Azure HDInsight 网关(网关)是 HDInsight 群集的 HTTPS 前端。 网关负责实现以下内容:身份验证、主机解析、服务发现,以及新式分布式系统所需的其他有用功能。 网关提供的功能会产生一些开销,本文档将为此介绍一些最佳做法。 其中还介绍了网关故障排除方法。
HDInsight 网关
HDInsight 网关是 HDInsight 群集中唯一可通过 Internet 公开访问的部分。 通过使用 clustername-int.azurehdinsight.cn 内部网关终结点,无需经由公共 Internet 即可访问网关服务。 内部网关终结点允许与网关服务建立连接,而无需退出群集的虚拟网络。 网关处理发送到群集的所有请求,然后将这些请求转发到正确的组件和群集主机。
下图大致说明了网关如何对 HDInsight 中可选的所有不同主机解析进行抽象。
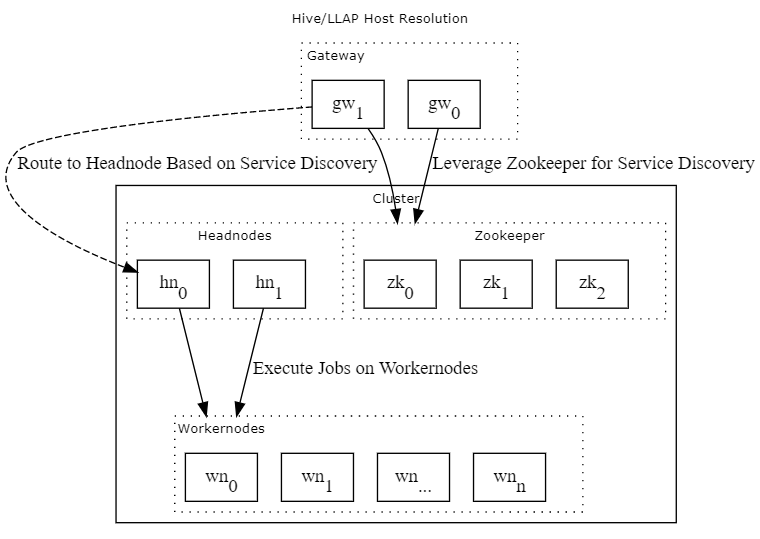
动机
在 HDInsight 群集之前放置网关旨在为服务发现和用户身份验证提供接口。 网关提供的身份验证机制特别适用于启用了 ESP 的群集。
对于服务发现,网关的优势在于可以将群集中的每个组件作为网关网站 (clustername.azurehdinsight.cn/hive2) 下不同的终结点进行访问,这不同于众多 host:port 配对。
对于身份验证,网关允许用户使用 username:password 凭据对进行身份验证。 对于启用了 ESP 的群集,此凭据将用作用户的域用户名和密码。 通过网关向 HDInsight 群集验证身份时,客户端无需获取 kerberos 票证。 由于网关接受 username:password 凭据并代表用户获取用户的 Kerberos 票证,因此可以在任何客户端主机(包括与 ESP 群集加入不同 AA-DDS 域的客户端)与网关之间建立安全连接。
最佳实践
网关是一项单一服务(跨两个主机进行负载均衡),负责请求的转发和身份验证。 对于超过特定大小的 Hive 查询,网关可能会成为吞吐量瓶颈。 通过 ODBC 或 JDBC 在网关上执行超大型 SELECT 查询时,可能会发现查询性能降低。 “超大型”表示查询包含的行或列中的数据超过 5 GB。 此查询可能包含一长列行和/或大量列。
网关因大量查询而导致性能下降的原因在于,数据必须从底层数据存储 (ADLS Gen2) 传输到以下位置:HDInsight Hive 服务器、网关,最后通过 JDBC 或 ODBC 驱动程序传输到客户端主机。
下图说明了 SELECT 查询所涉及的步骤。
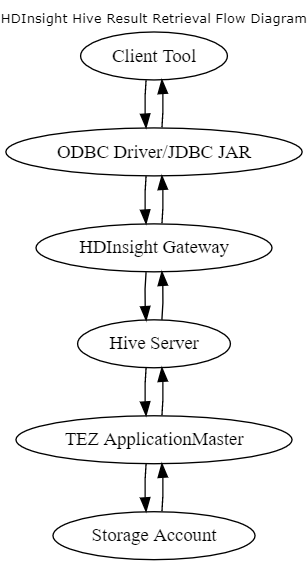
Apache Hive 是基于与 HDFS 兼容的文件系统的关系抽象。 此抽象意味着 Hive 中的 SELECT 语句对应于文件系统上的 READ 操作。 READ 操作在报告给用户之前,会被转换为适当的架构。 此过程的延迟随数据大小和到达最终用户所需的总跃点数的增大而增加。
执行大型数据的 CREATE 或 INSERT 语句时,可能会出现类似的行为,因为这些命令将与基础文件系统中的 WRITE 操作相对应。 请考虑将原始 ORC 等数据写入文件系统/数据湖,而不是使用 INSERT 或 LOAD 进行加载。
在启用了 Enterprise 安全包的群集中,Apache Ranger 策略太过复杂可能会导致查询编译速度变慢,进而可能导致网关超时。 如果在 ESP 群集中发现网关超时,请考虑减少或合并 Ranger 策略数。
故障排除方法
可在多个位置缓解和了解上述行为中的性能问题。 在 HDInsight 网关上遇到查询性能下降时,请使用以下清单:
执行大型 SELECT 查询时,请使用 LIMIT 子句。 LIMIT 子句将减少报告给客户端主机的总行数。 LIMIT 子句仅影响结果生成,不会更改查询计划。 若要在查询计划中应用 LIMIT 子句,请使用配置
hive.limit.optimize.enable。 可以使用参数形式 LIMIT x,y 组合 LIMIT 与偏移量。运行 SELECT 查询而不是使用 SELECT * 时,请为所需列命名。 选择的列越少,读取的数据量就越小。
尝试通过 Apache Beeline 运行所需查询。 如果通过 Apache Beeline 进行的结果检索耗时较长,则通过外部工具检索相同结果时也会出现延迟。
测试基本的 Hive 查询,确保可以与 HDInsight 网关建立连接。 尝试从两个或多个外部工具运行基本查询,确保不会有任何工具出现问题。
查看所有 Apache Ambari 警报,确保 HDInsight 服务运行正常。 Ambari 警报可以与 Azure Monitor 集成,以便进行报告和分析。
如果使用的是外部 Hive 元存储,请检查 Hive 元存储的 Azure SQL DB DTU 是否尚未达到其限制。 如果 DTU 快要达到其限制,则需要增加数据库大小。
确保所有第三方工具(例如 PBI 或 Tableau)均使用分页查看表或数据库。 请咨询你的支持合作伙伴,获取这些工具,了解如何使用分页。 分页所用的主要工具是 JDBC
fetchSize参数。 提取较小可能会导致网关性能下降,但提取太大可能会导致网关超时。 提取大小的调整必须基于工作负载进行。如果数据管道涉及从 HDInsight 群集的底层存储中读取大量数据,请考虑使用与 Azure 数据工厂等 Azure 存储直接连接的工具。
运行交互式工作负载时,请考虑使用 Apache Hive LLAP,因为 LLAP 可以为快速返回查询结果提供更流畅的体验。
请考虑使用
hive.server2.thrift.max.worker.threads增加可用于 Hive 元存储服务的线程数。 当大量并发用户向群集提交查询时,此设置特别重要。减少从任意外部工具访问网关的重试次数。 如果多次重试,请考虑使用指数回退重试策略。
请考虑使用配置
hive.exec.compress.output和hive.exec.compress.intermediate启用压缩 Hive。