Azure DevOps Services | Azure DevOps Server 2022 - Azure DevOps Server 2019
可以使用 Azure DevOps Pipelines 自动执行机器学习生命周期。 可以自动执行的操作包括:
- 数据准备(提取、转换、加载作)。
- 使用按需横向扩展和纵向扩展训练机器学习模型。
- 将机器学习模型部署为公共或专用 Web 服务。
- 监视部署的机器学习模型(例如性能或数据偏移分析)。
本文介绍如何创建一个 Azure 管道,用于生成机器学习模型并将其部署到 Azure 机器学习。
本教程使用 Azure 机器学习 Python SDK v2 和 Azure CLI ML 扩展 v2。
先决条件
- 完成 创建资源以开始学习以下教程 :
- 创建工作区
- 创建用于训练模型的基于云的计算群集 。
- 已安装用于在本地运行 Azure ML SDK v2 脚本的 Python 3.10 或更高版本。
- 安装适用于 Azure Pipelines 的 Azure 机器学习扩展。 可以从 Visual Studio 市场安装此扩展。
步骤 1:获取代码
从 GitHub 分叉以下存储库:
https://github.com/azure/azureml-examples
步骤 2:创建项目
登录到 Azure。 搜索并选择 Azure DevOps 组织。 选择“ 查看我的组织”。 选择要使用的组织。
在所选组织中,创建项目。 如果组织中没有任何项目,则会显示创建项目并开始使用屏幕。 或者选择仪表板右上角的“新建项目”按钮。
步骤 3:创建服务连接
可使用现有的服务连接。
需要 Azure 资源管理器连接才能通过 Azure 门户进行身份验证。
在 Azure DevOps 中,选择 “项目设置”,然后选择“ 服务连接”。
选择“ 创建服务连接”,选择 “Azure 资源管理器”,然后选择“ 下一步”。
使用标识类型和凭据的默认值。
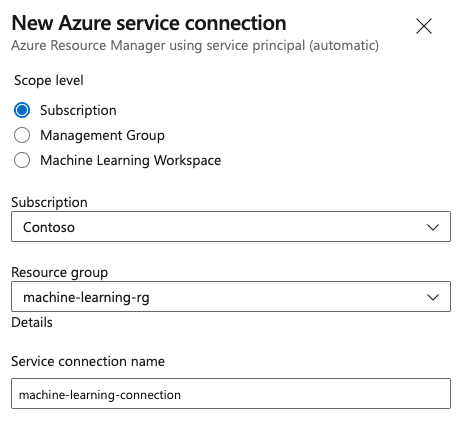
创建服务连接。 设置首选范围级别、订阅、资源组和连接名称。
步骤 4:创建管道
转到 管道,然后选择“ 创建管道”。
选择 GitHub 作为源代码位置。
可能会重定向到 GitHub 进行登录。 如果是,请输入 GitHub 凭据。
看到存储库列表时,请选择你的存储库。
你可能会被重定向到 GitHub 来安装 Azure Pipelines 应用。 如果是,请选择“ 批准并安装”。
选择“初学者管道”。 你将更新初学者管道模板。
步骤 5:创建 YAML 管道以提交 Azure 机器学习作业
删除初学者管道,并将其替换为以下 YAML 代码。 在此管道中,你将:
- 使用 Python 版本任务设置 Python 3.10 并安装 SDK 要求。
- 使用 Bash 任务为 Azure 机器学习 SDK 和 CLI 运行 bash 脚本。
- 使用 Azure CLI 任务提交 Azure 机器学习作业。
选择以下选项卡之一,具体取决于是使用 Azure 资源管理器服务连接还是通用服务连接。 在管道 YAML 中,将变量的值替换为与资源对应的值。
name: submit-azure-machine-learning-job
trigger:
- none
variables:
service-connection: 'machine-learning-connection' # replace with your service connection name
resource-group: 'machinelearning-rg' # replace with your resource group name
workspace: 'docs-ws' # replace with your workspace name
jobs:
- job: SubmitAzureMLJob
displayName: Submit AzureML Job
timeoutInMinutes: 300
pool:
vmImage: ubuntu-latest
steps:
- task: UsePythonVersion@0
displayName: Use Python >=3.10
inputs:
versionSpec: '>=3.10'
- bash: |
set -ex
az version
az extension add -n ml
displayName: 'Add AzureML Extension'
- task: AzureCLI@2
name: submit_azureml_job_task
displayName: Submit AzureML Job Task
inputs:
azureSubscription: $(service-connection)
workingDirectory: 'cli/jobs/pipelines-with-components/nyc_taxi_data_regression'
scriptLocation: inlineScript
scriptType: bash
inlineScript: |
# submit component job and get the run name
job_name=$(az ml job create --file single-job-pipeline.yml -g $(resource-group) -w $(workspace) --query name --output tsv)
# set output variable for next task
echo "##vso[task.setvariable variable=JOB_NAME;isOutput=true;]$job_name"
步骤 6:等待 Azure 机器学习作业完成
在步骤 5 中,你添加了一个提交 Azure 机器学习作业的作业。 在此步骤中,另外添加一个等待 Azure 机器学习作业完成的作业。
如果使用资源管理器服务连接,可以使用机器学习扩展。 可以在 Azure DevOps 扩展市场中 搜索此扩展,也可以直接转到 扩展页。 安装机器学习扩展。
重要
不要安装 机器学习(经典) 扩展。 它是一个不提供相同功能的较旧扩展。
在“管道评审”窗口中,添加服务器作业。 在作业的步骤部分中,选择“ 显示助手”,然后搜索 AzureML。 选择AzureML Job Wait任务,然后输入作业相关的信息。
该任务有四个输入:Service Connection、Azure Resource Group Name和AzureML Workspace NameAzureML Job Name。 提供这些输入。 这些步骤生成的 YAML 类似于以下示例:
注意
- Azure 机器学习作业等待任务在服务器作业上运行,该作业不使用昂贵的代理池资源,无需额外付费。 服务器作业(由
pool: server指示)在管道所在的计算机上运行。 有关详细信息,请参阅服务器作业。 - 一个 Azure 机器学习作业等待任务只能等待一个作业。 需要为每个需要等待的作业设置单独的任务。
- Azure 机器学习作业等待任务最多可以等待两天。 此限制是由 Azure DevOps 管道设置的硬性限制。
- job: WaitForAzureMLJobCompletion
displayName: Wait for AzureML Job Completion
pool: server
timeoutInMinutes: 0
dependsOn: SubmitAzureMLJob
variables:
# Save the name of the azureMl job submitted in the previous step to a variable. It will be used as an input to the AzureML Job Wait task.
azureml_job_name_from_submit_job: $[ dependencies.SubmitAzureMLJob.outputs['submit_azureml_job_task.JOB_NAME'] ]
steps:
- task: AzureMLJobWaitTask@1
inputs:
serviceConnection: $(service-connection)
resourceGroupName: $(resource-group)
azureMLWorkspaceName: $(workspace)
azureMLJobName: $(azureml_job_name_from_submit_job)
步骤 7:提交管道并验证管道的运行
选择“保存并运行”。 管道将等待 Azure 机器学习作业完成并结束 WaitForJobCompletion 任务,其状态与 Azure 机器学习作业相同。 例如:
Azure 机器学习作业 Succeeded == WaitForJobCompletion 作业下的 Azure DevOps 任务 Succeeded
Azure 机器学习作业 Failed == WaitForJobCompletion 作业下的 Azure DevOps 任务 Failed
Azure 机器学习作业 Cancelled == WaitForJobCompletion 作业下的 Azure DevOps 任务 Cancelled
提示
可以在 Azure 机器学习工作室中查看完整的 Azure 机器学习作业。
清理资源
如果你不打算继续使用管道,请删除 Azure DevOps 项目。 在 Azure 门户中,删除资源组和 Azure 机器学习实例。