适用于: Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
在Azure Machine Learning中,使用模型监视持续跟踪生产中机器学习模型的性能。 模型监视提供了监视信号和警报的广泛视图,可让你了解潜在问题。 监视生产中模型的信号和性能指标时,可以关键地评估模型固有风险。 还可以识别可能对业务产生不利影响的隐藏问题。
本文介绍如何执行以下任务:
- 为您部署到 Azure Machine Learning 在线终结点的模型设置开箱即用和高级监控
- 监视生产环境中模型的性能指标
- 监视在Azure Machine Learning外部部署的模型或部署到Azure Machine Learning批处理终结点的模型
- 设置自定义信号和指标以用于模型监视
- 解释监视结果
- 将Azure Machine Learning模型监视与Azure Event Grid集成
先决条件
安装并配置 Azure CLI 和其扩展
ml。 有关详细信息,请参阅安装和设置 CLI (v2)。Bash shell 或兼容的 shell,比如 Linux 系统上的 shell 或 Windows Subsystem for Linux。 本文中的Azure CLI示例假定你使用这种类型的 shell。
Azure Machine Learning工作区。 有关创建工作区的说明,请参阅 “设置”。
至少具有以下Azure基于角色的访问控制(Azure RBAC)角色之一的用户帐户:
- Azure Machine Learning工作区的所有者角色
- Azure Machine Learning工作区的参与者角色
- 具有
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*权限的自定义角色
有关详细信息,请参阅 管理访问 Azure 机器学习工作区。
用于监视 Azure Machine Learning 托管在线终结点或 Kubernetes 在线终结点:
部署到 Azure Machine Learning 在线端点的模型。 支持托管联机终结点和 Kubernetes 联机终结点。 有关将模型部署到Azure Machine Learning联机终结点的说明,请参阅 Deploy 并使用联机终结点对机器学习模型评分。
已为模型部署启用数据收集。 可以在部署步骤中为Azure Machine Learning联机终结点启用数据收集。 有关详细信息,请参阅 从为实时推理部署的模型收集生产数据。
若要监视部署到Azure Machine Learning批处理终结点或部署在Azure Machine Learning外部的模型:
- 收集生产数据并将其注册为Azure Machine Learning数据资产的方法
- 持续更新已注册的数据资产以监视模型的方法
- (推荐)在Azure Machine Learning工作区中注册模型,以便进行世系跟踪
配置无服务器 Spark 计算池
计划模型监视作业以在无服务器 Spark 计算池上运行。 支持以下Azure Virtual Machines实例类型:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
若要按照本文中的过程指定虚拟机实例类型,请执行以下步骤:
使用Azure CLI创建监视器时,请使用 YAML 配置文件。 在该文件中,将 create_monitor.compute.instance_type 值设置为要使用的类型。
设置开箱即用的模型监控
假设在一个场景中,您将模型部署到 Azure 机器学习的在线终结点,并在部署时启用数据收集。 在这种情况下,Azure Machine Learning收集生产推理数据,并将其自动存储在Azure Blob Storage中。 可以使用Azure Machine Learning模型监视来持续监视此生产推理数据。
可以使用 Azure CLI、Python SDK 或工作室进行模型监视的现式设置。 现成的模型监视配置提供以下监视功能:
- Azure Machine Learning自动检测与Azure Machine Learning联机部署关联的生产推理数据资产,并使用数据资产进行模型监视。
- 比较参考数据资产设置为最近的历史生产推理数据资产。
- 监视设置会自动包括和跟踪以下内置监视信号:数据偏移、预测偏移和数据质量。 对于每个监视信号,Azure Machine Learning使用:
- 最近的历史生产推理数据资产作为比较参考数据资产。
- 指标和阈值的智能默认值。
- 监控任务被配置为定期运行。 该作业获取监视信号,并根据其相应的阈值评估每个指标结果。 默认情况下,当超出任何阈值时,Azure Machine Learning向设置监视器的用户发送警报电子邮件。
若要设置开箱即用的模型监控,请执行以下步骤。
在Azure CLI中,使用 az ml schedule 来计划监视作业。
在 YAML 文件中创建监视定义。 有关开箱即用示例定义,请参阅以下示例 YAML 代码,该代码在 azureml-examples 存储库中也可用。
使用此定义之前,请调整值以适应你的环境。 对于
endpoint_deployment_id,请使用值的格式为azureml:<endpoint-name>:<deployment-name>。
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com
运行以下命令以创建模型:
az ml schedule create -f ./out-of-box-monitoring.yaml


设置高级模型监控
Azure Machine Learning为连续模型监视提供了许多功能。 有关此功能的综合列表,请参阅 模型监视的功能。 在许多情况下,需要设置支持高级监视任务的模型监视。 以下部分提供了一些高级监视示例:
- 使用多个监视信号获得广泛视图
- 使用历史模型定型数据或验证数据作为比较引用数据资产
- 监视前 N 个最重要的特征和单个特征
配置特征重要性
特征重要性表示每个输入特征对模型输出的相对重要性。 例如,温度对模型的预测可能比高程更重要。 启用特征重要性时,可以识别出那些您不希望在生产中发生漂移或出现数据质量问题的特征。
若要启用任何信号(如数据漂移或数据质量)的特征重要性,请提供:
- 训练数据资产作为
reference_data数据资产。 - 该
reference_data.data_column_names.target_column属性是模型输出列或预测列的名称。
启用特征重要性后,会看到Azure Machine Learning studio中监视的每个功能的功能重要性。
使用 Python SDK 或Azure CLI时,通过设置 alert_enabled 属性来打开或关闭每个信号的警报。
使用 Azure CLI、Python SDK 或工作室设置高级模型监视。
在 YAML 文件中创建监视定义。 有关示例高级定义,请参阅以下 YAML 代码,该代码在 azureml-examples 存储库中也可用。
使用此定义之前,请调整以下设置和任何其他设置以满足环境的需求:
- 对于
endpoint_deployment_id,请使用值的格式为azureml:<endpoint-name>:<deployment-name>。 - 对于引用输入数据部分中的
path,请使用格式为azureml:<reference-data-asset-name>:<version>的值。 - 对于
target_column,请使用包含模型预测的值的输出列的名称,例如DEFAULT_NEXT_MONTH。 - 对于
features,列出要用于高级数据质量信号的功能,例如SEX、EDUCATION和AGE。 - 在下方
emails,列出要用于通知的电子邮件地址。
- 对于
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
alert_enabled: true
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
alert_enabled: true
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com
运行以下命令以创建模型:
az ml schedule create -f ./advanced-model-monitoring.yaml






设置模型性能监控
使用Azure Machine Learning模型监视时,可以通过计算模型的性能指标来跟踪生产中模型的性能。 目前支持以下模型性能指标:
- 对于分类模型:
- 精准率
- 准确性
- 召回率
- 对于回归模型:
- 平均绝对误差 (MAE)
- 平均平方误差(MSE)
- 根均方误差(RMSE)
模型性能监视的先决条件
生产模型(模型预测)的输出数据,每行都有唯一 ID。 如果使用 Azure Machine Learning 数据收集器收集生产数据,则会为每个推理请求提供关联 ID。 数据收集器还提供从应用程序记录自己的唯一 ID 的选项。
注意事项
要监控 Azure Machine Learning 模型的性能,请使用 Azure Machine Learning 数据收集器在其自己的列中记录唯一 ID。
每行均具有唯一 ID 的基本事实数据(实际值)。 给定行的唯一 ID 应与该特定推理请求的模型输出数据的唯一 ID 匹配。 此唯一 ID 用于将地面真实数据资产与模型输出数据联接。
如果没有地面真实数据,则无法执行模型性能监视。 基本事实数据在应用程序级别出现,因此你有责任在这些数据可用时对其进行收集。 还应在包含此基本事实数据的Azure Machine Learning中维护数据资产。
(可选)已预先连接的表格数据资产,其中包含模型输出数据和真实基准数据。
使用数据收集器时监控模型性能的要求
Azure Machine Learning满足以下条件时生成相关 ID:
- 使用 Azure Machine Learning 数据收集器收集生产推理数据。
- 无需将每行的唯一 ID 作为单独列提供。
记录的 JSON 对象包括生成的关联 ID。 但是,数据收集器会批量处理在短时间间隔内发送的行。 批处理行位于同一 JSON 对象中。 在每个对象中,所有行都具有相同的关联 ID。
为了区分 JSON 对象中的行,Azure Machine Learning模型性能监视使用索引来确定对象中行的顺序。 例如,如果批处理包含三行,并且相关 ID 为 test,则第一行的 ID 为 test_0,第二行的 ID 为 test_1,第三行的 ID 为 test_2。 若要将地面真实数据资产唯一 ID 与收集的生产推理模型输出数据的 ID 匹配,请相应地为每个关联 ID 应用索引。 如果记录的 JSON 对象只有一行,则将 correlationid_0 用作 correlationid 值。
为了避免使用该索引功能,请在一个单独的列中记录您的唯一 ID。 将该列放入由 Azure Machine Learning 数据收集器记录的 pandas 数据帧中。 在模型监视配置中,可以指定此列的名称,以将模型输出数据与地面真实数据联接。 只要两个数据资产中每一行的 ID 相同,Azure Machine Learning模型监视就可以执行模型性能监视。
监视模型性能的示例工作流
若要了解与模型性能监视关联的概念,请考虑以下示例工作流。 它适用于部署模型以预测信用卡交易是否欺诈的方案:
- 将部署配置为使用数据收集器收集模型的生产推理数据(输入和输出数据)。 将输出数据存储在名为
is_fraud的列中。 - 对于收集的推理数据的每一行,请记录唯一 ID。 唯一 ID 可以来自应用程序,也可以使用Azure Machine Learning为每个记录的 JSON 对象唯一生成的
correlationid值。 - 当实际的(或真实的)
is_fraud数据可用时,请将每一行记录下并映射到模型输出数据中对应行的相同唯一 ID。 - 在 Azure Machine Learning 中注册数据资产,并使用它来收集和维护
is_fraud数据的基础事实。 - 创建一个模型性能监控信号,使用唯一的 ID 列将模型的生产推理和真实数据资产连接起来。
- 计算模型性能指标。
满足 模型性能监视的先决条件后,请执行以下步骤来设置模型监视:
在 YAML 文件中创建监视定义。 以下示例规范定义了使用生产推理数据的模型监视。 使用此定义之前,请调整以下设置和任何其他设置以满足环境的需求:
- 对于
endpoint_deployment_id,请使用值的格式为azureml:<endpoint-name>:<deployment-name>。 - 对于输入数据节中的每个
path值,请使用格式为azureml:<data-asset-name>:<version>的值。 -
prediction对于值,请使用包含模型预测的值的输出列的名称。 - 对于
actual值,请使用包含模型试图预测的实际值的“基本事实数据”列的名称。 - 针对
correlation_id值,请使用用于联接输出数据和地面真实数据的列名称。 - 在下方
emails,列出要用于通知的电子邮件地址。
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- 对于
运行以下命令以创建模型:
az ml schedule create -f ./model-performance-monitoring.yaml





设置生产数据的模型监视
还可以监视部署到Azure Machine Learning批处理终结点或部署在Azure Machine Learning外部的模型。 如果没有部署,但具有生产数据,则可以使用数据执行持续模型监视。 若要监视这些模型,你必须能够:
- 从生产环境中部署的模型收集生产推理数据。
- 将生产推理数据注册为Azure Machine Learning数据资产,并确保数据的持续更新。
- 提供自定义数据预处理组件,如果未使用 data collector 来收集数据,请将其注册为Azure Machine Learning组件。 如果没有此自定义数据预处理组件,Azure Machine Learning模型监视系统无法将数据处理成支持时间窗口的表格形式。
自定义预处理组件必须具有以下输入和输出签名:
| 输入或输出 | 签名名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|---|
| 输入 | data_window_start |
文本,字符串 | ISO8601格式的数据窗口开始时间 | 2023-05-01T04:31:57.012Z |
| 输入 | data_window_end |
文本,字符串 | ISO8601 格式的数据窗口结束时间 | 2023-05-01T04:31:57.012Z |
| 输入 | input_data |
uri_folder | 收集的生产推理数据,该数据注册为Azure Machine Learning数据资产 | azureml:myproduction_inference_data:1 |
| 输出 | preprocessed_data |
mltable | 与引用数据架构的子集匹配的表格数据资产 |
有关自定义数据预处理组件的示例,请参阅 azuremml 示例GitHub存储库中的 custom_preprocessing。
有关注册Azure Machine Learning组件的说明,请参阅工作区中的 Register 组件。
注册生产数据和预处理组件后,可以设置模型监视。
创建类似于以下文件的监视定义 YAML 文件。 使用此定义之前,请调整以下设置和任何其他设置以满足环境的需求:
- 对于
endpoint_deployment_id,请使用值的格式为azureml:<endpoint-name>:<deployment-name>。 - 对于
pre_processing_component,请使用值的格式为azureml:<component-name>:<component-version>。 指定确切的版本,例如1.0.0,而不是1。 - 对于每个
path,请使用格式为azureml:<data-asset-name>:<version>的值。 -
target_column对于值,请使用包含模型预测的值的输出列的名称。 - 在下方
emails,列出要用于通知的电子邮件地址。
- 对于
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1.0.0
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
alert_enabled: true
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
运行以下命令以创建模型。
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
使用自定义信号和指标设置模型监视
使用Azure Machine Learning模型监视时,可以定义自定义信号并实现所选的任何指标来监视模型。 可以将自定义信号注册为Azure Machine Learning组件。 当模型监视作业按其指定的计划运行时,它会计算自定义信号中定义的指标,就像它针对数据偏移、预测偏移和数据质量预生成信号所做的那样。
若要设置用于模型监视的自定义信号,必须先定义自定义信号并将其注册为Azure Machine Learning组件。 Azure Machine Learning组件必须具有以下输入和输出签名。
组件输入签名
组件输入数据帧应包含以下项:
- 包含
mltable预处理组件中已处理的数据的结构。 - 任何数量的文本,每个文本表示作为自定义信号组件的一部分实现的指标。 例如,如果实现
std_deviation指标,则需要为std_deviation_threshold提供输入。 通常,每个指标应有一个名称为<metric-name>_threshold的输入。
| 签名名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
production_data |
mltable | 与引用数据架构的子集匹配的表格数据资产 | |
std_deviation_threshold |
文本,字符串 | 实现的指标的相应阈值 | 2 |
组件输出签名
组件输出端口应具有以下签名:
| 签名名称 | 类型 | 描述 |
|---|---|---|
signal_metrics |
mltable | 包含计算指标的 mltable 结构。 有关此签名的架构,请参阅下一部分, signal_metrics架构。 |
signal_metrics 架构
组件输出数据帧应包含四列: group、 metric_name、 metric_value和 threshold_value。
| 签名名称 | 类型 | 描述 | 示例值 |
|---|---|---|---|
group |
文本,字符串 | 要应用于自定义指标的顶级逻辑分组 | 交易金额 |
metric_name |
文本,字符串 | 自定义指标的名称 | std_deviation |
metric_value |
数值 | 自定义指标的值 | 44,896.082 |
threshold_value |
数值 | 自定义指标的阈值 | 2 |
下表显示了计算指标的 std_deviation 自定义信号组件的示例输出:
| 组 | 度量值 | 指标名称 | 阈值 |
|---|---|---|---|
| 交易金额 | 44,896.082 | std_deviation | 2 |
| 本地时间 (LOCALHOUR) | 3.983 | std_deviation | 2 |
| 交易金额(美元) | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| 物理项目计数 | 5.509 | std_deviation | 2 |
若要查看自定义信号组件定义和指标计算代码的示例,请参阅 azureml 示例存储库中的 custom_signal。
有关注册Azure Machine Learning组件的说明,请参阅工作区中的 Register 组件。
在 Azure Machine Learning 中创建和注册自定义信号组件后,请执行以下步骤来设置模型监视:
在 YAML 文件中创建类似于以下定义的监视定义。 使用此定义之前,请调整以下设置和任何其他设置以满足环境的需求:
- 对于
component_id,请使用值的格式为azureml:<custom-signal-name>:1.0.0。 - 在输入数据部分的
path,请使用格式为azureml:<production-data-asset-name>:<version>的值。 - 对于
pre_processing_component:- 如果使用 数据收集器 收集数据,则可以省略该
pre_processing_component属性。 - 如果不使用数据收集器,并且想使用组件预处理生产数据,请使用
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>格式的值。
- 如果使用 数据收集器 收集数据,则可以省略该
- 在下方
emails,列出要用于通知的电子邮件地址。
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- 对于
运行以下命令以创建模型:
az ml schedule create -f ./custom-monitoring.yaml
解释监视结果
配置模型监视器并完成第一次运行后,可以在Azure Machine Learning studio中查看结果。
在工作室的 “管理”下,选择“ 监视”。 在“监视”页中,选择模型监视器的名称以查看其概述页。 本页显示监视模型、终结点和部署。 它还提供有关配置的信号的详细信息。 下图显示了包含数据偏移和数据质量信号的监视概述页。
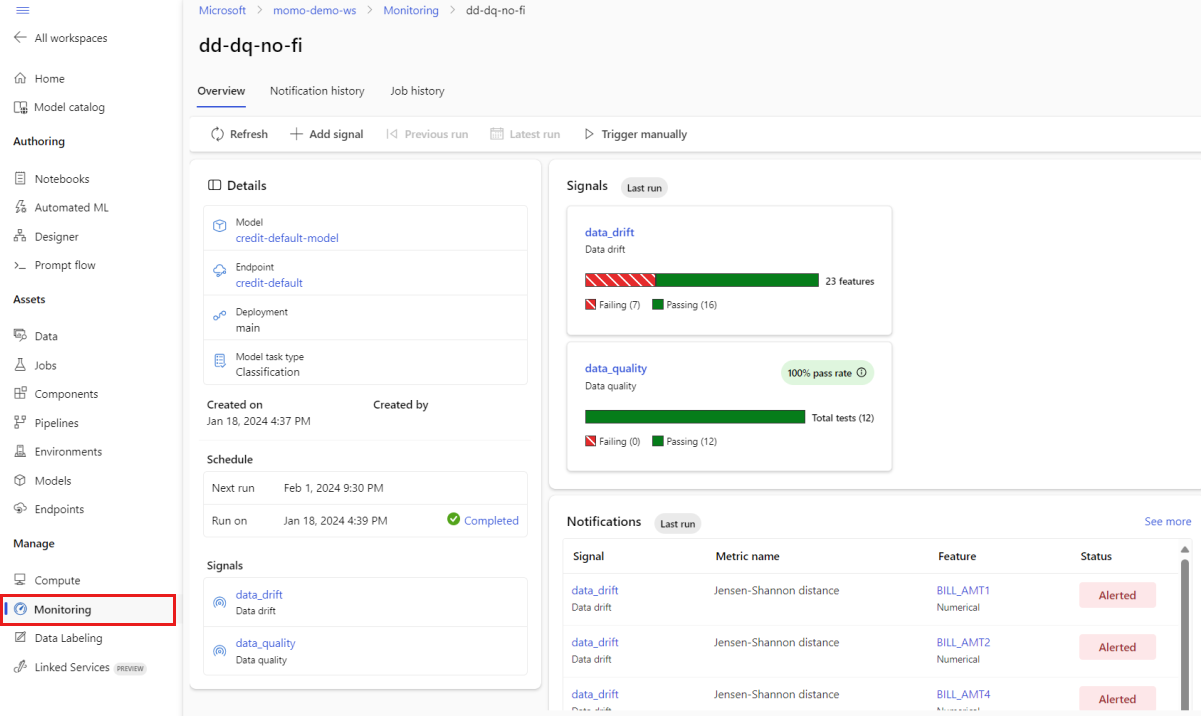
查看概述页的 “通知 ”部分。 在本部分中,可以看到每个信号的功能违反了其相应指标配置的阈值。
在 “信号 ”部分中,选择 data_drift 以查看有关数据偏移信号的详细信息。 在详细信息页上,可以看到监视配置包含的每个数值和分类功能的数据偏移指标值。 如果你的监视器有多个运行,则会看到每个特征的趋势线。
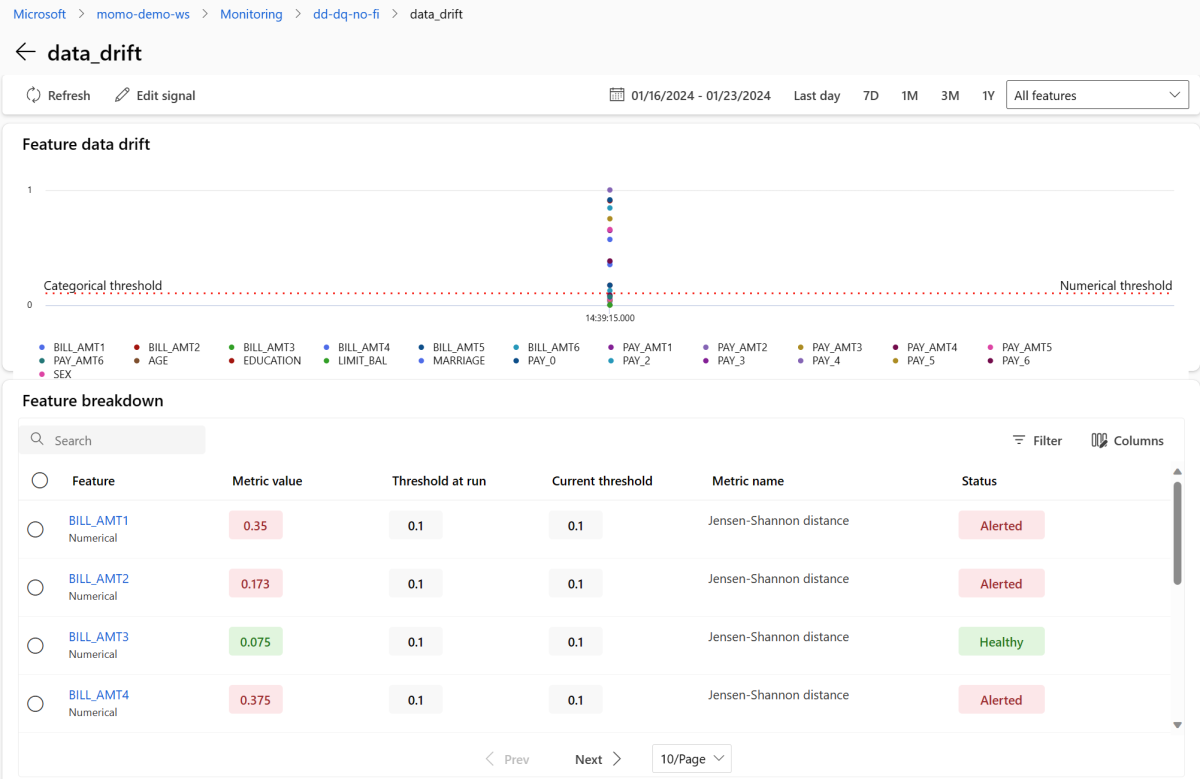
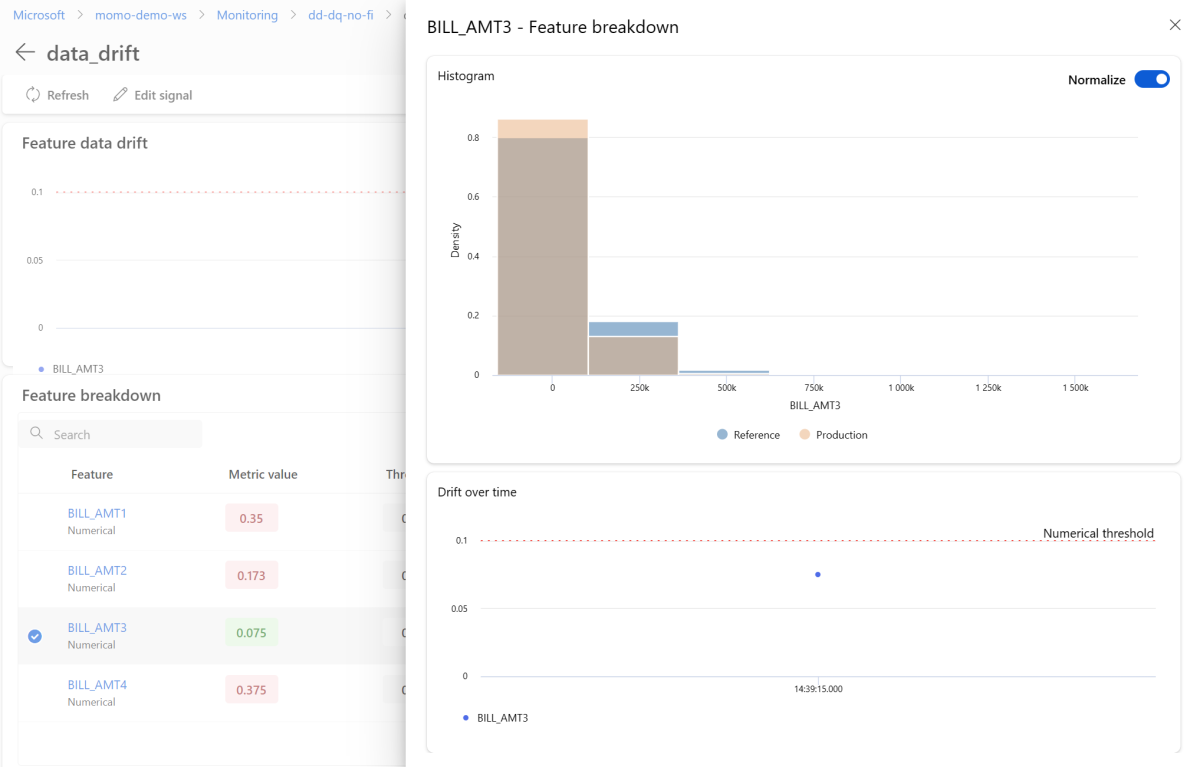
在详细信息页上,选择单个功能的名称。 打开一个详细视图,显示生产分布与参考分布的对比。 您还可以使用此视图跟踪该功能随时间推移的变化。
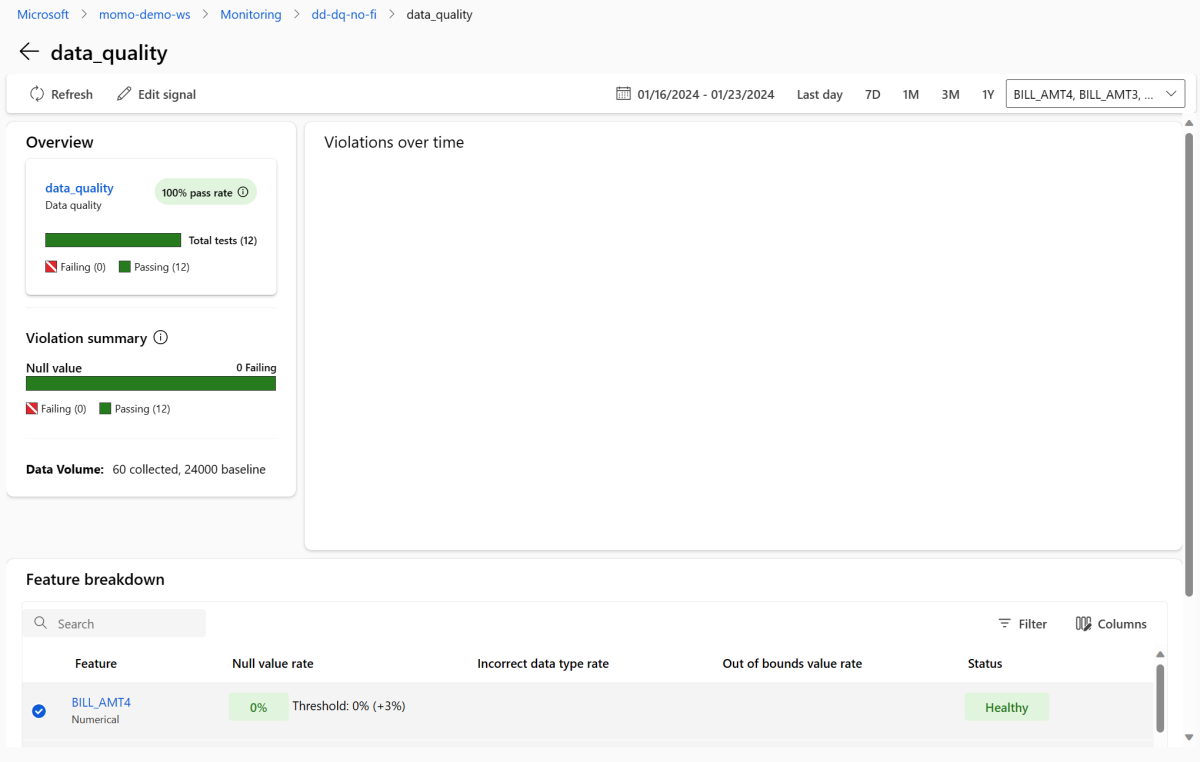
返回到监视概述页。 在 “信号 ”部分中,选择 data_quality 以查看有关此信号的详细信息。 在此页上,可以看到所监视的每个功能的 null 值速率、超出边界速率和数据类型错误率。




模型监视是一个持续的过程。 使用Azure Machine Learning模型监视时,可以配置多个监视信号,以便大致了解生产中模型的性能。
将Azure Machine Learning模型监视与事件网格集成
使用 Event Grid 时,可以配置Azure Machine Learning模型监视生成的事件来触发应用程序、进程和 CI/CD 工作流。 可以通过各种事件处理程序(例如Azure Event Hubs、Azure Functions和Azure Logic Apps)来使用事件。 当监视器检测到漂移时,可以通过编程方式执行操作,例如运行机器学习管道来重新训练和重新部署模型。
若要将Azure Machine Learning模型监视与事件网格集成,请执行以下步骤。
创建系统主题
如果没有用于监视的事件网格系统主题,请创建一个。 有关说明,请参阅 Azure 门户中创建、查看和管理事件网格系统主题。
创建事件订阅
在Azure门户中,转到Azure Machine Learning工作区。
选择事件,然后选择事件订阅。
在 “名称”旁边,输入事件订阅的名称,例如 MonitoringEvent。
在 “事件类型”下,仅选择 “运行状态已更改”。
警告
仅为事件类型选择 运行状态已更改。 不要选择检测到数据集偏移(适用于数据漂移 v1,而不是 Azure Machine Learning 模型监视)。
选择“ 筛选器 ”选项卡。在 “高级筛选器”下,选择“ 添加新筛选器”,然后输入以下值:
- 在“密钥”下,输入“data.RunTags.azureml_modelmonitor_threshold_breached”。
- 在“运算符”下,选择“字符串包含”。
- 在 值下,输入由于一个或多个特性违反指标阈值而导致失败。

使用此筛选器时,当Azure Machine Learning工作区中的任何监视器的运行状态发生更改时,将生成事件。 运行状态可以从已完成更改为失败或从失败更改为已完成。
若要在监视级别进行筛选,请再次选择“ 添加新筛选器 ”,然后输入以下值:
- 在“密钥”下,输入“data.RunTags.azureml_modelmonitor_threshold_breached”。
- 在“运算符”下,选择“字符串包含”。
- 在“值”下,输入要为其筛选事件的监视器信号的名称,例如 credit_card_fraud_monitor_data_drift。 输入的名称必须与监视信号的名称匹配。 在筛选中使用的任何信号都应采用包含监视器名称和信号说明的格式
<monitor-name>_<signal-description>的名称。
选择基本选项卡。配置您希望用作事件处理端点的终结点,例如事件中心。
选择“创建”以创建事件订阅。

查看事件
捕获事件后,可以在事件处理程序终结点页上查看它们:

还可以在 Azure Monitor Metrics 选项卡中查看事件:
