HDInsight 提供弹性,可让你选择纵向扩展和纵向缩减群集中的工作器节点数。 这种弹性允许你在若干小时后或者在周末收缩群集。 还可以在业务需求高峰期扩展群集。
在定期批处理之前纵向扩展群集,使群集拥有足够的资源。 在完成处理并且用量下降后,可将 HDInsight 群集纵向缩减为使用更少的工作器节点。
可以使用以下方法之一手动缩放群集。 也可使用自动缩放选项来自动纵向缩放以响应某些指标。
注意
只支持使用 HDInsight 3.1.3 或更高版本的群集。 如果不确定群集的版本,可以查看“属性”页面。
用来缩放群集的实用程序
Azure 提供以下实用程序来缩放群集:
| 实用工具 | 说明 |
|---|---|
| PowerShell Az | Set-AzHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| PowerShell AzureRM | Set-AzureRmHDInsightClusterSize -ClusterName CLUSTERNAME -TargetInstanceCount NEWSIZE |
| Azure CLI | az hdinsight resize --resource-group RESOURCEGROUP --name CLUSTERNAME --workernode-count NEWSIZE |
| Azure 经典 CLI | azure hdinsight cluster resize CLUSTERNAME NEWSIZE |
| Azure 门户 | 打开 HDInsight 群集的窗格,在左侧菜单中选择“群集大小”,然后在“群集大小”窗格中键入工作节点数并选择“保存”。 |
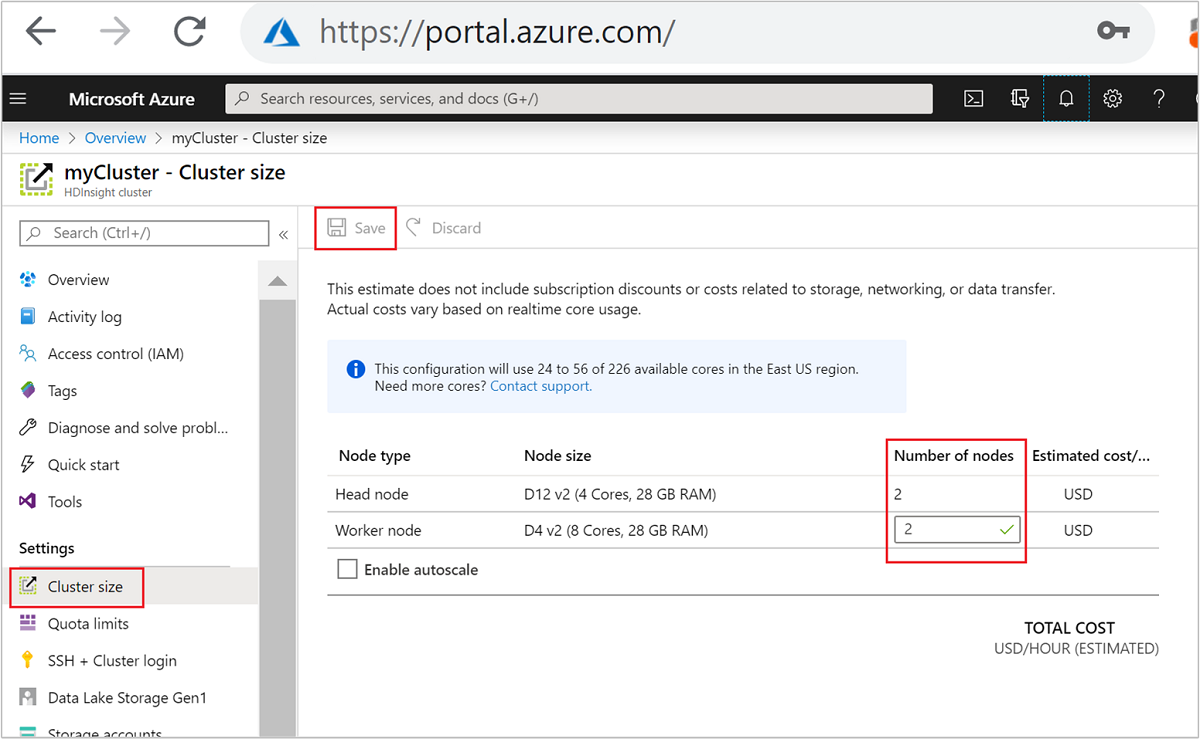
使用以下任一方法可在几分钟之内扩展或缩放 HDInsight 群集。
重要
缩放操作的影响
将节点添加到正在运行的 HDInsight 群集时(纵向扩展)时,作业不受影响。 在运行缩放过程时,可以安全提交新作业。 如果缩放操作失败,此类失败会让群集保持正常运行状态。
如果删除节点(纵向缩减),则在缩放操作完成时,挂起的或正在运行的作业将会失败。 此失败的原因是某些服务在缩放过程中重启。 在手动缩放操作过程中,群集可能会停滞在安全模式。
对于 HDInsight 支持的每种类型的群集,更改数据节点数的影响有所不同:
Apache Hadoop
可无缝增加正在运行的 Hadoop 群集中的工作器节点数,而不会影响任何作业。 也可在操作进行中提交新作业。 缩放操作中的失败会得到妥善处理。 群集始终保持正常运行状态。
当 Hadoop 群集纵向缩减为使用较少的数据节点时,一些服务会重启。 此行为会导致所有正在运行和挂起的作业在缩放操作完成时失败。 但是,可在操作完成后重新提交这些作业。
Apache HBase
可在 HBase 群集运行时无缝添加或删除节点。 完成缩放操作后的几分钟内,区域服务器自动平衡。 不过,也可以手动平衡区域服务器。 登录到群集头节点并运行以下命令:
pushd %HBASE_HOME%\bin hbase shell balancer有关使用 HBase shell 的详细信息,请参阅 HDInsight 中的 Apache HBase 示例入门。
注意
不适用于 Kafka 群集。
Apache Hive LLAP
缩放到
N个工作器节点后,HDInsight 将自动设置以下配置并重启 Hive。- 最大总并发查询数:
hive.server2.tez.sessions.per.default.queue = min(N, 32) - Hive 的 LLAP 使用的节点数:
num_llap_nodes = N - 运行 Hive LLAP 守护程序的节点数:
num_llap_nodes_for_llap_daemons = N
- 最大总并发查询数:
如何安全地纵向缩减群集
通过运行的作业纵向缩减群集
为了避免运行的作业在纵向缩减操作过程中失败,可以尝试三项操作:
- 等待作业完成之后再纵向缩减群集。
- 手动结束作业。
- 在缩放操作完成后重新提交这些作业。
若要查看挂起的和正在运行的作业列表,可以遵循以下步骤使用 YARN“资源管理器 UI”:
从 Azure 门户中,选择群集。 群集会在新的门户页中打开。
在主视图中,导航到“群集仪表板”>“Ambari 主页”。 输入群集凭据。
在 Ambari UI 的左侧菜单中的服务列表内选择“YARN”。
在“YARN”页中选择“快速链接”,将鼠标悬停在活动头节点上,然后选择“资源管理器 UI”。
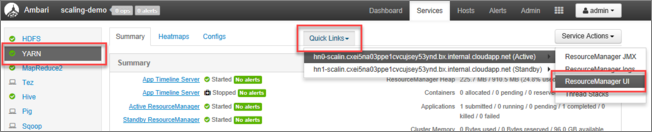
可以使用 https://<HDInsightClusterName>.azurehdinsight.cn/yarnui/hn/cluster 直接访问资源管理器 UI。
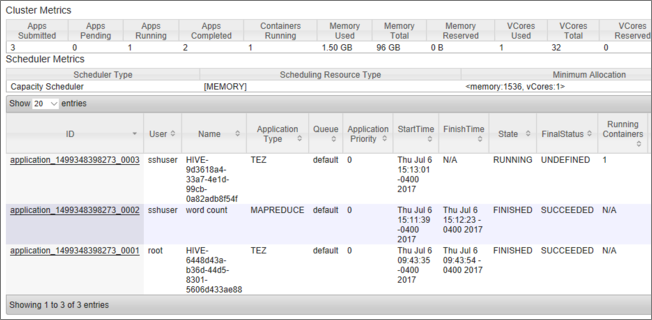
可以看到作业及其当前状态的列表。 在屏幕截图中,当前有一个作业正在运行:
若要手动终止正在运行的应用程序,请通过 SSH shell 执行以下命令:
yarn application -kill <application_id>
例如:
yarn application -kill "application_1499348398273_0003"
停滞在安全模式下
纵向缩减群集时,HDInsight 使用 Apache Ambari 管理接口先停用额外的工作器节点。 节点将其 HDFS 块复制到其他联机工作器节点。 然后,HDInsight 安全地纵向缩减群集。 HDFS 在缩放操作期间进入安全模式。 HDFS 应该在缩放完成后退出安全模式。 但在某些情况下,HDFS 会在缩放操作期间停滞在安全模式下,因为文件块复制数量不足。
默认情况下,进行 HDFS 配置时,会将 dfs.replication 设置为 1,该项控制每个文件块的可用副本数。 文件块的每个副本存储在群集的不同节点上。
在预期的块副本数不可用时,HDFS 会进入安全模式,此时 Ambari 会生成警报。 HDFS 可能会进入安全模式以进行缩放操作。 如果未检测到复制所需的节点数,则群集可能会停滞在安全模式。
启用安全模式时的错误示例
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /tmp/hive/hive/819c215c-6d87-4311-97c8-4f0b9d2adcf0. Name node is in safe mode.
org.apache.http.conn.HttpHostConnectException: Connect to active-headnode-name.servername.internal.chinacloudapp.cn:10001 [active-headnode-name.servername. internal.chinacloudapp.cn/1.1.1.1] failed: Connection refused
可以查看 /var/log/hadoop/hdfs/ 文件夹中的名称节点日志,以了解缩放群集时群集进入安全模式的大致时间。 日志文件命名为 Hadoop-hdfs-namenode-<active-headnode-name>.*。
根本原因是 Hive 在运行查询时依赖于 HDFS 中的临时文件。 当 HDFS 进入安全模式时,Hive 无法运行查询,因为它无法写入 HDFS。 HDFS 中的临时文件位于装载到各个工作器节点 VM 的本地驱动器中。 这些文件将在其他工作器节点之间复制,并至少提供三个副本。
如何防止 HDInsight 停滞在安全模式下
可通过多种方法防止 HDInsight 保留在安全模式:
- 在缩减 HDInsight 之前停止所有 Hive 作业。 或者,计划好纵向缩减进程,以避免与运行中的 Hive 作业冲突。
- 执行缩减操作之前,在 HDFS 中手动清理 Hive 的 scratch
tmp目录文件。 - 只将 HDInsight 纵向缩减为三个工作节点(最少数量)。 避免将工作节点数减少至一个。
- 根据需要运行命令来退出安全模式。
以下部分将介绍这些选项。
停止所有 Hive 作业
在缩减至一个工作节点之前停止所有 Hive 作业。 如果已计划工作负荷,请在完成 Hive 工作后执行缩减。
在缩放之前停止 Hive 作业有助于将临时文件夹中的 scratch 文件(如果有)的数目减至最少。
手动清理 Hive 的 scratch 文件
如果 Hive 遗留了临时文件,可以在缩减之前手动清理这些文件,以避免进入安全模式。
通过查看
hive.exec.scratchdir配置属性,了解用于 Hive 临时文件的具体位置。 此参数在/etc/hive/conf/hive-site.xml中设置:<property> <name>hive.exec.scratchdir</name> <value>hdfs://mycluster/tmp/hive</value> </property>停止 Hive 服务,并确保所有查询和作业都已完成。
列出在上面找到的 scratch 目录
hdfs://mycluster/tmp/hive/的内容,看其是否包含任何文件:hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive下面是存在文件时的示例输出:
sshuser@scalin:~$ hadoop fs -ls -R hdfs://mycluster/tmp/hive/hive drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c drwx------ - hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/_tmp_space.db -rw-r--r-- 3 hive hdfs 27 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.info -rw-r--r-- 3 hive hdfs 0 2017-07-06 13:40 hdfs://mycluster/tmp/hive/hive/4f3f4253-e6d0-42ac-88bc-90f0ea03602c/inuse.lck drwx------ - hive hdfs 0 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699 -rw-r--r-- 3 hive hdfs 26 2017-07-06 20:30 hdfs://mycluster/tmp/hive/hive/c108f1c2-453e-400f-ac3e-e3a9b0d22699/inuse.info如果知道 Hive 已处理这些文件,则可以删除这些文件。 查看 Yarn 资源管理器 UI 页,确保 Hive 中没有任何正在运行的查询。
用于从 HDFS 中删除文件的示例命令行:
hadoop fs -rm -r -skipTrash hdfs://mycluster/tmp/hive/
缩减 HDInsight 时保持三个或更多个工作器节点
如果将群集纵向缩减到少于三个工作器节点,群集通常会停滞在安全模式,因此,请至少保留三个工作器节点。
与纵向缩减到仅一个工作器节点相比,拥有三个工作器节点的成本更高。 但是,此操作将防止群集停滞在安全模式。
将 HDInsight 缩减到一个工作器节点
即使群集纵向缩减到 1 个节点,工作器节点 0 仍将继续存在。 永远不能停用工作器节点 0。
运行命令来退出安全模式。
最后一种做法是执行退出安全模式的命令。 如果 HDFS 进入安全模式的原因是 Hive 文件复制数量不足,请执行以下命令退出安全模式:
hdfs dfsadmin -D 'fs.default.name=hdfs://mycluster/' -safemode leave
纵向缩减 Apache HBase 群集
在完成缩放操作后的几分钟内,区域服务器会自动进行均衡。 若要手动均衡区域服务器,请完成以下步骤:
使用 SSH 连接到 HDInsight 群集。 有关详细信息,请参阅 将 SSH 与 HDInsight 配合使用。
启动 HBase shell:
hbase shell使用以下命令手动均衡区域服务器:
balancer
后续步骤
有关缩放 HDInsight 群集的特定信息,请参阅: