本文介绍了一些最常见的性能优化,可用于提高 Apache Hive 查询的性能。
群集类型选择
在Azure HDInsight中,可以在几个不同的群集类型上运行 Apache Hive 查询。
选择适当的群集类型,以便根据工作负荷需求优化性能:
- 选择 Interactive Query 群集类型以针对
ad hoc交互式查询进行优化。 - 选择 Apache Hadoop 群集类型可以优化用作批处理的 Hive 查询。
- 如果你正在运行这些任务,Spark 和 HBase 群集类型也可以运行 Hive 查询,并且可能适合。
关于在各种 HDInsight 群集类型上运行 Hive 查询的更多信息,请参阅 什么是 Apache Hive 和 HiveQL 在 Azure HDInsight?。
扩展工作节点
增加 HDInsight 群集中的工作器节点数可以利用更多的映射器和减速器来并行运行工作。 在 HDInsight 中,可通过两种方式进行横向扩展:
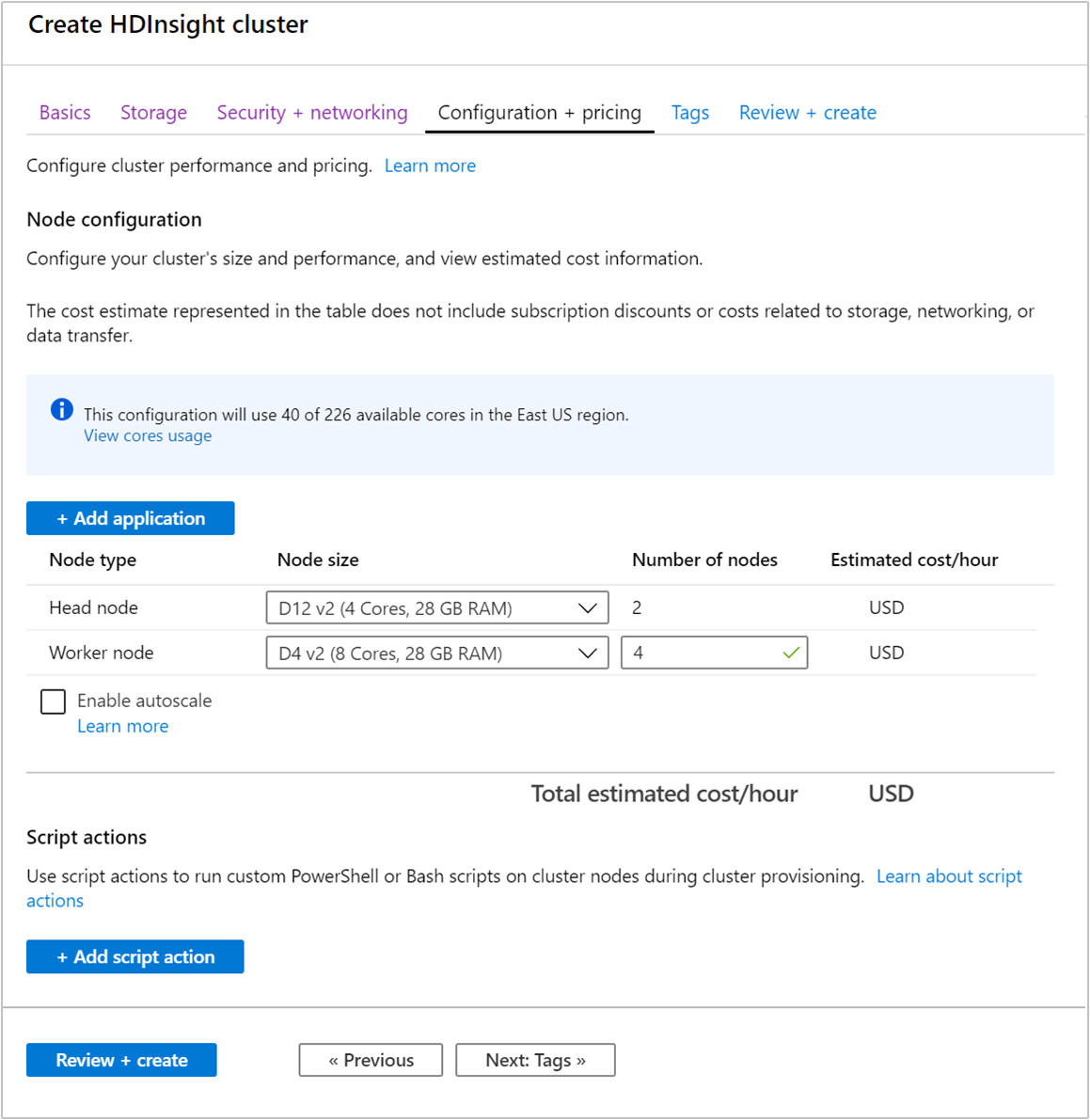
创建群集时,可以使用Azure门户、Azure PowerShell或命令行接口指定工作器节点数。 有关详细信息,请参阅创建 HDInsight 群集。 以下屏幕截图显示了Azure门户中的工作器节点配置:
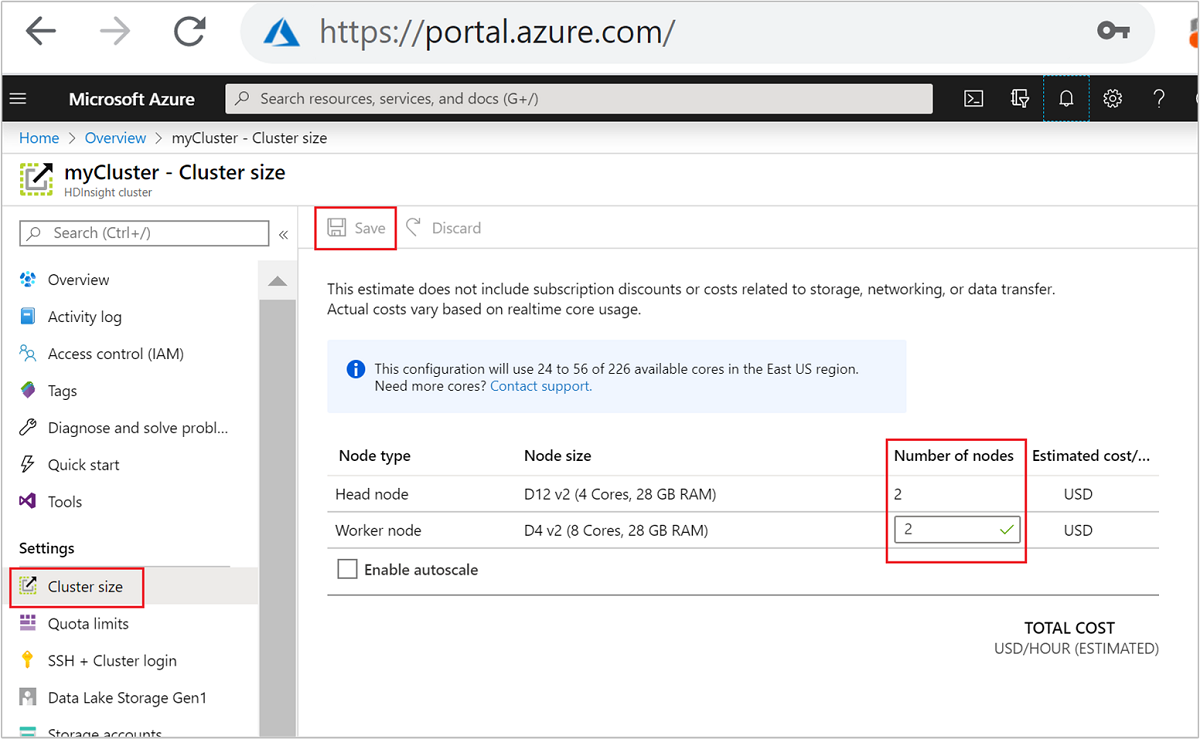
创建后,还可以通过编辑工作节点的数目来进一步横向扩展群集,而无需重新创建:
有关缩放 HDInsight 的详细信息,请参阅缩放 HDInsight 群集
使用 Apache Tez 而不是 Map Reduce
Apache Tez 是 MapReduce 引擎的替代执行引擎。 基于 Linux 的 HDInsight 群集在默认情况下会启用 Tez。
Tez 速度更快,因为:
- 作为 MapReduce 引擎中的单个作业执行有向无环图 (DAG) 。 DAG 要求每组映射器后接一组化简器。 此要求会导致针对每个 Hive 查询运行多个 MapReduce 作业。 Tez 没有此类约束,它可以将复杂的 DAG 作为一个作业进行处理,从而将作业启动开销降至最低。
- 避免不必要的写入。 多个作业用于处理 MapReduce 引擎中的同一 Hive 查询。 每个 MapReduce 作业的输出将作为中间数据写入 HDFS。 Tez 最大程度地减少了 Hive 查询所需的作业数,能够避免不必要的写入。
- 最大限度地降低启动延迟。 Tez 可以通过减少需要启动的映射器数量并改进整体优化,从而更好地最大限度地降低启动延迟。
- 再利用容器。 Tez 会尽可能地重复使用容器,以确保降低因启动容器而产生的延迟。
- 连续优化技术。 传统上,优化是在编译阶段完成的。 但是,由于可以提供有关输入的详细信息,因此可以在运行时更好地进行优化。 Tez 使用连续优化技术,从而可以在运行时阶段进一步优化计划。
有关这些概念的详细信息,请参阅 Apache TEZ。
可以通过在查询前添加以下 set 命令,使任何 Hive 查询支持 Tez:
set hive.execution.engine=tez;
Hive 分区
I/O 操作是运行 Hive 查询的主要性能瓶颈。 如果可以减少需要读取的数据量,即可改善性能。 默认情况下,Hive 查询会扫描整个 Hive 表。 但是,对于只需扫描少量数据的查询(例如,使用筛选进行查询),此行为会产生不必要的开销。 使用 Hive 分区,Hive 查询只需访问 Hive 表中必要的数据量。
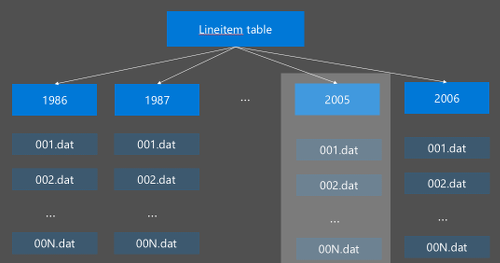
Hive 分区的实现方法是将原始数据重新组织成新目录。 每个分区都有自身的文件目录。 用户定义分区。 下图说明如何根据 Year 列来分区 Hive 表。 每年都会创建新的目录。
一些分区注意事项:
- 不要分区不足 - 根据仅包含少量值的列进行分区可能导致创建很少的分区。 例如,基于性别进行分区只会导致两个分区(男性和女性),因此最多可以将延迟减少一半。
- 不要创建过多分区 - 另一种极端情况是,根据包含唯一值的列(例如,userid)创建分区会导致创建多个分区。 过多的分区会给集群的 namenode 带来很大压力,因为它必须处理大量的目录。
- 避免数据倾斜 - 明智选择分区键,以便所有分区的大小均等。 例如,按“州”列分区可能会导致数据分布出现偏斜。 因为加利福尼亚州的人口几乎是佛蒙特州的 30 倍,分区大小可能会出现偏差,性能可能有极大的差异。
要创建分区表,请使用 Partitioned By 子句:
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
创建分区表后,可以创建静态分区或动态分区。
静态分区表示已在相应目录中创建了分片数据。 使用静态分区可以根据目录位置手动添加 Hive 分区。 以下代码片段是一个示例。
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.chinacloudapi.cn/partitions/5_23_1996/'动态分区 表示希望 Hive 自动创建分区。 因为已基于临时表创建了分区表,所以需要做的就是将数据插入分区表:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
有关详细信息,请参阅分区表。
使用 ORCFile 格式
Hive 支持不同的文件格式。 例如:
- 文本:默认的文件格式,适用于大多数情况。
- Avro:非常适合互操作性方案。
- ORC/Parquet:最适合用于提高性能。
ORC(优化行纵栏式)格式是存储 Hive 数据的高效方式。 与其他格式相比,ORC 具有以下优点:
- 支持复杂类型(包括 DateTime)和复杂的半结构化类型。
- 压缩比可高达 70%。
- 每 10,000 行编制一次索引,从而允许跳过行。
- 大幅减少运行时执行时间。
要启用 ORC 格式,请先使用 Stored as ORC子句创建一个表:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
接下来,您将数据从暂存表插入到 ORC 表中。 例如:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
可在 Apache Hive 语言手册中阅读有关 ORC 格式的详细信息。
向量化
向量化可让 Hive 以批的形式同时处理 1024 行,而不是一次处理一行。 这意味着,简单的操作可以更快地完成,因为需要运行的内部代码更少。
要启用向量化,请在 Hive 查询的前面加上以下设置作为前缀:
set hive.vectorized.execution.enabled = true;
有关详细信息,请参阅 向量化查询执行。
其他优化方法
还可以考虑使用其他一些高级优化方法,例如:
- Hive 分桶: 一种将大型数据集分段或分组以优化查询性能的技术。
- 连接优化: Hive 的查询执行计划优化,以提高连接的效率并减少对用户提示的需求。 有关详细信息,请参阅 联接优化。
- 增加化简器。
后续步骤
在本文中,学习了几种常见的 Hive 查询优化方法。 要了解更多信息,请参阅下列文章: