缓存是用于提高数据仓库系统性能的关键技术,因为它可以避免多次重新计算或提取相同数据的需要。 在 Databricks SQL 中,缓存可以显著加快查询执行速度并最大程度地减少仓库的使用,从而降低了成本并提高了资源利用效率。 每个缓存层可以提高查询性能、最大程度地减少群集的使用并优化资源利用率,以实现无缝的数据仓库体验。
缓存机制在数据仓库中提供许多优势,包括:
- 速度:通过将查询结果或经常访问的数据存储在内存或其他快速存储媒体中,缓存可以显著减少查询执行时间。 此存储对于重复性查询特别有利,因为系统可以快速检索缓存的结果,而无需重新计算结果。
- 减少群集的使用:缓存通过重用先前计算出的结果来最大程度地减少对额外计算资源的需求。 这减少了仓库的总体运行时间以及对额外计算群集的需求,从而节省了成本并改善了资源分配。
Databricks SQL 中的查询缓存类型
Databricks SQL 执行多种类型的查询缓存。
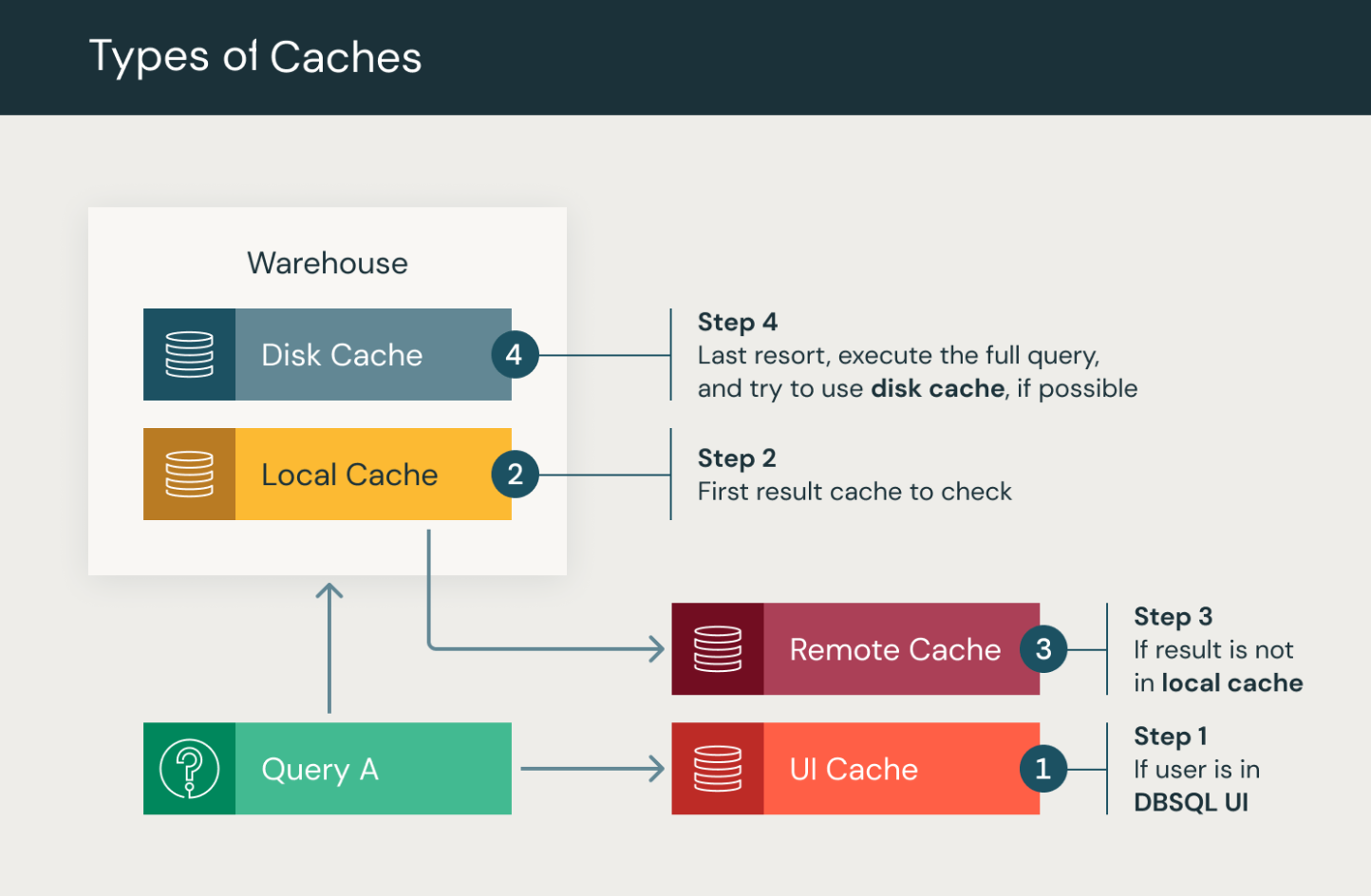
Databricks SQL UI 缓存: Databricks SQL UI 中查询结果和 SQL 编辑器可视化效果的按用户缓存。 当用户首次打开 SQL 查询或旧版 SQL 仪表板时,Databricks SQL UI 缓存会显示最新的查询结果,包括计划执行的结果。
注释
Databricks SQL UI 缓存不适用于 AI/BI 仪表板(原为 Lakeview 仪表板)。 AI/BI 仪表板有自己的缓存行为。 请参阅数据集优化和缓存。
Databricks SQL UI 缓存的生命周期最长为 7 天。 缓存位于帐户中的 Azure Databricks 文件系统内。 可通过重新运行不再需要存储的查询来删除查询结果。 重新运行后,将从缓存中删除旧的查询结果。 此外,一旦更新基础表,缓存就会失效。
结果缓存:按群集缓存通过 SQL 仓库进行的所有查询的查询结果。 结果缓存包括本地和远程结果缓存,这两种缓存通过将查询结果存储在内存中或远程存储介质中来共同提高查询性能。
- 本地缓存:本地缓存属于内存中缓存,用于在群集的生存期结束之前或缓存已满之前(以先到者为准)存储查询结果。 此缓存用于加速重复查询,无需重新计算相同的结果。 但是,一旦群集停止或重启,系统就会清理缓存并删除所有查询结果。
- 远程结果缓存:远程结果缓存是一种仅限无服务器方式的缓存系统,通过将其作为工作区系统数据持久保存来保留查询结果。 因此,停止或重启 SQL 仓库不会导致此缓存失效。 远程结果缓存解决了在内存中缓存查询结果时常见的一个问题,此功能只有在计算资源处于运行状态时才可用。 远程缓存是 Databricks 工作区中所有仓库的永久性共享缓存。
访问远程结果缓存需要一个正在运行的仓库。 处理查询时,群集将首先查看其本地缓存,然后根据需要查看远程结果缓存。 仅当查询结果未缓存在任一缓存中时,才会执行查询。 本地缓存和远程缓存的生命周期为 24 小时,并从进入缓存开始计算。 远程结果缓存通过停止或重启 SQL 仓库持久保存。 更新基础表时,两个缓存都会失效。
远程结果缓存适用于那些使用 ODBC/JDBC 客户端和 SQL 语句 API 的查询。
若要禁用查询结果缓存,可以在 SQL 编辑器中运行
SET use_cached_result = false。重要
应仅在测试或基准测试中使用此选项。
磁盘缓存:本地 SSD 缓存,用于通过 SQL 仓库进行的查询从数据存储中读取的数据。 磁盘缓存旨在增强查询性能,为此它会在磁盘上存储数据,从而可以加速数据读取。 使用快速中间格式提取文件时,会自动缓存数据。 通过将文件副本存储在已附加到计算节点的本地存储上,磁盘缓存可以确保数据靠近工作节点,从而提高查询性能。 请参阅通过 Azure Databricks 上的缓存优化性能。
除了其主要功能之外,磁盘缓存还会自动检测对基础数据文件的更改。 当它检测到更改时,缓存就会失效。 磁盘缓存与本地结果缓存具有相同的生命周期特征。 这意味着,当群集停止或重启时,缓存将被清理并需要重新填充。
查询结果缓存和磁盘缓存会影响 Databricks SQL UI 以及 BI 和其他外部客户端中的查询。