适用于: Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
开始使用 GitHub Actions 在Azure Machine Learning上训练模型。
本文介绍如何创建生成机器学习模型并将其部署到 Azure Machine Learning 的GitHub Actions工作流。 你将基于纽约出租车数据集训练 scikit-learn 线性回归模型。
GitHub Actions在存储库的 /.github/workflows/ 路径中使用工作流 YAML (.yml) 文件。 此定义包含组成工作流的各种步骤和参数。
先决条件
Azure Machine Learning工作区。 有关创建工作区的步骤,请参阅 “创建工作区”。
适用于 Python v2 的 Azure Machine Learning SDK。 若要安装 SDK,请使用以下命令:
pip install azure-ai-ml azure-identity要将 SDK 的现有安装更新到最新版本,请使用以下命令:
pip install --upgrade azure-ai-ml azure-identity有关详细信息,请参阅 Azure Machine Learning 包的 Python 客户端库。
- GitHub帐户。 如果你没有帐户,可免费注册一个。
步骤 1:获取代码
在GitHub分叉以下存储库:
https://github.com/azure/azureml-examples
在本地克隆你的派生的代码库。
git clone https://github.com/YOUR-USERNAME/azureml-examples
步骤 2:使用Azure进行身份验证
首先,定义如何使用Azure进行身份验证。 建议更安全的选项是将 OpenID Connect 与Microsoft Entra应用程序或用户分配的托管标识配合使用来登录。 如有必要,还可以 使用服务主体帐户和密钥登录。 此方法不太安全,不建议这样做。
生成部署凭据
使用 Azure CLI 中的 az ad sp create-for-rbac 命令创建 service principal。
az ad sp create-for-rbac --name "myML" --role contributor \
--scopes /subscriptions/<subscription-id>/resourceGroups/<group-name> \
--sdk-auth
在上面的示例中,请将占位符替换为你的订阅 ID、资源组名称和应用名称。 输出是一个 JSON 对象,包含的角色分配凭据可提供对应用服务应用的访问权限,如下所示。 复制此 JSON 对象供以后使用。
{
"clientId": "<GUID>",
"clientSecret": "<GUID>",
"subscriptionId": "<GUID>",
"tenantId": "<GUID>",
(...)
}
创建机密
在 GitHub 中,浏览存储库,选择 Settings > secrets > Actions。 选择“新建存储库机密”。
将Azure CLI命令的整个 JSON 输出粘贴到机密的值字段中。 为机密指定名称
AZ_CREDS。
步骤 3:更新 setup.sh 以连接到Azure Machine Learning工作区
更新 CLI 安装程序文件变量以匹配工作区。
在分支存储库中,转到
azureml-examples/cli/。编辑
setup.sh并更新文件中的这些变量。变量 说明 GROUP资源组的名称 LOCATION工作区的位置(例如 chinanorth2)WORKSPACEAzure Machine Learning 工作区的名称
步骤 4:将 pipeline.yml 替换为您的计算群集名称
使用 pipeline.yml 文件部署Azure Machine Learning管道。 该管道为机器学习管道,而不是 DevOps 管道。 如果您的计算群集名称不是 cpu-cluster,则只需进行此更新。
- 在分支存储库中,转到
azureml-examples/cli/jobs/pipelines/nyc-taxi/pipeline.yml。 - 每次看到
compute: azureml:cpu-cluster时,都使用计算群集名称更新cpu-cluster的值。 例如,如果群集名称为my-cluster,则新的值为azureml:my-cluster。 有五个更新。
步骤 5:运行GitHub Actions工作流
工作流使用Azure进行身份验证,设置Azure Machine Learning CLI,并使用 CLI 在Azure Machine Learning中训练模型。
工作流文件由触发器部分和作业组成:
- 触发器在
on部分中启动工作流。 工作流默认按照 cron 计划运行,同时也会在匹配的分支和路径发出拉取请求时运行。 详细了解触发工作流的事件。 - 在工作流的“作业”部分中,签出代码并使用服务主体机密登录到Azure。
- 作业部分还包括安装操作和设置操作,这些操作用于安装和设置Machine Learning CLI(v2)。 安装 CLI 后,运行作业操作将运行 Azure Machine Learning
pipeline.yml文件,以使用 NYC 出租车数据训练模型。
启用工作流
在分叉存储库中,打开
.github/workflows/cli-jobs-pipelines-nyc-taxi-pipeline.yml并验证工作流是否如下所示。注释
存储库中的工作流文件可能包括此处未显示的其他步骤。 以下示例显示了核心步骤。
name: cli-jobs-pipelines-nyc-taxi-pipeline on: workflow_dispatch: schedule: - cron: "0 0/4 * * *" pull_request: branches: - main paths: - cli/jobs/pipelines/nyc-taxi/** - .github/workflows/cli-jobs-pipelines-nyc-taxi-pipeline.yml - cli/run-pipeline-jobs.sh - cli/setup.sh jobs: build: runs-on: ubuntu-latest steps: - name: check out repo uses: actions/checkout@v4 - name: azure login uses: azure/login@v2 with: creds: ${{secrets.AZURE_CREDENTIALS}} - name: setup run: bash setup.sh working-directory: cli continue-on-error: true - name: run job run: bash -x ../../../run-job.sh pipeline.yml working-directory: cli/jobs/pipelines/nyc-taxi选择“查看运行”选项。
选择“我已了解工作流,请继续启用”以启用工作流。
选择 cli-jobs-pipelines-nyc-taxi-pipeline 工作流 并选择 启用工作流。

选择“运行工作流”,并选择立即运行工作流。
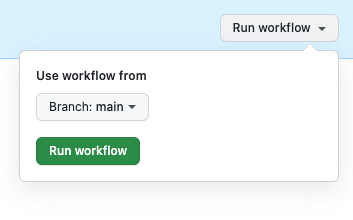
第 6 步:验证您的工作流程运行
打开已完成的工作流运行并验证生成作业是否成功运行。 你会看到工作旁边有一个绿色的复选标记。
打开Azure Machine Learning studio,转到 nyc-taxi-pipeline-example。 验证作业的每个部分(准备、转换、训练、预测、评分)是否完成,以及是否看到绿色复选标记。
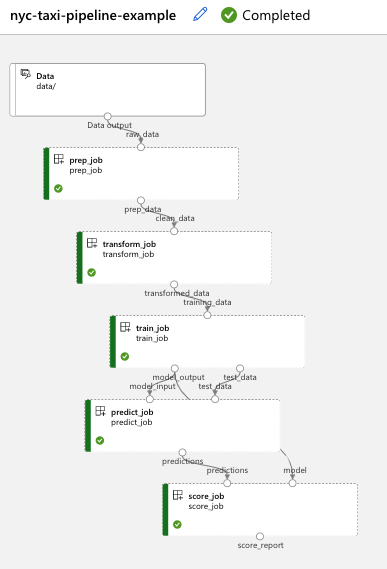
清理资源
不再需要资源组和存储库时,请通过删除资源组和GitHub存储库来清理部署的资源。