你会看到工作时间线中存在间隙,如下所示:
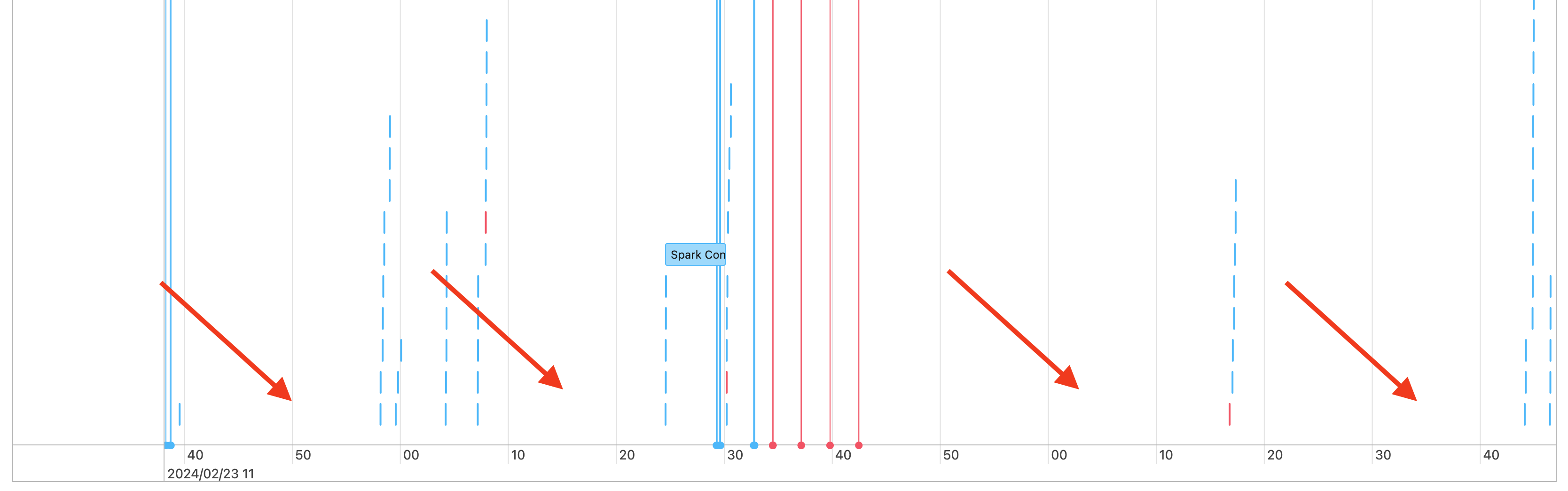
导致这种情况发生的原因有几个。 如果差距占工作负荷花费的时间比例很高,则需要确定是什么原因造成了这些差距,以及这是否在预期内。 在间隙期间可能会发生几种情况:
- 没有工作要做
- 驱动程序正在编译复杂的执行计划
- 执行非 Spark 代码
- 驱动程序过载
- 群集出现故障
没有工作
在通用计算中,没有工作可做是导致这些间隙的最可能的解释。 由于群集正在运行并且用户正在提交查询,因此预期会存在间隙。 这些间隙是查询提交之间的时间。 请考虑改用 无服务器计算 。 使用无服务器时,你不会为空闲时间付费,这可能会显著降低成本。
复杂的执行计划
例如,如果在循环中使用 withColumn(),则会创建一个成本十分昂贵的处理计划。 这些间隙可能是因为驱动程序在构建和处理计划时所花费的时间。 如果是这种情况,请尝试简化代码。 使用 selectExpr() 将多个 withColumn() 调用合并为一个表达式,或将代码转换为 SQL。 仍然可以将 SQL 嵌入到 Python 代码中,使用 Python 通过字符串函数操作查询。 这通常可以解决此类问题。
执行非 Spark 代码
Spark 代码可以用 SQL 编写,也可以使用 PySpark 等 Spark API 编写。 任何非 Spark 代码的执行都会在时间线中显示为间隙。 例如,可以在 Python 中使用一个循环来调用本机 Python 函数。 此代码不在 Spark 中执行,它可能显示为时间线中的间隙。 如果不确定代码是否正在运行 Spark,请尝试在笔记本中以交互方式运行它。 如果代码使用 Spark,你将在单元格下看到 Spark 作业:

还可以展开单元格下的“Spark 作业”下拉列表,查看作业是否正在主动执行(如果 Spark 现在处于空闲状态)。 如果未使用 Spark,则不会在单元格下看到“Spark 作业”,或者将看到没有 Spark 作业处于活动状态。 如果无法以交互方式运行代码,可以尝试登录代码,并查看是否可以按时间戳将差距和代码部分匹配起来,但这可能很麻烦。
如果你发现由于运行非 Spark 代码而导致时间线出现间隙,这意味着你的工作线程都处于闲置状态,并且在间隙期间可能会浪费资金。 也许这是有意为之,而且不可避免,但如果你可以编写此代码来使用 Spark,则可以充分利用群集。 从本教程开始,了解如何使用 Spark,或者如果非 Spark 代码是有意的,请考虑改用无服务器计算。 使用无服务器时,你不会为空闲时间付费,这可能会显著降低成本。
驱动程序过载
若要确定驱动程序是否重载,则需要查看群集指标。
如果您的群集正在运行 Databricks Runtime 13.0 或更高版本,请单击屏幕截图中突出显示的 Metrics。
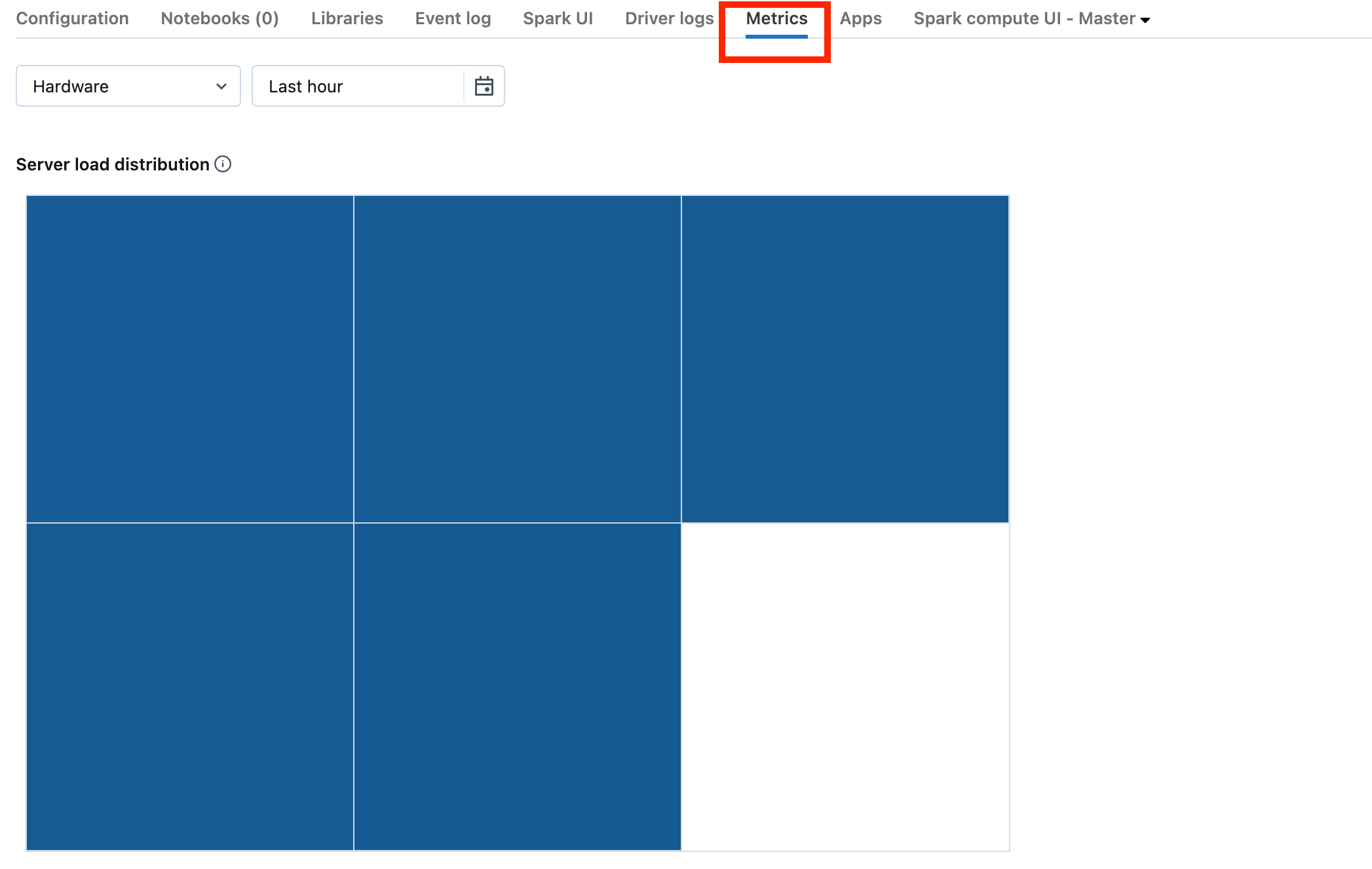
请注意服务器负载分布可视化效果。 应该检查驱动程序是否负载过重。 该可视化效果为群集中的每台机器显示了一个颜色块。 红色表示重载,蓝色表示完全没有任何负载。
上一个屏幕截图显示了一个基本空闲的群集。 如果驱动程序过载,它将如下所示:
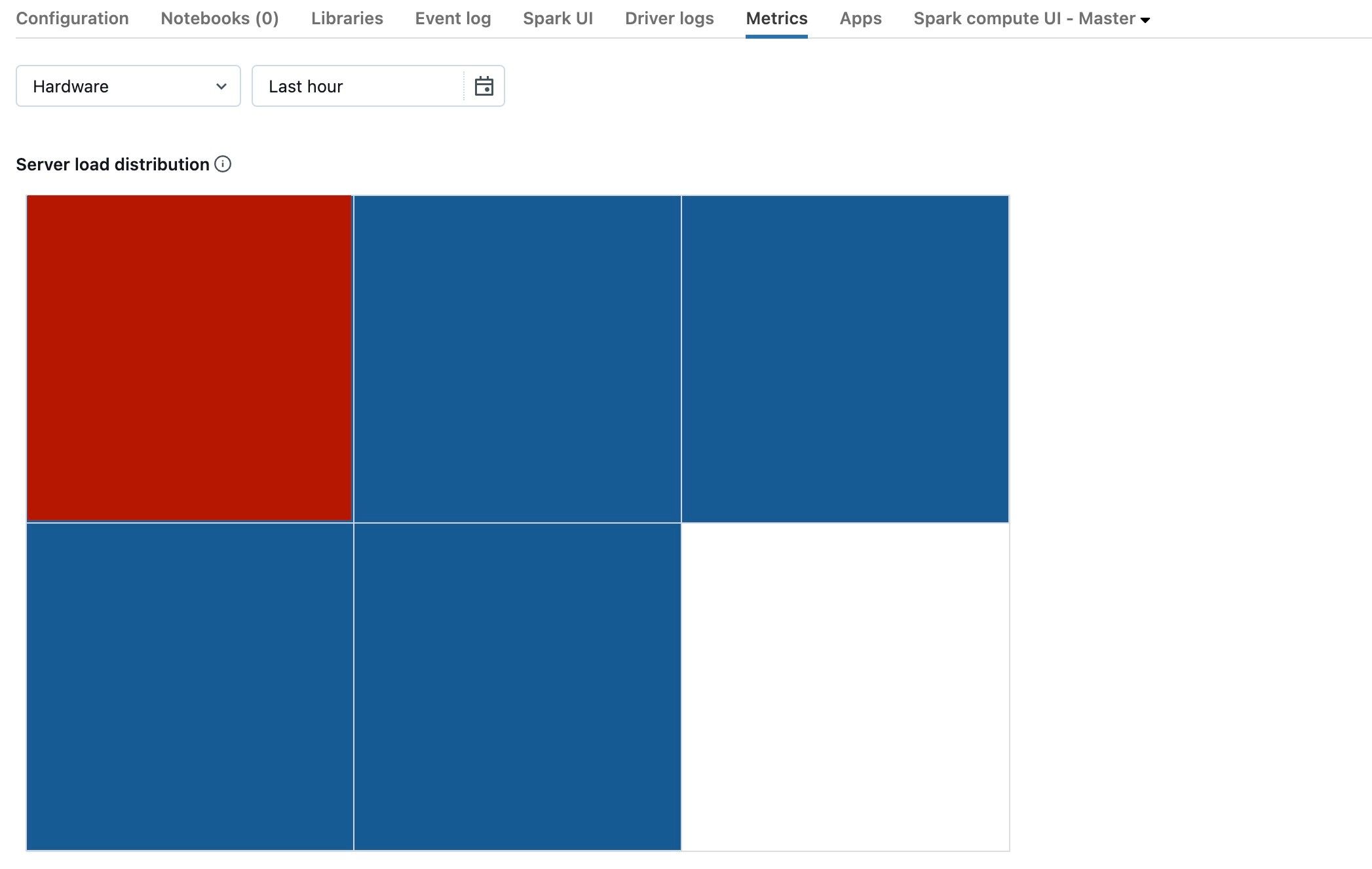
我们可以看到,一个方块是红色的,而其他方块是蓝色的。 将鼠标滚动到红色方块上,确保红色块代表你的驱动程序。
若要修复重载驱动程序,请参阅 Spark 驱动程序重载。
群集出现故障
群集发生故障的情况很少见,但如果是这种情况,则很难确定发生了什么。 你可能需要重新启动群集以查看是否可以解决问题。 也可以查看日志,寻找可疑内容。 下面的屏幕截图中突出显示的“事件日志”选项卡和“驱动程序日志”选项卡将是你需要查看的位置:
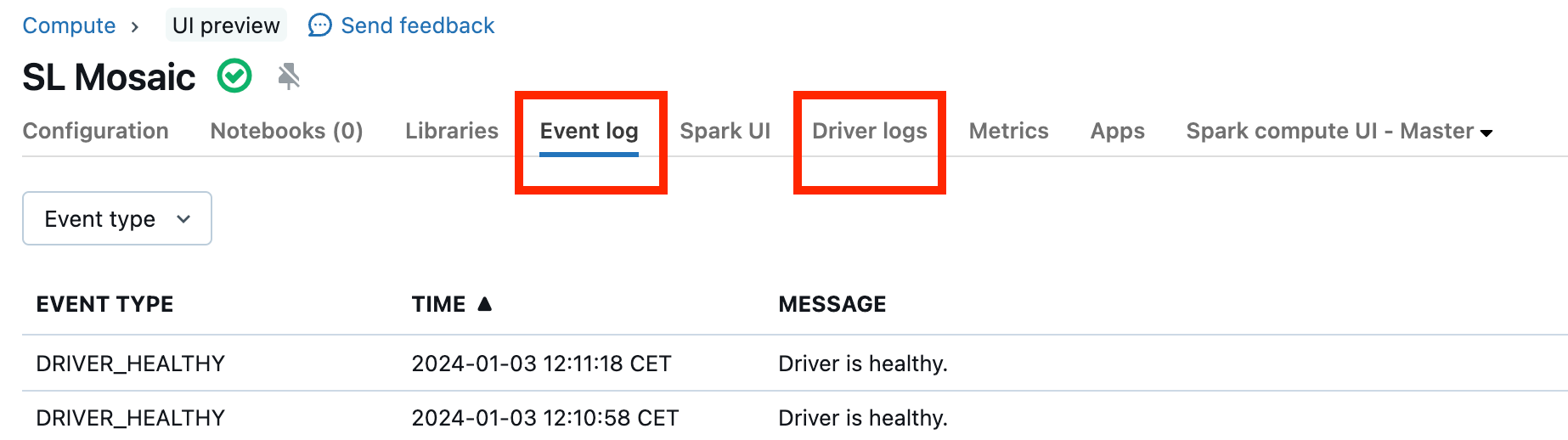
可能需要启用群集日志传送才能访问工作线程的日志。 还可以更改日志级别,但可能需要联系 Databricks 客户团队寻求帮助。