本快速入门将使用 Azure 资源管理器模板(ARM 模板)在 Azure HDInsight 中创建一个 Apache Spark 群集。 然后,你将创建一个 Jupyter Notebook 文件,并使用它针对 Apache Hive 表运行 Spark SQL 查询。 Azure HDInsight 是适用于企业的分析服务,具有托管、全面且开源的特点。 用于 HDInsight 的 Apache Spark 框架使用内存中处理功能实现快速数据分析和群集计算。 使用 Jupyter Notebook,可以与数据进行交互、将代码和 Markdown 文本结合使用,以及进行简单的可视化。
如果将多个群集一起使用,则需创建一个虚拟网络;如果使用的是 Spark 群集,则还需使用 Hive Warehouse Connector。 有关详细信息,请参阅为 Azure HDInsight 规划虚拟网络和将 Apache Spark 和 Apache Hive 与 Hive Warehouse Connector 集成。
Azure 资源管理器模板是定义项目基础结构和配置的 JavaScript 对象表示法 (JSON) 文件。 模板使用声明性语法。 你可以在不编写用于创建部署的编程命令序列的情况下,描述预期部署。
如果你的环境满足先决条件,并且你熟悉如何使用 ARM 模板,请选择“部署到 Azure”按钮。 Azure 门户中会打开模板。

先决条件
如果没有 Azure 订阅,可在开始前创建一个 创建试用帐户。
查看模板
本快速入门中使用的模板来自 Azure 快速启动模板。
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.4.412.5873",
"templateHash": "208593930043773060"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"functions": [],
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-04-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2018-06-01-preview",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-04-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
该模板中定义了两个 Azure 资源:
- Microsoft.Storage/storageAccounts:创建 Azure 存储帐户。
- Microsoft.HDInsight/cluster:创建 HDInsight 群集。
部署模板
选择下面的“部署到 Azure”按钮登录到 Azure,并打开 ARM 模板。
输入或选择下列值:
属性 说明 订阅 从下拉列表中选择用于此群集的 Azure 订阅。 资源组 从下拉列表中选择现有资源组,或选择“新建” 。 位置 将使用用于资源组的位置自动填充此值。 群集名称 输入任何全局唯一的名称。 对于此模板,请只使用小写字母和数字。 群集登录用户名 提供用户名,默认值为 admin。群集登录密码 提供密码。 密码长度不得少于 10 个字符,且至少必须包含一个数字、一个大写字母和一个小写字母、一个非字母数字字符( ' ` "字符除外)。SSH 用户名 提供用户名,默认为 sshuser。SSH 密码 提供密码。 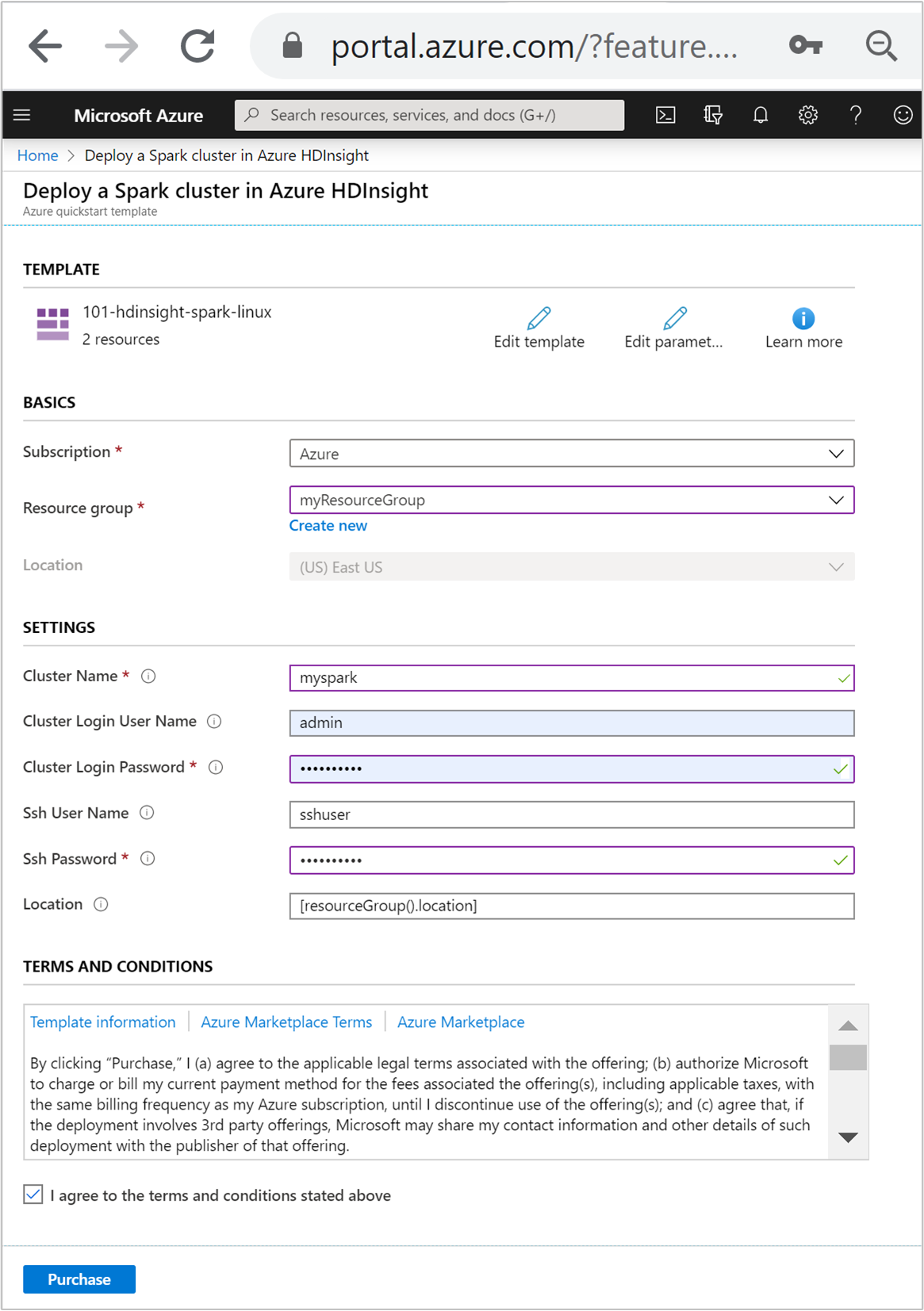
查看“条款和条件”。 接着选择“我同意上述条款和条件”,然后选择“购买” 。 你会收到一则通知,说明正在进行部署。 创建群集大约需要 20 分钟时间。
如果在创建 HDInsight 群集时遇到问题,可能是因为你没有这样做的适当权限。 有关详细信息,请参阅访问控制要求。
查看已部署的资源
创建群集后,你会收到“部署成功”通知,通知中附有“转到资源”链接 。 “资源组”页会列出新的 HDInsight 群集以及与该群集关联的默认存储。 每个群集都有一个 Azure 存储(Azure Data Lake Storage Gen2 依赖项)。 该帐户称为默认存储帐户。 HDInsight 群集及其默认存储帐户必须共存于同一个 Azure 区域中。 删除群集不会删除存储帐户依赖项。 该帐户称为默认存储帐户。 HDInsight 群集及其默认存储帐户必须共存于同一个 Azure 区域中。 删除群集不会删除存储帐户。
创建 Jupyter Notebook 文件
Jupyter Notebook 是支持各种编程语言的交互式笔记本环境。 可以使用 Jupyter Notebook 文件与数据交互,将代码和 Markdown 文本相结合,并执行简单的可视化操作。
打开 Azure 门户。
选择“HDInsight 群集”,然后选择所创建的群集。
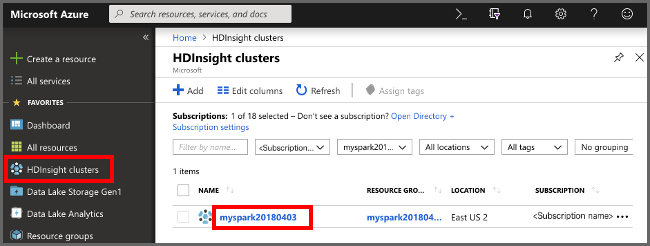
在门户的“群集仪表板”部分中,选择“Jupyter Notebook”。 出现提示时,请输入群集的群集登录凭据。
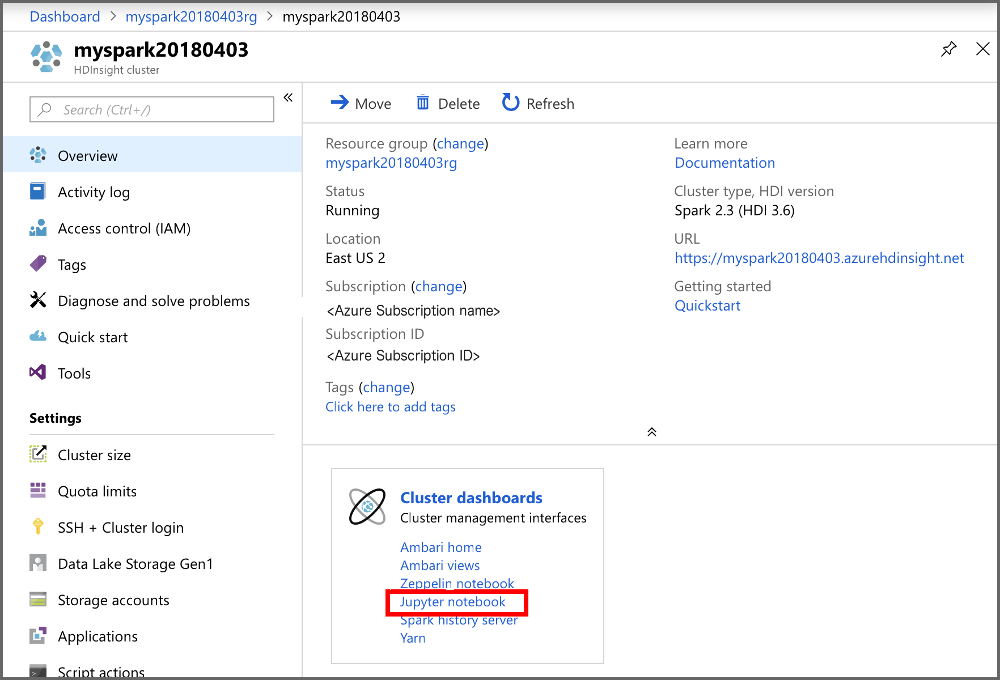
选择“新建”>“PySpark”,创建笔记本 。
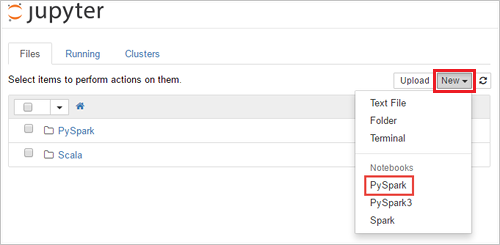
新笔记本随即已创建,并以 Untitled(Untitled.pynb) 名称打开。
运行 Apache Spark SQL 语句
SQL(结构化查询语言)是用于查询和转换数据的最常见、最广泛使用的语言。 Spark SQL 作为 Apache Spark 的扩展使用,可使用熟悉的 SQL 语法处理结构化数据。
验证 kernel 已就绪。 如果在 Notebook 中的内核名称旁边看到空心圆,则内核已准备就绪。 实心圆表示内核正忙。
 alt-text="内核状态。" border="true":::
alt-text="内核状态。" border="true":::首次启动 Notebook 时,内核在后台执行一些任务。 等待内核准备就绪。
将以下代码粘贴到一个空单元格中,然后按 SHIFT + ENTER 来运行这些代码。 此命令列出群集上的 Hive 表:
%%sql SHOW TABLES将 Jupyter Notebook 文件与 HDInsight 群集配合使用时,会获得一个预设
spark会话,可以使用它通过 Spark SQL 来运行 Hive 查询。%%sql指示 Jupyter Notebook 使用预设spark会话运行 Hive 查询。 该查询从默认情况下所有 HDInsight 群集都带有的 Hive 表 (hivesampletable) 检索前 10 行。 第一次提交查询时,Jupyter 将为笔记本创建 Spark 应用程序。 该操作需要大约 30 秒才能完成。 Spark 应用程序准备就绪后,查询将在大约一秒钟内执行并生成结果。 输出如下所示: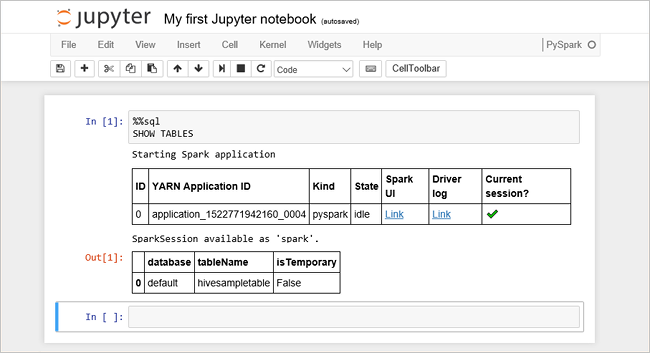 y in HDInsight" border="true":::
y in HDInsight" border="true":::每次在 Jupyter 中运行查询时,Web 浏览器窗口标题中都会显示“(繁忙)”状态和 Notebook 标题。 右上角“PySpark” 文本的旁边还会出现一个实心圆。
运行另一个查询,请查看
hivesampletable中的数据。%%sql SELECT * FROM hivesampletable LIMIT 10屏幕在刷新后会显示查询输出。
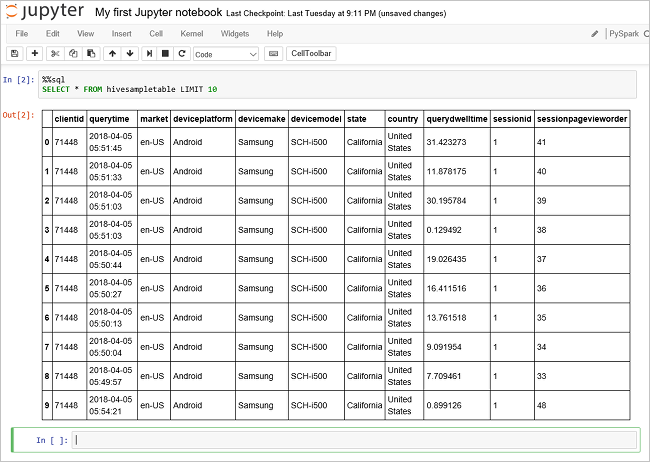 Insight" border="true":::
Insight" border="true":::请在 Notebook 的“文件”菜单中选择“关闭并停止” 。 关闭笔记本会释放群集资源,包括 Spark 应用程序。
清理资源
完成本快速入门后,可以删除群集。 有了 HDInsight,便可以将数据存储在 Azure 存储中,因此可以在群集不用时安全地删除群集。 此外,还需要为 HDInsight 群集付费,即使不用也是如此。 由于群集费用数倍于存储空间费用,因此在群集不用时删除群集可以节省费用。
从 Azure 门户导航到群集,然后选择“删除”。
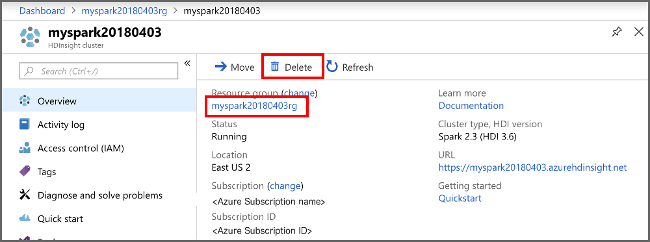 sight 群集" border="true":::
sight 群集" border="true":::
还可以选择资源组名称来打开“资源组”页,然后选择“删除资源组”。 通过删除资源组,可以删除 HDInsight 群集和默认存储帐户。
后续步骤
在本快速入门中,你已了解如何在 HDInsight 中创建 Apache Spark 群集并运行基本的 Spark SQL 查询。 转到下一教程,了解如何使用 HDInsight 群集针对示例数据运行交互式查询。