本教程介绍如何结合使用 Apache Maven 和 IntelliJ IDEA 创建用 Scala 编写的 Apache Spark 应用程序。 本文使用 Apache Maven 作为生成系统, 并从 IntelliJ IDEA 提供的适用于 Scala 的现有 Maven 原型开始。 在 IntelliJ IDEA 中创建 Scala 应用程序需要以下步骤:
- 将 Maven 用作生成系统。
- 更新项目对象模型 (POM) 文件,以解析 Spark 模块依赖项。
- 使用 Scala 编写应用程序。
- 生成可以提交到 HDInsight Spark 群集的 jar 文件。
- 使用 Livy 在 Spark 群集上运行应用程序。
在本教程中,你将了解如何执行以下操作:
- 安装适用于 IntelliJ IDEA 的 Scala 插件
- 使用 IntelliJ 开发 Scala Maven 应用程序
- 创建独立 Scala 项目
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
Oracle Java 开发工具包。 本教程使用 Java 版本 8.0.202。
Java IDE。 本文使用 IntelliJ IDEA Community 2018.3.4。
Azure Toolkit for IntelliJ。 请参阅安装 Azure Toolkit for IntelliJ。
安装适用于 IntelliJ IDEA 的 Scala 插件
执行以下步骤安装 Scala 插件:
打开 IntelliJ IDEA。
在欢迎屏幕上,导航到“配置”>“插件”打开“插件”窗口。
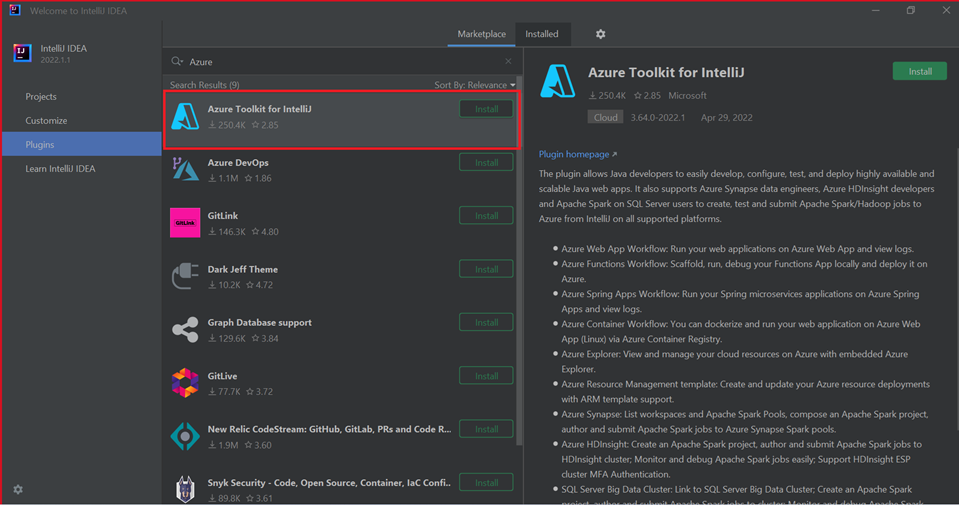
为 Azure Toolkit for IntelliJ 选择“安装”。
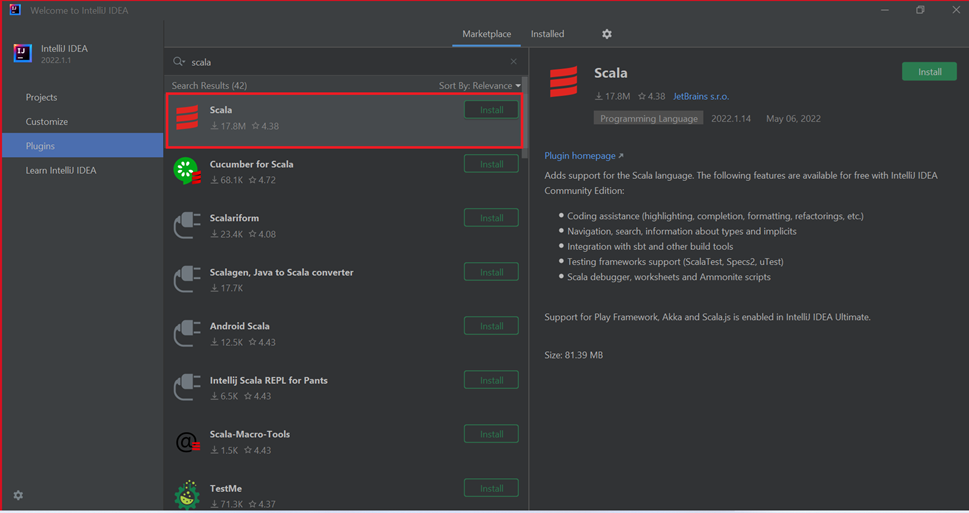
选择在新窗口中作为特色功能列出的 Scala 插件对应的“安装”。
成功安装该插件后,必须重启 IDE。
使用 IntelliJ 创建应用程序
启动 IntelliJ IDEA,选择“创建新项目”打开“新建项目”窗口。
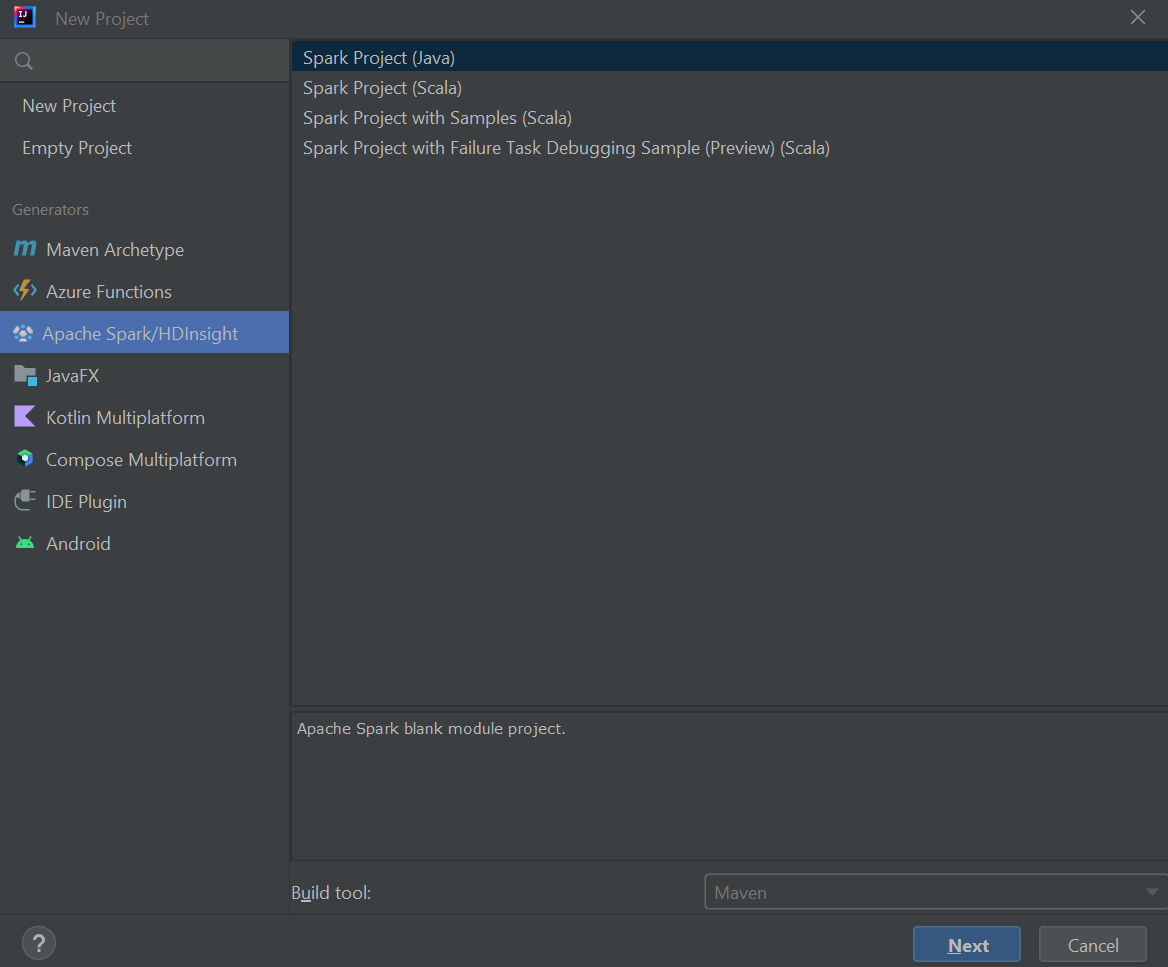
从左侧窗格中选择“Apache Spark/HDInsight”。
在主窗口中选择“Spark 项目(Scala)”。
从“生成工具”下拉列表中,选择以下值之一:
- Maven:支持 Scala 项目创建向导。
- SBT:用于管理依赖项和生成 Scala 项目。
选择“下一页”。
在“新建项目”窗口中提供以下信息:
属性 说明 项目名称 输入名称。 项目位置 输入项目保存位置。 项目 SDK 首次使用 IDEA 时,此字段将为空。 选择“新建...”并导航到 JDK。 Spark 版本 创建向导集成了适当版本的 Spark SDK 和 Scala SDK。 如果 Spark 群集版本低于 2.0,请选择“Spark 1.x” 。 否则,请选择“Spark 2.x” 。 本示例使用“Spark 2.3.0 (Scala 2.11.8)”。 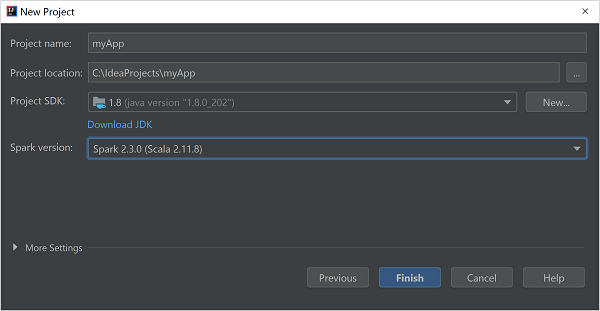
选择“完成”。
创建独立 Scala 项目
启动 IntelliJ IDEA,选择“创建新项目”打开“新建项目”窗口。
在左窗格中选择“Maven”。
指定“项目 SDK”。 如果此字段是空白的,请选择“新建...”并导航到 Java 安装目录。
选中“从原型创建”复选框。
从原型列表中,选择
org.scala-tools.archetypes:scala-archetype-simple。 此原型会创建适当的目录结构,并下载所需的默认依赖项来编写 Scala 程序。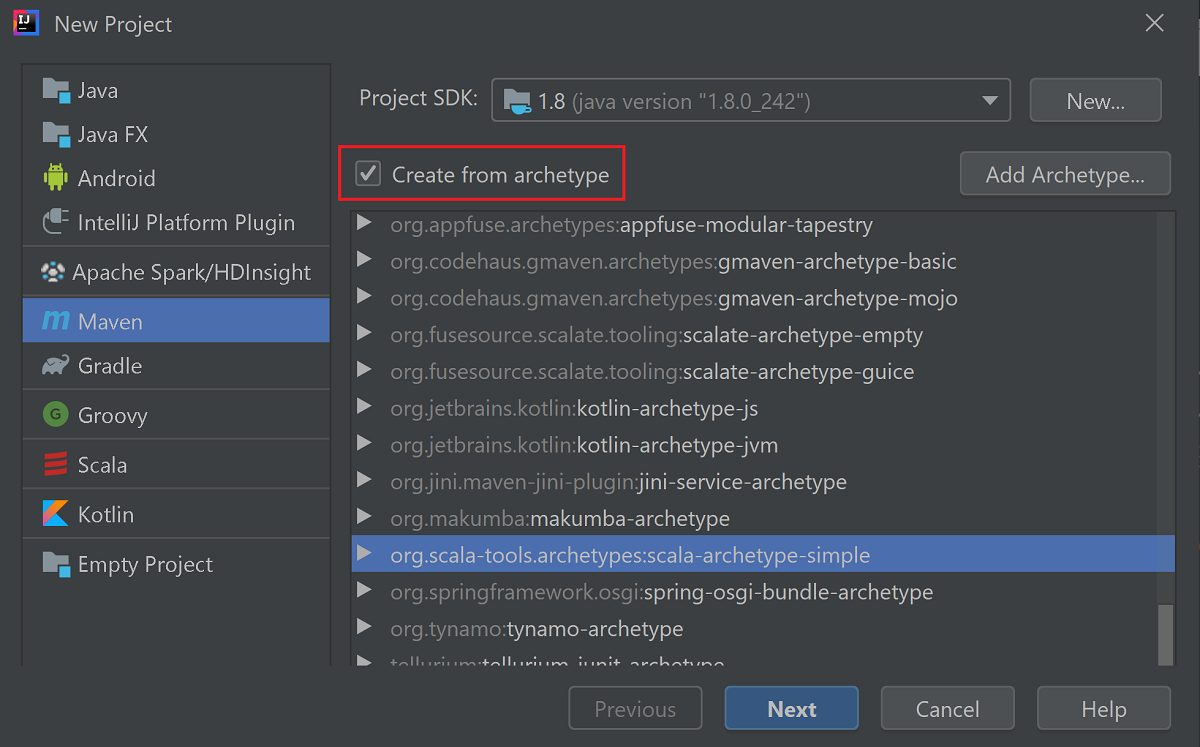
选择“下一步”。
展开“项目坐标”。 提供 GroupId 和 ArtifactId 的相关值。 “名称”和“位置”将自动填充。 本教程涉及以下值:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
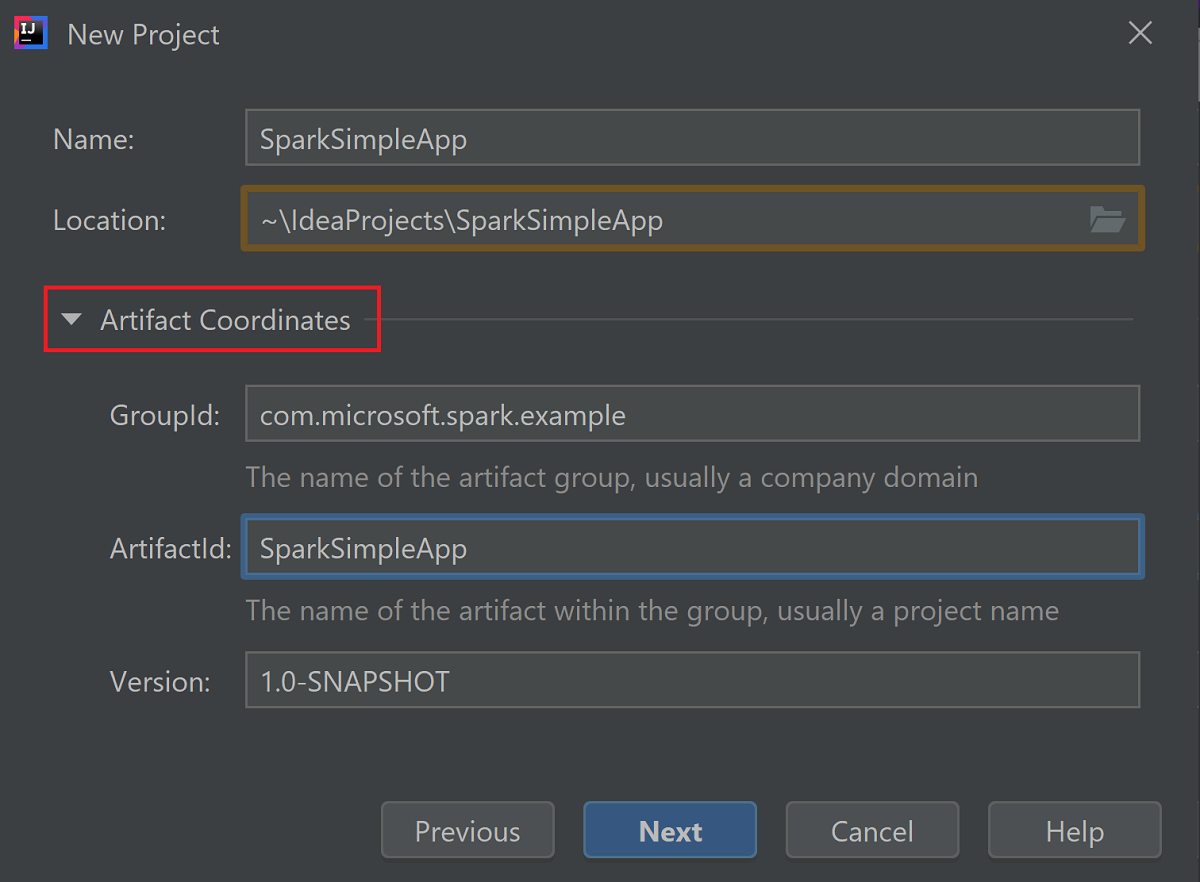
选择“下一步”。
验证设置,并选择“下一步”。
验证项目名称和位置,并选择“完成”。 导入项目需要花费几分钟时间。
导入项目后,在左窗格中导航到“SparkSimpleApp”>“src”>“test”>“scala”>“com”>“microsoft”>“spark”>“example”。 右键单击“MySpec”并选择“删除...” 。应用程序不需要此文件。 在对话框中选择“确定”。
后续步骤会更新 pom.xml 以定义 Spark Scala 应用程序的依赖项。 若要自动下载和解析这些依赖项,你必须配置 Maven。
在“文件”菜单中,选择“设置”打开“设置”窗口。
在“设置”窗口中,导航到“生成、执行、部署”>“生成工具”>“Maven”>“导入”。
选中“自动导入 Maven 项目”复选框。
依次选择“应用”、“确定” 。 然后将返回到项目窗口。
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::在左侧窗格中,导航到“src”>“main”>“scala”>“com.microsoft.spark.example”,然后双击“应用”打开 App.scala。
将当前示例代码替换为以下代码,然后保存所做的更改。 此代码从 HVAC.csv(在所有 HDInsight Spark 群集上均可用)读取数据。 检索第六列中只有一位数字的行。 并将输出写入群集的默认存储容器下的“/HVACOut”。
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }在左侧窗格中,双击“pom.xml”。
在
<project>\<properties>中添加以下段:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>在
<project>\<dependencies>中添加以下段:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.创建 .jar 文件。 IntelliJ IDEA 允许创建 JAR,将其作为项目的一项。 执行以下步骤。
在“文件”菜单中,选择“项目结构...”。
在“项目结构”窗口中,导航到“项目”>“+”>“JAR”>“从包含依赖项的模块...”。
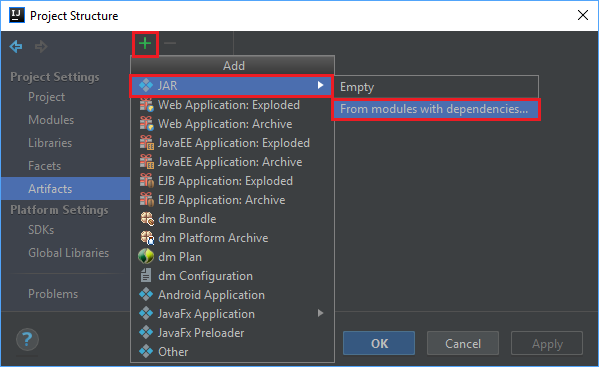
在“从模块创建 JAR”窗口中,选择“主类”文本框中的文件夹图标。
在“选择主类”窗口中,选择默认显示的类,然后选择“确定” 。
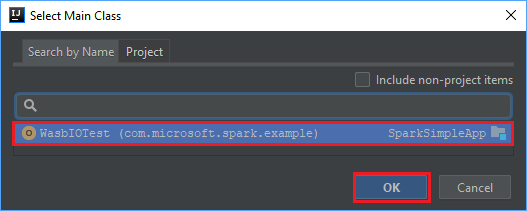
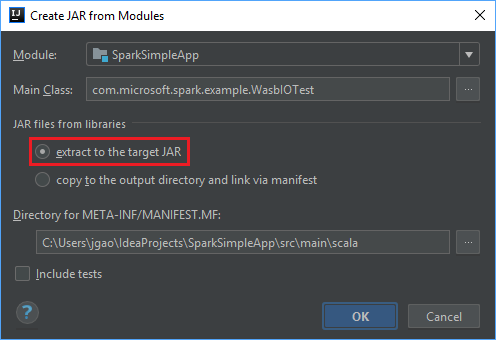
在“从模块创建 JAR”窗口中,确保已选择“提取到目标 JAR”选项,然后选择“确定” 。 这设置会创建包含所有依赖项的单个 JAR。
“输出布局”选项卡列出了所有包含为 Maven 项目一部分的 jar。 可以选择并删除 Scala 应用程序不直接依赖的 jar。 对于此处创建的应用程序,可以删除最后一个(SparkSimpleApp 编译输出)以外的所有 jar。 选择要删除的 jar,然后选择减号 - 。
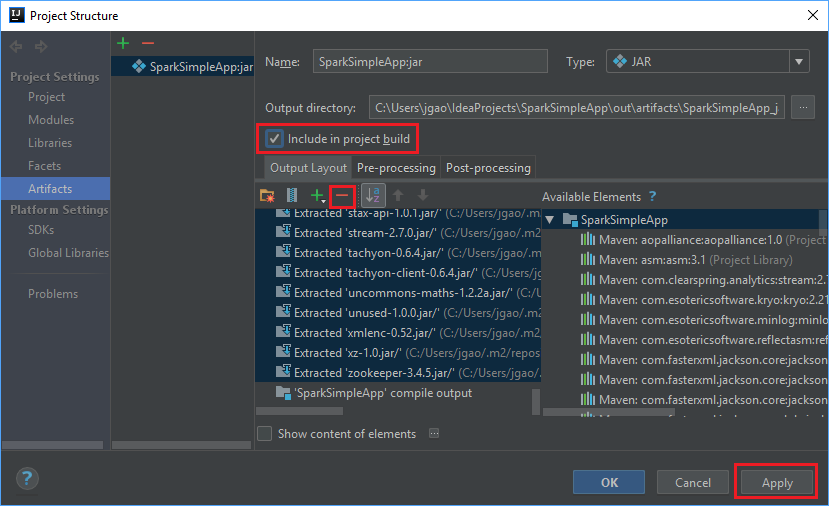
确保选中“包含在项目生成中”复选框。 此选项可确保每次生成或更新项目时都创建 jar。 依次选择“应用”、“确定” 。
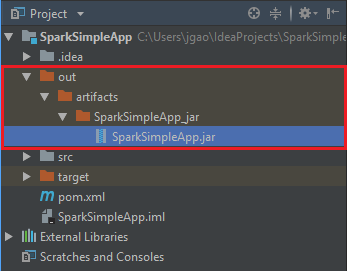
若要创建 jar,请导航到“生成”>“生成项目”>“生成”。 该项目将在大约 30 秒内完成编译。 输出 jar 会在 \out\artifacts 下创建。
在 Apache Spark 群集上运行应用程序
若要在群集上运行应用程序,可以使用以下方法:
将应用程序 jar 复制到与群集关联的 Azure 存储 blob。 可以使用命令行实用工具 AzCopy 来执行此操作。 也可以使用许多其他客户端来上传数据。 有关详细信息,请参阅在 HDInsight 中上传 Apache Hadoop 作业的数据。
使用 Apache Livy 将应用程序作业远程提交到 Spark 群集。 HDInsight 上的 Spark 群集包括公开 REST 终结点的 Livy,可远程提交 Spark 作业。 有关详细信息,请参阅将 Apache Livy 与 HDInsight 上的 Apache Spark 群集配合使用以远程提交 Spark 作业。
清理资源
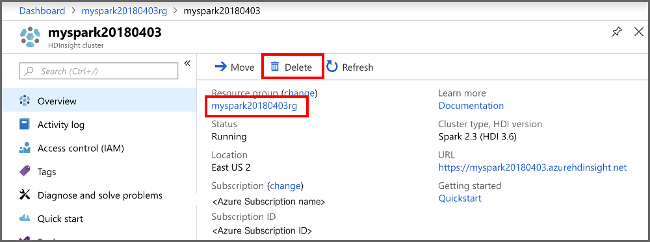
如果不打算继续使用此应用程序,请使用以下步骤删除创建的群集:
登录 Azure 门户。
在顶部的“搜索”框中,键入 HDInsight。
选择“服务”下的“HDInsight 群集” 。
在显示的 HDInsight 群集列表中,选择为本教程创建的群集旁边的“...”。
选择“删除”。 请选择“是”。
后续步骤
本文介绍了如何创建 Apache Spark scala 应用程序。 转到下一文章,了解如何使用 Livy 在 HDInsight Spark 群集上运行此应用程序。