Azure HDInsight 的复制机制可集成到高度可用的解决方案体系结构中。 在本文中,一个虚构的 Contoso Retail 案例研究用于解释可能的高可用性灾难恢复方法、成本考虑因素及其相应的设计。
高可用性灾难恢复建议可以有许多排列和组合。 这些解决方案是在考虑每个选项的利弊后得出的。 本文仅讨论一种可能的解决方案。
客户体系结构
下图描绘了 Contoso Retail 的主要体系结构。 该体系结构包含流式处理工作负载、批处理工作负载、服务层、消耗层、存储层和版本控制。
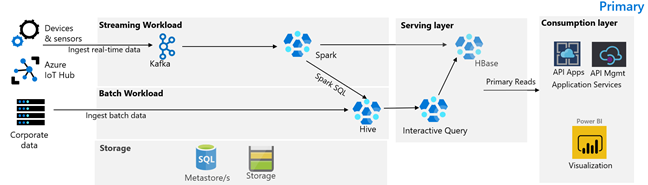
流式处理工作负载
设备和传感器将数据生成到 HDInsight Kafka,后者构建消息传送框架。 HDInsight Spark 使用者从 Kafka 主题读取数据。 Spark 转换传入的消息,并将其写入到服务层上的 HDInsight HBase 群集。
批处理工作负荷
运行 Hive 和 MapReduce 的 HDInsight Hadoop 群集从本地事务系统中引入数据。 Hive 和 MapReduce 转换的原始数据存储在由 Azure Data Lake Storage Gen2 提供支持的数据湖的逻辑分区上的 Hive 表中。 存储在 Hive 表中的数据还可供 Spark SQL 使用,Spark SQL 在将特选数据存储在 HBase 中以供使用之前执行批量转换。
服务层
包含 Apache Phoenix 的 HDInsight HBase 群集用于向 Web 应用程序和可视化效果仪表板提供数据。 HDInsight LLAP 群集用于满足内部报告要求。
消耗层
Azure API 应用和 API 管理层为面向公众的网页提供支持。 内部报告要求由 Power BI 来满足。
存储层
进行了逻辑分区的 Azure Data Lake Storage Gen2 将用作企业数据湖。 HDInsight 元存储由 Azure SQL DB 提供支持。
版本控制系统
集成到 Azure Pipelines 中并在 Azure 外部承载的版本控制系统。
客户业务连续性要求
确定发生灾难时所需的最低业务功能非常重要。
Contoso Retail 的业务连续性要求
- 我们必须防范区域性故障或区域性服务运行状况问题。
- 我的客户不得看到 404 错误。 必须始终提供公共内容。 (RTO = 0)
- 在一年的大部分时间里,我们可以显示过时 5 小时的公共内容。 (RPO = 5 小时)
- 在节假日期间,面向公众的内容必须始终保持最新状态。 (RPO = 0)
- 我的内部报告要求对业务连续性并不重要。
- 优化业务连续性成本。
建议的解决方案
下图显示了 Contoso Retail 的高可用性灾难恢复体系结构。
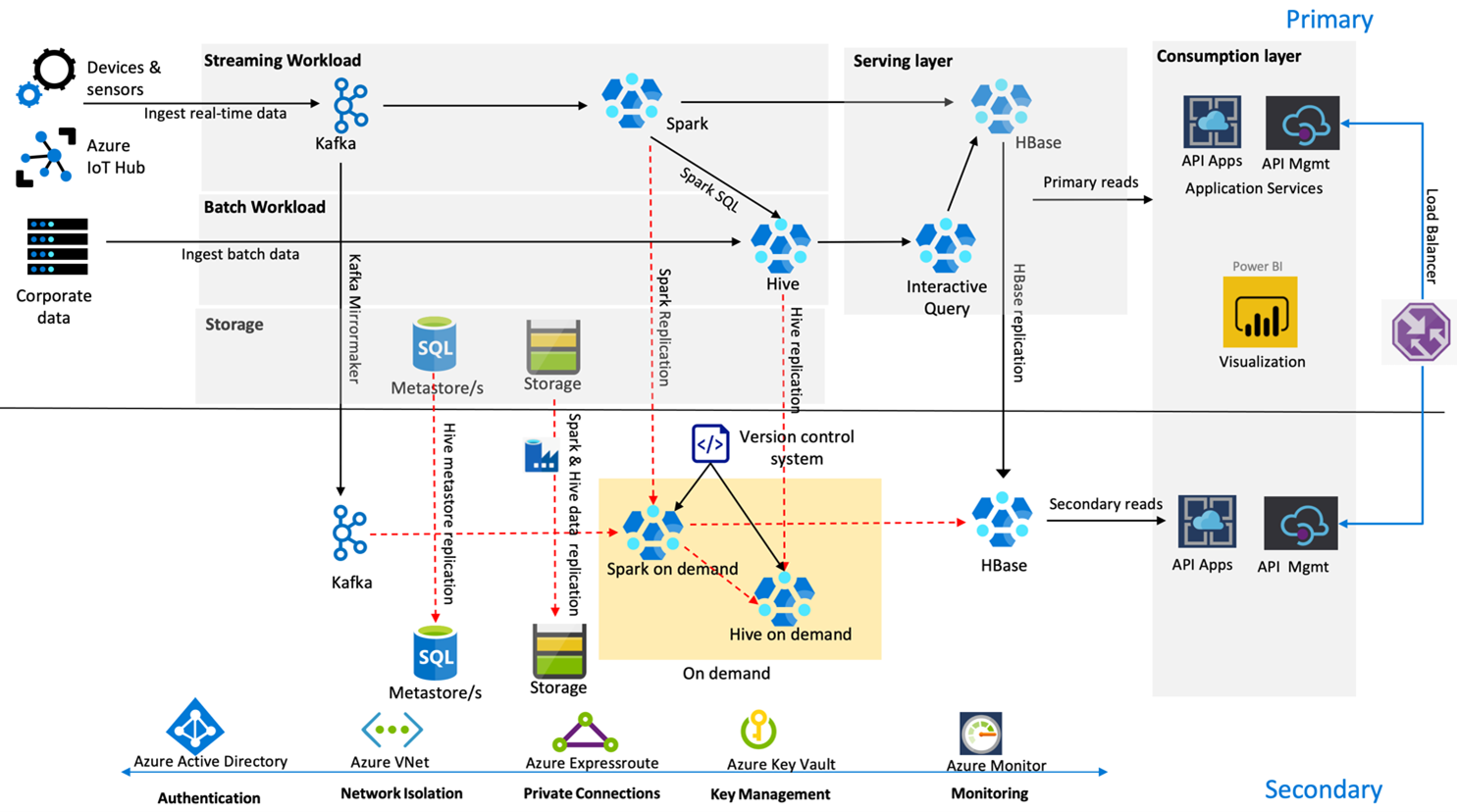
Kafka 使用 主动 - 被动 复制将 Kafka 主题从主要区域镜像到次要区域。 Kafka 复制的替代方法是在这两个区域中都生成 Kafka。
Hive 和 Spark 在常规情况下使用主动主 - 按需次要复制模型。 Hive 复制过程会定期运行,同时还会进行 Hive Azure SQL 元存储和 Hive 存储帐户复制。 Spark 存储帐户使用 ADF DistCP 定期进行复制。 这些群集的暂时性特性有助于优化成本。 复制安排为每 4 小时进行一次,这样达到的 RPO 可确保符合 5 小时的要求。
HBase 复制在正常情况下使用 Leader - Follower 模型,以确保无论区域如何,数据始终可用,并且 RPO 非常低。
如果主要区域发生区域性故障,则会从辅助区域提供 5 小时的网页和后端内容,并存在一定程度的陈旧性。 如果 Azure 服务运行状况仪表板在 5 小时期限内未指示恢复 ETA,Contoso Retail 将在辅助区域中创建 Hive 和 Spark 转换层,然后将所有上游数据源指向辅助区域。 使辅助区域可写会导致执行故障回复过程,该过程涉及复制回主要区域。
在购物高峰季,整个辅助管道始终处于活动和运行状态。 Kafka 生成者同时向这两个区域生成数据,HBase 复制将从“领导者-追随者”更改为“领导者-领导者”,以确保面向公众的内容始终处于最新状态。
无需为内部报告设计故障转移解决方案,因为它对于业务连续性并不重要。
后续步骤
要详细了解本文中所述项目,请参阅: