本教程介绍如何使用 Azure 逻辑应用工作流实现Microsoft Entra ID API 驱动的入站预配。 使用本教程中的步骤,可以将包含 HR 数据的 CSV 文件转换为批量请求有效负载,并将其发送到 Microsoft Entra 预配 /bulkUpload API 终结点。 本文还提供了有关如何将同一集成模式与任何记录系统一起使用的指导。
集成方案
业务需求
您的记录系统定期生成包含工人数据的 CSV 文件导出。 你想要实现一个从 CSV 文件读取数据并自动配置用户账户的集成方案,针对混合用户在本地 Active Directory 中执行此操作,而仅限云的用户则在 Microsoft Entra ID 中进行。
实现要求
从实现的角度来看:
- 你希望使用 Azure 逻辑应用工作流从 Azure 文件共享中可用的 CSV 文件导出读取数据,并将其发送到入站预配 API 终结点。
- 在 Azure 逻辑应用工作流中,你不希望实现在记录和目标目录系统之间比较标识数据的复杂逻辑。
- 你希望使用 Microsoft Entra 预配服务应用 IT 托管预配规则,以便在目标目录中自动创建/更新/启用/禁用帐户(本地 Active Directory 或 Microsoft Entra ID)。

集成方案变体
虽然本教程使用 CSV 文件作为记录系统,但可以自定义示例 Azure 逻辑应用工作流,以从任何记录系统读取数据。 Azure 逻辑应用提供了各种内置连接器和 托管连接器 ,以及可在集成工作流中使用的预构建触发器和操作。
下面是企业集成方案变体的列表,其中可以使用逻辑应用工作流实现 API 驱动的入站预配。
| # | 记录系统 | 有关使用逻辑应用读取源数据的集成指南 |
|---|---|---|
| 1 | 存储在 SFTP 服务器上的文件 | 使用内置 SFTP 连接器或 [托管 SFTP SSH 连接器(/connectors/connectors-sftp-ssh)从 SFTP 服务器上存储的文件读取数据。 |
| 2 | 数据库表 | 如果使用 Azure SQL Server 或本地 SQL Server,请使用 [SQL Server(/connectors/connectors-create-api-sqlazure) 连接器读取表数据。 如果使用 Oracle 数据库,请使用 [Oracle database(/connectors/connectors-create-api-oracledatabase) 连接器读取表数据。 |
| 3 | 本地和云托管的 SAP S/4 HANA 或 经典本地 SAP 系统,例如 R/3 和 ECC |
使用 SAP 连接器 从 SAP 系统检索标识数据。 有关如何配置此连接器的示例,请参阅使用 Azure 逻辑应用和 SAP 连接器 的常见 SAP 集成方案 。 |
| 4 | IBM MQ | 使用 [IBM MQ 连接器(/connectors/connectors-create-api-mq)从队列接收预配消息。 |
| 5 | Dynamics 365 人力资源 | 使用 [Dataverse 连接器(/connectors/connect-common-data-service),从 Microsoft Dynamics 365 人力资源所使用的 Dataverse 表中读取数据。 |
| 6 | 公开 REST API 的任何系统 | 如果在逻辑应用连接器库中找不到记录系统的连接器,则可以创建自己的 自定义连接器 ,以便从记录系统读取数据。 |
读取源数据后,应用预处理规则并将记录系统中的输出转换为批量请求,该请求可以发送到 Microsoft Entra 预配 bulkUpload API 终结点。
重要
如果要与社区共享 API 驱动的入站预配 + 逻辑应用集成工作流,请创建 一个逻辑应用模板,记录有关如何使用它并提交拉取请求以包含在 GitHub 存储库 entra-id-inbound-provisioning中。
如何使用本教程
Microsoft Entra 入站预配 GitHub 存储库中发布的逻辑应用部署模板自动执行多个任务。 它还具有用于处理大型 CSV 文件的逻辑,并分块批量请求以在每个请求中发送 50 条记录。 下面介绍如何根据集成要求对其进行测试并对其进行自定义。
注释
提供了示例 Azure 逻辑应用工作流“as-is”以供实现参考。 如果存在与之相关的问题,或者想要对其进行增强,请使用 GitHub 项目存储库。
| # | 自动化任务 | 实施指南 | 高级自定义 |
|---|---|---|---|
| 1 | 从 CSV 文件读取工人数据。 | 逻辑应用工作流使用 Azure 函数读取存储在 Azure 文件共享中的 CSV 文件。 Azure 函数将 CSV 数据转换为 JSON 格式。 如果 CSV 文件格式不同,请更新工作流步骤“分析 JSON”和“构造 SCIMUser”。 | 如果记录系统不同,请查看 集成方案变体 中提供的有关如何使用适当连接器自定义逻辑应用工作流的指南。 |
| 2 | 预处理数据并将其转换为 SCIM 格式。 | 默认情况下,逻辑应用工作流会将 CSV 文件中的每个记录转换为 SCIM 核心用户 + 企业用户表示形式。 如果计划使用自定义 SCIM 架构扩展,请更新步骤“构造 SCIMUser”以包含自定义 SCIM 架构扩展。 | 若要运行 C# 代码进行高级格式设置和数据验证,请使用 自定义 Azure Functions。 |
| 3 | 使用正确的身份验证方法 | 可以使用 服务主体 或使用 托管标识 访问入站预配 API。 使用正确的身份验证方法更新步骤“将 SCIMBulkPayload 发送到 API 终结点”。 | - |
| 4 | 在本地 Active Directory 或 Microsoft Entra ID 中配置帐户。 | 配置 API 驱动的入站预配应用。 这会生成一个唯一的 /bulkUpload API 终结点。 更新步骤“将 SCIMBulkPayload 发送到 API 终结点”以使用正确的 bulkUpload API 终结点。 | 如果计划对自定义 SCIM 架构使用批量请求,请扩展预配应用架构以包含自定义 SCIM 架构属性。 |
| 5 | 扫描预配日志,并对失败的记录重新尝试进行预配。 | 此自动化尚未在示例逻辑应用工作流中实现。 若要实现它,请参阅 预配日志图形 API。 | - |
| 6 | 将基于逻辑应用的自动化部署到生产环境。 | 验证 API 驱动的预配流并自定义逻辑应用工作流以满足要求后,请在环境中部署自动化。 | - |
步骤 1:创建 Azure 存储帐户以托管 CSV 文件
本部分中介绍的步骤是可选的。 如果已有一个存储帐户,或者想要从其他源(如 SharePoint 网站或 Blob 存储)读取 CSV 文件,请更新逻辑应用以使用所选连接器。
- 以至少应用程序管理员身份登录到 Azure 门户。
- 搜索“存储帐户”并创建新的存储帐户。
- 分配资源组并为其命名。
- 创建存储帐户后,转到资源。
- 选择“文件共享”菜单选项并创建新的文件共享。
- 验证文件共享创建是否成功。
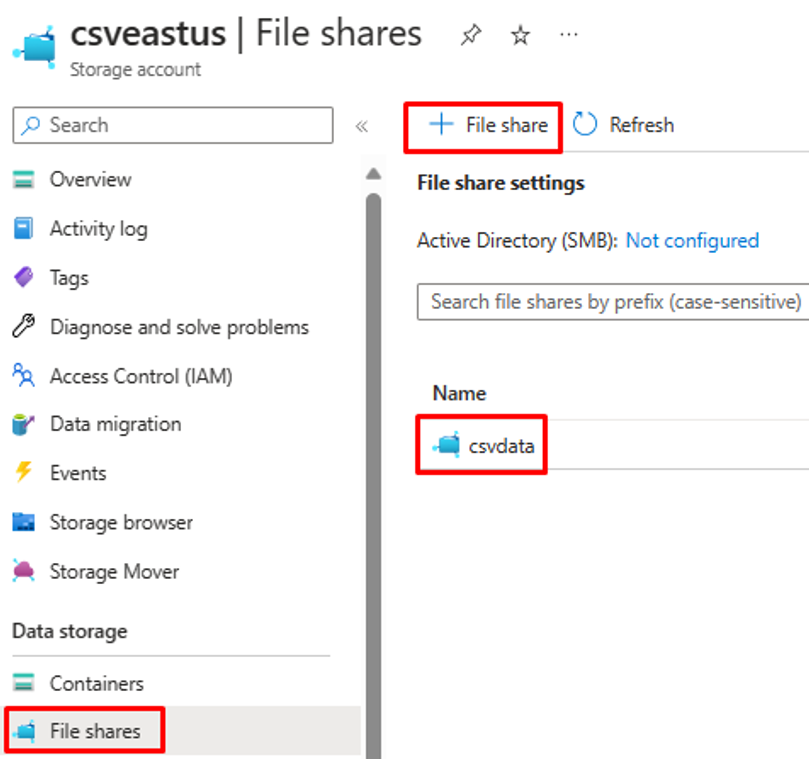
- 使用上传选项将示例 CSV 文件上传到文件共享。
- 下面是 CSV 文件中列的屏幕截图。






步骤 2:配置 Azure Function CSV2JSON 转换器
在与 Azure 门户关联的浏览器中,打开 GitHub 存储库 URL - https://github.com/joelbyford/CSVtoJSONcore。
选择“部署到 Azure”链接,将此 Azure 函数部署到 Azure 租户。
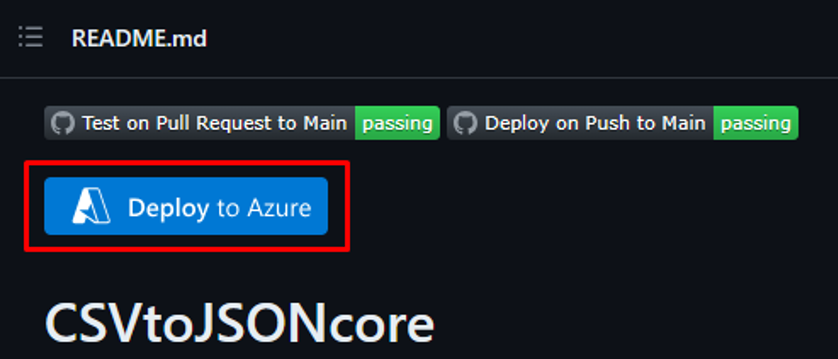
指定要在其中部署此 Azure 函数的资源组。
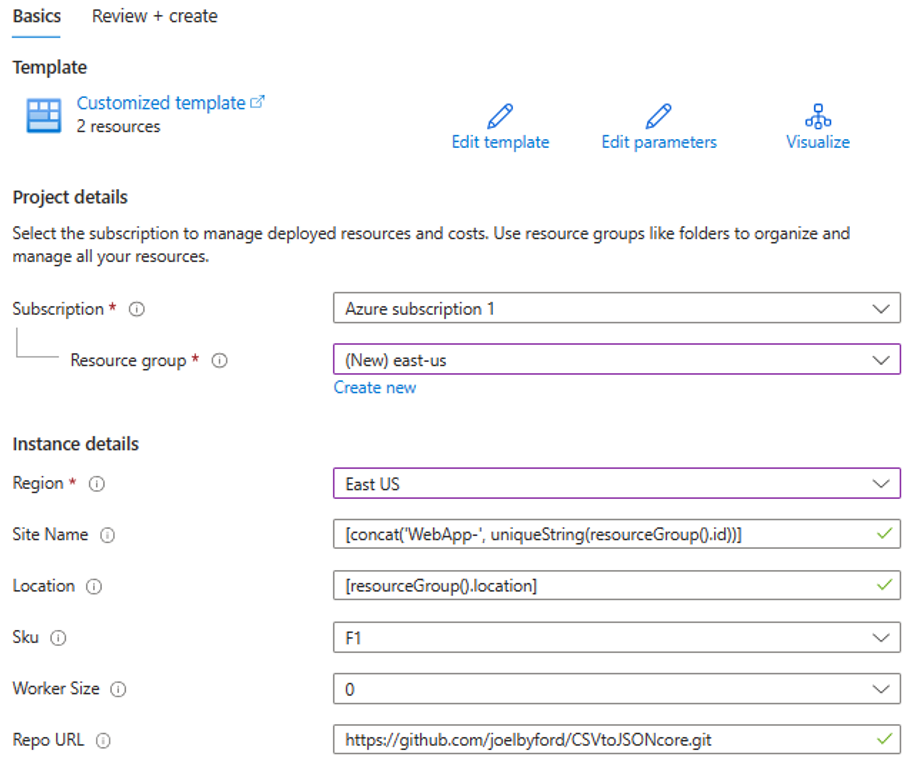
如果收到错误“此区域具有 0 个实例的配额”,请尝试选择其他区域。
确保将 Azure Function 部署为应用服务成功。
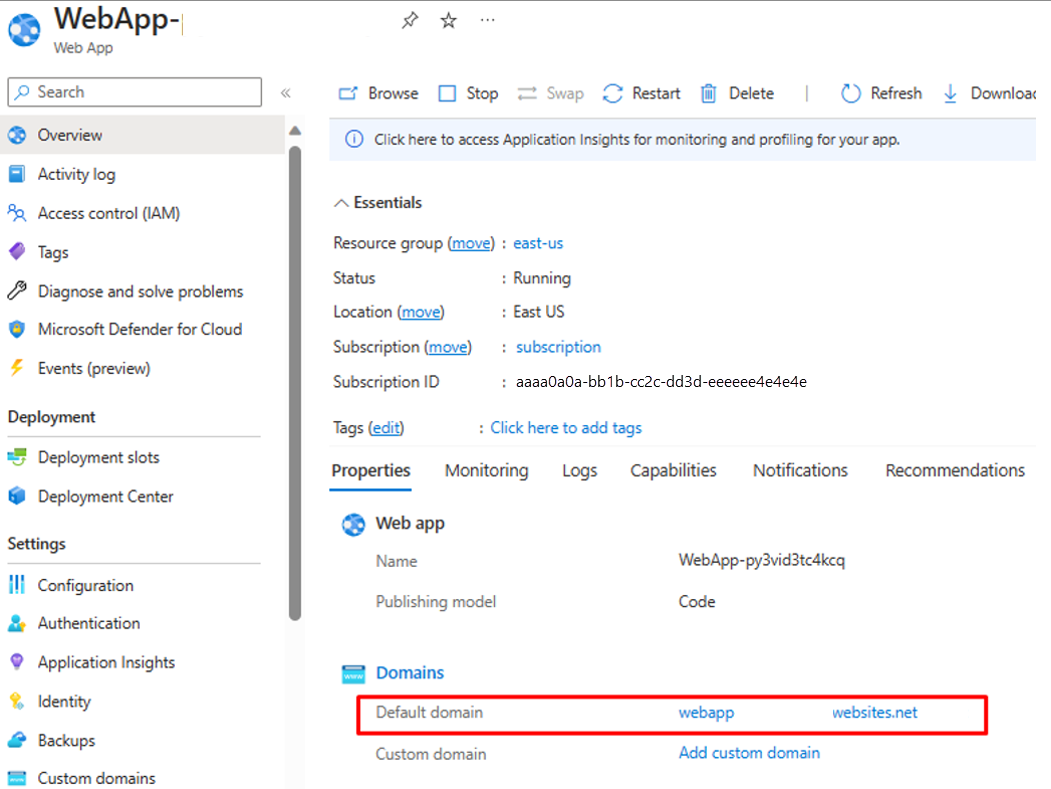
转到资源组并打开 WebApp 配置。 确保系统处于“正在运行”状态。 复制与 Web 应用关联的默认域名。
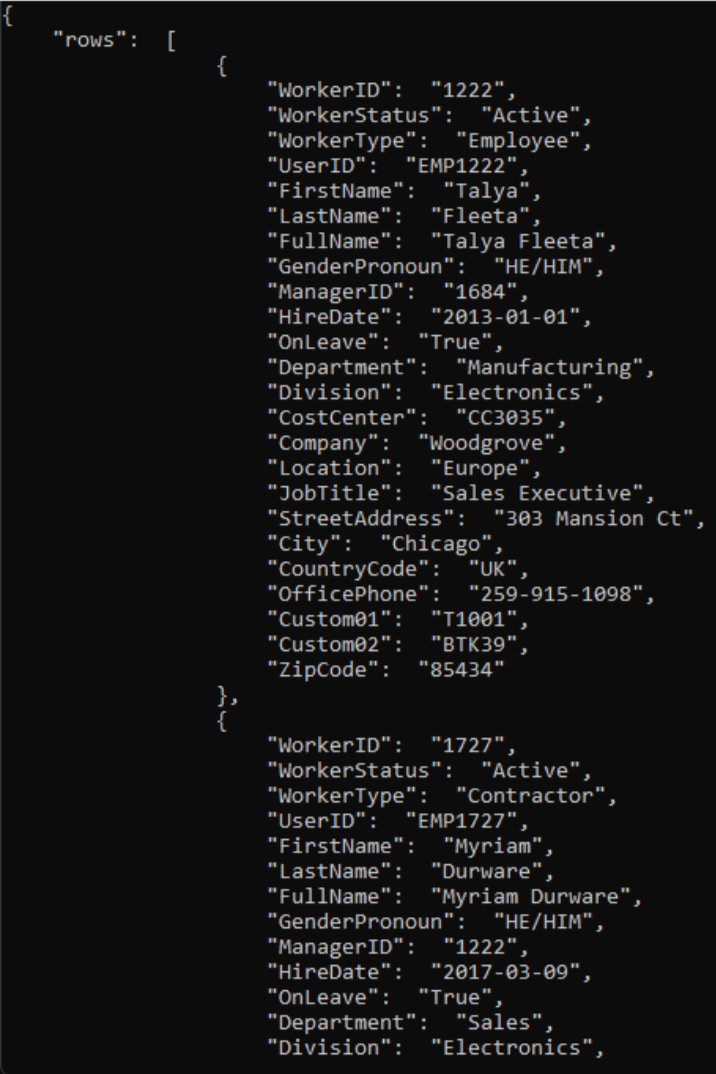
运行以下 PowerShell 脚本,测试 CSVtoJSON 终结点是否按预期工作。 为变量
$csvFilePath和$uri脚本中设置正确的值。# Step 1: Read the CSV file $csvFilePath = "C:\Path-to-CSV-file\hr-user-data.csv" $csvContent = Get-Content -Path $csvFilePath # Step 2: Set up the request $uri = "https://az-function-webapp-your-domain/csvtojson" $headers = @{ "Content-Type" = "text/csv" } $body = $csvContent -join "`n" # Join the CSV lines into a single string # Step 3: Send the POST request $response = Invoke-WebRequest -Uri $uri -Method POST -Headers $headers -Body $body # Output and format the JSON response $response.Content | ConvertFrom-JSON | ConvertTo-JSON如果 Azure 函数部署成功,则脚本的最后一行将输出 CSV 文件的 JSON 版本。
 .
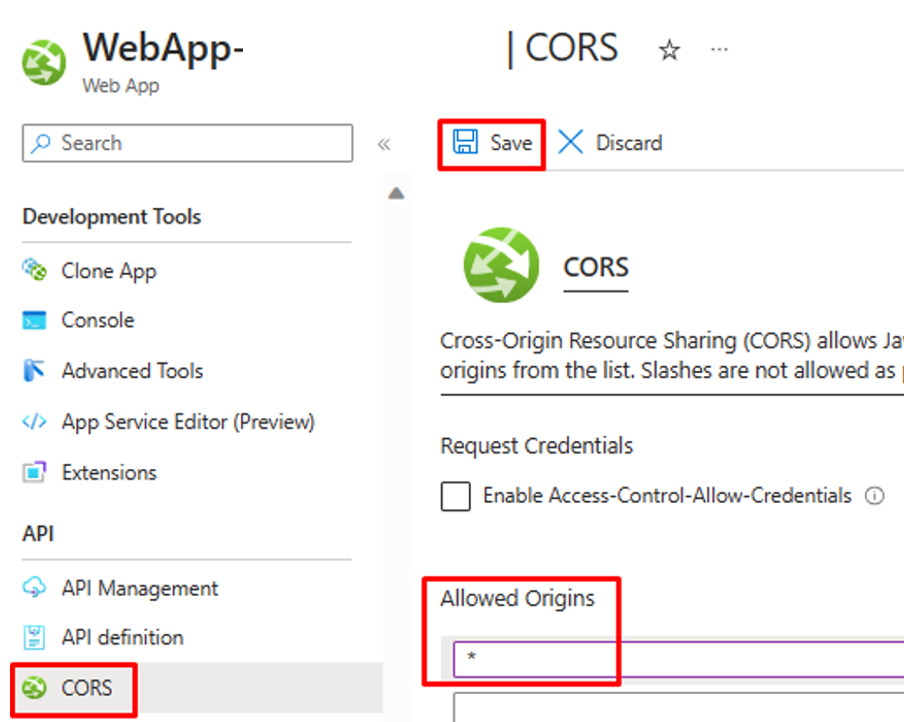
.若要允许逻辑应用调用此 Azure 函数,请在 WebApp 的 CORS 设置中输入星号 \ 和“保存”配置。





步骤 3:配置 API 驱动的入站用户预配
- 配置 API 驱动的入站用户预配。
步骤 4:配置 Azure 逻辑应用工作流
选择下面的按钮,为 CSV2SCIMBulkUpload 逻辑应用工作流部署 Azure 资源管理器模板。
在实例详细信息下,更新突出显示的项,复制粘贴前面步骤中的值。
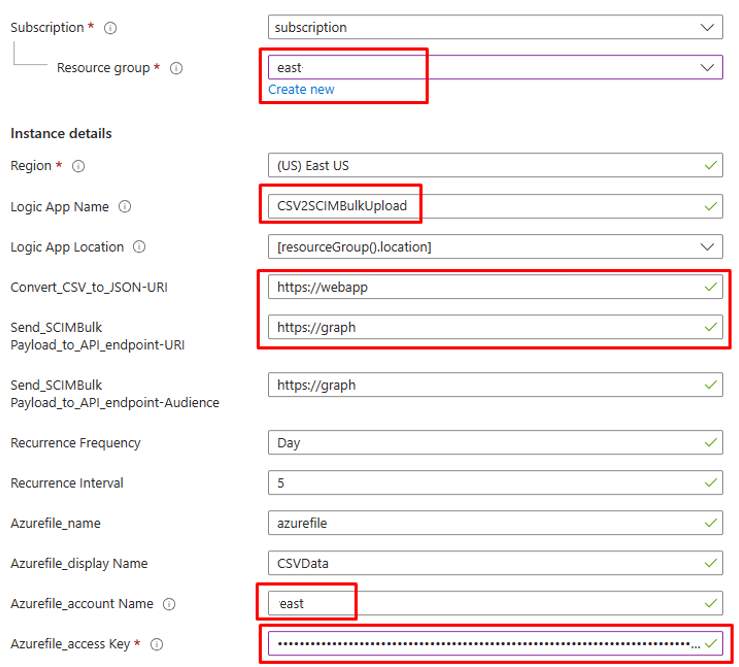
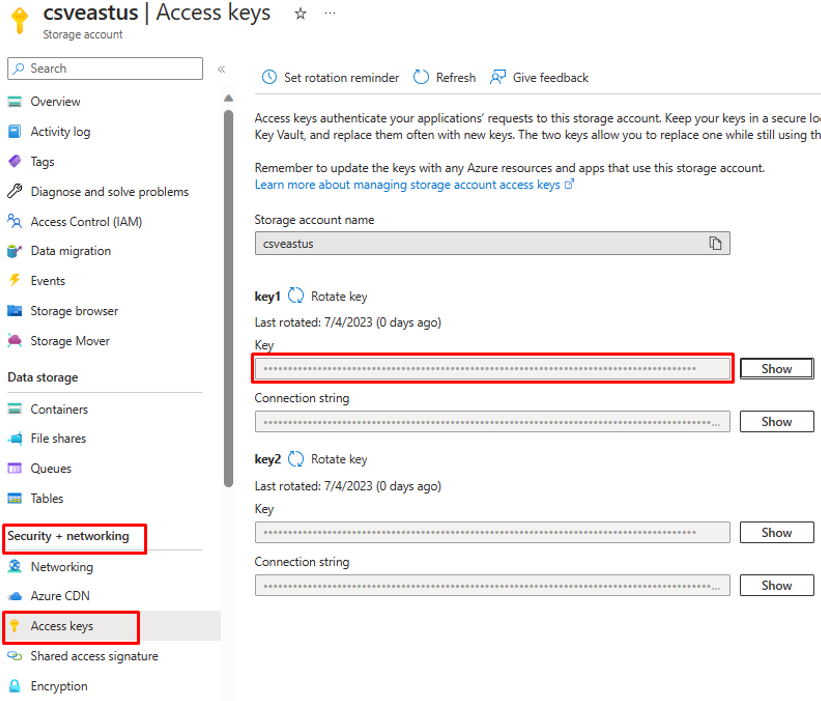
Azurefile_access Key对于参数,请打开 Azure 文件存储帐户,并复制“安全和网络”下存在的访问密钥。
选择“查看和创建”选项以启动部署。
部署完成后,会看到以下消息。
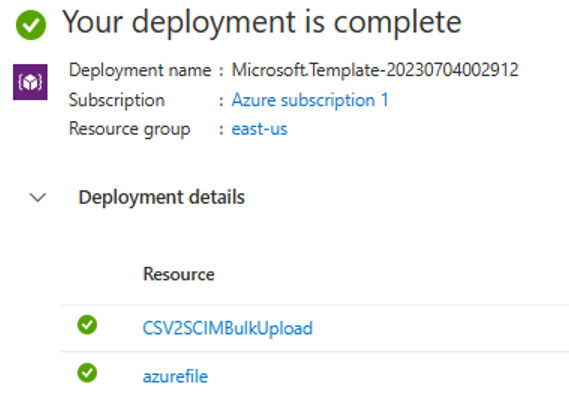



步骤 5:配置系统分配的托管标识
- 访问逻辑应用工作流的“设置 -> 标识”页。
- 启用 系统分配的托管标识。
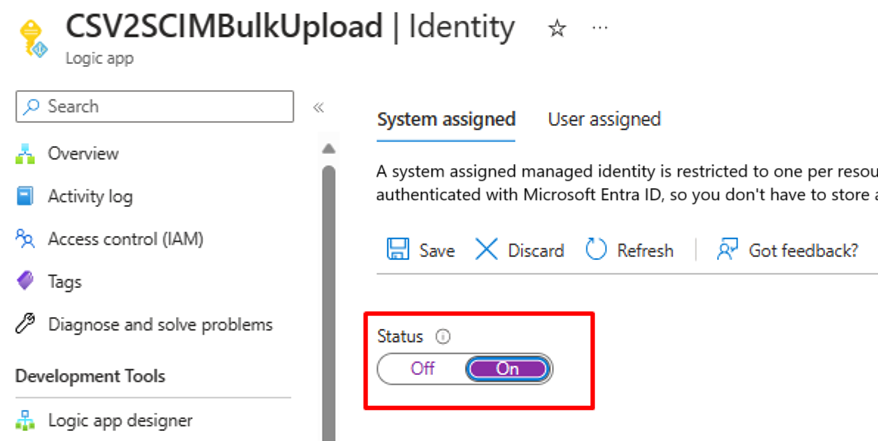
- 你将看到确认使用托管标识的提示。 选择 “是”。
- 授予托管标识 执行批量上传的权限。

步骤 6:查看和调整工作流步骤
在设计器视图中打开逻辑应用。
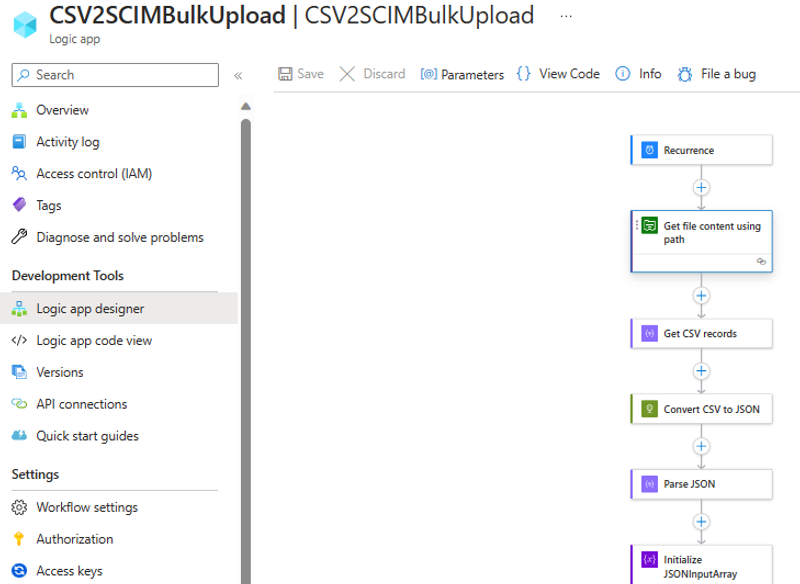
查看工作流中每个步骤的配置,确保其正确无误。
打开“使用路径获取文件内容”步骤,并更正它以浏览到租户中的 Azure 文件存储。
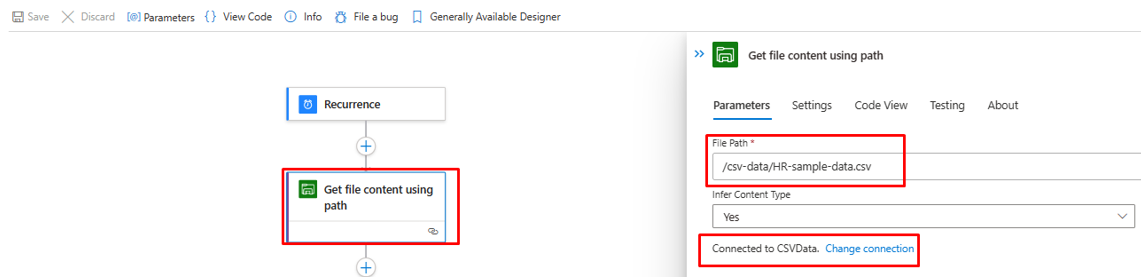
如有必要,请更新连接。
确保“将 CSV 转换为 JSON”步骤指向正确的 Azure Function Web App 实例。
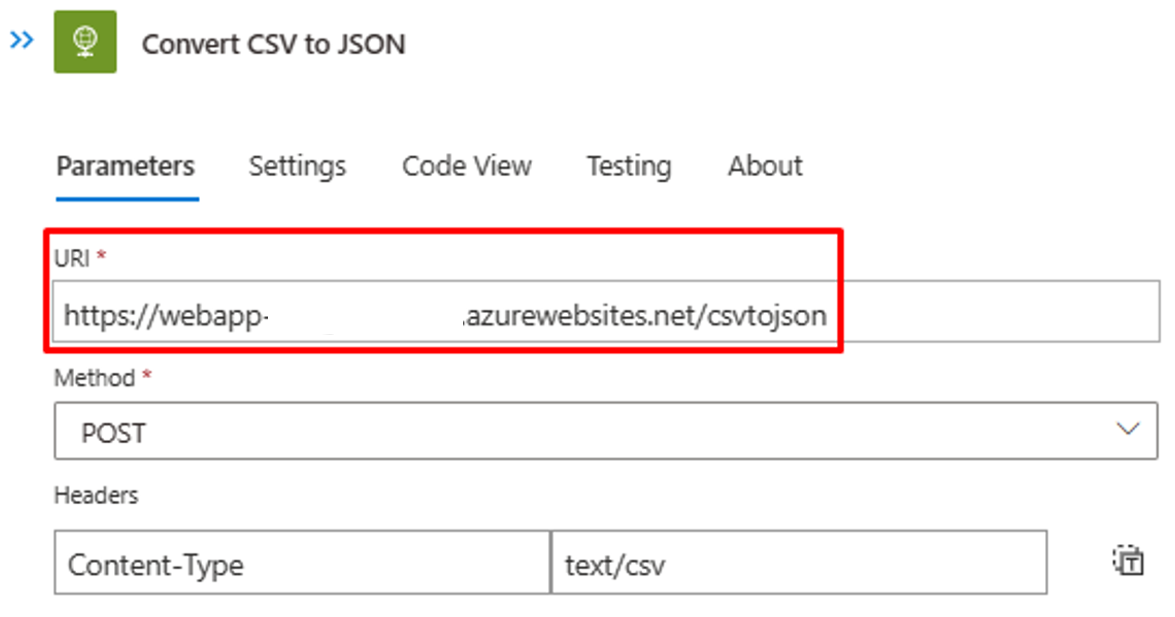
如果 CSV 文件的内容和标头不同,请使用可通过 API 调用 Azure Function 检索到的 JSON 输出更新“解析 JSON”步骤。 使用步骤 2 中的 PowerShell 输出。
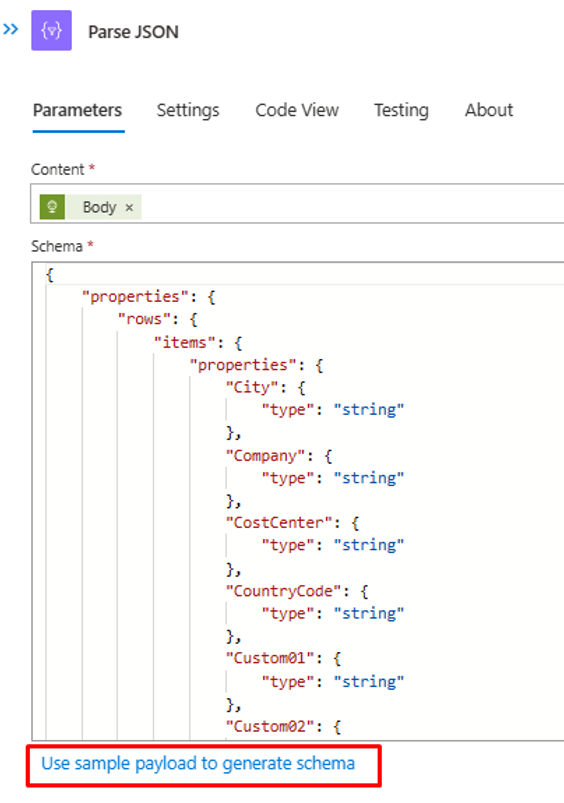
在步骤“构造 SCIMUser”中,确保 CSV 字段正确映射到将用于处理的 SCIM 属性。

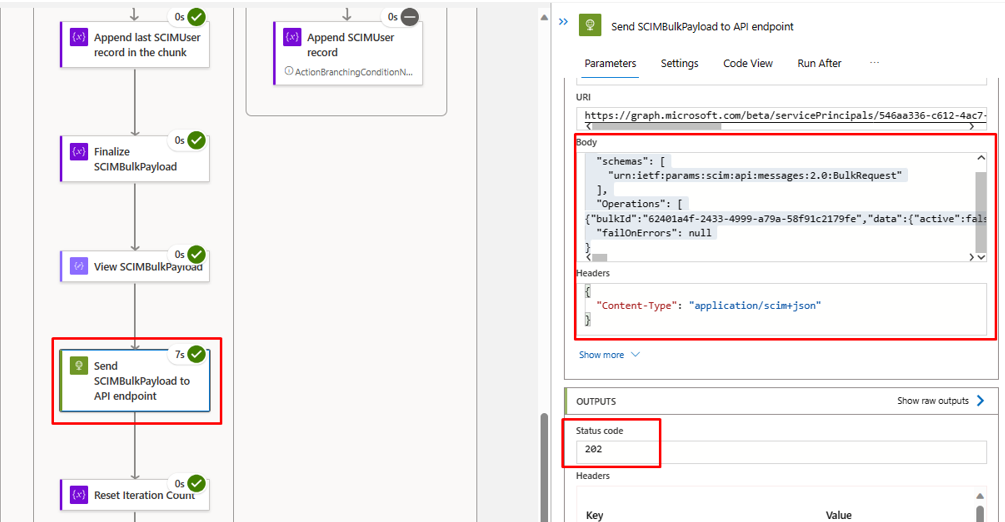
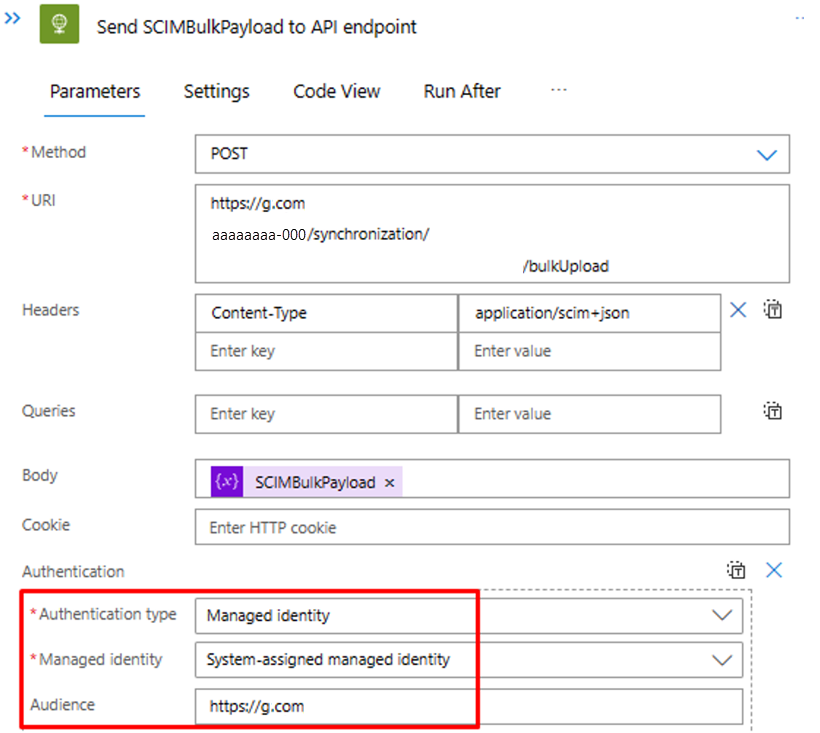
在步骤“将 SCIMBulkPayload 发送到 API 终结点”中,请确保使用正确的 API 终结点和身份验证机制。






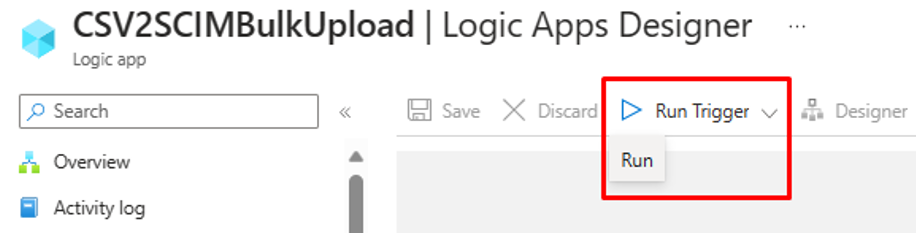
步骤 7:运行触发器并测试逻辑应用工作流
- 在逻辑应用设计器的“正式发布”版本中,选择“运行触发器”以手动执行工作流。
- 执行完成后,查看 Logic Apps 在每次迭代中执行的操作。
- 在最后一次迭代中,应会看到逻辑应用将数据上传到入站预配 API 终结点。 查找
202 Accept状态代码。 可以复制粘贴并验证批量上传请求。