本文提供了一些可以考虑Azure HDInsight的业务连续性体系结构示例。 对于灾难期间功能降低的容忍度是一个业务决策,每个应用程序都会有所不同。 对于某些应用程序,可以接受其不可用,或者部分可用但功能降低,或者处理操作延迟一段时间。 对于另一些应用程序,任何功能降低可能都是不可接受的。
注意
本文中介绍的体系结构并不是详尽无遗的。 在对预期的业务连续性、运营复杂性和拥有成本做出客观的判断后,你应该设计自己独特的体系结构。
Apache Hive 和 Interactive Query
为了在 HDInsight Hive 和 Interactive Query 群集中实现业务连续性,建议使用 Hive Replication V2。 需要复制的独立 Hive 群集的永久部分是存储层和 Hive 元存储。 具有企业安全性套餐的多用户场景中的 Hive 群集需要 Microsoft Entra Domain Services 和 Ranger 元数据存储。
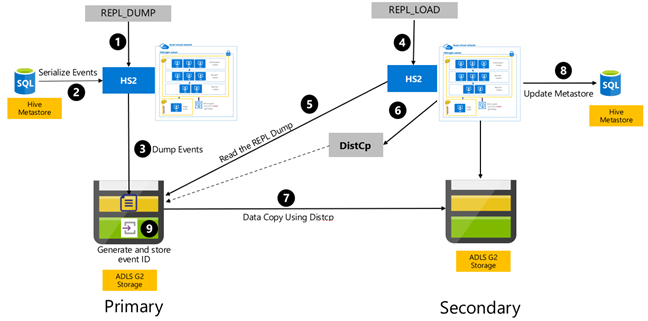
Hive 基于事件的复制是在主群集与辅助群集之间配置的。 这包括两个不同的阶段,即启动和增量运行:
“启动”会将整个 Hive 仓库(包括 Hive 元存储信息)从主群集复制到辅助群集。
增量运行在主群集上自动进行,在增量运行期间生成的事件会在辅助群集上回放。 辅助群集的事件会跟上从主群集生成的事件的进度,确保辅助群集的事件在复制运行后与主群集的事件一致。
只有在复制时才需要使用辅助群集来运行分布式复制 DistCp,但是存储和元存储需要是永久性的。 你可以选择在复制之前按需启动脚本化的辅助群集,在其上运行复制脚本,然后在成功复制后将其销毁。
备用集群通常是只读的。 你可以将辅助群集设置为可读写的,但这会增加额外的复杂性,涉及将更改从辅助群集复制到主群集。
Hive 基于事件的复制 RPO 和 RTO
RPO:数据丢失限制为从主群集到辅助群集的最后一个成功的增量复制事件。
RTO:故障之后恢复与次级系统进行的上游和下游事务所需的时间。
Apache Hive 和交互式查询体系结构
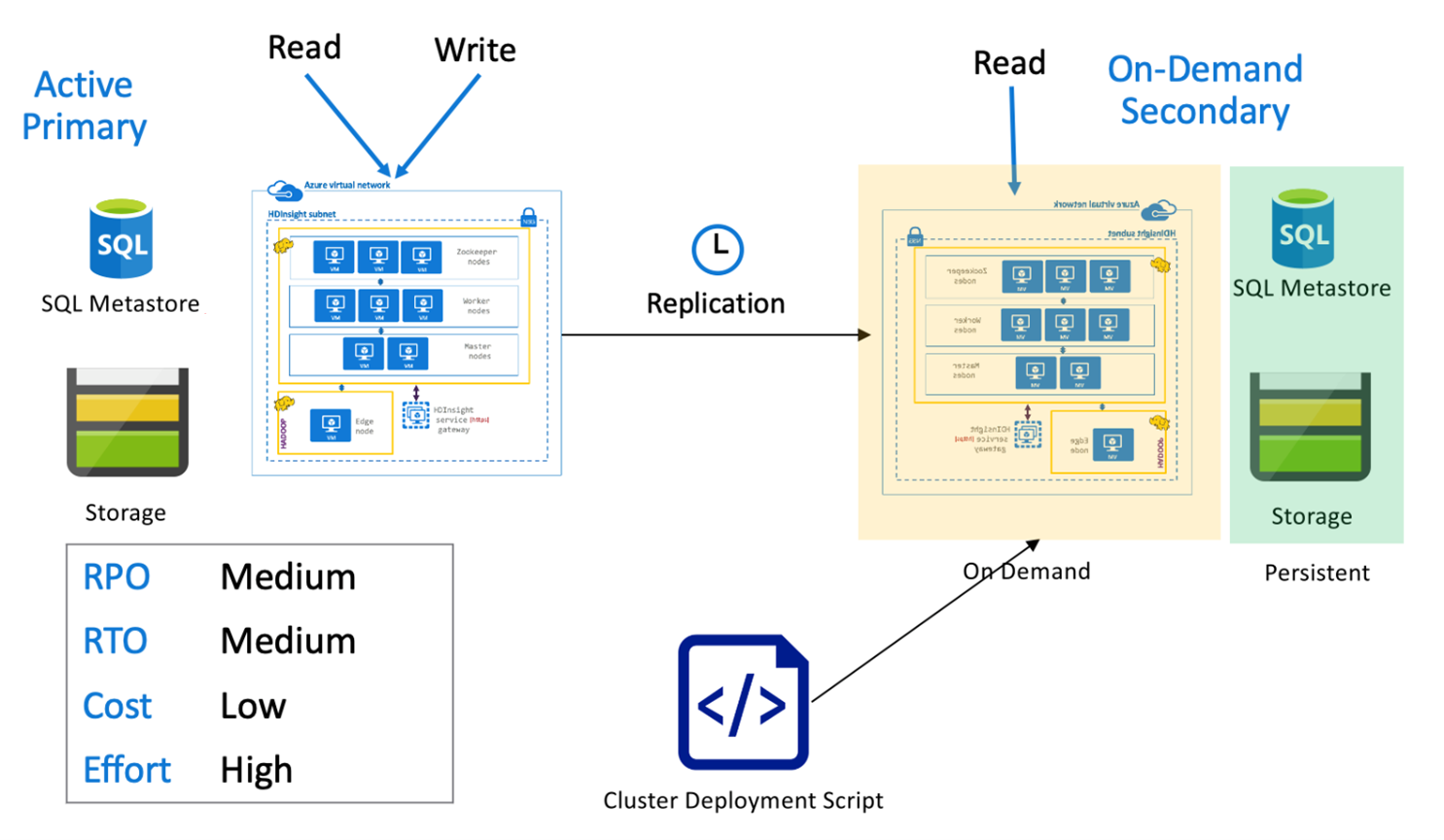
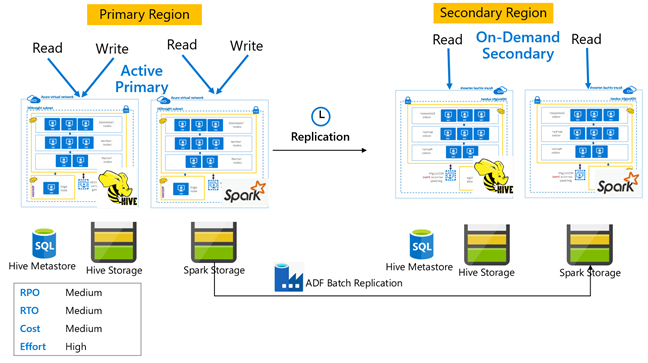
与按需辅助群集配合使用的 Hive 主动主群集
在主动主节点与按需辅助节点架构中,应用程序在正常操作期间会写入主动主节点区域,而辅助区域不会预配任何群集。 在辅助区域中,SQL Metastore 和存储是持久的,而 HDInsight 群集则是在计划的 Hive 复制运行之前才根据需求编写脚本并部署。
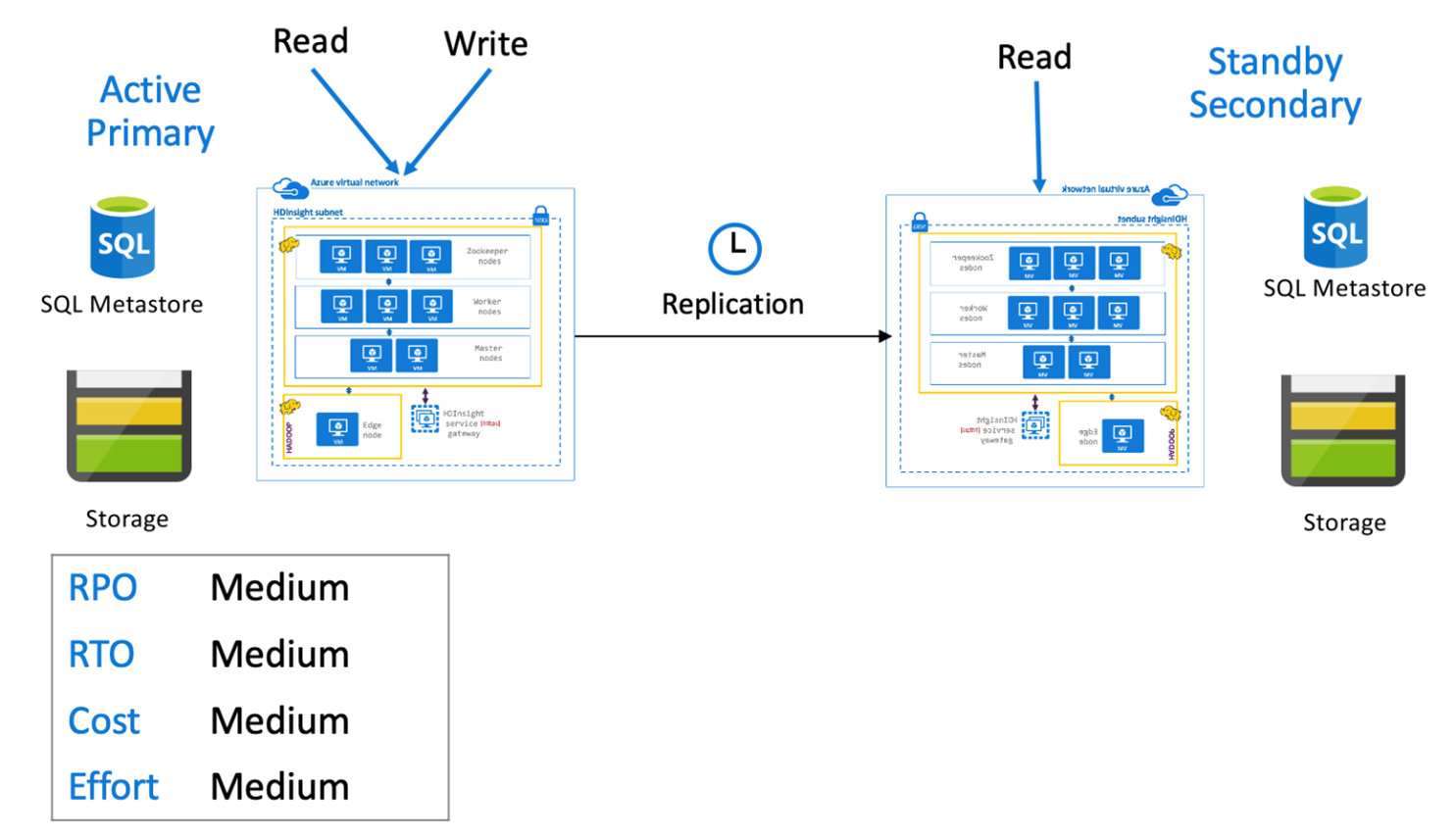
Hive 主动主节点与备用从节点
在“主动主与备用辅助”体系结构中,应用程序在正常操作期间写入主区域,而备用缩减辅助群集在只读模式下运行。 在正常操作期间,你可以选择将特定于区域的读取操作负荷转移到辅助区域。
有关 Hive 复制和代码示例的详细信息,请参阅 Azure HDInsight 群集中的 Apache Hive 复制
Apache Spark
Spark 工作负荷可能涉及也可能不涉及 Hive 组件。 为了使 Spark SQL 工作负荷能够从 Hive 读取和写入数据,HDInsight Spark 群集共享来自同一区域中的 Hive/Interactive Query 群集的 Hive 自定义元存储。 在这种情况下,Spark 工作负荷的跨区域复制还必须伴随着 Hive 元存储和存储的复制。 本部分的故障转移方案适用于以下两种情况:
- 使用 HDInsight Interactive Query 群集设置通过 Hive Warehouse Connector(HWC)访问 ACID 表的 Spark SQL。
- 使用 HDInsight Hadoop 群集的非 ACID 表上的 Spark SQL 工作负荷。
对于 Spark 在独立模式下工作的情况,需要使用 Azure Data Factory 的 DistCP 定期将特选数据和存储的 Spark Jar(适用于 Livy 作业)从主要区域复制到次要区域。
建议你使用版本控制系统来存储 Spark 笔记本和库,这样可以轻松将它们部署在主群集或辅助群集上。 请确保基于笔记本的解决方案和不基于笔记本的解决方案都已准备就绪,以在主工作区或辅助工作区中加载正确的数据装载内容。
如果有特定于客户的库,但这些库超出了 HDInsight 本身的提供能力,则必须对其进行跟踪,并定期将其加载到备用辅助群集。
Apache Spark 复制 RPO 和 RTO
RPO:数据丢失仅限于从主数据库到备数据库的最后一次成功的增量复制(Spark 和 Hive)。
RTO:故障之后恢复与次级系统进行的上游和下游事务所需的时间。
Apache Spark 体系结构
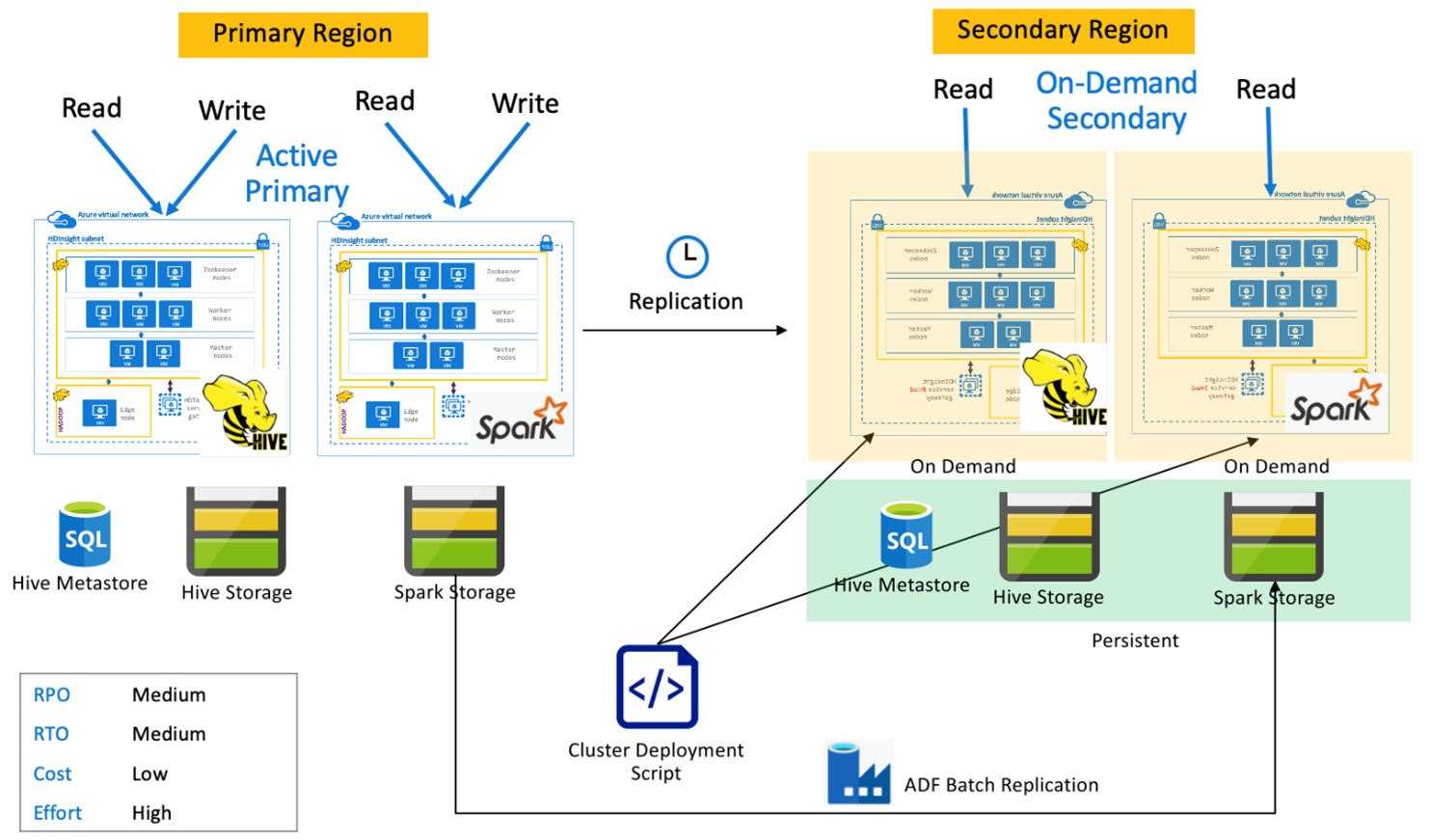
与按需辅助群集配合使用的 Spark 主动主群集
在正常操作期间,应用程序在主区域中的 Spark 和 Hive 群集上进行读取和写入,不在辅助区域中预配任何群集。 SQL 元存储、Hive 存储和 Spark 存储在辅助区域中持久存在。 针对 Spark 和 Hive 群集按需编写脚本并进行部署。 Hive 复制用于复制 Hive 存储和 Hive 元存储,而 Azure Data Factory 的 DistCP 可用于复制独立的 Spark 存储。 由于进行依赖关系 DistCp 计算,每次运行 Hive 复制之前都需要部署 Hive 群集。
与备用辅助群集配合使用的 Spark 主动主群集
在正常运行期间,应用程序在主区域中的 Spark 和 Hive 集群上进行读取和写入,而辅助区域中的待命缩减 Hive 和 Spark 集群以只读模式运行。 在正常操作期间,你可以选择将特定于区域的 Hive 和 Spark 读取操作负荷转移到辅助区域。
Apache HBase
HBase 导出和 HBase 复制是在 HDInsight HBase 群集之间实现业务连续性的常用方法。
HBase 导出是一个批处理复制过程,它使用 HBase 导出实用工具将表从主 HBase 群集导出到其基础 Azure Data Lake Storage Gen 2 存储。 然后,可以从辅助 HBase 群集访问导出的数据,并将其导入到辅助群集中必须事先存在的表中。 尽管 HBase 导出提供了表级粒度,但在增量更新的情况下,导出自动化引擎将控制每次运行中包含的增量行范围。 有关详细信息,请参阅 HDInsight HBase 备份和复制。
HBase 复制通过完全自动化的方式实现 HBase 集群之间的近实时复制。 复制在表级别进行。 可以将所有表或特定表作为复制的目标。 HBase 复制是最终一致性的,这意味着最近对主区域表的编辑信息可能不会立即可用于所有从属节点。 辅助区域保证最终会变得与主区域一致。 在以下情况下,可以在两个或多个 HDInsight HBase 群集之间设置 HBase 复制:
- 主群集和辅助群集位于同一虚拟网络中。
- 主群集和辅助群集位于同一区域中对等互连的不同 VNet 中。
- 主群集和辅助群集位于不同区域中对等互连的不同 VNet 中。
有关详细信息,请参阅 在 Azure 虚拟网络中设置 Apache HBase 群集复制。
还有一些其他方式可用来执行 HBase 群集的备份,例如复制 hbase 文件夹、复制表和快照。
HBase RPO 和 RTO
HBase 导出
- RPO:数据丢失限制为辅助群集从主群集执行的最后一次成功的批量增量导入。
- RTO:主群集上发生故障与辅助群集上的 I/O 操作恢复之间的时间间隔。
HBase 复制
- RPO:数据丢失限制为在辅助群集上收到的最后一次 WalEdit 发货。
- RTO:主群集上发生故障与辅助群集上的 I/O 操作恢复之间的时间间隔。
HBase 体系结构
可以采用三种模式设置 HBase 复制:“领导者-追随者”、“领导者-领导者”和“循环”。
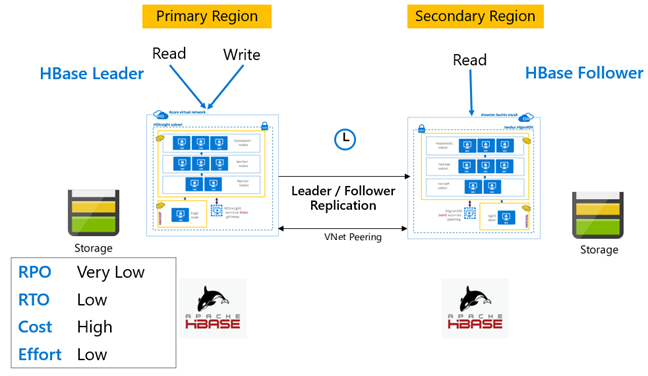
HBase 复制:“领导者-追随者”模型
在此跨区域设置中,复制从主区域到辅助区域单向进行。 可以在主数据库中标识要进行单向复制的所有表或特定表。 在正常操作期间,辅助群集可用于处理其自己的区域中的读取请求。
辅助群集作为普通的 HBase 群集运行,它可以承载自己的表,并且可以处理区域应用程序的读写操作。 但是,在已复制的表或属于辅助群集原有的表上进行的写入不会被复制回主群集。
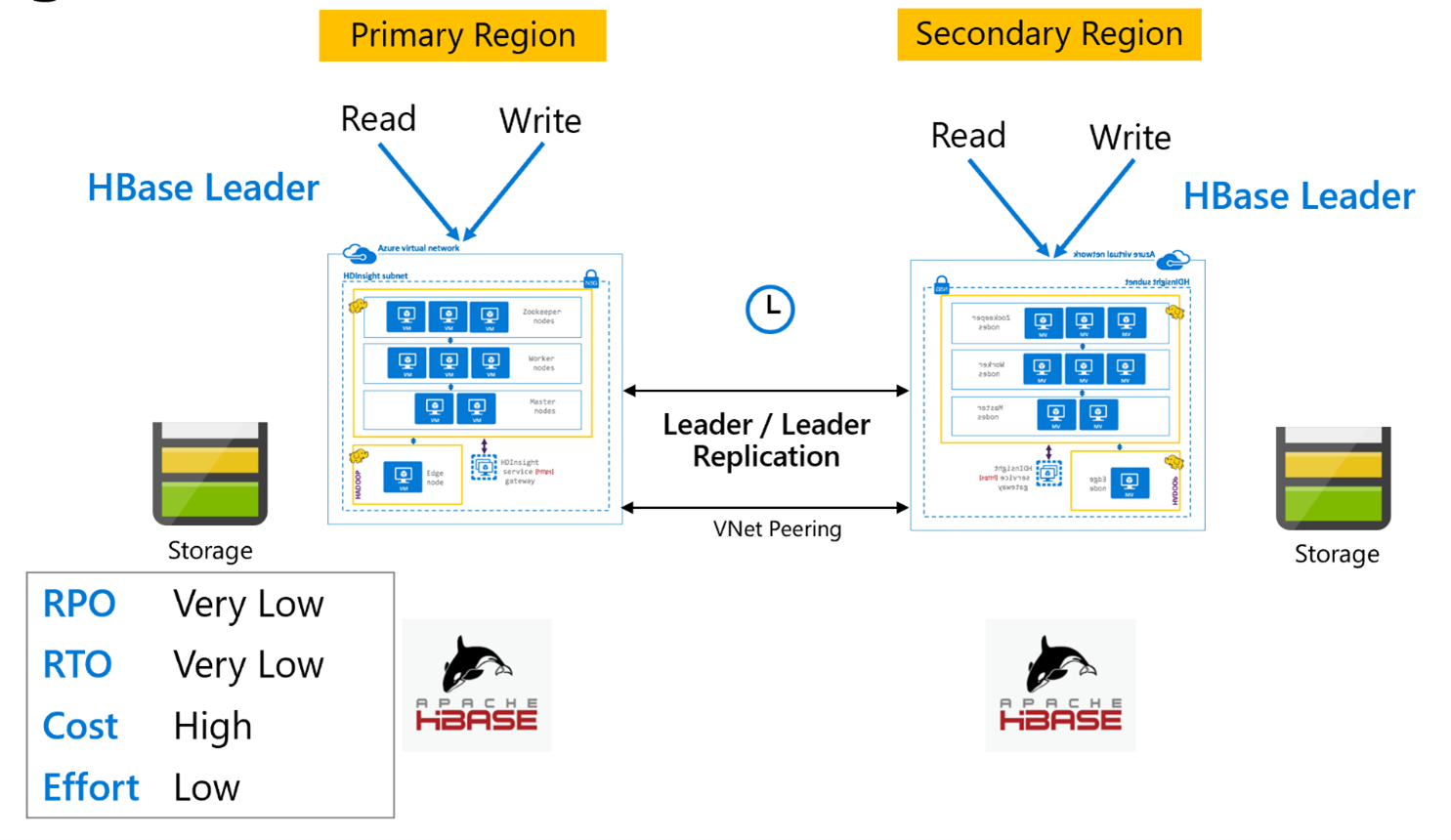
HBase 复制:领导者模型
此跨区域设置非常类似于单向设置,只不过复制在主区域与辅助区域之间双向进行。 应用程序可以在读写模式下使用这两个群集,并在它们之间异步交换更新。
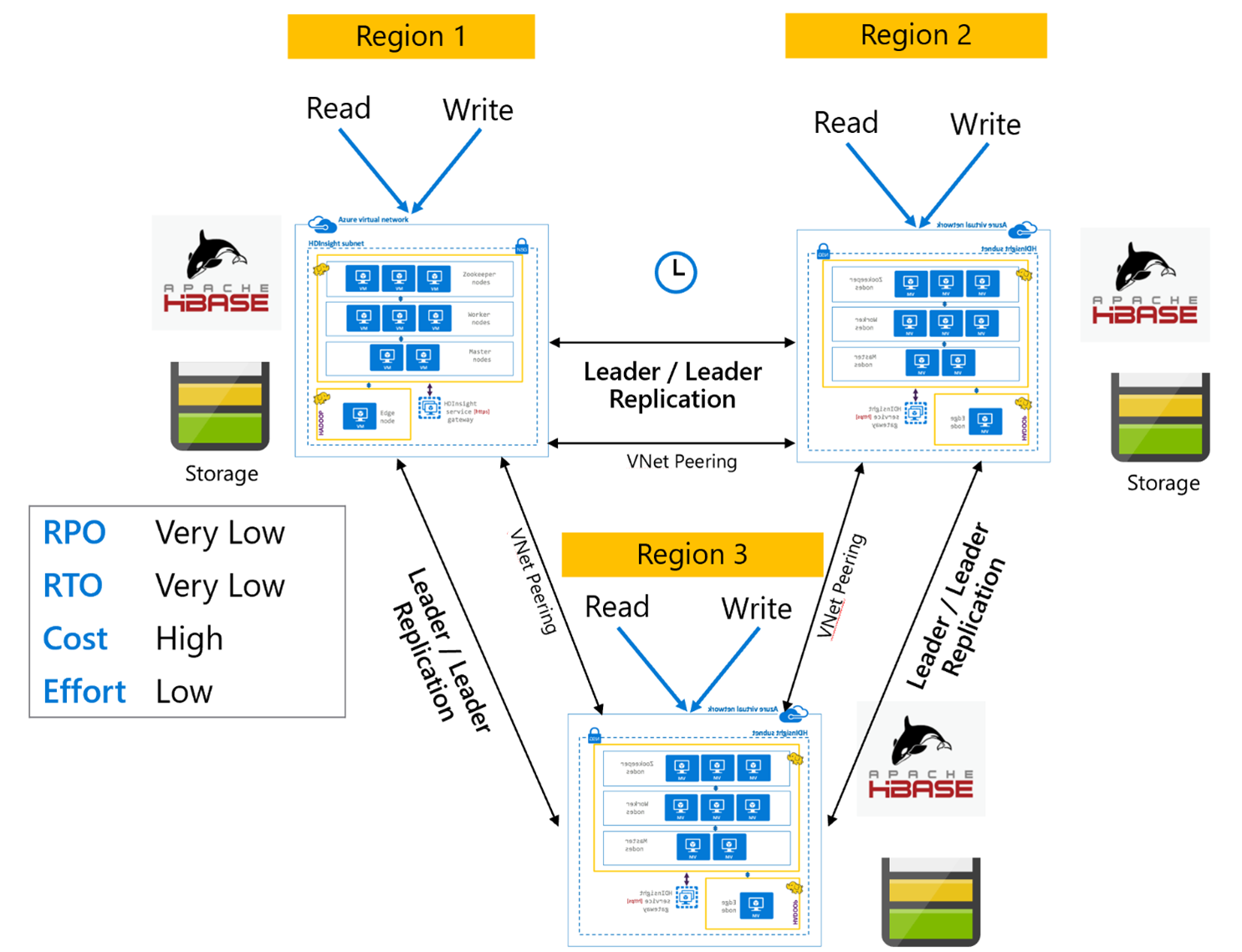
HBase 复制:多区域或循环
“多区域/循环”复制模型是 HBase 复制的扩展,可用于创建包含多个应用程序的全局冗余 HBase 体系结构,这些应用程序可在特定于区域的 HBase 群集中进行读取和写入。 可以根据业务要求按不同的“领导者/领导者”或“领导者/追随者”组合来设置群集。
Apache Kafka
为了实现跨区域可用性,HDInsight 4.0 支持 Kafka MirrorMaker,后者可用于在另一区域中维护主 Kafka 群集的辅助副本。 MirrorMaker 充当高级“使用者-生成者”对,使用主群集中某个特定主题提供的内容,将内容生成到辅助群集中名称相同的主题。 使用 MirrorMaker 进行跨群集复制以实现高可用性灾难恢复的假设条件是生成者和使用者需要故障转移到副本群集。 有关详细信息,请参阅使用 MirrorMaker 通过 Kafka on HDInsight 复制 Apache Kafka 主题
MirrorMaker 主题复制可能会在源主题与副本主题之间导致不同的偏移量,具体取决于复制开始时的主题生存期。 HDInsight Kafka 群集还支持主题分区复制,这是在单个群集级别的高可用性功能。
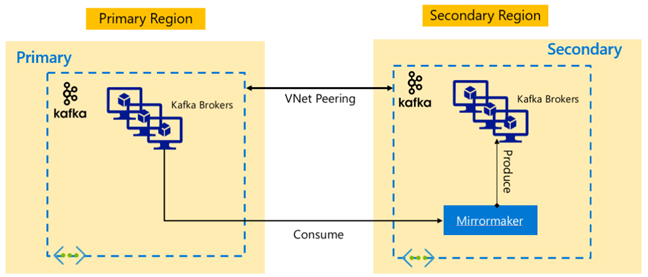
Apache Kafka 体系结构
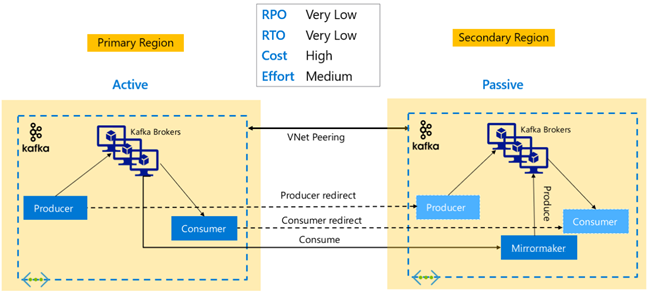
Kafka 复制:主动-被动
激活-被动配置启用从激活到被动的异步单向镜像。 生产者和消费者需要了解主动和被动群集的存在,并且必须准备好在主动群集发生故障时切换到被动群集。 下面是“主动-被动”设置的一些优点和缺点。
优点:
- 群集之间的网络延迟不会影响主动群集的性能。
- 单向复制的简单性。
缺点:
- 被动群集可能仍未得到充分利用。
- 在应用程序生成者和使用者中纳入故障转移感知的设计复杂性。
- 在主动群集故障期间可能会丢失数据。
- 主动与被动群集的主题之间的最终一致性。
- 故障切换回主节点可能会导致主题中的消息不一致。
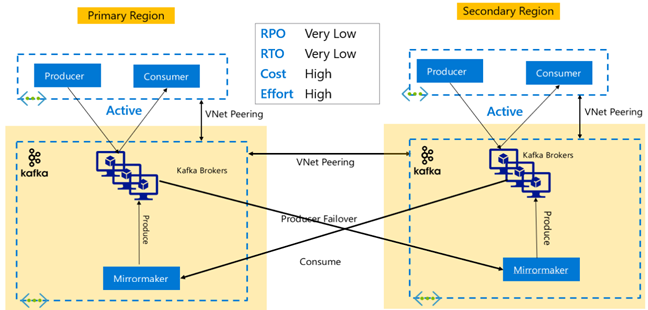
Kafka 复制:主动-主动
“主动-主动”设置包括两个区域分离、通过 VNet 对等互连的 HDInsight Kafka 群集,这些群集使用 MirrorMaker 进行双向异步复制。 在此设计中,主区域中的使用者使用的消息也可以供辅助区域中的使用者使用,反之亦然。 下面是“主动-主动”设置的一些优点和缺点。
优点:
- 由于其状态是重复的,故障转移和故障回复更容易执行。
缺点:
- 设置、管理和监视比“主动-被动”设置更复杂。
- 循环复制的问题需要解决。
- 双向复制会导致更高的区域数据出口费用。
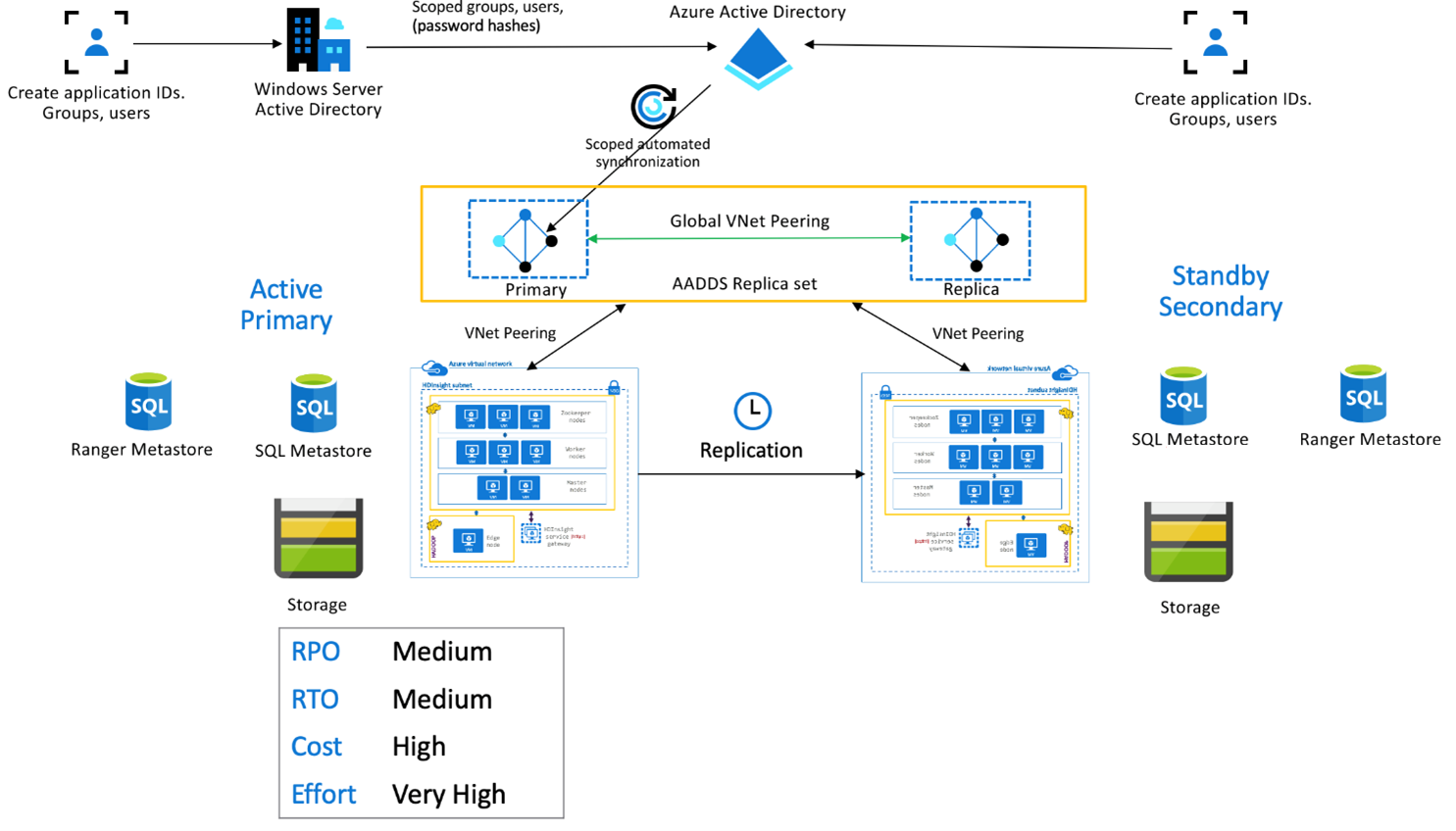
HDInsight 企业安全性套餐
此设置用于在主群集和辅助副本集中启用多用户功能,以及 Microsoft Entra Domain Services 副本集以确保用户可以向两个群集进行身份验证。 在正常运行时,需要在辅助系统中设置 Ranger 策略,以确保用户被限制为只能进行读取操作。 下面的体系结构说明了启用了 ESP 的 Hive“主动主群集 – 备用辅助群集”设置的情况。
Ranger 元存储复制:
Ranger 元存储用于永久存储和提供 Ranger 策略来控制数据授权。 建议在主群集和辅助群集中保留独立的 Ranger 策略,并保留辅助群集作为只读副本。
如果要求在主群集与辅助群集之间保持 Ranger 策略同步,请使用 Ranger 导入/导出定期备份 Ranger 策略并将其从主群集导入到辅助群集。
如果在主群集与辅助群集之间复制 Ranger 策略,则可能会导致辅助群集变为支持写入的群集,这可能会导致在辅助群集上出现意外的写入,导致数据不一致。
后续步骤
若要详细了解本文中所述的项,请参阅: