Azure 机器学习环境封装了您的机器学习训练或推理进行的环境。 它们为训练和评分脚本指定 Python 包和软件设置。 机器学习工作区管理并版本这些环境,跨各种计算目标实现可重现、可审核和可移植的机器学习工作流。 使用 Environment 对象去:
- 开发训练脚本。
- 在 Azure 机器学习计算中重用相同的环境进行大规模的模型训练。
- 使用该相同环境部署你的模型。
- 重新访问在其中训练了现有模型的环境。
下图说明了如何将单个 Environment 对象同时用于你的作业配置(用于训练)与你的推理和部署配置(用于 Web 服务部署)。
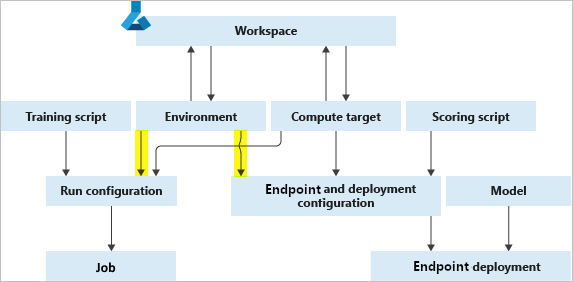
环境、计算目标和训练脚本共同构成了作业配置:完整的训练作业规范。
环境类型
环境分为三个类别:精心挑选、用户管理、系统托管。
特选环境由 Azure 机器学习提供,且默认可用于你的工作区。 按原样使用它们。 它们包含 Python 包和设置的集合,可帮助你开始使用各种机器学习框架。 这些预先创建的环境还可以加快部署速度。 Azure 机器学习在 AzureML 注册表中托管特选环境,它是由Microsoft托管的 机器学习注册表 。 有关完整列表,请参阅 AzureML 注册表中的环境。
在用户管理的环境中,你需要负责设置环境,并在计算目标上安装训练脚本所需的每个包。 此外,请确保包含模型部署所需的任何依赖项。 用户管理的环境可以是 BYOC(自带容器),也可以基于 Docker 生成上下文,可将映像具体化委托给 Azure 机器学习来处理。 与特选环境类似,可以使用所创建和管理的机器学习注册表跨工作区共享用户管理的环境。
如果希望 conda 为你管理 Python 环境,请使用系统托管的环境。 新的 conda 环境将从基础 Docker 映像顶层的 conda 规范具体化。
创建和管理环境
可以使用 Azure 机器学习 Python SDK、Azure 机器学习 CLI、Azure 机器学习工作室和 VS Code 扩展创建环境。 每个客户端都允许根据需要自定义基本映像、Dockerfile 和 Python 层。
如需具体的代码示例,请参阅如何使用环境中的“创建环境”部分。
还可以通过工作区管理环境。 使用您的工作区,您可以:
- 注册环境。
- 从工作区提取环境以用于训练或部署。
- 通过编辑现有环境来创建环境的新实例。
- 查看环境随时间的变化,确保可重现性。
- 从环境自动生成 Docker 映像。
提交试验时,服务会自动在工作区中注册“匿名”环境。 这些环境未列出,但你可以使用版本来检索它们。
如需代码示例,请参阅如何使用环境中的“管理环境”部分。
生成、缓存和重复使用环境
Azure 机器学习将环境定义生成到 Docker 映像中。 它还会缓存环境,以便在后续训练作业和服务终结点部署中重复使用它们。 远程运行训练脚本需要创建 Docker 映像。 默认情况下,如果未为工作区设置专用计算,则 Azure 机器学习将根据可用的工作区无服务器计算配额管理映像生成目标。
注意
Azure 机器学习工作区中的任何网络限制可能要求设置专用的、用户管理的映像生成计算。 请按照保护工作区资源的步骤操作。
借助特定环境提交作业
首次使用环境或手动创建环境实例提交远程作业时,Azure 机器学习会为提供的规范生成映像。 生成的映像缓存在与工作区关联的容器注册表实例中。 特选环境已缓存在 Azure 机器学习注册表中。 开始执行作业时,计算目标会从相关容器注册表检索该映像。
以 Docker 映像的形式生成环境
如果与 Azure 机器学习工作区关联的容器注册表实例中尚不存在特定环境定义的映像,该服务将生成一个新映像。 对于系统托管环境,映像生成过程包括两个步骤:
- 下载基础映像,并执行任何 Docker 步骤
- 根据环境定义中指定的 conda 依赖项生成 conda 环境。
对于用户托管环境,该服务按原样使用提供的 docker 上下文生成。 在这种情况下,你将负责安装任何 Python 包,方法是将其包含在基本映像中,或指定自定义 Docker 步骤。
缓存和重复使用映像
如果对另一个作业使用相同的环境定义,Azure 机器学习会重复使用与工作区关联的容器注册表中的缓存映像。
若要查看缓存映像的详细信息,请查看 Azure 机器学习工作室中的“环境”页或使用 MLClient.environments 获取和检查环境。
为了确定是要重用缓存的映像还是生成新映像,Azure 机器学习会从环境定义计算哈希值。 然后将其与现有环境的哈希值进行比较。 哈希充当环境的唯一标识符,基于环境定义:
- 基础映像
- 自定义 Docker 步骤
- Python 包
环境名称和版本对哈希没有影响。 如果重命名环境或创建与另一个环境相同的设置和包的新环境,则哈希值保持不变。 但是,环境定义更改(例如添加或删除 Python 包或更改包版本)会更改生成的哈希值。 更改环境中依赖项或通道的顺序会更改哈希,并需要生成新映像。 同样,对特选环境所做的任何更改都会导致创建自定义环境。
注意
如果不更改环境的名称,则无法将任何本地更改提交到特选环境。 前缀“AzureML-”和“Microsoft”专用于特选环境,如果名称以其中任一开头,作业提交将失败。
环境的计算哈希值将与工作区容器注册表中的哈希值进行比较。 如果有匹配项,则会拉取并使用缓存的镜像。 否则,将触发映像生成。
下图显示了三个环境定义。 其中两个环境的名称和版本不同,但基础映像和 Python 包相同,这会导致生成相同的哈希和相应的缓存映像。 第三个环境具有不同的 Python 包和版本,从而导致生成不同的哈希和缓存映像。
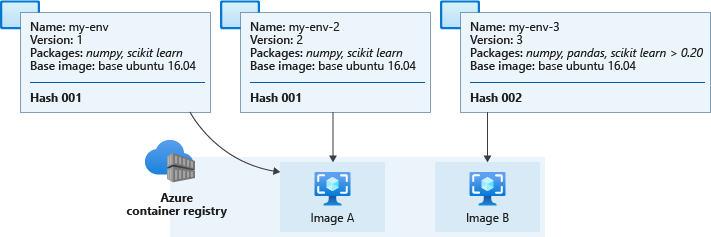
工作区容器注册表中的实际缓存映像的名称类似于 azureml/azureml_e9607b2514b066c851012848913ba19f,哈希显示在末尾。
重要
如果使用未固定的包依赖项(例如
numpy)创建环境,则环境将使用创建环境时可用的包版本。 使用匹配定义的任何未来环境都使用原始版本。若要更新包,请指定版本号以强制重新生成映像。 此更改的一个示例是更新
numpy到numpy==1.18.1。 安装了新的依赖项(包括嵌套依赖项),它们可能会中断以前工作的方案。使用未固定版本的基础映像,如在环境定义中使用
mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04,可能会导致每次更新latest标签时重新生成映像。 此行为可帮助映像接收最新的修补程序和系统更新。
映像修补
Microsoft更新已知安全漏洞的基础映像。 支持的映像的更新每两周发布一次,最新版本的映像没有 30 天以上的未修补漏洞。 修补的映像是使用新的不可变标记发布的, :latest 该标记将更新为已修补映像的最新版本。
你需要更新关联的 Azure 机器学习资产以使用新修补的映像。 例如,使用托管联机终结点时,你需要重新部署终结点以使用修补的映像。
如果你提供自己的映像,则需负责更新它们并更新使用这些映像的 Azure 机器学习资产。
有关基础映像的详细信息,请参阅以下链接:
- Azure 机器学习基础映像 GitHub 存储库。
- 使用自定义容器将模型部署到联机终结点
- 管理环境和容器映像