
在本操作指南中,你将了解如何将 Fairlearn 开源 Python 程序包与 Azure 机器学习配合使用来执行以下任务:
- 评估模型预测的公平性。 若要详细了解机器学习中的公平性,请参阅机器学习中的公平性一文。
- 在 Azure 机器学习工作室中上传、列出和下载公平性评估见解。
- 请查看 Azure 机器学习工作室中的公平性评估仪表板,与模型的公平性见解进行交互。
备注
公平性评估并非纯粹的技术练习。 此程序包可帮助你评估机器学习模型的公平性,但只有你可以配置并做出有关模型执行方式的决策。 虽然此程序包有助于识别用于评估公平性的量化指标,但机器学习模型的开发人员也必须执行定性分析来评估其自己的模型的公平性。
Azure 机器学习公平性 SDK azureml-contrib-fairness 在 Azure 机器学习中集成了开源 Python 程序包 Fairlearn。 若要详细了解 Azure 机器学习中的 Fairlearn 的集成,请查看这些示例笔记本。 有关 Fairlearn 的详细信息,请参阅示例指南和示例笔记本。
使用以下命令安装 azureml-contrib-fairness 和 fairlearn 程序包:
pip install azureml-contrib-fairness
pip install fairlearn==0.4.6
更高版本的 Fairlearn 还应在下面的示例代码中可用。
以下示例演示如何使用公平性包。 我们会将模型公平性见解上传到 Azure 机器学习,并查看 Azure 机器学习工作室中的公平性评估面板。
在 Jupyter Notebook 中训练示例模型。
对于数据集,我们使用从 OpenML 提取的众所周知的成人普查数据集。 假设我们有一个贷款决策问题,并使用标签指示个人是否偿还了以前的贷款。 我们将训练一个模型来预测素未相识的个人是否会偿还贷款。 这样的模型可以用于做出贷款决策。
import copy import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import make_column_selector as selector from sklearn.pipeline import Pipeline from raiwidgets import FairnessDashboard # Load the census dataset data = fetch_openml(data_id=1590, as_frame=True) X_raw = data.data y = (data.target == ">50K") * 1 # (Optional) Separate the "sex" and "race" sensitive features out and drop them from the main data prior to training your model X_raw = data.data y = (data.target == ">50K") * 1 A = X_raw[["race", "sex"]] X = X_raw.drop(labels=['sex', 'race'],axis = 1) # Split the data in "train" and "test" sets (X_train, X_test, y_train, y_test, A_train, A_test) = train_test_split( X_raw, y, A, test_size=0.3, random_state=12345, stratify=y ) # Ensure indices are aligned between X, y and A, # after all the slicing and splitting of DataFrames # and Series X_train = X_train.reset_index(drop=True) X_test = X_test.reset_index(drop=True) y_train = y_train.reset_index(drop=True) y_test = y_test.reset_index(drop=True) A_train = A_train.reset_index(drop=True) A_test = A_test.reset_index(drop=True) # Define a processing pipeline. This happens after the split to avoid data leakage numeric_transformer = Pipeline( steps=[ ("impute", SimpleImputer()), ("scaler", StandardScaler()), ] ) categorical_transformer = Pipeline( [ ("impute", SimpleImputer(strategy="most_frequent")), ("ohe", OneHotEncoder(handle_unknown="ignore")), ] ) preprocessor = ColumnTransformer( transformers=[ ("num", numeric_transformer, selector(dtype_exclude="category")), ("cat", categorical_transformer, selector(dtype_include="category")), ] ) # Put an estimator onto the end of the pipeline lr_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", LogisticRegression(solver="liblinear", fit_intercept=True), ), ] ) # Train the model on the test data lr_predictor.fit(X_train, y_train) # (Optional) View this model in the fairness dashboard, and see the disparities which appear: from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test, y_pred={"lr_model": lr_predictor.predict(X_test)})登录到 Azure 机器学习并注册你的模型。
公平性仪表板可以与已注册或未注册的模型进行集成。 在 Azure 机器学习中注册模型,步骤如下:
from azureml.core import Workspace, Experiment, Model import joblib import os ws = Workspace.from_config() ws.get_details() os.makedirs('models', exist_ok=True) # Function to register models into Azure Machine Learning def register_model(name, model): print("Registering ", name) model_path = "models/{0}.pkl".format(name) joblib.dump(value=model, filename=model_path) registered_model = Model.register(model_path=model_path, model_name=name, workspace=ws) print("Registered ", registered_model.id) return registered_model.id # Call the register_model function lr_reg_id = register_model("fairness_logistic_regression", lr_predictor)预先计算公平性指标。
使用 Fairlearn 的
metrics程序包创建一个仪表板字典。_create_group_metric_set方法的参数与仪表板构造函数类似,只是将敏感特性作为字典传递(以确保名称可用)。 调用此方法时,还必须指定预测类型(在本例中为二元分类)。# Create a dictionary of model(s) you want to assess for fairness sf = { 'Race': A_test.race, 'Sex': A_test.sex} ys_pred = { lr_reg_id:lr_predictor.predict(X_test) } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')上传预先计算的公平性指标。
现在,导入
azureml.contrib.fairness程序包以执行上传操作:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_id创建一个试验,然后创建一个运行并将仪表板上传到其中:
exp = Experiment(ws, "Test_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness insights of Logistic Regression Classifier" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()查看 Azure 机器学习工作室中的公平性仪表板
如果你完成了前面的步骤(将生成的公平性见解上传到 Azure 机器学习),则可查看 Azure 机器学习工作室中的公平性仪表板。 此仪表板与 Fairlearn 中提供的可视化效果仪表板相同,可用于分析敏感特性的子组(例如,男性与女性)之间的差异。 通过以下途径之一访问 Azure 机器学习工作室中的可视化仪表板:
- 作业窗格(预览)
- 在左窗格中选择“作业”,查看在 Azure 机器学习上运行的试验的列表。
- 选择特定的试验可查看该试验中的所有运行。
- 选择一个运行,然后选择“公平性”选项卡来查看解释可视化效果仪表板。
- 打开“公平性”选项卡后,单击右侧菜单中的“公平性 ID” 。
- 配置仪表板:将感兴趣的敏感属性、性能指标和公平性指标选入公平性评估页面。
- 将图表从一种类型切换为另一种类型,同时观察“分配”损害和“服务质量”损害 。
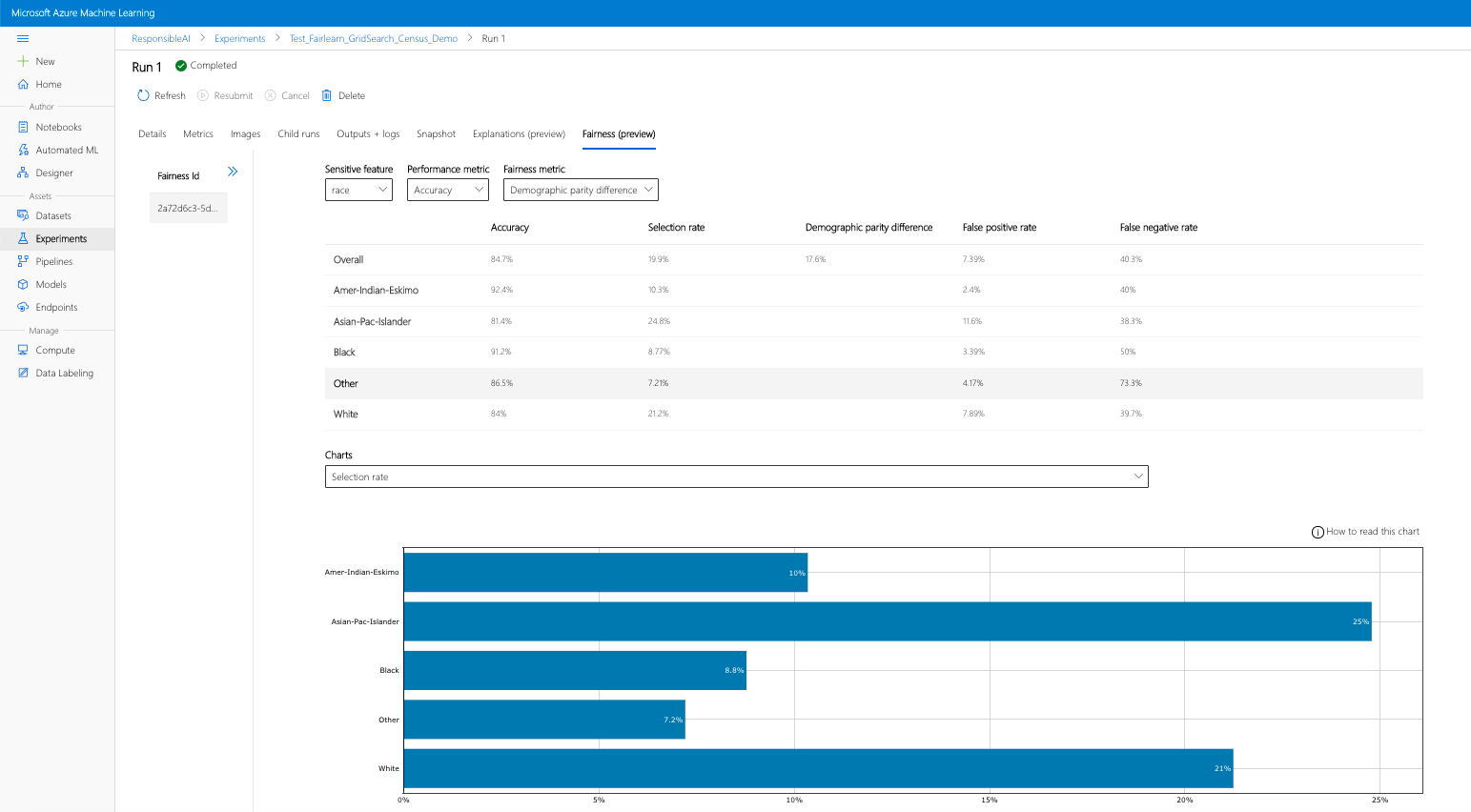
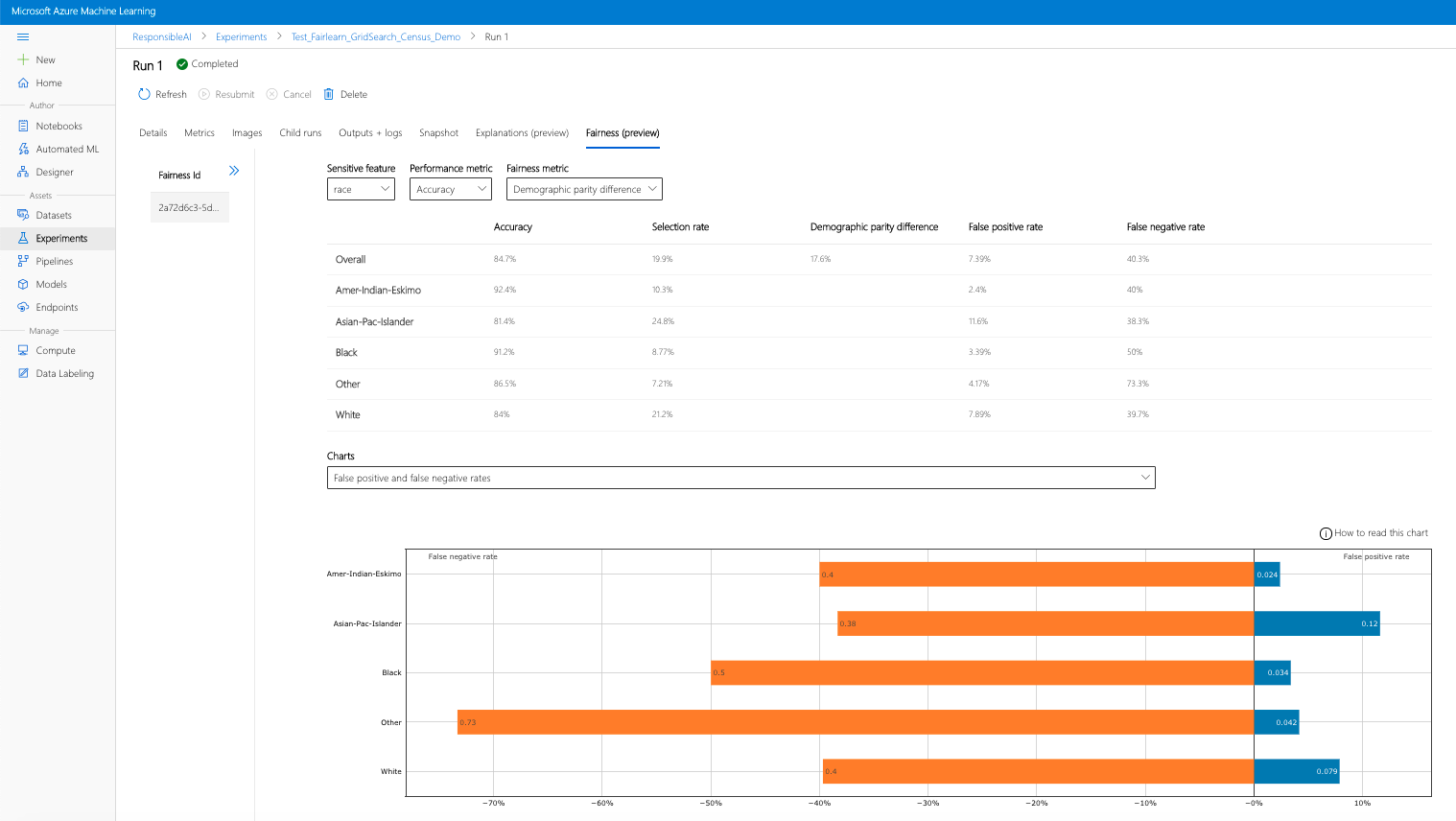
- “模型”窗格
- 如果已通过前面的步骤注册了原始模型,则可在左侧窗格中选择“模型”来查看它。
- 选择一个模型,然后选择“公平性”选项卡来查看解释可视化效果仪表板。
若要详细了解此可视化效果面板及其包含的内容,请查看 Fairlearn 的用户指南。


若要比较多个模型并了解其公平性评估的不同之处,可以将多个模型传递到可视化结果面板,并比较其性能-公平性权衡情况。
训练你的模型:
我们现在还创建一个基于“支持向量机”估算器的另一个分类器,并使用 Fairlearn 的
metrics程序包上传公平性面板字典。 我们假设以前训练的模型仍然可用。# Put an SVM predictor onto the preprocessing pipeline from sklearn import svm svm_predictor = Pipeline( steps=[ ("preprocessor", copy.deepcopy(preprocessor)), ( "classifier", svm.SVC(), ), ] ) # Train your second classification model svm_predictor.fit(X_train, y_train)注册模型
接下来,在 Azure 机器学习中注册这两个模型。 为方便起见,请将结果存储在字典中,这会将已注册模型的
id(name:version格式的字符串)映射到预测器本身:model_dict = {} lr_reg_id = register_model("fairness_logistic_regression", lr_predictor) model_dict[lr_reg_id] = lr_predictor svm_reg_id = register_model("fairness_svm", svm_predictor) model_dict[svm_reg_id] = svm_predictor在本地加载“公平性”仪表板
在将公平性见解上传到 Azure 机器学习之前,可以在通过本地方式调用的公平性仪表板中检查这些预测。
# Generate models' predictions and load the fairness dashboard locally ys_pred = {} for n, p in model_dict.items(): ys_pred[n] = p.predict(X_test) from raiwidgets import FairnessDashboard FairnessDashboard(sensitive_features=A_test, y_true=y_test.tolist(), y_pred=ys_pred)预先计算公平性指标。
使用 Fairlearn 的
metrics程序包创建一个仪表板字典。sf = { 'Race': A_test.race, 'Sex': A_test.sex } from fairlearn.metrics._group_metric_set import _create_group_metric_set dash_dict = _create_group_metric_set(y_true=Y_test, predictions=ys_pred, sensitive_features=sf, prediction_type='binary_classification')上传预先计算的公平性指标。
现在,导入
azureml.contrib.fairness程序包以执行上传操作:from azureml.contrib.fairness import upload_dashboard_dictionary, download_dashboard_by_upload_id创建一个试验,然后创建一个运行并将仪表板上传到其中:
exp = Experiment(ws, "Compare_Two_Models_Fairness_Census_Demo") print(exp) run = exp.start_logging() # Upload the dashboard to Azure Machine Learning try: dashboard_title = "Fairness Assessment of Logistic Regression and SVM Classifiers" # Set validate_model_ids parameter of upload_dashboard_dictionary to False if you have not registered your model(s) upload_id = upload_dashboard_dictionary(run, dash_dict, dashboard_name=dashboard_title) print("\nUploaded to id: {0}\n".format(upload_id)) # To test the dashboard, you can download it back and ensure it contains the right information downloaded_dict = download_dashboard_by_upload_id(run, upload_id) finally: run.complete()与上一部分类似,你可以在 Azure 机器学习工作室中遵循上述路径之一(使用试验或模型)来访问可视化结果仪表板,并比较两个模型的公平性和性能。
你可以使用 Fairlearn 的修正算法,将其生成的修正模型与原始的未修正模型进行比较,查看所比较模型在性能/公平性方面的权衡情况。
若要通过示例来了解如何使用网格搜索修正算法(用于创建一系列在公平性和性能方面进行了各种权衡的修正模型),请查看此示例笔记本。
在单个运行中上传多个模型的公平性见解就可以比较模型的公平性和性能。 你可以单击模型比较图表中显示的任何模型,以查看针对特定模型的详细公平性见解。
