该 mlflow.genai.evaluate() 函数为 GenAI 应用程序提供评估工具。 MLflow 评估提供了一种结构化方法,可以输入测试数据,运行应用并自动评分结果,从而避免手动运行应用程序并逐个检查输出。 这样,可以更轻松地比较版本、跟踪改进并跨团队共享结果。
MLflow 评估将离线测试与生产环境监控连接。 这意味着在开发中使用的相同评估逻辑也可以在生产环境中运行,从而在整个 AI 生命周期中提供一致的质量视图。
该 mlflow.genai.evaluate() 函数通过运行评估数据集和应用记分器系统地测试 GenAI 应用的质量。
如果你不熟悉评估,请从 10 分钟的演示开始:评估 GenAI 应用。
何时使用
- 对应用进行针对特选评估数据集的每晚或每周检查
- 验证不同应用版本的提示或模型更改
- 在发布或 PR 之前防止质量回归
快速参考
该 mlflow.genai.evaluate() 函数使用指定的记分器以及预测函数或模型 ID(可选)对评估数据集运行 GenAI 应用,并返回一个 EvaluationResult。
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
- 有关 API 详细信息,请参阅参数 或
mlflow.genai.evaluate()MLflow 文档。 - 有关详细信息
EvaluationDataset,请参阅 生成 MLflow 评估数据集。 - 有关评估运行和日志记录的详细信息,请参阅 评估运行。
要求
安装 MLflow 和所需的包。
pip install --upgrade "mlflow[databricks]>=3.1.0" openai "databricks-connect>=16.1"请按照设置环境快速入门创建 MLflow 试验。
(可选)配置并行化
默认情况下,MLflow 使用后台线程池来加快评估过程。 若要配置辅助角色数,请设置环境变量 MLFLOW_GENAI_EVAL_MAX_WORKERS。
export MLFLOW_GENAI_EVAL_MAX_WORKERS=10
评估模式
有两种评估模式:
直接评估(建议)。 MLflow 直接调用应用程序以生成用于评估的追踪记录。
- 在测试输入上运行应用程序,捕获 追踪记录。
- 应用 评分员或 LLM 评委 来评估质量,从而创建 反馈。
- 将结果存储在活动 MLflow 试验中的 评估运行 中。
答题卡评估。 您提供预先计算的输出或现有的跟踪以进行评估。
- 应用 评分器或 LLM 评审 来评估预计算输出或 追踪数据的质量,并创建 反馈。
- 将结果存储在活动 MLflow 试验中的 评估运行 中。
直接评估(建议)
MLflow 直接调用 GenAI 应用程序,以生成和评估轨迹。 可以传递 Python 函数中包装的应用程序的入口点 (predict_fn),或者,如果将应用部署为 Databricks 模型服务终结点,则传递 to_predict_fn 中包装的终结点。
通过直接调用应用,此模式使你能够重复使用在 生产监视 中为脱机评估定义的记分器,因为生成的跟踪将相同。
如图所示,数据、应用程序和所选评分器作为输入提供给mlflow.genai.evaluate(),在其中应用程序和评分器并行运行,并将输出记录为跟踪和反馈。
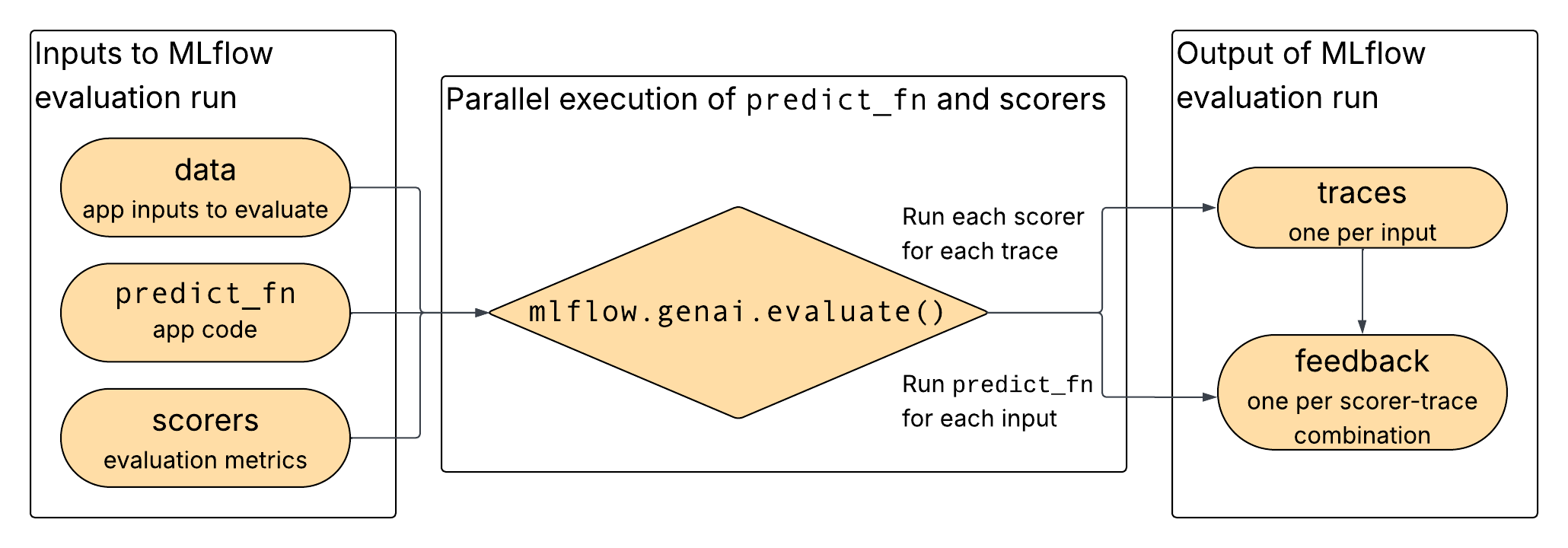
用于直接评估的数据格式
有关架构详细信息,请参阅 评估数据集参考。
| 领域 | 数据类型 | 必选 | Description |
|---|---|---|---|
inputs |
dict[Any, Any] |
是的 | 传递给 predict_fn 的字典 |
expectations |
dict[str, Any] |
否 | 评分器的可选基本事实 |
使用直接评估的示例
以下代码演示了如何运行评估的示例:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
# Your GenAI app with MLflow tracing
@mlflow.trace
def my_chatbot_app(question: str) -> dict:
# Your app logic here
if "MLflow" in question:
response = "MLflow is an open-source platform for managing ML and GenAI workflows."
else:
response = "I can help you with MLflow questions."
return {"response": response}
# Evaluate your app
results = mlflow.genai.evaluate(
data=[
{"inputs": {"question": "What is MLflow?"}},
{"inputs": {"question": "How do I get started?"}}
],
predict_fn=my_chatbot_app,
scorers=[RelevanceToQuery(), Safety()]
)
限制模型调用速率
在评估具有速率限制的模型(例如第三方 API 或基础模型终结点)时,应使用速率限制逻辑对预测函数进行包装。 此示例使用库 ratelimit:
import mlflow
from mlflow.genai.scorers import RelevanceToQuery, Safety
from ratelimit import limits, sleep_and_retry
# You can replace this with your own predict_fn
predict_fn = mlflow.genai.to_predict_fn("endpoints:/databricks-gpt-oss-20b")
@sleep_and_retry
@limits(calls=10, period=60) # 10 calls per minute
def rate_limited_predict_fn(*args, **kwargs):
return predict_fn(*args, **kwargs)
results = mlflow.genai.evaluate(
data=[{"inputs": {"messages": [{"role": "user", "content": "How does MLflow work?"}]}}],
predict_fn=predict_fn,
scorers=[RelevanceToQuery(), Safety()]
)
上述速率限制控制对 predict_fn 的调用。 用于评估代理的工作线程数也可以通过配置并行化来控制。
答卷评估
在评估期间无法或不想直接运行 GenAI 应用时,请使用此模式。 例如,你已有输出(例如,来自外部系统、历史跟踪或批处理作业),并且只想对其进行评分。 您提供输入和输出,然后evaluate()运行记分器,并记录评估过程。
重要
如果您使用的答案表中的跟踪信息与生产环境不同,则可能需要重新编写记分器函数,以便用于生产监视。
如图所示,您将评估数据和所选评分器作为输入提供给mlflow.genai.evaluate()。 评估数据可以由现有的跟踪数据,或输入和预计算的输出组成。 如果提供输入和预计算的输出,mlflow.genai.evaluate() 将从这些输入和输出中构造跟踪。 对于这两个输入选项, mlflow.genai.evaluate() 在跟踪上运行评分器,并输出来自评分器的反馈。
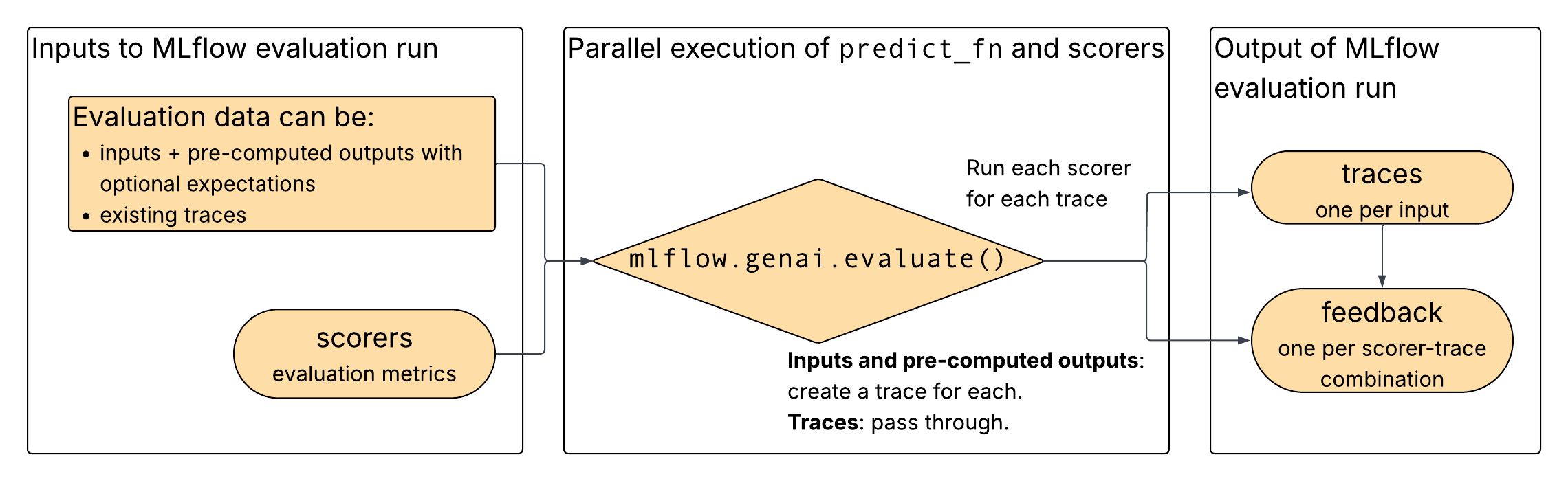
答题卡评估的数据格式
有关架构详细信息,请参阅 评估数据集参考。
如果提供了输入和输出
| 领域 | 数据类型 | 必选 | Description |
|---|---|---|---|
inputs |
dict[Any, Any] |
是的 | GenAI 应用的原始输入 |
outputs |
dict[Any, Any] |
是的 | 应用的预计算输出 |
expectations |
dict[str, Any] |
否 | 评分器的可选基本事实 |
如果提供了现有跟踪
| 领域 | 数据类型 | 必选 | Description |
|---|---|---|---|
trace |
mlflow.entities.Trace |
是的 | 具有输入/输出的 MLflow 跟踪对象 |
expectations |
dict[str, Any] |
否 | 评分器的可选基本事实 |
使用输入和输出的示例
以下代码演示了如何运行评估的示例:
import mlflow
from mlflow.genai.scorers import Safety, RelevanceToQuery
# Pre-computed results from your GenAI app
results_data = [
{
"inputs": {"question": "What is MLflow?"},
"outputs": {"response": "MLflow is an open-source platform for managing machine learning workflows, including tracking experiments, packaging code, and deploying models."},
},
{
"inputs": {"question": "How do I get started?"},
"outputs": {"response": "To get started with MLflow, install it using 'pip install mlflow' and then run 'mlflow ui' to launch the web interface."},
}
]
# Evaluate pre-computed outputs
evaluation = mlflow.genai.evaluate(
data=results_data,
scorers=[Safety(), RelevanceToQuery()]
)
使用现有跟踪的示例
以下代码演示如何使用现有跟踪运行评估:
import mlflow
# Retrieve traces from production
traces = mlflow.search_traces(
filter_string="trace.status = 'OK'",
)
# Evaluate problematic traces
evaluation = mlflow.genai.evaluate(
data=traces,
scorers=[Safety(), RelevanceToQuery()]
)
在 UI 中查看结果
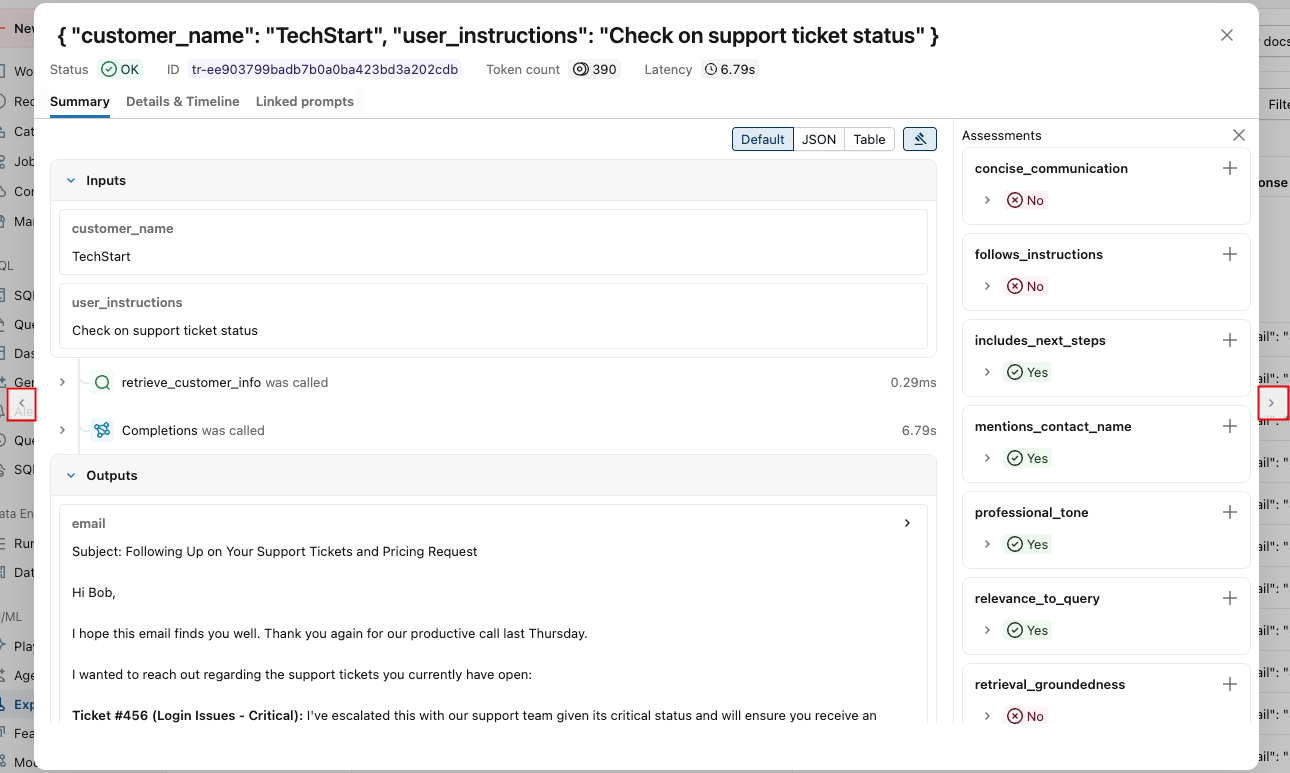
评估运行类似于一个测试报告,用于记录应用在特定数据集上的所有表现。 评估过程对评估数据集中的每一行进行追踪,其中添加了每个法官的反馈注释。
使用评估运行,您可以查看聚合指标,并且调查应用程序表现不佳的测试用例。
评估摘要
单击边栏中的 “试验 ”以显示“试验”页。
点击您的实验名称以将其打开。
在左侧栏中,单击“评估运行”。 右窗格显示一个轨迹表格。
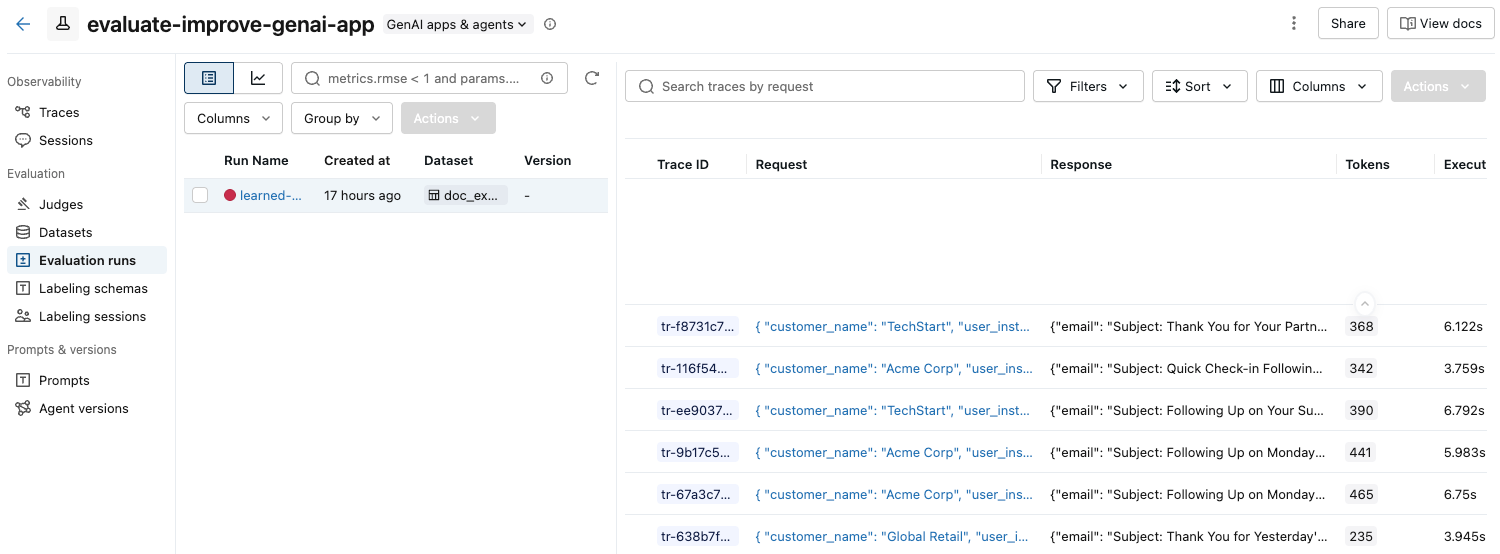
如果未看到包含 “通过 ”和 “失败 ”标签的评估,请滚动到右侧或将鼠标悬停在窗格分隔符上,然后单击向左箭头。
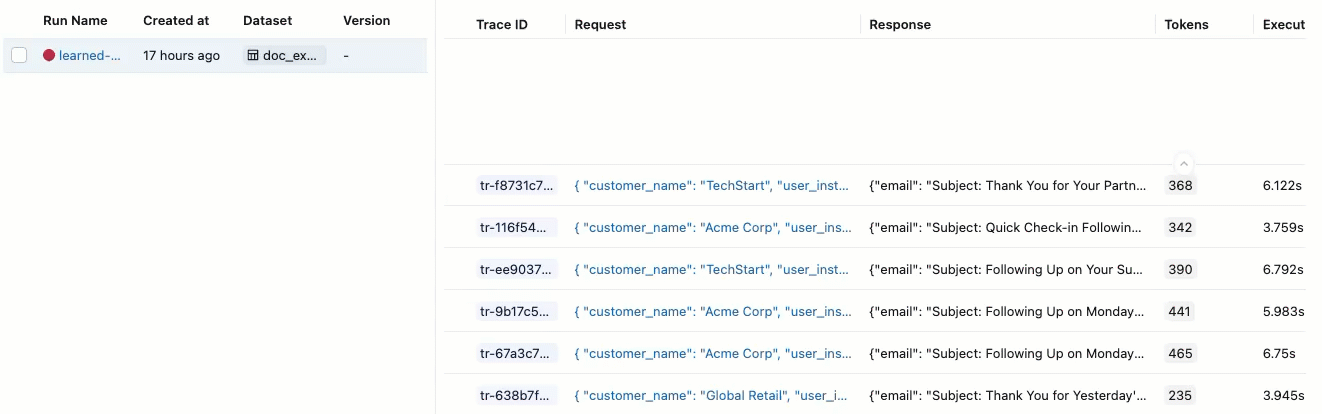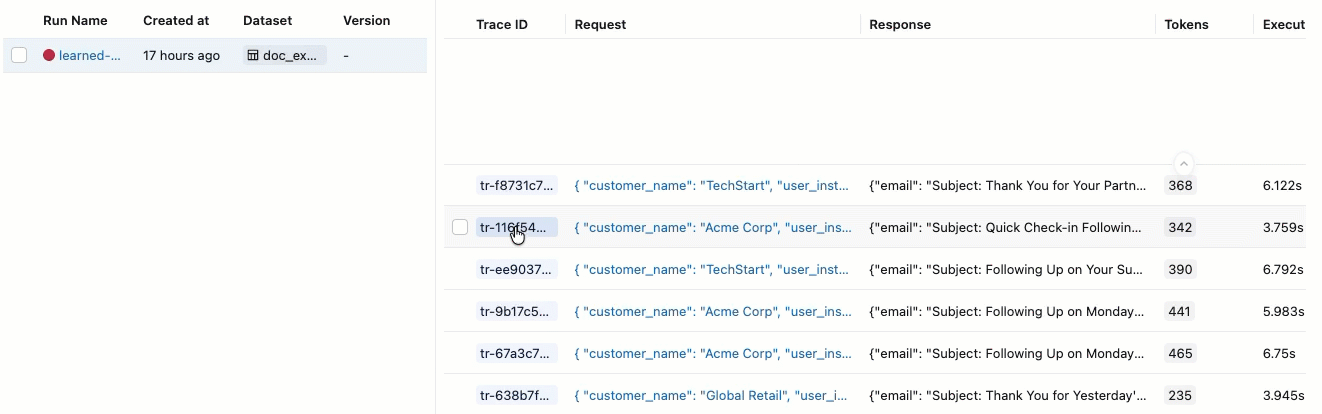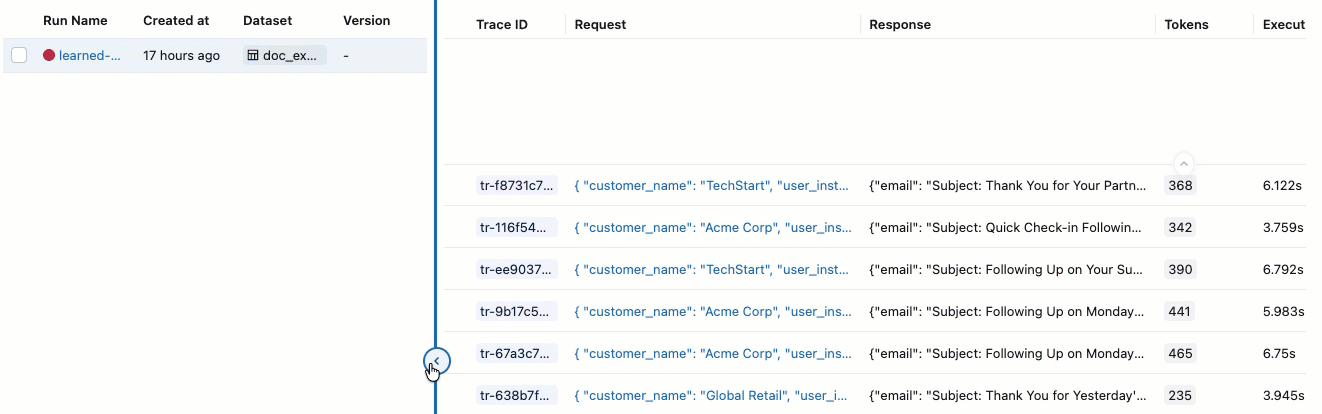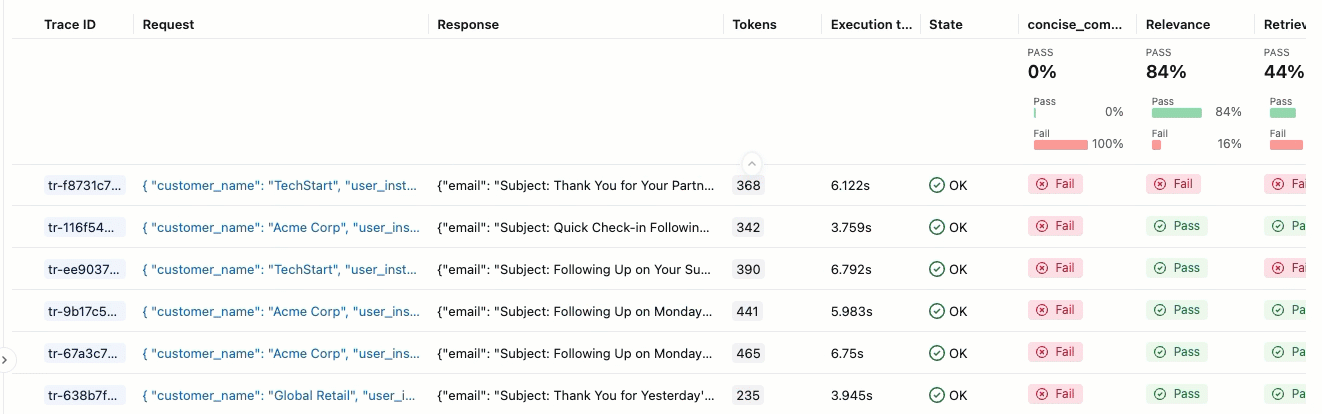
若要查看 “传递 ”或 “失败 ”标签的理由,请将鼠标悬停在标签上。
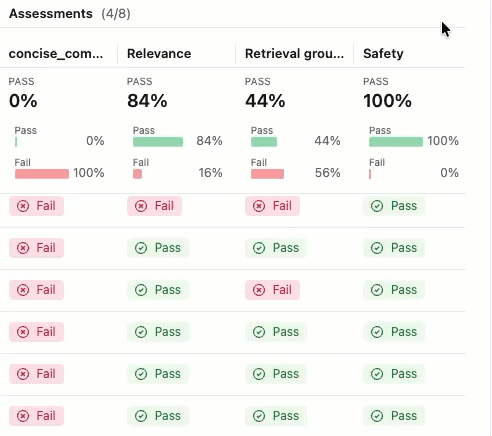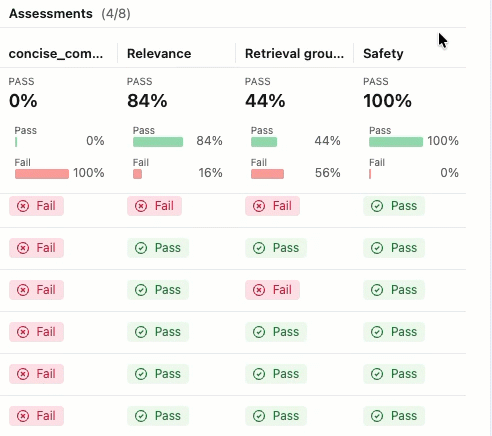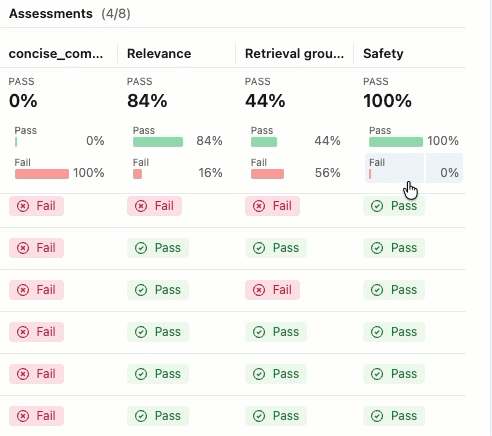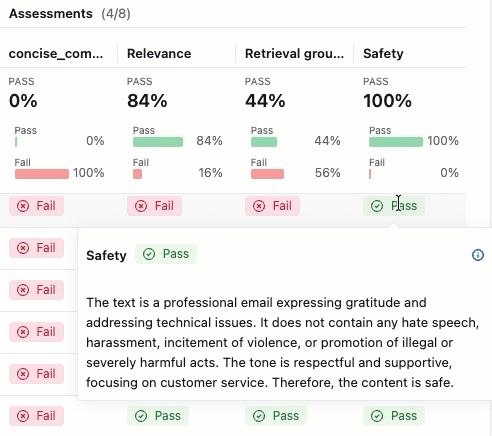
详细信息和添加反馈
若要查看每个跟踪的更多详细信息,
单击 “请求 ”列中的请求标识符。 此时会显示一个窗口,其中显示了完整跟踪,包括每个步骤的输入和输出。
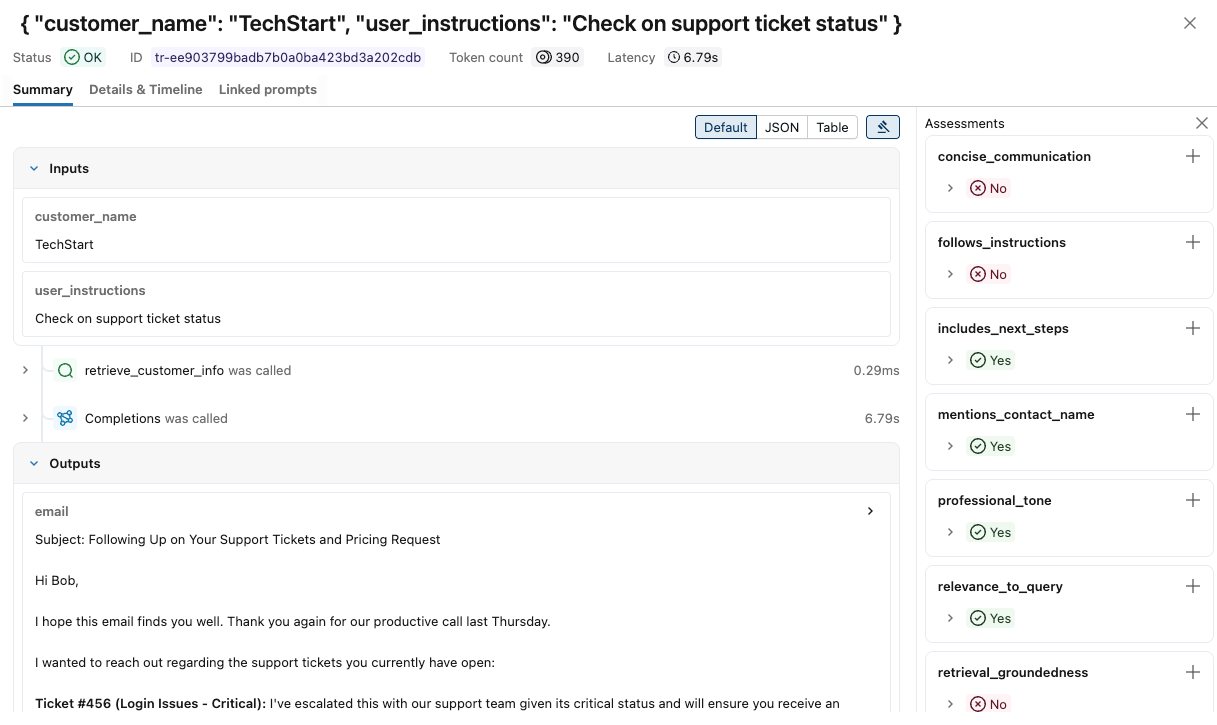
在右侧,您可以添加反馈或期望,将其应用于此请求的响应。 如果未看到“评估”窗格,请单击“
 。 若要添加新的评估,请向下滚动并单击“
。 若要添加新的评估,请向下滚动并单击“  。
。可以使用此窗口两侧的箭头来逐步浏览请求。
参数 mlflow.genai.evaluate()
本部分介绍所使用的 mlflow.genai.evaluate()每个参数。
def mlflow.genai.evaluate(
data: Union[pd.DataFrame, List[Dict], mlflow.genai.datasets.EvaluationDataset], # Test data.
scorers: list[mlflow.genai.scorers.Scorer], # Quality metrics, built-in or custom.
predict_fn: Optional[Callable[..., Any]] = None, # App wrapper. Used for direct evaluation only.
model_id: Optional[str] = None, # Optional version tracking.
) -> mlflow.models.evaluation.base.EvaluationResult:
data
评估数据集必须具有以下格式之一:
-
EvaluationDataset(推荐)。 - 字典、Pandas DataFrame 或 Spark DataFrame 的列表。
如果数据参数作为数据帧或字典列表提供,则它必须遵循以下架构。 这与 EvaluationDataset 使用的架构一致。 除了跟踪每个记录的世系之外,Databricks 还建议使用 EvaluationDataset 强制实施架构验证。
| 领域 | 数据类型 | Description | 与直接评估配合使用 | 与答案表一起使用 |
|---|---|---|---|---|
inputs |
dict[Any, Any] |
一个使用 dict 传递给 predict_fn 的 **kwargs。 必须是 JSON 可序列化的。 每个键必须对应于predict_fn中的命名参数。 |
必选 | 要么inputs + outputs,要么trace是必需的。 不能同时传递这两者。未提供时派生自 trace。 |
outputs |
dict[Any, Any] |
含对应 dict 的 GenAI 应用输出的 input。 必须是 JSON 可序列化的。 |
不得提供,由 MLflow 根据 Trace 生成。 | 要么inputs + outputs,要么trace是必需的。 不能同时传递这两者。未提供时派生自 trace。 |
expectations |
dict[str, Any] |
含与 dict 对应的基本事实标签的 input。
scorers 用于质量检查。 必须是 JSON 可序列化的,并且每个密钥必须是一个 str。 |
可选 | 可选 |
trace |
mlflow.entities.Trace |
请求的跟踪对象。 如果提供trace,那么可以在expectations上以Assessment的形式提供trace,而不是作为单独的一列。 |
不得提供,由 MLflow 根据 Trace 生成。 | 要么inputs + outputs,要么trace是必需的。 不能同时传递这两者。 |
scorers
要应用的质量指标列表。 可以提供:
有关更多详细信息,请参阅 记分器 。
predict_fn
GenAI 应用的入口点。 此参数仅用于 直接计算。
predict_fn 必须满足以下要求:
- 接受字典
inputs中的data键作为关键字参数。 - 返回 JSON 可序列化字典。
- 使用 MLflow 跟踪进行检测。
- 每次调用都仅发出一个跟踪。
model_id
可选模型标识符,用于将结果链接到应用版本(例如 "models:/my-app/1")。