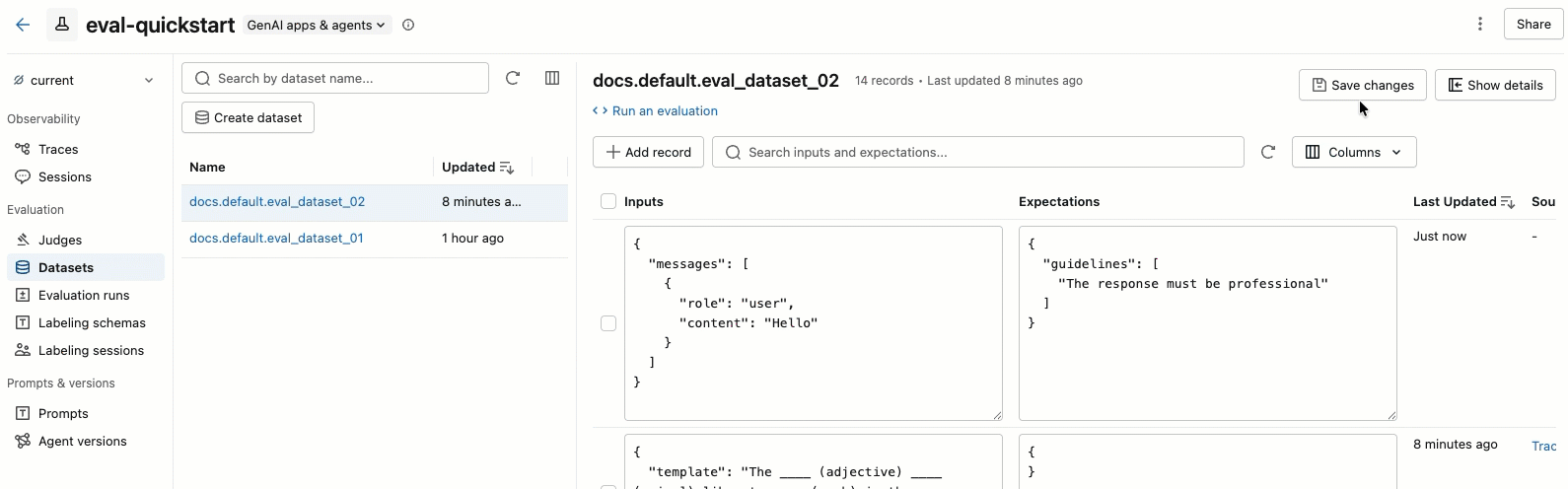
- 在左窗格中选择数据集以查看其记录。
- 可以直接在表中编辑 “输入 ”和 “期望值 ”字段。 这些字段接受 JSON 并在键入时验证输入。
- 若要添加新行,请单击“ 添加记录”。 具有默认值的新行显示在表顶部。
- 若要保存所有挂起的编辑,请单击右上角的“ 保存更改 ”。
删除记录或数据集
- 若要删除记录,请使用复选框选择一个或多个记录,然后单击“删除”(N)。
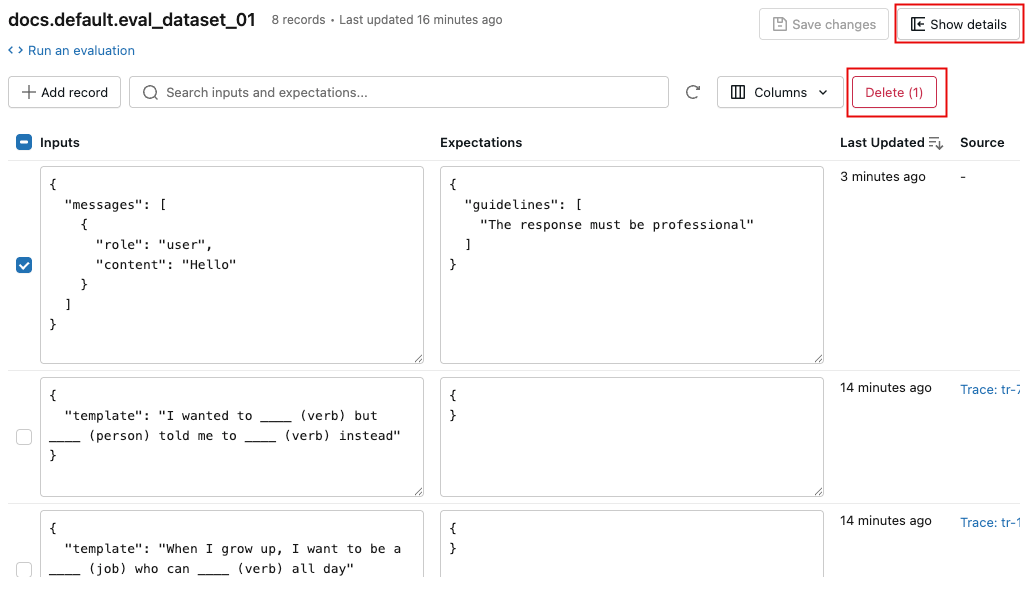
- 若要删除数据集,请单击“ 显示详细信息 ”以打开详细信息窗格,然后单击窗格底部的 “删除数据集 ”。 还可以从烤肉串菜单
 中删除数据集。在数据集列表中。
中删除数据集。在数据集列表中。
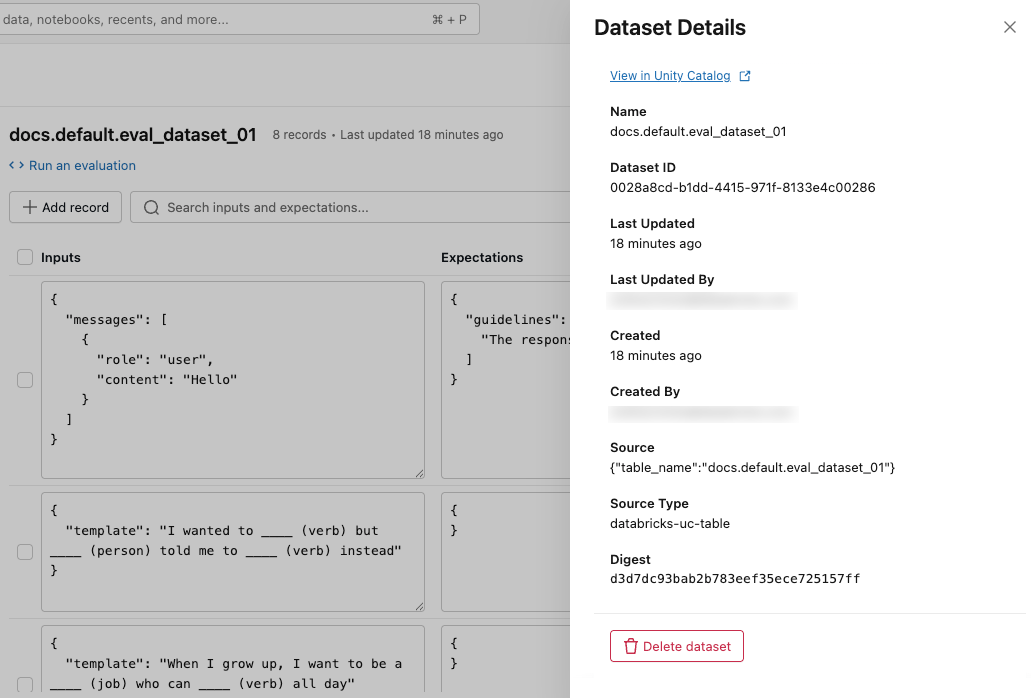
查看数据集详细信息
若要查看数据集的元数据,请单击右上角的“ 显示详细信息 ”。 此时会打开一个窗格,包括数据集名称、ID、创建时间、上次更新、源以及用于在 Unity 目录中查看数据集的链接。
添加和删除标记
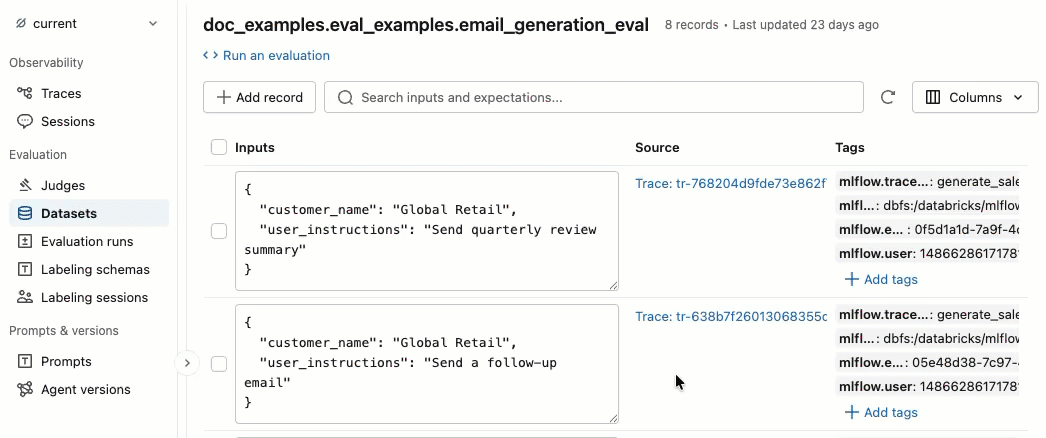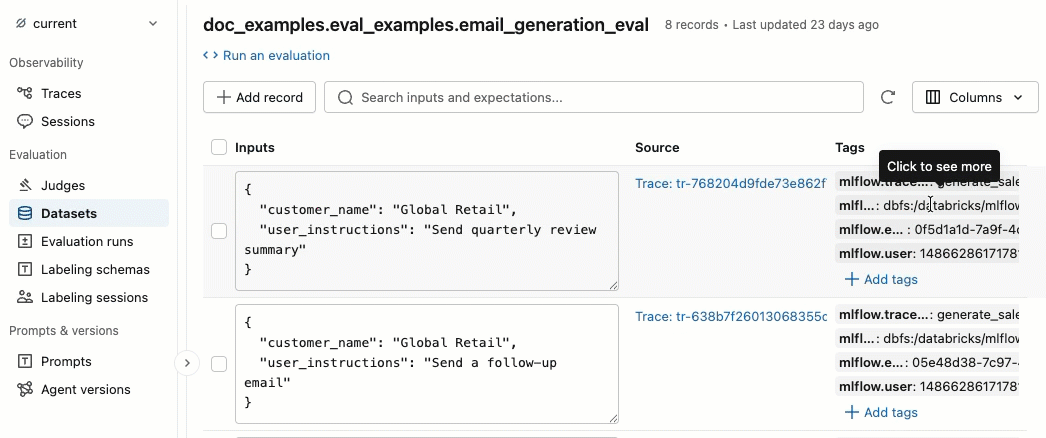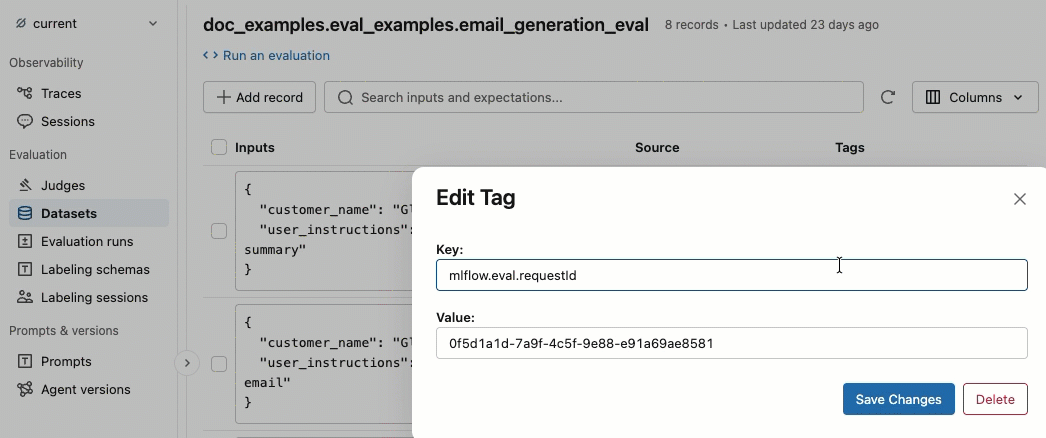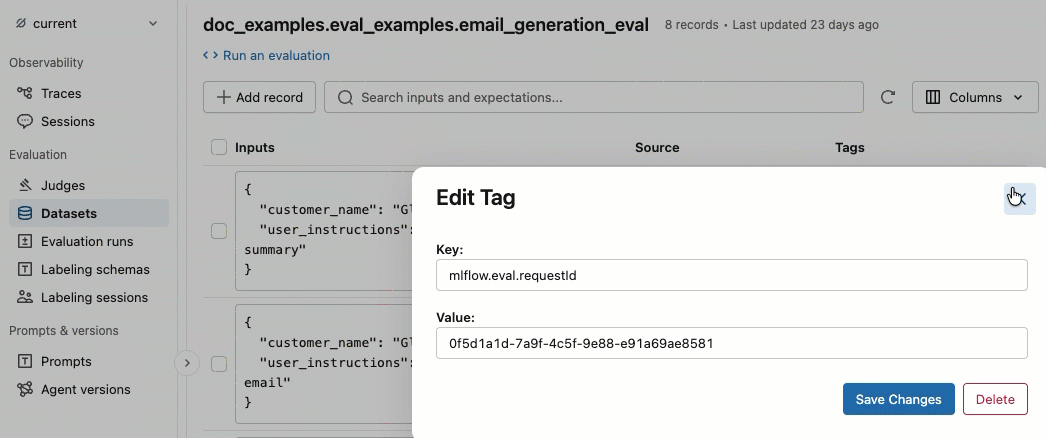
在 “标记 ”列中,单击标记以对其进行编辑,或单击“ 添加标记 ”以添加新标记。
查看源跟踪
在 “源 ”列中,单击跟踪以打开显示完整跟踪和评估的交互式窗口。
使用数据集运行评估
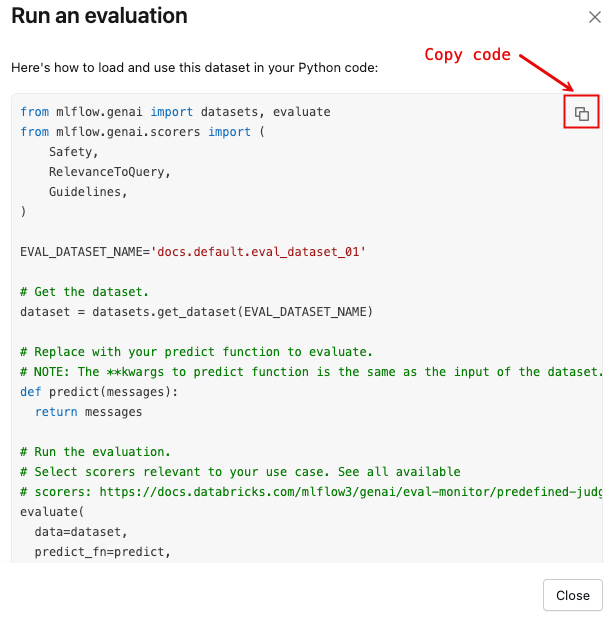
若要使用 Python 代码模板打开对话框,该模板加载数据集并使用默认的评分器集运行 mlflow.genai.evaluate() :
单击“ 运行评估”。
单击下图中显示的复制图标,将代码片段复制到剪贴板。
MLflow 评估数据集 SDK 参考
评估数据集 SDK 提供编程访问,用于创建、管理和使用用于 GenAI 应用评估的数据集。 有关详细信息,请参阅 API 参考: mlflow.genai.datasets 下面是一些最常用的方法和类: