适用于: Python SDK azure-ai-ml v2(当前版本)
Python SDK azure-ai-ml v2(当前版本)
自动化机器学习(也称为自动化 ML 或 AutoML)自动执行机器学习模型开发的耗时迭代任务。 借助自动化 ML,数据科学家、分析师和开发人员可以通过效率和工作效率大规模构建机器学习模型,同时保持模型质量。 Azure 机器学习中的自动化 ML 基于 Microsoft Research 部门的突破性技术。
- 对于编程经验丰富的客户,请安装 Azure 机器学习 Python SDK。 入门教程:使用 AutoML 和 Python 训练物体检测模型(预览版)。
AutoML 如何运作?
在训练期间,Azure 机器学习会创建多个尝试不同算法和参数的并行管道。 该服务遍历与特征选择配对的 ML 算法。 每次迭代都会生成一个具有训练分数的模型。 要优化的指标的分数越好,模型越适合数据。 进程在满足试验中定义的退出条件后停止。
使用 Azure 机器学习可以通过以下步骤设计和运行自动化 ML 训练试验:
确定要解决的 ML 问题:分类、预测、回归、计算机视觉或 NLP。
选择代码优先体验或无代码工作室 Web 体验:首选代码优先体验的用户可以使用 Azure 机器学习 SDKv2 或 Azure 机器学习 CLIv2。 入门教程:使用 AutoML 和 Python 训练物体检测模型。 首选有限或无代码体验的用户可以在 Azure 机器学习工作室 () 中使用 https://studio.ml.azure.cn。 入门教程:使用 Azure 机器学习中的自动化 ML 创建分类模型。
指定已标记训练数据的源:以 许多不同的方式将数据引入 Azure 机器学习。
配置自动化机器学习参数:设置不同模型、超参数设置、高级预处理和特征化选项的迭代次数,以及确定最佳模型时要评估的指标。
提交训练作业。
查看结果。
下图演示了此过程。
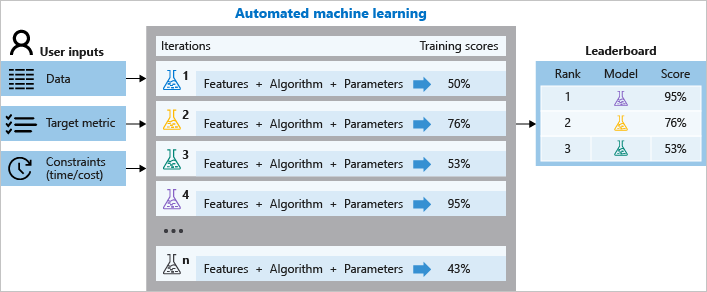
还可以检查记录的作业信息,其中包含的指标是在作业期间收集的。 训练作业会生成一个包含模型和数据预处理的 Python 序列化对象(.pkl 文件)。
模型生成是自动化的,同时,你也可以了解特征对于生成的模型而言如何重要或者彼此相关。
何时使用 AutoML:分类、回归、预测、计算机视觉和 NLP
如果希望 Azure 机器学习使用指定的目标指标来训练和优化模型,请使用自动化 ML。 自动化 ML 将机器学习模型开发过程实现民主化,并使其用户能够(无论其数据科学专业知识如何)确定用于任何问题的端到端机器学习管道。
各行业的 ML 专业人员和开发人员可以使用自动化 ML 来实现以下目的:
- 无需丰富的编程知识,即可实现机器学习解决方案
- 节省时间和资源
- 应用数据科学最佳做法
- 提供灵活的问题解决方法
分类
分类是一种监督式学习,其中的模型使用训练数据进行学习,并将学习所得应用于新数据。 Azure 机器学习为这些任务专门提供特征化,例如用于分类的深度神经网络文本特征化器。 有关特征化选项的详细信息,请参阅数据特征化。 还可以在支持的算法中找到 AutoML 支持的算法列表。
分类模型的主要目标是根据从训练数据习得的内容来预测新数据属于哪些类别。 常见分类示例包括欺诈检测、手写识别和对象检测。
请参阅此 Python 笔记本中的分类和自动化机器学习示例:银行营销。
回归
类似于分类,回归任务也是常见的监督式学习任务。 Azure 机器学习提供特定于回归问题的特征化。 详细了解特征化选项。 还可以在支持的算法中找到 AutoML 支持的算法列表。
不同于分类(其中的预测输出值是分类的),回归模型基于独立的预测器预测数字输出值。 在回归中,目标是通过估计一个变量对其他变量的影响,帮助建立这些独立预测因子变量之间的关系。 例如,模型可能会基于里程油耗和安全评级等特征预测汽车价格。
请参阅以下 Python 笔记本中用于预测的回归和自动化机器学习示例:硬件性能。
时序预测
生成预测是任何业务(无论是收入、库存、销售还是客户需求)中不可或缺的组成部分。 使用自动化机器学习结合各种技术和方法,获得推荐的高质量时间序列预测。 有关 AutoML 支持的算法列表,请参阅 支持的算法。
自动时序试验将问题视为多变量回归问题。 将“透视”过去的时序值,使其成为回归量与其他预测器的更多维度。 与传统时序方法不同,这种方法的优点是,在训练过程中自然包含多个上下文变量及其相互关系。 自动化 ML 会针对数据集和预测时间范围内的所有项目,习得通常有内部分支的单个模型。 这样,就有更多数据可用于估计模型参数,使得未知系列的泛化成为可能。
高级预测配置包括:
- 假日检测和特征化
- 时序和 DNN 学习器(Auto-ARIMA、Prophet、ForecastTCN)
- 通过分组支持多个模型
- 滚动原点交叉验证
- 可配置滞后
- 滚动窗口聚合特征
有关预测和自动化机器学习的示例,请参阅以下 Python 笔记本: 能源需求。
计算机视觉
通过对计算机视觉任务的支持,可以轻松地为图像分类和对象检测等方案生成针对图像数据训练的模型。
借助此功能,可以:
- 与 Azure 机器学习数据标签功能无缝集成。
- 使用标签数据生成图像模型。
- 通过指定模型算法并优化超参数来优化模型性能。
- 下载生成的模型或将其部署为 Azure 机器学习中的 Web 服务。
- 大规模运作,利用 Azure 机器学习 MLOps 和 ML 管道功能。
可以使用 Azure 机器学习 Python SDK 为视觉任务创作 AutoML 模型。 可以从 Azure 机器学习工作室 UI 访问生成的试验作业、模型和输出。
了解如何为计算机视觉模型设置 AutoML 训练。
 图像来自:http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
图像来自:http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
图像自动 ML 支持以下计算机视觉任务:
| 任务 | 说明 |
|---|---|
| 多类图像分类 | 仅使用一组类中的单个标签对图像进行分类的任务 - 例如,每个图像都分类为“猫”或“狗”或“鸭子”图像。 |
| 多标签图像分类 | 图像可以具有一组标签中的一个或多个标签的任务 - 例如,图像可以同时标记为“猫”和“狗”。 |
| 对象检测 | 用于标识图像中的对象以及使用边界框定位每个对象的任务,例如,在图像中查找所有狗和猫,并围绕每个对象绘制边界框。 |
| 实例分段 | 在像素级别标识图像中对象的任务,围绕图像中的每个对象绘制多边形。 |
自然语言处理:NLP
支持自动化 ML 中的自然语言处理(NLP)任务,使你能够轻松生成针对文本数据训练的模型,以便进行文本分类和命名实体识别方案。 可以通过 Azure 机器学习 Python SDK 创作自动化 ML 训练的 NLP 模型。 可以从 Azure 机器学习工作室 UI 访问生成的试验作业、模型和输出。
NLP 功能支持:
- 使用最新预先训练的 BERT 模型进行端到端深度神经网络 NLP 训练
- 与 Azure 机器学习数据标签无缝集成
- 使用标记数据生成 NLP 模型
- 104 种语言的多语言支持
- 使用 Horovod 进行分布式训练
了解如何为 NLP 模型设置 AutoML 训练。
训练、验证和测试数据
借助自动化 ML,可以提供训练数据来训练 ML 模型,并可以指定要执行的模型验证类型。 自动化 ML 在训练中执行模型验证。 也就是说,自动化 ML 使用验证数据根据应用的算法来优化模型超参数,以找到适合训练数据的最佳组合。 但是,每次优化迭代都使用相同的验证数据,这样会导致模型评估偏差,因为模型会不断改进和适应这些验证数据。
为帮助确认此类偏差未应用于最终推荐的模型,自动化 ML 支持使用测试数据来评估自动化 ML 在试验结束时推荐的最终模型。 如果在 AutoML 试验配置中提供测试数据,则在默认情况下,会在试验(预览版)结束时测试此推荐模型。
重要
使用测试数据集测试模型以评估生成的模型是一项预览功能。 此功能是一个试验性预览功能,可能会随时更改。
了解如何通过 SDK 或 Azure 机器学习工作室配置 AutoML 试验以使用测试数据(预览版)。
特性工程
特征工程使用数据的域知识来创建有助于 ML 算法更好地学习的特征。 在 Azure 机器学习中,缩放和规范化技术有助于进行特征工程。 这些技术和特征工程统称为特征化。
对于自动化机器学习试验,特征化会自动进行,但你也可以根据数据对其进行自定义。 详细了解包含的特征化 (SDK v1) 以及 AutoML 如何帮助防止模型中出现过度拟合与数据不均衡。
注意
自动化机器学习特征化步骤(例如特征规范化、处理缺失数据以及将文本转换为数字)将成为基础模型的一部分。 使用模型进行预测时,训练期间应用的相同特征化步骤会自动应用于输入数据。
自定义特征化
还可以使用其他特征工程技术,例如编码和转换。
可通过以下方式启用此设置:
集成模型
自动化机器学习支持默认已启用的系综模型。 组合学习通过组合多个模型而不是使用单一模型来提高机器学习结果和预测性能。 系综迭代显示为作为的最后一个迭代。 自动化机器学习使用投票和堆叠系综方法来组合模型:
- 投票:根据预测类概率(针对分类任务)或预测回归目标(针对回归任务)的加权平均值进行预测。
- 堆叠:组合异类模型并基于单个模型的输出训练元模型。 当前的默认元模型是 LogisticRegression(对于分类任务)和 ElasticNet(对于回归/预测任务)。
具有已排序合奏初始化的Caruana合奏选择算法决定在合奏中使用哪些模型。 从较高层面看,此算法使用个体评分最高的最多五个模型来初始化集成,并验证这些模型是否在最佳评分的 5% 阈值范围内,以避免初始系综不佳。 然后,对于每个系综迭代,会将一个新模型添加到现有系综,并计算最终评分。 如果新模型提高了现有集成的分数,集成将更新,以纳入新模型。
请参阅 AutoML 包,了解如何在自动化机器学习中更改默认系综设置。
AutoML 和 ONNX
借助 Azure 机器学习,可以使用自动化 ML 来生成 Python 模型并将其转换为 ONNX 格式。 模型采用 ONNX 格式后,可以在各种平台和设备上运行它们。 详细了解如何使用 ONNX 加速 ML 模型。
在此 Jupyter 笔记本示例中了解如何转换为 ONNX 格式。 了解 ONNX 支持的算法。
ONNX 运行时还支持 C#。因此,你可以在 C# 应用中使用自动生成的模型,而无需重新编写代码,同时可避免 REST 终结点造成的任何网络延迟。 详细了解在带有 ML.NET 的 .NET 应用程序中使用 AutoML ONNX 模型和使用 ONNX 运行时 C# API 推断 ONNX 模型。
后续步骤
要快速上手 AutoML,请使用以下资源。
教程和操作指南文章
教程是 AutoML 方案的端到端介绍性示例。
有关代码首次体验,请遵循 教程:使用 AutoML 和 Python 训练对象检测模型。
指南文章提供有关自动化 ML 功能的更多详细信息。 例如,
配置自动训练试验的设置
了解如何使用 Python 训练计算机视觉模型。
Jupyter 笔记本示例
查看用于自动化机器学习的 GitHub 笔记本存储库示例中的详细代码示例和用例。
Python SDK 参考
阅读 AutoML Job 类参考文档,加深你对 SDK 设计模式和类规范的专业知识的理解。
注意
自动化机器学习功能也可以在其他 Microsoft 解决方案(例如 ML.NET、HDInsight、Power BI 和 SQL Server)中使用。