了解如何从 Java 应用程序使用 JDBC 驱动程序。 在 Azure HDInsight 中向 Apache Hadoop 提交 Apache Hive 查询。 本文档中的信息演示了如何以编程方式从 SQuirreL SQL 客户端进行连接。
有关 Hive JDBC 接口的详细信息,请参阅 HiveJDBCInterface。
先决条件
- HDInsight Hadoop 群集。 要创建一个,请参阅 Azure HDInsight 入门。 确保服务 HiveServer2 正在运行。
- Java 开发人员工具包 (JDK) 版本 11 或更高版本。
- SQuirreL SQL。 SQuirreL 是 JDBC 客户端应用程序。
JDBC 连接字符串
JDBC 通过端口 443 连接到 Azure 上的 HDInsight 群集。 使用 TLS/SSL 保护流量。 公用网关(群集位于其后)会将通信重定向到 HiveServer2 实际进行侦听的端口。 以下连接字符串显示要用于 HDInsight 的格式:
jdbc:hive2://CLUSTERNAME.azurehdinsight.cn:443/default;transportMode=http;ssl=true;httpPath=/hive2
将 CLUSTERNAME 替换为 HDInsight 群集的名称。
连接字符串中的主机名
连接字符串中的主机名“CLUSTERNAME.azurehdinsight.cn”与群集 URL 相同。 可以通过 Azure 门户获取它。
连接字符串中的端口
只能使用端口 443 从 Azure 虚拟网络外部的某个位置连接到群集。 HDInsight 是一种托管服务,这意味着与群集的所有连接都通过安全网关进行管理。 不能直接在端口 10001 或 10000 上连接到 HiveServer 2。 这些端口不向外公开。
身份验证
建立连接时,请使用 HDInsight 群集管理员名称和密码进行身份验证。 在 JDBC 客户端(如 SQuirreL SQL)的客户端设置中输入管理员名称和密码。
从 Java 应用程序建立连接时,必须使用该名称和密码。 例如,以下 Java 代码会打开新的连接:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
使用 SQuirreL SQL 客户端进行连接
SQuirreL SQL 是一个 JDBC 客户端,可用于通过 HDInsight 群集远程运行 Hive 查询。 以下步骤假设已安装 SQuirreL SQL。
创建一个目录来包含要从群集复制的某些文件。
在下面的脚本中,将
sshuser替换为群集的 SSH 用户帐户名。 将CLUSTERNAME替换为 HDInsight 群集名称。 从命令行将工作目录更改为上一步中创建的目录,然后输入以下命令以从 HDInsight 群集复制文件:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.cn:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.cn:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.cn:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .启动 SQuirreL SQL 应用程序。 在窗口左侧中,选择“驱动程序”。

从“驱动程序”对话框顶部的图标中,选择 图标来创建驱动程序。
在“添加的驱动程序”对话框中,添加以下信息:
资产 价值 名称 蜂房 示例 URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2额外类路径 使用“添加”按钮添加此前下载的所有 jar 文件。 类名 org.apache.hive.jdbc.HiveDriver 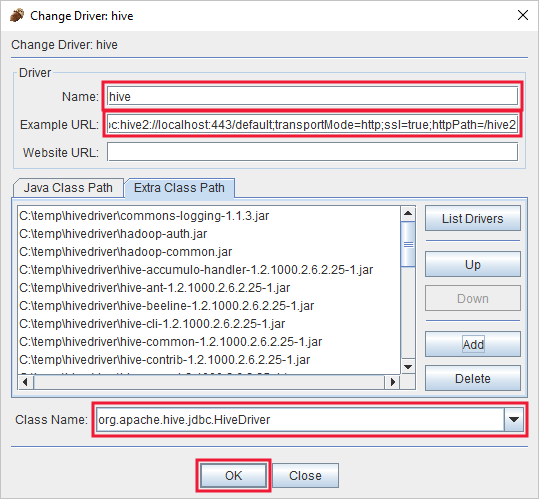
选择“确定”保存这些设置。
在 SQuirreL SQL 窗口左侧,选择“别名”。 然后选择 + 图标来创建连接别名。
将以下值用于“添加别名”对话框:
资产 价值 名称 HDInsight 上的 Hive 司机 使用下拉列表选择 Hive 驱动程序。 网址 jdbc:hive2://CLUSTERNAME.azurehdinsight.cn:443/default;transportMode=http;ssl=true;httpPath=/hive2。 将 CLUSTERNAME 替换为 HDInsight 群集的名称。用户名 HDInsight 群集的群集登录帐户名。 默认值为“admin”。 密码 群集登录帐户的密码。 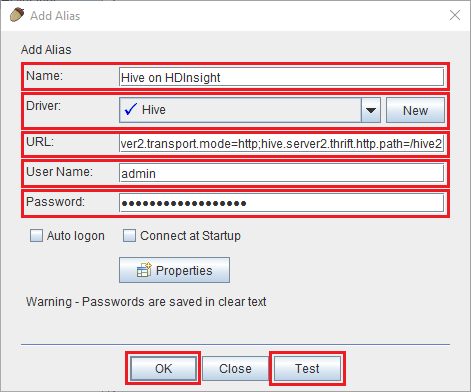
重要
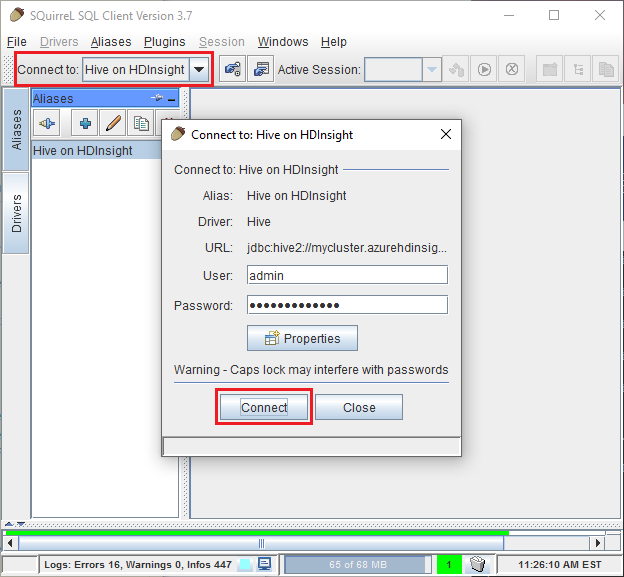
使用“测试”按钮验证连接是否有效。 出现“连接到: Hive on HDInsight”对话框时,选择“连接”执行测试。 如果测试成功,将会显示“连接成功”对话框。 如果发生错误,请参阅故障排除。
若要保存连接别名,请使用“添加别名”对话框底部的“确定”按钮。
在 SQuirreL SQL 顶部的“连接到”下拉列表中,选择“Hive on HDInsight”。 出现提示时选择连接。
连接后,在 SQL 查询对话框中输入以下查询,然后选择“运行”图标(一个正在跑步的人)。 结果区域会显示查询的结果。
select * from hivesampletable limit 10;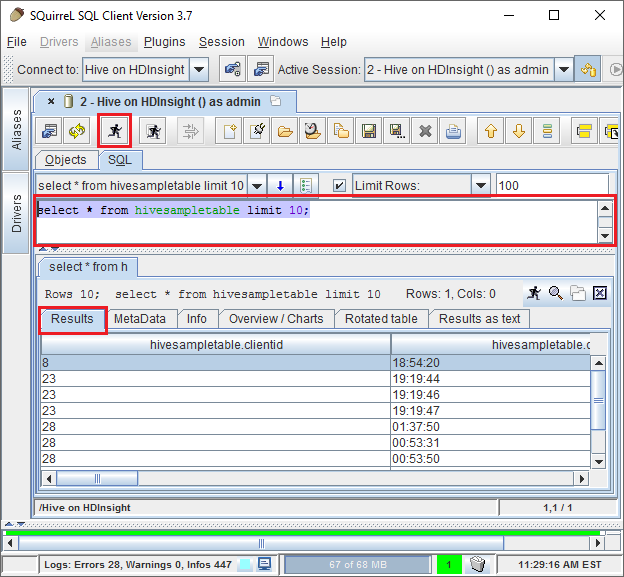
从 Java 应用程序示例进行连接
https://github.com/Azure-Samples/hdinsight-java-hive-jdbc 上提供了使用 Java 客户端查询 Hive on HDInsight 的示例。 按照存储库中的说明生成并运行该示例。
故障排除
尝试打开 SQL 连接时发生意外错误
症状:连接到 HDInsight 群集版本 3.3 或更高版本时,可能会遇到意外错误。 此错误的堆栈跟踪的开头为以下行:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
原因: 此错误由 SQuirreL 随附的较旧版本 commons-codec.jar 文件引起。
解决方法:若要解决此错误,请使用以下步骤:
退出 SQuirreL,并转到系统上安装 SQuirreL 的目录(可能是
C:\Program Files\squirrel-sql-4.0.0\lib)。 在 SquirreL 目录的lib目录下,将现有的 commons-codec.jar 替换为从 HDInsight 群集下载的文件。重新启动 SQuirreL。 连接到 HDInsight 上的 Hive 时,应不再会出现该错误。
HDInsight 断开了连接
症状:HDInsight 在尝试通过 JDBC/ODBC 下载大量数据(例如好几个 GB)时意外断开连接。
原因:网关节点上的限制会导致此错误。 从 JDBC/ODBC 获取数据时,所有数据都需要通过网关节点。 但网关并非设计用于下载大量数据,因此,如果网关无法处理该流量,它可能会关闭连接。
解决方法:避免使用 JDBC/ODBC 驱动程序下载大量数据, 而是直接从 blob 存储复制数据。
后续步骤
现在,你已了解如何将 JDBC 与 Hive 配合使用,请使用以下链接来学习 Azure HDInsight 的其他用法。
- 在 Azure HDInsight 中使用 Microsoft Power BI 直观显示 Apache Hive 数据。
- 在 Azure HDInsight 中使用 Power BI 直观显示交互式查询 Hive 数据。
- 使用 Microsoft Azure Hive ODBC 驱动程序将 Excel 连接到 HDInsight。
- 使用 Power Query 将 Excel 连接到 Apache Hadoop。
- 将 Apache Hive 和 HDInsight 配合使用
- 将 Apache Pig 和 HDInsight 配合使用
- 将 MapReduce 作业与 HDInsight 配合使用