在本文中,你将了解如何为 Apache Hive 配置 Apache Ranger 策略。 你将创建两个 Ranger 策略来限制对 hivesampletable 的访问。
hivesampletable 随 HDInsight 群集提供。 配置策略后,可以使用 Excel 和 Open Database Connectivity (ODBC) 驱动程序连接到 HDInsight 中的 Hive 表。
先决条件
- 具有企业安全性套餐 (ESP) 的 HDInsight 群集。 有关详细信息,请参阅配置具有 ESP 的 HDInsight 群集。
- 具有适用于企业的Microsoft 365应用的工作站、Office 2016、Office 2013 专业增强版、Excel 2013 独立版或 Office 2010 专业增强版。
连接到 Apache Ranger 管理界面
若要连接到 Ranger 管理员用户界面 (UI):
在浏览器中,转到 Ranger 管理员 UI (
https://CLUSTERNAME.azurehdinsight.cn/Ranger/),其中CLUSTERNAME是你的群集的名称。注意
Ranger 使用的凭据与 Apache Hadoop 群集不同。 若要防止浏览器使用缓存的 Hadoop 凭据,请使用新的 InPrivate 浏览器窗口连接到 Ranger 管理 UI。
使用群集管理员域用户名和密码登录:
目前,Ranger 仅适用于 Yarn 和 Hive。
创建域用户
有关如何创建 hiveruser1 和 hiveuser2 的信息,请参阅创建具有 ESP 的 HDInsight 群集。 本文使用这两个用户帐户。
创建 Ranger 策略
本部分将创建用于访问 hivesampletable 的两个 Ranger 策略。 授予对不同列集的 select 权限。 这两个用户是使用创建具有 ESP 的 HDInsight 群集创建的。 在下一部分中,你将测试Excel中的两个策略。
若要创建 Ranger 策略:
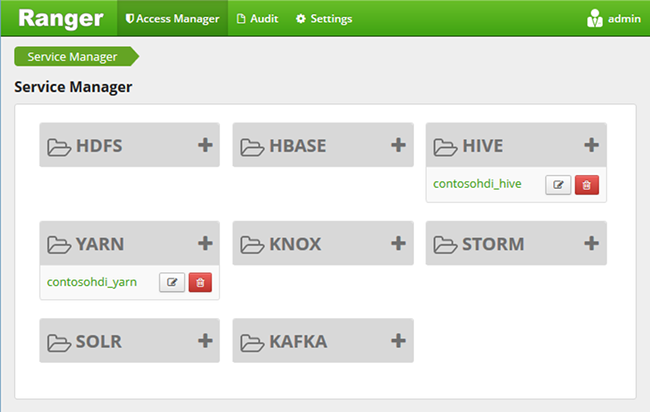
打开“Ranger 管理 UI”。 请参阅上一部分:连接到 Apache Ranger 管理员 UI。
在*Hive*下,选择*CLUSTERNAME_Hive*。 你会看到两个预配置的策略。
选择“添加新策略”,然后输入以下值:
属性 值 策略名称 read-hivesampletable-all Hive 数据库 默认 表 hivesampletable Hive 列 * 选择用户 hiveuser1 权限 选择 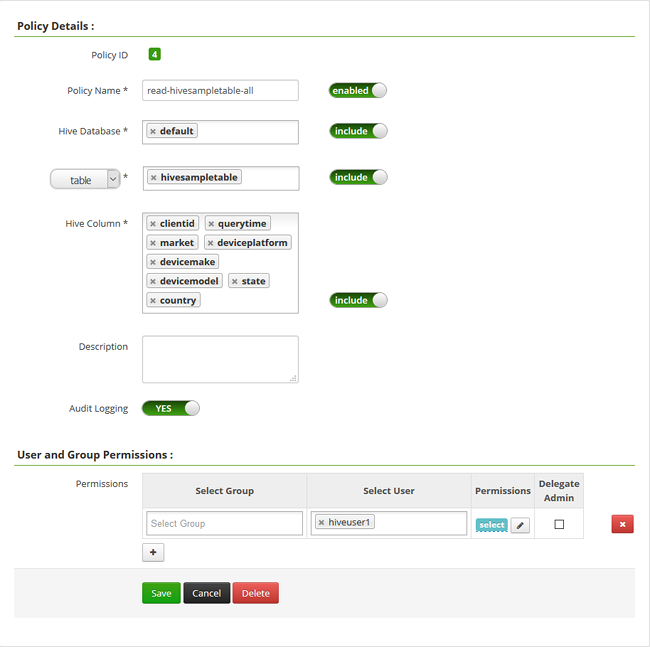 。
。注意
如果域用户未在 选择用户 中显示,请等待片刻,让 Ranger 与 Microsoft Entra ID 同步。
选择“添加”以保存策略。
重复最后两个步骤以创建具有以下属性的另一个策略:
属性 值 策略名称 read-hivesampletable-devicemake Hive 数据库 默认 表 hivesampletable Hive 列 clientid、devicemake 选择用户 hiveuser2 权限 选择
创建 Hive ODBC 数据源
有关如何创建 Hive ODBC 数据源的说明,请参阅创建 Hive ODBC 数据源。
| 属性 | 说明 |
|---|---|
| 数据源名称 | 为数据源提供名称。 |
| 主机 | 输入“CLUSTERNAME.azurehdinsight.cn”。 例如,使用myHDICluster.azurehdinsight.cn。 |
| 端口 | 使用 443。 (此端口从 563 更改为 443。) |
| 数据库 | 使用默认。 |
| Hive 服务器类型 | 选择“Hive Server 2”。 |
| 机制 | 选择Azure HDInsight服务。 |
| HTTP 路径 | 将此字段留空。 |
| 用户名 | 输入 hiveuser1@contoso158.partner.onmschina.cn。 如果域名不同,请更新域名。 |
| 密码 | 输入 hiveuser1 的密码。 |
在保存数据源之前选择“测试”。
将数据从 HDInsight 导入Excel
在上一部分中,你配置了两个策略:hiveuser1 对所有列拥有 select 权限,hiveuser2 对两列拥有 select 权限。 在本部分中,将模拟两个用户将数据导入Excel。
在Excel中打开新的或现有的工作簿。
在数据选项卡中,转到获取数据>从其他源>从 ODBC以打开从 ODBC窗口。
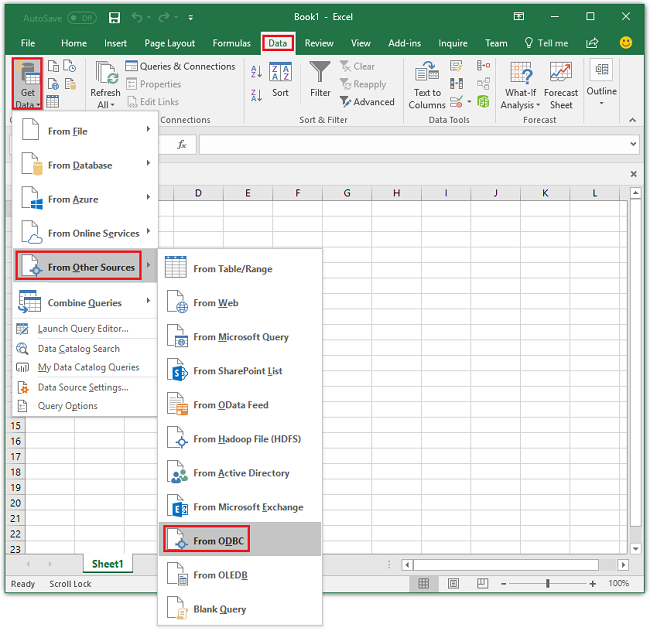
在下拉列表中,选择在上一部分中创建的数据源名称,然后选择“确定”。
第一次使用时,会打开“ODBC 驱动程序”对话框。 从左侧菜单中选择 Windows。 然后选择“连接”以打开“导航器”窗口。
等待
Select Database and Table对话框打开。 此步骤可能需要几秒钟时间。选择hivesampletable>下一步。
选择“完成”。
在“导入数据”对话框中,可以更改或指定查询。 为此,请选择“属性”。 此步骤可能需要几秒钟时间。
选择“定义”选项卡。命令文本为:
SELECT * FROM "HIVE"."default"."hivesampletable"`根据你定义的 Ranger 策略,
hiveuser1对所有列拥有 select 权限。 此查询适用于hiveuser1的凭据,但此查询不适用于hiveuser2的凭据。选择“确定”关闭“连接属性”对话框。
选择“确定”关闭“导入数据”对话框。
重新输入
hiveuser1的密码,然后选择“确定”。 数据导入到Excel前需要几秒钟的时间。 完成后,你会看到 11 列的数据。
若要测试你在最后一部分中创建的第二个策略 (read-hivesampletable-devicemake):
在Excel添加新工作表。
按照上一过程导入数据。 你所做的唯一更改是使用
hiveuser2的凭据而不是hiveuser1。 此操作失败,因为hiveuser2只有权查看两列。 出现以下错误:[Microsoft][HiveODBC] (35) Error from Hive: error code: '40000' error message: 'Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [hiveuser2] does not have [SELECT] privilege on [default/hivesampletable/clientid,country ...]'.按照相同的过程导入数据。 这一次,请使用
hiveuser2的凭据,并修改 select 语句如下:SELECT * FROM "HIVE"."default"."hivesampletable"收件人:
SELECT clientid, devicemake FROM "HIVE"."default"."hivesampletable"完成后,你会看到两列导入的数据。
后续步骤
- 若要配置具有 ESP 的 HDInsight 群集,请参阅配置具有 ESP 的 HDInsight 群集。
- 若要管理具有 ESP 的 HDInsight 群集,请参阅管理具有 ESP 的 HDInsight 群集。
- 若要在具有 ESP 的 HDInsight 群集上使用安全外壳 (SSH) 运行 Hive 查询,请参阅将 SSH 与 HDInsight 配合使用。
- 若要使用 Hive Java 数据库连接(JDBC)连接 Hive,请参阅使用 Hive JDBC 驱动程序连接到 Azure HDInsight 上的 Apache Hive。
- 若要使用 Hive ODBC 驱动程序将 Excel 连接到 Hadoop,请参阅 使用 Azure Hive ODBC 驱动程序将 Excel 连接到 Apache Hadoop。
- 若要使用 Power 查询 将 Excel 连接到 Hadoop,请参阅 使用 Power 查询 将 Excel 连接到 Apache Hadoop。