本文介绍了如何查看从任何自动化机器学习训练模型生成的训练代码。
使用自动化 ML 训练模型的代码生成,你可以查看自动化 ML 用于为特定运行训练和生成模型的以下详细信息。
- 数据预处理
- 算法选择
- 特征化
- 超参数
可以选择任何自动化 ML 训练模型、推荐模型或子运行,并查看创建该特定模型的生成的 Python 训练代码。
使用生成的模型的训练代码,可以:
- 了解模型算法使用的特征化过程和超参数。
- 跟踪/版本控制/审核经过训练的模型。 存储版本控制的代码,以跟踪与要部署到生产环境的模型一起使用的特定训练代码。
- 通过更改超参数或应用 ML 算法技能/经验来自定义训练代码,然后使用自定义代码重新训练新模型。
下图演示了可以使用所有任务类型为自动化 ML 试验生成代码。 首先选择模型。 选择的模型将突出显示,然后 Azure 机器学习会复制用于创建模型的代码文件,并将它们显示在笔记本共享文件夹中。 在此处,可以根据需要查看和自定义代码。
Azure 机器学习工作区。 若要创建工作区,请参阅创建工作区资源。
自动化 ML 代码生成仅适用于在远程 Azure 机器学习计算目标上运行的试验。 本地运行不支持代码生成。
通过 Azure 机器学习工作室、SDKv2 或 CLIv2 触发的所有自动化 ML 运行都将启用代码生成。
默认情况下,每个自动化 ML 训练模型都会在训练完成后生成其训练代码。 自动化 ML 将此代码保存在该特定模型的试验的 outputs/generated_code 中。 可以在 Azure 机器学习工作室 UI 中所选模型的“输出 + 日志”选项卡上查看它们。
script.py 这是模型的训练代码,你可能想要分析其中的特征化步骤、使用的特定算法和超参数。
script_run_notebook.ipynb 包含样板代码的笔记本,用于通过 Azure 机器学习 SDKv2 在 Azure 机器学习计算中运行模型的训练代码 (script.py)。
自动化 ML 训练运行完成后,可以通过 Azure 机器学习工作室 UI 访问 script.py 和 script_run_notebook.ipynb 文件。
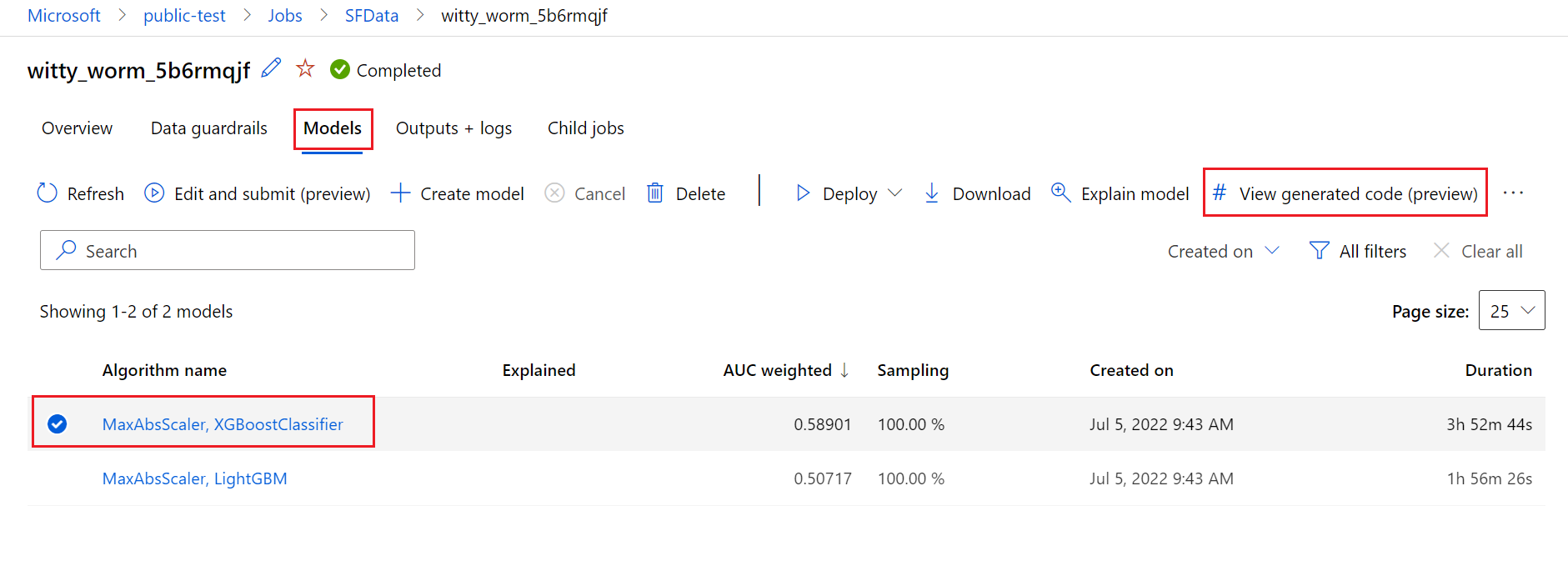
为此,请导航至自动化 ML 试验父运行页的“模型”选项卡。 选择一个已训练的模型后,可以选择“查看生成的代码”按钮。 此按钮会将你重定向到“笔记本”门户扩展,可在其中查看、编辑和运行为该特定所选模型生成的代码。
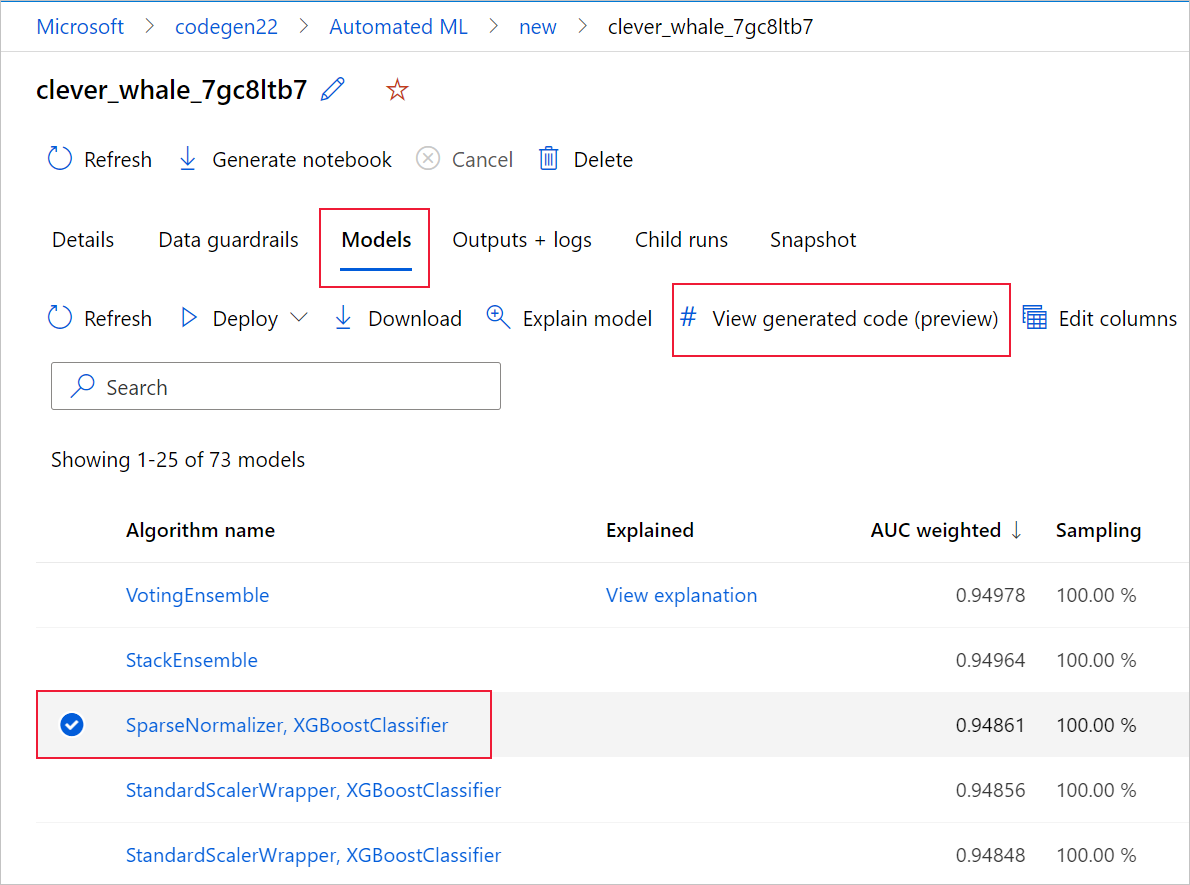
还可以在导航到特定模型的子运行页后,从子运行页的顶部访问模型生成的代码。
如果使用的是 Python SDKv2,则还可以通过 MLFlow 检索最佳运行并下载生成的项目来下载“script.py”和“script_run_notebook.ipynb”。
script.py 文件包含使用先前使用的超参数训练模型所需的核心逻辑。 虽然模型的训练代码计划在 Azure 机器学习脚本运行的上下文中执行,但经过一些修改,这些代码也可以在你自己的本地环境中独立运行。
该脚本大致可以分为以下几个部分:数据加载、数据准备、数据特性化、预处理器/算法规范和训练。
函数 get_training_dataset() 可加载先前使用的数据集。 它假定脚本在 Azure 机器学习脚本中运行,该脚本在与原始试验相同的工作区下运行。
def get_training_dataset(dataset_id):
from azureml.core.dataset import Dataset
from azureml.core.run import Run
logger.info("Running get_training_dataset")
ws = Run.get_context().experiment.workspace
dataset = Dataset.get_by_id(workspace=ws, id=dataset_id)
return dataset.to_pandas_dataframe()
在脚本运行中运行时,Run.get_context().experiment.workspace 将检索正确的工作区。 但是,如果此脚本在其他工作区内运行或在本地运行,则需要修改脚本以显式指定适当的工作区。
检索到工作区后,将通过原始数据集 ID 检索原始数据集。 结构完全相同的另一个数据集也可以通过 ID 或名称分别使用 get_by_id() 或 get_by_name() 进行指定。 稍后可以在脚本中与以下代码类似的部分中找到 ID。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--training_dataset_id', type=str, default='xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx', help='Default training dataset id is populated from the parent run')
args = parser.parse_args()
main(args.training_dataset_id)
还可以选择将整个函数替换为你自己的数据加载机制;唯一的约束是返回值必须是 Pandas 数据帧,并且数据的形状必须与原始试验中的形状相同。
函数 prepare_data() 可清理数据、拆分特征列和样本权重列,并准备数据以用于训练。
此函数可能因数据集类型和试验任务类型(分类、回归、时序预测、图像或 NLP 任务)而异。
以下示例显示,通常会传入数据加载步骤的数据帧。 提取标签列和样本权重(如果最初指定),并从输入数据中删除包含 NaN 的行。
def prepare_data(dataframe):
from azureml.training.tabular.preprocessing import data_cleaning
logger.info("Running prepare_data")
label_column_name = 'y'
# extract the features, target and sample weight arrays
y = dataframe[label_column_name].values
X = dataframe.drop([label_column_name], axis=1)
sample_weights = None
X, y, sample_weights = data_cleaning._remove_nan_rows_in_X_y(X, y, sample_weights,
is_timeseries=False, target_column=label_column_name)
return X, y, sample_weights
如果要执行任何其他数据准备,可以在此步骤中通过添加自定义数据准备代码来完成。
函数 generate_data_transformation_config() 可指定最终 scikit-learn 管道中的特征化步骤。 原始试验中的特征化器及其参数在此处重现。
例如,此函数中可能发生的数据转换可以基于 SimpleImputer() 和 CatImputer() 之类的插补器,或 StringCastTransformer() 和 LabelEncoderTransformer() 之类的转换器。
下面是一个类型为 StringCastTransformer() 的转换器,可用于转换一组列。 在此例中,由 column_names 指示这组列。
def get_mapper_0(column_names):
# ... Multiple imports to package dependencies, removed for simplicity ...
definition = gen_features(
columns=column_names,
classes=[
{
'class': StringCastTransformer,
},
{
'class': CountVectorizer,
'analyzer': 'word',
'binary': True,
'decode_error': 'strict',
'dtype': numpy.uint8,
'encoding': 'utf-8',
'input': 'content',
'lowercase': True,
'max_df': 1.0,
'max_features': None,
'min_df': 1,
'ngram_range': (1, 1),
'preprocessor': None,
'stop_words': None,
'strip_accents': None,
'token_pattern': '(?u)\\b\\w\\w+\\b',
'tokenizer': wrap_in_lst,
'vocabulary': None,
},
]
)
mapper = DataFrameMapper(features=definition, input_df=True, sparse=True)
return mapper
请注意,如果有许多列需要应用相同的特征化/转换(例如,多个列组中的 50 列),则将通过基于类型的分组来处理这些列。
在以下示例中,请注意每个组都应用了唯一的映射器。 然后,此映射器应用于该组的每个列。
def generate_data_transformation_config():
from sklearn.pipeline import FeatureUnion
column_group_1 = [['id'], ['ps_reg_01'], ['ps_reg_02'], ['ps_reg_03'], ['ps_car_11_cat'], ['ps_car_12'], ['ps_car_13'], ['ps_car_14'], ['ps_car_15'], ['ps_calc_01'], ['ps_calc_02'], ['ps_calc_03']]
column_group_2 = ['ps_ind_06_bin', 'ps_ind_07_bin', 'ps_ind_08_bin', 'ps_ind_09_bin', 'ps_ind_10_bin', 'ps_ind_11_bin', 'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_ind_16_bin', 'ps_ind_17_bin', 'ps_ind_18_bin', 'ps_car_08_cat', 'ps_calc_15_bin', 'ps_calc_16_bin', 'ps_calc_17_bin', 'ps_calc_18_bin', 'ps_calc_19_bin', 'ps_calc_20_bin']
column_group_3 = ['ps_ind_01', 'ps_ind_02_cat', 'ps_ind_03', 'ps_ind_04_cat', 'ps_ind_05_cat', 'ps_ind_14', 'ps_ind_15', 'ps_car_01_cat', 'ps_car_02_cat', 'ps_car_03_cat', 'ps_car_04_cat', 'ps_car_05_cat', 'ps_car_06_cat', 'ps_car_07_cat', 'ps_car_09_cat', 'ps_car_10_cat', 'ps_car_11', 'ps_calc_04', 'ps_calc_05', 'ps_calc_06', 'ps_calc_07', 'ps_calc_08', 'ps_calc_09', 'ps_calc_10', 'ps_calc_11', 'ps_calc_12', 'ps_calc_13', 'ps_calc_14']
feature_union = FeatureUnion([
('mapper_0', get_mapper_0(column_group_1)),
('mapper_1', get_mapper_1(column_group_3)),
('mapper_2', get_mapper_2(column_group_2)),
])
return feature_union
此方法可让你的代码更精简,因为每列都不包含转换器的代码块,而即使数据集中只有数十或数百列,这种代码块也特别繁琐。
对于分类和回归任务,[FeatureUnion] 用于特征化器。
对于时序预测模型,会将多个时序感知特征化器收集到 scikit-learn 管道中,然后包装在 TimeSeriesTransformer 中。
用户为时序预测模型提供的任何特征化都发生在自动化 ML 提供的特征化之前。
函数 generate_preprocessor_config()(如果存在)指定在最终 scikit-learn 管道中进行特征化后要完成的预处理步骤。
通常,此预处理步骤仅包含使用 sklearn.preprocessing 完成的数据标准化/规范化。
自动化 ML 仅为非集成分类和回归模型指定预处理步骤。
下面是生成的预处理器代码的示例:
def generate_preprocessor_config():
from sklearn.preprocessing import MaxAbsScaler
preproc = MaxAbsScaler(
copy=True
)
return preproc
算法和超参数规范代码可能是许多 ML 专业人员最感兴趣的内容。
generate_algorithm_config() 函数将用于训练模型的实际算法和超参数指定为最终 scikit-learn 管道的最后阶段。
以下示例使用具有特定超参数的 XGBoostClassifier 算法。
def generate_algorithm_config():
from xgboost.sklearn import XGBClassifier
algorithm = XGBClassifier(
base_score=0.5,
booster='gbtree',
colsample_bylevel=1,
colsample_bynode=1,
colsample_bytree=1,
gamma=0,
learning_rate=0.1,
max_delta_step=0,
max_depth=3,
min_child_weight=1,
missing=numpy.nan,
n_estimators=100,
n_jobs=-1,
nthread=None,
objective='binary:logistic',
random_state=0,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=None,
silent=None,
subsample=1,
verbosity=0,
tree_method='auto',
verbose=-10
)
return algorithm
大多数情况下,生成的代码使用开源软件 (OSS) 包和类。 在某些情况下,使用中间包装类简化更复杂的代码。 例如,可以应用 XGBoost 分类器和其他常用库,如 LightGBM 或 Scikit-Learn 算法。
作为 ML 专业人员,你可以根据你对该算法的技能和经验以及你的特定 ML 问题,根据需要调整算法的超参数,从而自定义该算法的配置代码。
对于集成模型,将为集成模型中的每个学习器定义 generate_preprocessor_config_N()(如果需要)和 generate_algorithm_config_N(),其中 N 表示每个学习器在集成模型列表中的位置。 对于堆栈集成模型,将定义元学习器 generate_algorithm_config_meta()。
代码生成发出 build_model_pipeline() 和 train_model(),分别用于定义 scikit-learn 管道和对其调用 fit()。
def build_model_pipeline():
from sklearn.pipeline import Pipeline
logger.info("Running build_model_pipeline")
pipeline = Pipeline(
steps=[
('featurization', generate_data_transformation_config()),
('preproc', generate_preprocessor_config()),
('model', generate_algorithm_config()),
]
)
return pipeline
Scikit-learn 管道包括特征化步骤、预处理器(如果使用)和算法或模型。
对于时序预测模型,scikit-learn 管道包装在 ForecastingPipelineWrapper 中,它具有适当处理时序数据所需的额外逻辑,具体取决于所应用的算法。
对于所有任务类型,在需要对标签列进行编码的情况下使用 PipelineWithYTransformer。
获得 scikit-learn 管道后,剩下的就是调用 fit() 方法来训练模型:
def train_model(X, y, sample_weights):
logger.info("Running train_model")
model_pipeline = build_model_pipeline()
model = model_pipeline.fit(X, y)
return model
train_model() 的返回值是根据输入数据拟合/训练的模型。
运行上述所有函数的主要代码如下:
def main(training_dataset_id=None):
from azureml.core.run import Run
# The following code is for when running this code as part of an Azure Machine Learning script run.
run = Run.get_context()
setup_instrumentation(run)
df = get_training_dataset(training_dataset_id)
X, y, sample_weights = prepare_data(df)
split_ratio = 0.1
try:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=True)
except Exception:
(X_train, y_train, sample_weights_train), (X_valid, y_valid, sample_weights_valid) = split_dataset(X, y, sample_weights, split_ratio, should_stratify=False)
model = train_model(X_train, y_train, sample_weights_train)
metrics = calculate_metrics(model, X, y, sample_weights, X_test=X_valid, y_test=y_valid)
print(metrics)
for metric in metrics:
run.log(metric, metrics[metric])
获得已训练的模型后,就可以使用它通过 predict() 方法进行预测。 如果试验是针对时序模型的,请使用 forecast() 方法进行预测。
y_pred = model.predict(X)
最后,模型被序列化并保存为名为“model.pkl”的 .pkl 文件:
with open('model.pkl', 'wb') as f:
pickle.dump(model, f)
run.upload_file('outputs/model.pkl', 'model.pkl')
script_run_notebook.ipynb 笔记本是在 Azure 机器学习计算上执行 script.py 的一种简单方法。
此笔记本类似于现有的自动化 ML 示例笔记本,但有几个主要差异,如以下部分中所述。
通常,SDK 会自动设置自动化 ML 运行的训练环境。 但是,当运行一个像生成的代码一样的自定义脚本运行时,自动化 ML 不再驱动该过程,所以必须指定环境才能使命令作业成功。
如果可能,代码生成将重用原始自动化 ML 试验中使用的环境。 这样做可以保证训练脚本运行不会因缺少依赖项而失败,并且有一个很大的优势,即不需要重新生成 Docker 映像,这可以节省时间和计算资源。
如果对需要其他依赖项的 script.py 进行更改,或者想使用自己的环境,则需要相应地更新 script_run_notebook.ipynb 中的环境。
由于生成的代码不再由自动化 ML 驱动,因此你需要创建一个 Command Job 并向其提供生成的代码 (script.py),而无需创建和提交 AutoML 作业。
以下示例包含运行命令作业所需的参数和常规依赖项,例如计算、环境等。
from azure.ai.ml import command, Input
# To test with new training / validation datasets, replace the default dataset id(s) taken from parent run below
training_dataset_id = '<DATASET_ID>'
dataset_arguments = {'training_dataset_id': training_dataset_id}
command_str = 'python script.py --training_dataset_id ${{inputs.training_dataset_id}}'
command_job = command(
code=project_folder,
command=command_str,
environment='AutoML-Non-Prod-DNN:25',
inputs=dataset_arguments,
compute='automl-e2e-cl2',
experiment_name='build_70775722_9249eda8'
)
returned_job = ml_client.create_or_update(command_job)
print(returned_job.studio_url) # link to naviagate to submitted run in Azure Machine Learning Studio
- 详细了解如何以及在何处部署模型。
- 了解如何专门在自动化机器学习试验中启用可解释性特征。