一个常见问题是“我应使用哪种机器学习算法?”所选的算法主要取决于数据科学方案的两个不同方面:
要将数据用于何种用途? 具体而言,从以往的数据中学习信息是要解答哪个业务问题?
数据科学方案的要求是什么? 具体而言,解决方案支持的准确度、训练时间、线性度、参数数目和特征数目是多少?
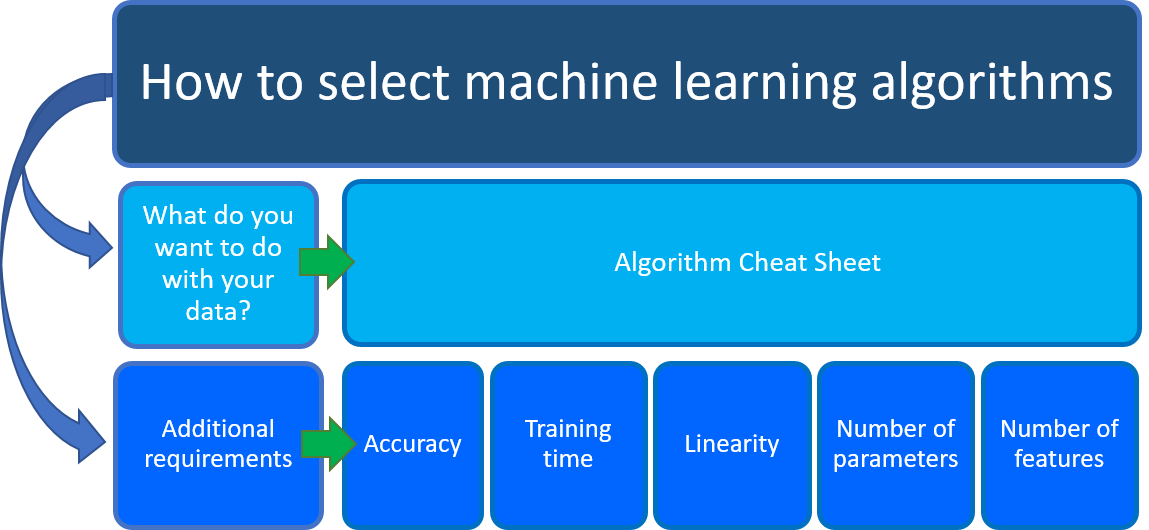
Azure 机器学习算法速查表可帮助你解决首要考虑因素:要将数据用于何种用途? 在机器学习算法速查表中,查找想要执行的任务,然后找到适用于预测分析解决方案的 Azure 机器学习设计器算法。
机器学习设计器提供全面的算法阵容,例如推荐系统、神经网络回归、多类神经网络和 K 平均值聚类。 每种算法旨在用于解决一种不同类型的机器学习问题。 请参阅机器学习设计器算法和组件参考,获取完整列表,以及有关每个算法的工作原理和如何调整参数以优化算法的文档。
备注
在此处下载该备忘单:机器学习算法备忘单(11 x 17 英寸)
除了遵循 Azure 机器学习算法速查表中的指导以外,在为解决方案选择机器学习算法时,还应该记住其他要求。 下面是要考虑的其他因素,例如准确度、训练时间、线性度、参数数目和特征数目。
备注
设计器支持两种类型的组件:经典预生成组件和自定义组件。 这两种类型的组件不兼容。
经典预生成组件主要为数据处理和传统的机器学习任务(如回归和分类)提供预生成组件。 此类型的组件将继续受支持,但不会增加任何新组件。
自定义组件允许你以组件的形式提供自己的代码。 它支持跨工作区共享,以及跨 Studio、CLI 和 SDK 接口进行无缝创作。
本文适用于经典预生成组件。
一些学习算法会对数据的结构或期望的结果做出特定假设。 如果找到符合需求的算法,它可以提供更有用的结果、更准确的预测或更快的定型时间。
下表总结了分类、回归和聚类系列算法的一些最重要的特征:
| 算法 | 准确性 | 定型时间 | 线性 | Parameters | 说明 |
|---|---|---|---|---|---|
| 分类系列 | |||||
| 双类逻辑回归 | 好 | 快速 | 是 | 4 | |
| 双类决策林 | 很好 | 中等 | 否 | 5 | 显示的评分时间变慢。 建议不要使用“一对多”多类分类,因为树预测累积中的梯级锁定会导致评分时间变慢 |
| 双类提升决策树 | 很好 | 中等 | 否 | 6 | 内存占用量大 |
| 双类神经网络 | 好 | 中等 | 否 | 8 | |
| 双类平均感知器 | 好 | 中等 | 是 | 4 | |
| 双类支持向量机 | 好 | 快速 | 是 | 5 | 适用于大型特征集 |
| 多类逻辑回归 | 好 | 快速 | 是 | 4 | |
| 多类决策林 | 很好 | 中等 | 否 | 5 | 显示的评分时间变慢 |
| 多类提升决策树 | 很好 | 中等 | 否 | 6 | 提高了准确性,同时存在小的覆盖面降低的风险 |
| 多类神经网络 | 好 | 中等 | 否 | 8 | |
| “一对多”多类分类 | - | - | - | - | 查看所选双类方法的属性 |
| 回归系列 | |||||
| 线性回归 | 好 | 快速 | 是 | 4 | |
| 决策林回归 | 很好 | 中等 | 否 | 5 | |
| 提升决策树回归 | 很好 | 中等 | 否 | 6 | 内存占用量大 |
| 神经网络回归 | 好 | 中等 | 否 | 8 | |
| 群集系列 | |||||
| K-Means 群集 | 很好 | 中等 | 是 | 8 | 聚类算法 |
知道要将数据用于何种用途后,需要确定解决方案的其他要求。
做出选择,并针对以下要求采取可能的折衷方案:
- 精确度
- 定型时间
- 线性
- 参数数目
- 特征数量
机器学习中的准确度根据真实结果数与案例总数之比来度量模型的有效性。 在机器学习设计器中,评估模型组件会计算一组符合行业标准的评估指标。 可使用此组件评估已训练模型的准确性。
获取最准确的答案可能并不总是必要的。 有时,近似值便已足够,具体取决于想要将其用于何处。 如果是这种情况,可以通过坚持使用更多的近似值方法大大减少处理时间。 此外,近似值方法在性质上趋向于避免过度拟合。
有三种方法可以使用评估模型组件:
- 针对训练数据生成评分以评估模型
- 在模型中生成评分,但将这些评分与保留的测试集中的评分进行比较
- 使用相同的数据集比较两个不同但相关的模型的评分
有关可用于评估机器学习模型准确性的指标和方法的完整列表,请参阅评估模型组件。
在监督式学习中,训练表示使用历史数据生成一个可以尽量减少误差的机器学习模型。 算法之间定型模型所需的分钟数或小时数差异较大。 训练时间通常与准确度密切相关:两者通常是相辅相成的。
此外,相较于其他算法,某些算法对数据点数目更敏感。 可以选择特定的算法,因为时间是有限的,尤其是数据集很大的情况下。
在机器学习设计器中,创建和使用机器学习模型通常是一个三步过程:
统计学和机器学习中的线性度表示数据集中的某个变量与常数之间存在线性关系。 例如,线性分类算法假设直线(或其更高维的模拟)可以将类分离。
许多机器学习算法都使用线性。 在 Azure 机器学习设计器中,这些算法包括:
线性回归算法假定数据趋势遵循一条直线。 对于某些问题而言,这种假设可以成立,但对于其他一些问题,它会降低准确度。 尽管它们有缺点,但线性算法往往被用作首要策略。 它们往往算法简单且可快速定型。
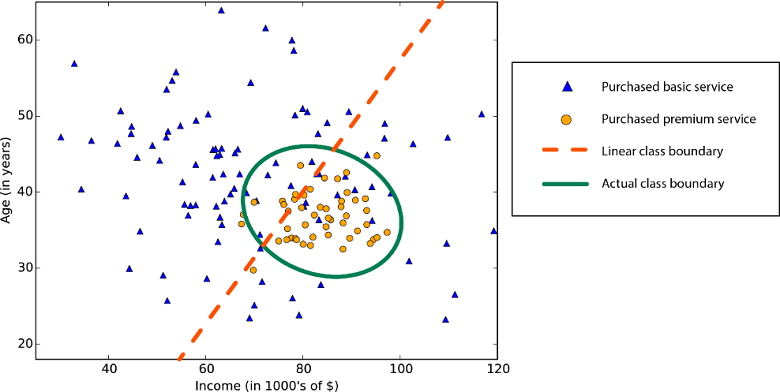
非线性类边界:依赖于线性分类算法会导致较低的准确性。
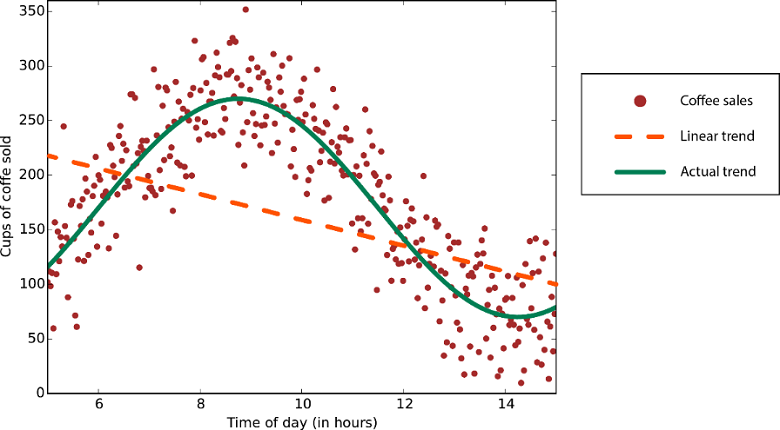
非线性趋势数据:使用线性回归方法会生成比必要的更大的错误。
参数是数据科学家在设置算法时要旋转的旋钮。 它们是影响算法行为的数字,例如错误容限、迭代次数,或算法行为方式的变体之间的选项。 算法的训练时间和准确度有时可能对获取正确设置相当敏感。 通常情况下,具有大量参数的算法需要进行最多的试用和错误,才能找到好的组合。
另外,机器学习设计器中还存在优化模型超参数组件:此组件的目标是确定机器学习模型的最佳超参数。 该组件使用不同的设置组合来生成和测试多个模型。 它将比较所有模型的指标,以获取设置组合。
虽然这是确保跨越参数空间的好方法,但定型模型所需的时间随参数数量呈指数增长。 优点是通常情况下,参数较多说明算法具有更大的灵活性。 只要你能提供正确的参数设置组合,它通常能达到很好的精度。
在机器学习中,特征是你要尝试分析的现象的可量化变量。 对于某些类型的数据,相较于数据点的数量,特征的数量可能非常大。 这通常出现在遗传学或文本数据的情况下。
大量的特征会导致某些学习算法不可用,从而使得训练时间特别长。 支持向量机特别适合存在大量特征的方案。 出于此原因,从信息检索到图文分类等许多应用场景中都使用了支持向量机。 支持向量机可用于分类和回归任务。
特征选择是指在指定了输出的情况下,将统计测试应用到输入的过程。 目标是确定哪些列能够更准确地预测输出。 机器学习设计器中基于筛选器的特征选择组件可提供多种特征选择算法供用户选择。 该组件包含“皮尔逊相关”和卡方值等关联方法。
还可以在 Azure 机器学习设计器中使用排列特征重要性组件,计算数据集的一组特征重要性分数。 然后,可以利用这些评分来帮助确定最适合在模型中使用的特征。
- 详细了解 Azure 机器学习设计器
- 有关 Azure 机器学习设计器中可用的所有机器学习算法的说明,请参阅机器学习设计器算法和组件引用
- 若要探索深度学习、机器学习与 AI 之间的关系,请参阅深度学习与机器学习