适用于: Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure CLI ml 扩展 v2 (当前版本)Python SDK azure-ai-ml v2 (当前版本)
Azure Machine Learning与Azure DevOps 管道集成,以自动化机器学习生命周期。 可以自动执行的操作包括:
- 部署Azure Machine Learning基础结构
- 数据准备(提取、转换和加载作)
- 通过按需横向扩展和纵向扩展训练机器学习模型
- 将机器学习模型部署为公共或专用 Web 服务
- 监视部署的机器学习模型(例如用于性能分析)
本文介绍如何使用Azure Machine Learning设置端到端 MLOps 管道,该管道运行线性回归来预测纽约市的出租车费用。 管道由组件组成,每个组件提供不同的功能。 可以将这些组件注册到工作区,对其进行版本控制,并使用各种输入和输出重复使用它们。 使用 推荐的 Azure MLOps 体系结构和 AzureMLOps (v2) 解决方案加速器,可以快速在 Azure Machine Learning 中设置 MLOps 项目。
提示
在实现任何解决方案之前,请查看 MLOps 的一些Azure 的推荐架构。 为机器学习项目选择最佳体系结构。
先决条件
- 一个 Azure 订阅。 如果没有Azure订阅,请在开始之前创建一个试用订阅。 尝试试用版订阅。
- Azure Machine Learning工作区。
- 在本地计算机上运行 Git。
- 如果在本地使用 Python SDK v2,Python 3.10 或更高版本。
- Azure DevOps中的组织化。
- 托管源存储库和管道的 Azure DevOps 项目。
- 如果您使用 Azure DevOps + Terraform 来启动基础架构,您需要 适用于 Azure DevOps 的 Terraform 扩展。
注意
需要 Git 2.27 或更高版本。 有关安装 Git 命令的详细信息,请参阅 https://git-scm.com/downloads 并选择操作系统。
重要
本文中的 CLI 命令是使用 Bash 进行测试的。 如果使用其他 shell,则可能会遇到错误。
使用 Azure 和 DevOps 设置身份验证
在使用 Azure Machine Learning 设置 MLOps 项目之前,需要为Azure DevOps设置身份验证。
创建服务主体
对于演示,请根据要处理的环境数量(开发、生产或两者),创建一两个服务主体。 可以使用以下方法之一创建这些主体:
转到 Azure App 注册。
选择“新建注册”。
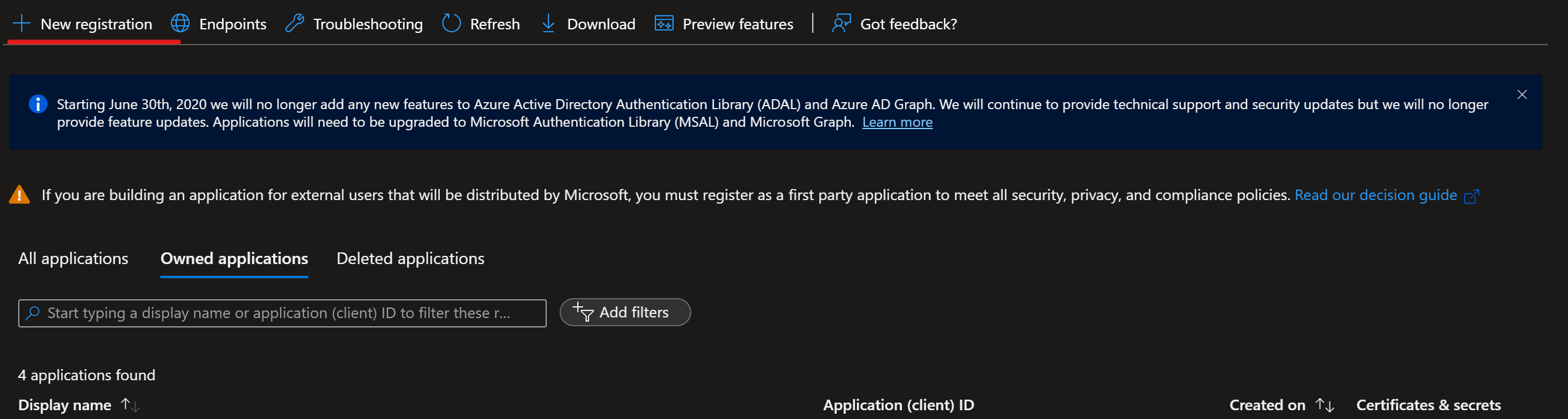
通过选择任何组织目录中的 帐户(任何 Microsoft Entra 目录 - 多租户) 创建服务主体。 将服务主体命名为 Azure-ARM-Dev-ProjectName。 创建后,创建名为 Azure-ARM-Prod-ProjectName 的新服务主体。 将 ProjectName 替换为项目的名称,以便可以唯一标识服务主体。
转到 证书和机密 ,并为每个服务主体添加新 客户端密码 。 单独存储值和机密。
若要为这些主体分配必要的权限,请选择相应的订阅并转到 IAM。 选择 “+添加 ”,然后选择“ 添加角色分配”。
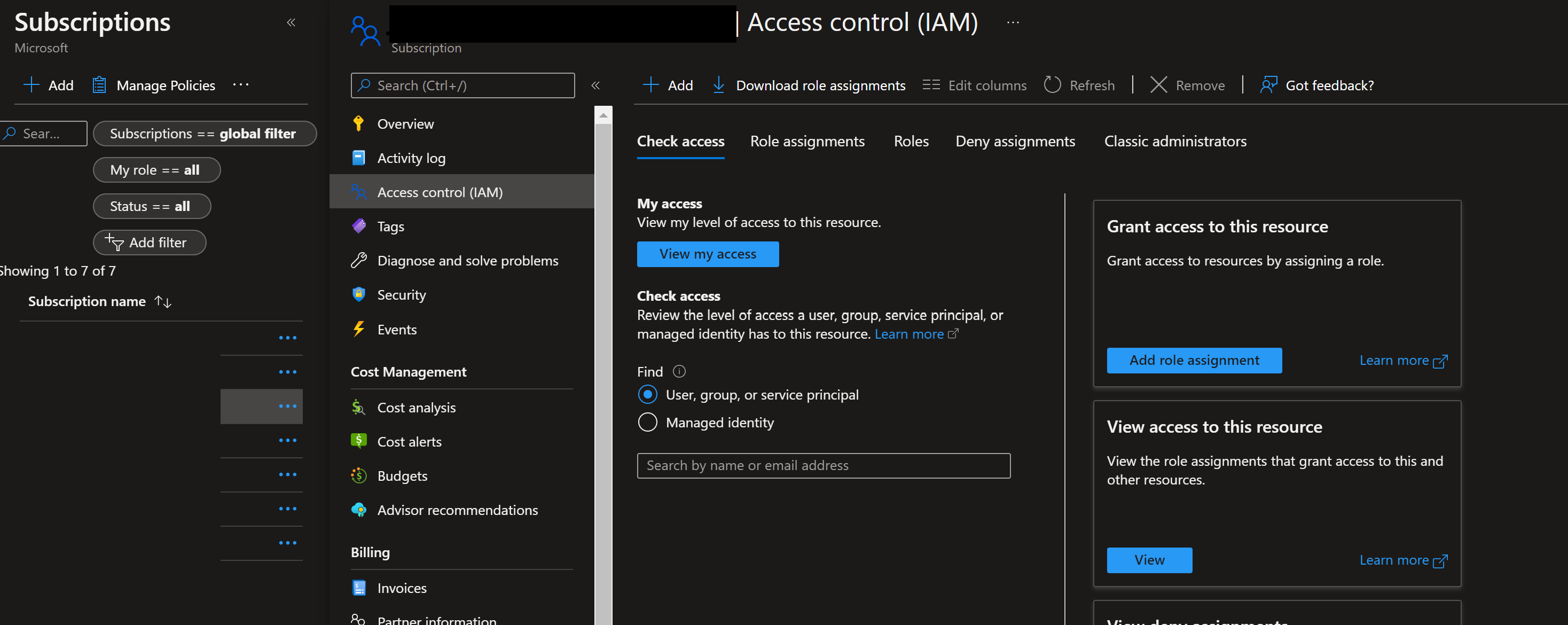
选择“参与者”,然后通过选择 “+ 选择成员”添加成员。 添加前面创建的成员 Azure-ARM-Dev-ProjectName。
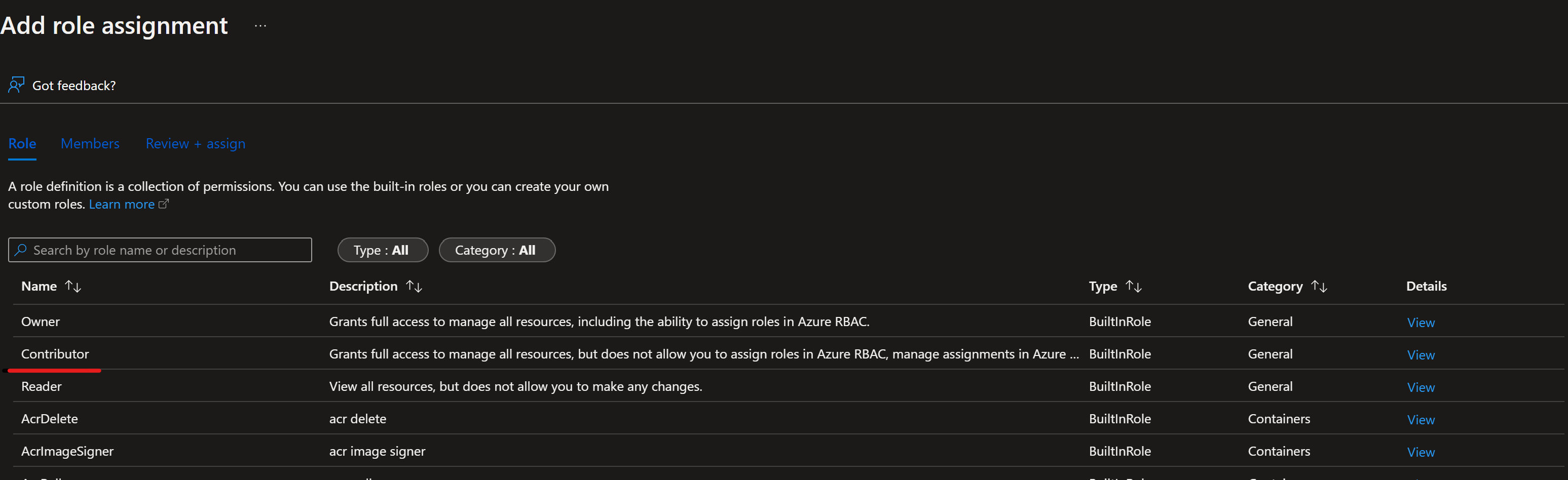
如果将开发环境和生产环境部署到同一订阅中,请重复此步骤。 否则,请更改为 prod 订阅并重复 Azure-ARM-Prod-ProjectName。 基本服务主体设置已完成。
设置Azure DevOps
转到 Azure DevOps。
选择 创建新项目。 为本教程命名项目
mlopsv2。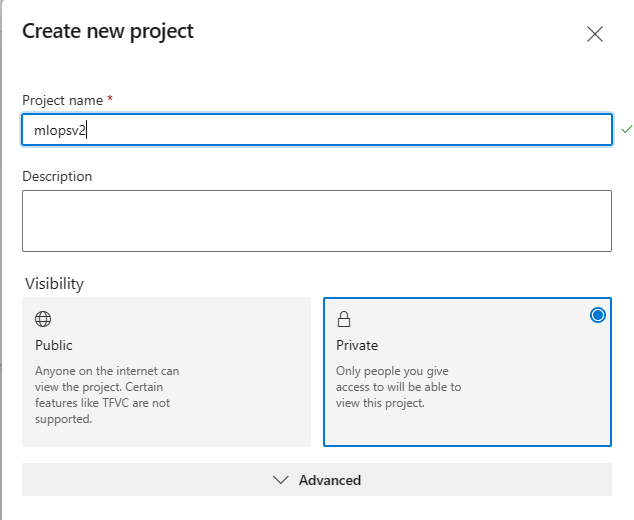 Screenshot of ADO Project.ADO项目的截图。
Screenshot of ADO Project.ADO项目的截图。在项目的项目设置(在项目页左下角)中,选择Service Connections。
选择“创建服务连接”。
选择 Azure Resource Manager,然后选择 Next。
注意
对于新项目,请选择应用注册或托管标识(手动),并使用工作负载身份联合凭据以提高安全性。 本文中的步骤使用了传统的 服务主体(手动) 方法以及需要手动轮换的秘钥。
选择 “服务主体”(手动),选择“ 下一步”,然后选择“范围级别 订阅”。
- 订阅名称 - 使用存储服务主体的订阅的名称。
- 订阅 ID - 使用在步骤 1 输入中使用的 作为订阅 ID
- 服务主体 ID - 使用步骤 1 输出中的 作为服务主体 ID
- 服务主体密钥 - 使用步骤 1 输出中的 作为服务主体密钥
- 租户 ID - 使用步骤 1 输出中的 作为租户 ID
将服务连接命名Azure-ARM-Prod。
选择 “授予对所有管道的访问权限”,然后选择“ 验证”和“保存”。
Azure DevOps设置成功完成。
使用 Azure DevOps 设置源存储库
打开在 Azure DevOps 中创建的项目。
进入Repos选项,然后选择 导入仓库。
在“克隆 URL”字段中输入
https://github.com/Azure/mlops-v2-ado-demo。 选择页面底部的 导入 。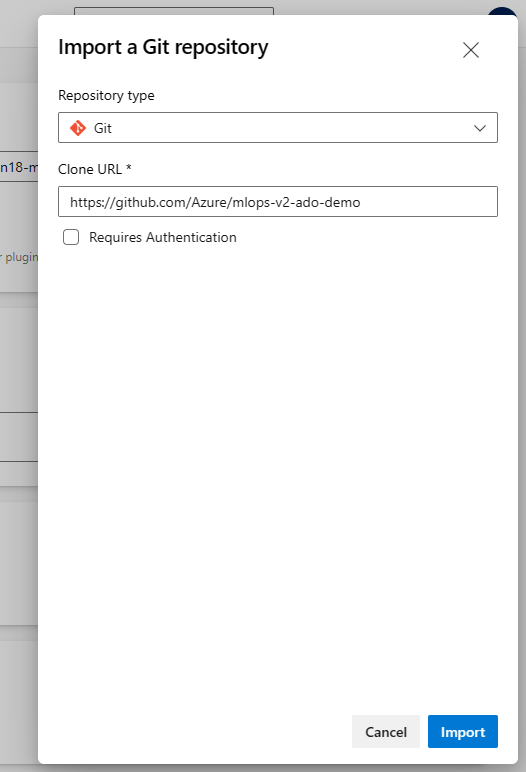
注意
示例仓库可能具有待定的依赖更新。 导入后,检查是否有 Dependabot 安全警报,并根据需要应用更新。 有关最新功能和修补程序,另请查看主要的 Azure MLOps (v2) 解决方案加速器存储库。
打开左侧导航窗格底部的 Project 设置。
在“Repos”部分下,选择“repositories。 选择在上一步中创建的存储库。 选择“安全”选项卡。
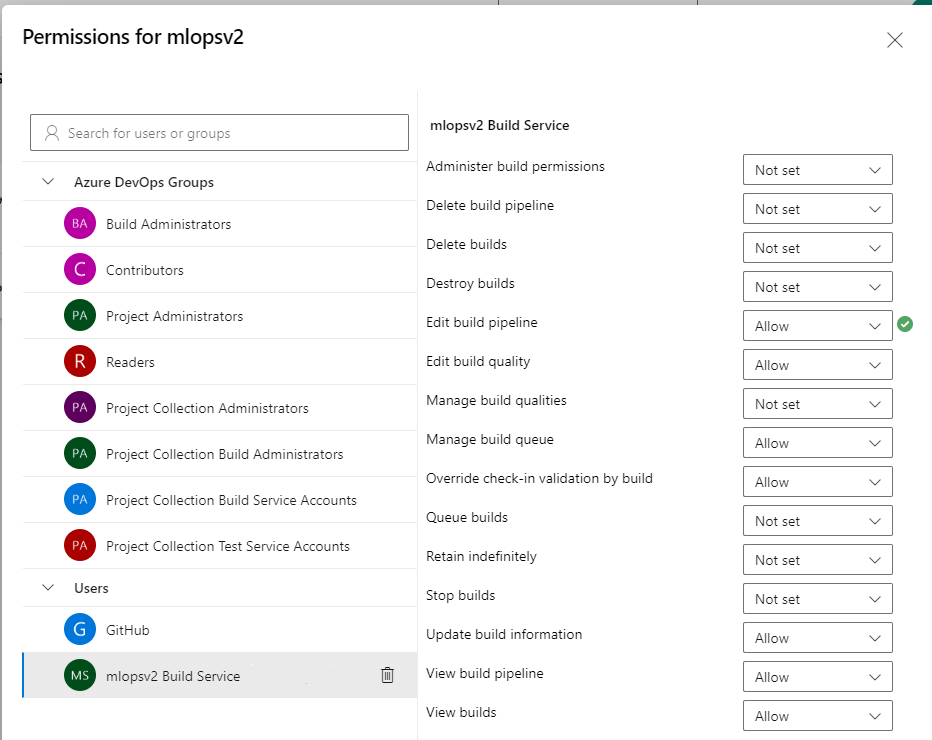
在“用户权限”部分下,选择“mlopsv2 生成服务”用户。 将参与权限更改为允许,将创建分支权限更改为允许。
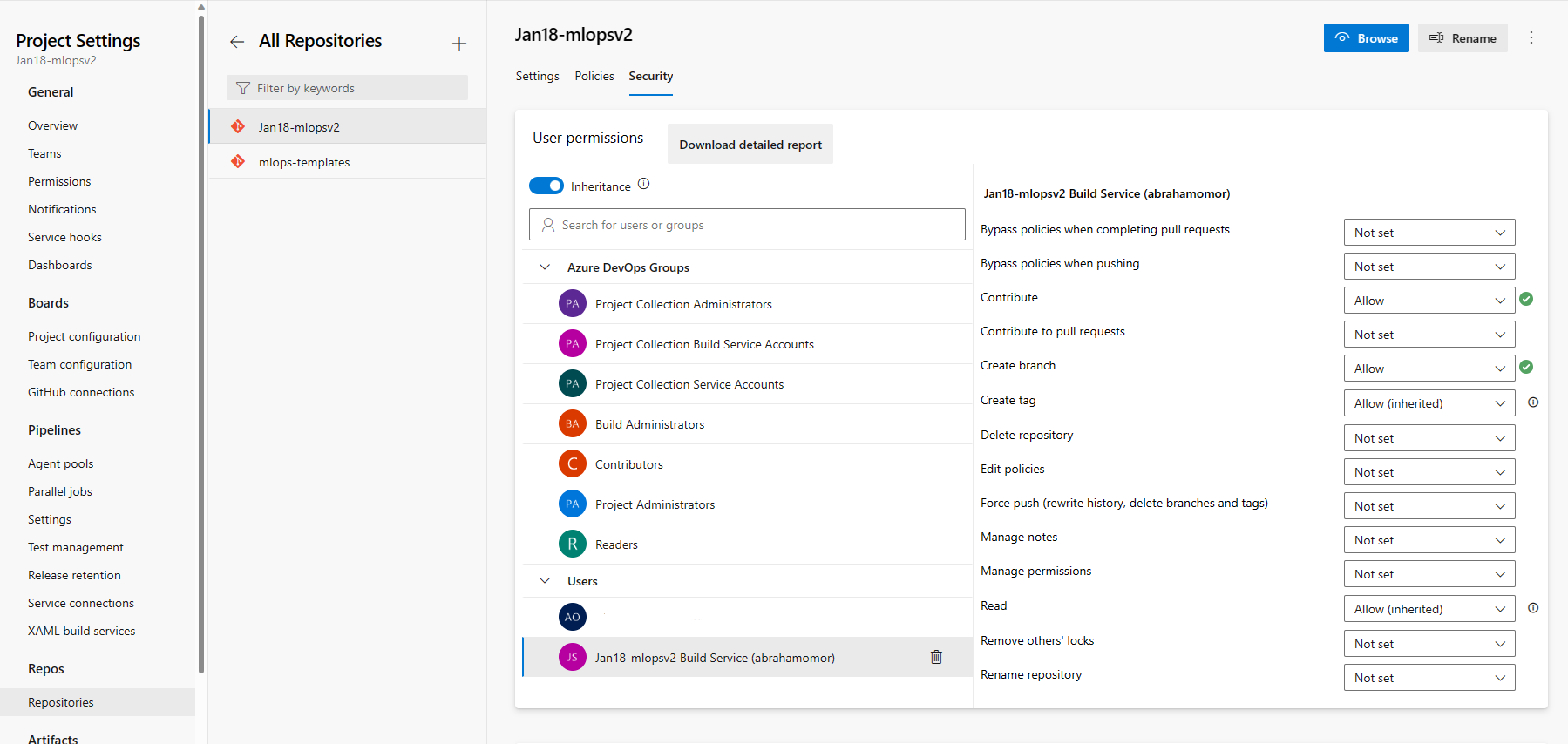
在左侧导航窗格中打开“管道”部分,然后选择“创建管道”按钮旁边的 3 个垂直点。 选择“ 管理安全性”。
在“用户”部分下,为项目选择“mlopsv2 生成服务”帐户。 将 “编辑生成管道” 权限更改为 “允许”。
注意
这完成了先决条件部分。 现在可以部署解决方案加速器。
通过 Azure DevOps 部署基础结构
此步骤将训练管道部署到在前面的步骤中创建的Azure Machine Learning工作区。
提示
在查看 MLOps v2 存储库并部署基础结构之前,请确保了解解决方案加速器的 体系结构模式 。 在示例中,使用 经典 ML 项目类型。
运行Azure基础设施管道
转到存储库
mlops-v2-ado-demo,然后选择 config-infra-prod.yml 文件。重要
请确保选择存储库 的主 分支。
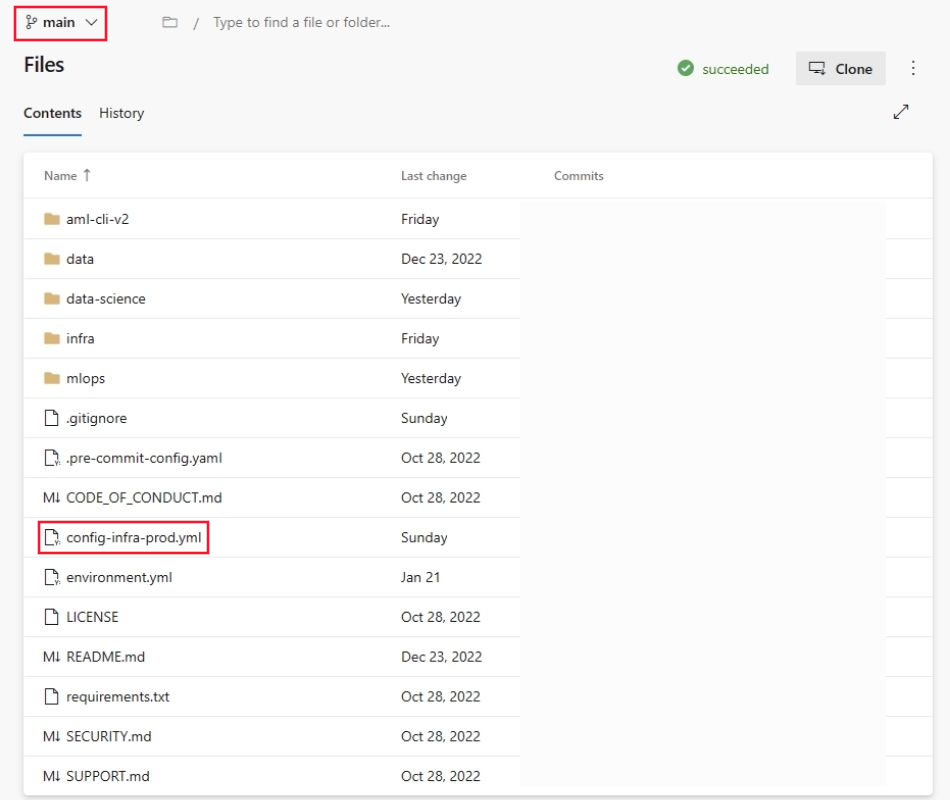
此配置文件使用命名空间和后缀值(项目的名称)以确保唯一性。 根据自己的需要更新配置中的以下部分。
namespace: [5 max random new letters] postfix: [4 max random new digits] location: chinaeast2注意
如果运行的是深度学习工作负载(如 CV 或 NLP),请确保 GPU 计算在部署区域中可用。
选择 “提交 ”以将代码推送到管道中并获取这些值。
转到 “管道” 部分。
选择“Create Pipeline”。
选择 Azure Repos Git。
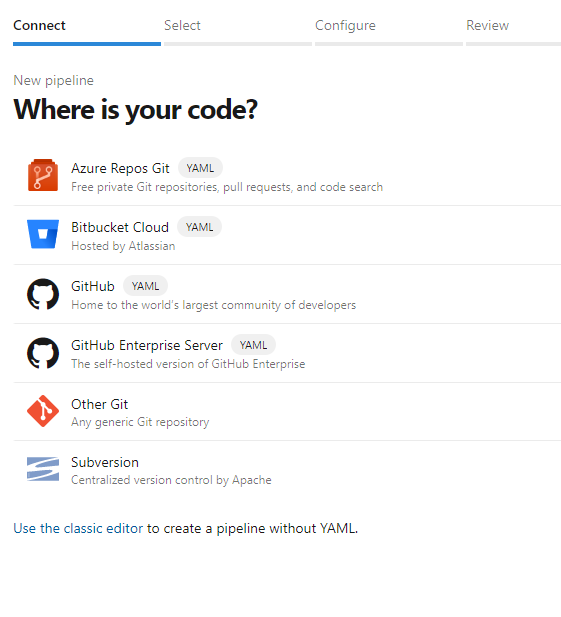
选择您从上一部分已克隆的存储库,
mlops-v2-ado-demo。选择 现有的 Azure Pipelines YAML 文件。
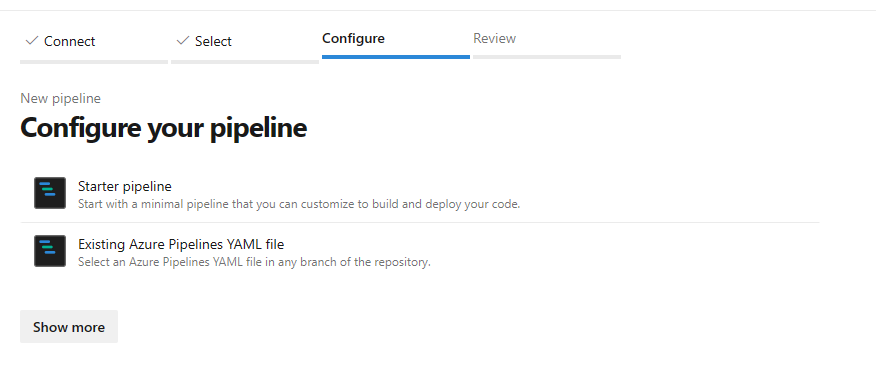
选择
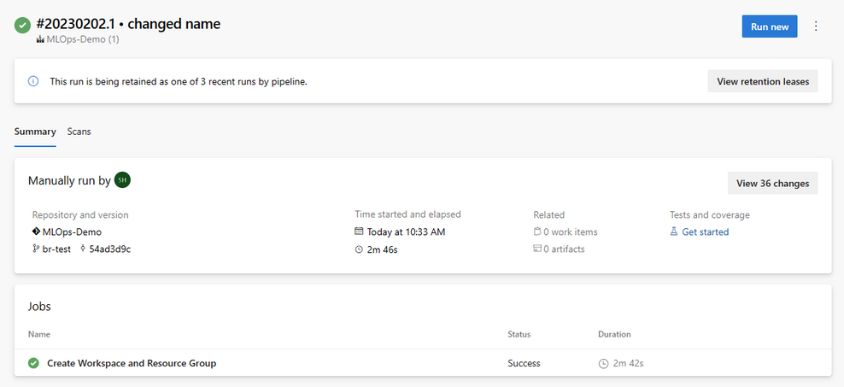
main分支,选择mlops/devops-pipelines/cli-ado-deploy-infra.yml,然后选择“继续”。运行管道。 完成需要几分钟时间。 流水线创建以下制品:
- 工作区的资源组,包括存储帐户、容器注册表、Application Insights、Key Vault和Azure Machine Learning工作区本身。
- 在工作区中,它还会创建计算群集。
现在,MLOps 项目的基础结构已部署。
注意
您可以忽略 无法移动并重用现有存储库到所需位置 的警告。
示例训练和部署方案
解决方案加速器包括示例端到端机器学习管道的代码和数据,该管道运行线性回归来预测纽约市的出租车费用。 管道由组件组成,每个组件提供不同的功能。 可以将这些组件注册到工作区,对其进行版本控制,并使用各种输入和输出重复使用它们。 Computer Vision和 NLP 方案的示例管道和工作流具有不同的步骤和部署步骤。
此训练管道包含以下步骤:
准备数据
- 此组件采用多个出租车数据集(黄色和绿色),并合并和筛选数据。 它准备训练、验证和评估数据集。
- 输入:./data/ 下的本地数据(多个 .csv 文件)
- 输出:单个准备数据集(.csv)和训练、验证和测试数据集。
训练模型
- 此组件使用训练集来训练线性回归器。
- 输入:训练数据集
- 输出:经过训练的模型(pickle 格式)
评估模型
- 此组件使用经过训练的模型来预测测试集的出租车费用。
- 输入:ML 模型和测试数据集
- 输出:模型性能和部署标志,指示是否进行部署。
- 此组件将模型的性能与新测试数据集上以前部署的所有模型进行比较。 它决定是否将模型部署到生产环境。 通过在Azure Machine Learning工作区中注册模型,将模型提升到生产环境。
注册模型
- 此组件根据测试集中预测的准确程度对模型进行评分。
- 输入:经过训练的模型和部署标记。
- 输出:Azure Machine Learning中已注册的模型。
部署模型训练管道
转到 ADO 管道。
选择“新建管道”。

选择 Azure Repos Git。
选择您从上一部分已克隆的存储库,
mlopsv2。选择 现有的 Azure Pipelines YAML 文件。
选择
main为分支,然后选择/mlops/devops-pipelines/deploy-model-training-pipeline.yml。 选择继续。保存并运行 管道。
注意
此时,将配置基础结构并部署 MLOps 体系结构的原型循环。 你已准备好将已训练的模型迁移到生产环境。
部署已训练的模型
此方案包括用于部署已训练模型的两种方法的预生成工作流:批量评分或将模型部署到终结点进行实时评分。 运行这两个工作流,以测试Azure Machine Learning工作区中模型的性能。 在此示例中,使用实时评分。
部署 ML 模型终结点
转到 ADO 管道。
选择“新建管道”。
选择 Azure Repos Git。
选择您从上一部分已克隆的存储库,
mlopsv2。选择 现有的 Azure Pipelines YAML 文件。
选择
作为分支,选择“联机托管终结点” ,然后选择“继续” 。 联机终结点名称必须是唯一的,因此请将
taxi-online-$(namespace)$(postfix)$(environment)更改为另一个唯一名称,然后选择“运行”。 如果默认值未失败,则无需更改其。
重要
如果运行因现有联机终结点名称而失败,请按照前面所述重新创建管道,并将 [your endpoint-name] 更改为 [your endpoint-name (random number)]
运行完成后,会看到类似于下图的输出:
若要测试此部署,请转到 Azure Machine Learning 工作区中的 Endpoints 选项卡,选择终结点,然后选择 Test 选项卡。可以使用位于
/data/taxi-request.json克隆存储库中的示例输入数据来测试终结点。
清理资源
- 如果不打算继续使用管道,请删除Azure DevOps项目。
- 在Azure门户中,删除资源组和Azure Machine Learning实例。
后续步骤
- 安装和设置 Python SDK v2
- install 并设置 Python CLI v2
- Azure MLOps (v2) 解决方案加速器GitHub
- 详细了解 Azure Pipelines 与 Azure 机器学习
- 了解有关 GitHub Actions 与 Azure 机器学习 的详细信息