Azure Machine Learning注册表使你能够跨组织内的工作区进行协作。 使用注册表可以共享模型、组件和环境。
对于以下两种方案,你希望在多个工作区中使用同一组模型、组件和环境:
- 跨工作区 MLOps:你正在 工作区中训练模型,并需要将其部署到
dev和test工作区。 在这种情况下,你希望在test或prod工作区中部署模型的终结点与dev工作区中用于训练模型的训练作业、指标、代码、数据和环境之间建立端到端世系。 - 在不同团队之间共享和重用模型和流程:共享和重用可提高协作和工作效率。 在此方案中,可能需要将已训练的模型以及用于对其进行训练的相关组件和环境发布到中心目录。 从那里,其他团队的同事可以在他们自己的试验中搜索和重用你共享的资产。
在这篇文章中,你将学会如何:
- 在注册表中创建环境和组件。
- 使用注册表中的组件在工作区中提交模型训练作业。
- 在注册表中注册已训练的模型。
- 将注册表中的模型部署到工作区中的联机终结点,然后提交推理请求。
先决条件
在按照本文中的步骤操作之前,请确保满足以下先决条件:
- 一个 Azure 订阅。 如果没有Azure订阅,请在开始之前创建一个试用订阅。 尝试试用版订阅。
用于共享模型、组件和环境的Azure Machine Learning注册表。 若要创建注册表,请参阅了解如何创建注册表。
Azure Machine Learning工作区。 如果您尚未拥有,请参照快速入门:创建工作区资源一文中的步骤来创建一个。
重要
在其中创建工作区的Azure区域(位置)必须位于Azure Machine Learning注册表支持的区域列表中
Azure CLI 和
ml扩展或 Azure 机器学习 Python SDK v2:若要安装Azure CLI和扩展,请参阅 Install、设置和使用 CLI (v2)。
重要
本文中的 CLI 示例假定你使用的是 Bash(或兼容的)shell。 例如,从 Linux 系统或 Windows Subsystem for Linux。
这些示例还假定你为Azure CLI配置了默认值,这样就不必为订阅、工作区、资源组或位置指定参数。 若要配置默认设置,请使用以下命令。 将以下参数替换为你的配置值:
- 将
<subscription>替换为Azure订阅 ID。 - 将
<workspace>替换为Azure Machine Learning工作区名称。 - 将
<resource-group>替换为包含工作区的Azure资源组。 - 将
<location>替换为包含工作区的Azure区域。
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>可以使用
az configure -l命令查看当前的默认值。- 将
克隆示例存储库
本文中的代码示例基于 examples 存储库中的 nyc_taxi_data_regression 示例。 若要在开发环境中使用这些文件,请使用以下命令克隆存储库并将目录更改为示例:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
对于 CLI 示例,请在 cli/jobs/pipelines-with-components/nyc_taxi_data_regression 的本地克隆中将目录更改为 。
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
创建 SDK 连接
提示
仅当使用 Python SDK 时,才需要此步骤。
创建与Azure Machine Learning工作区和注册表的客户端连接:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
在注册表中创建环境
环境定义 Docker 容器以及运行训练作业或部署模型所需的 Python 依赖项。 有关环境的详细信息,请参阅以下文章:
提示
CLI 命令 az ml environment create 还可用于在工作区或注册表中创建环境。 结合 --workspace-name 命令运行该命令会在工作区中创建环境,而结合 --registry-name 运行该命令会在注册表中创建环境。
我们将创建一个环境,该环境使用 python:3.10 docker 映像,并安装使用 SciKit Learn 框架运行训练作业所需的Python包。 如果克隆了示例存储库,并且位于 cli/jobs/pipelines-with-components/nyc_taxi_data_regression 文件夹中,则应能够看到引用 docker 文件env_train.yml的环境定义文件env_train/Dockerfile。
env_train.yml 的内容如下所示:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1-<VERSION>
description: Scikit Learn environment
build:
path: ./env_train
如下所示使用 az ml environment create 创建环境
az ml environment create --file env_train.yml --registry-name <registry-name>
如果出现错误,指出注册表中已存在具有此名称和版本的环境,你可以编辑 version 中的 env_train.yml 字段,或者在 CLI 中指定不同的版本以便替代 env_train.yml 中的版本值。
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
提示
version=$(date +%s) 只能在 Linux 中运行。 如果此作不起作用,请替换为 $version 随机数。
记下 name 命令输出中环境的 version 和 az ml environment create,并将其与 az ml environment show 命令结合使用,如下所示。 在下一部分中创建注册表组件时,你需要用到 name 和 version。
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
提示
如果你使用了不同的环境名称或版本,请相应地替换 --name 和 --version 参数。
还可以使用 az ml environment list --registry-name <registry-name> 列出注册表中的所有环境。
可以浏览Azure Machine Learning studio中的所有环境。 请务必导航到全局 UI 并查看注册表条目。

注释
注册表资源的系统分配托管标识对与该注册表关联的Azure Container Registry (ACR) 实例具有 AcrPull 权限。 当工作区计算需要拉取环境映像时,AzureML 注册表会创建并返回一个 ACR 令牌,该令牌具有适当的范围映射,允许工作区计算提取映像。 工作区和计算托管标识都无权直接访问注册表的 ACR。
在注册表中创建组件
组件是Azure 机器学习中机器学习管道的可重用模块。 可以将单个管道步骤的代码、命令、环境、输入接口和输出接口打包到组件中。 然后,可以在多个pipelines中重复使用组件,而无需担心每次编写其他管道时移植依赖项和代码。
在工作区中创建组件后,可以在该工作区内的任何管道作业中使用该组件。 在注册表中创建组件后,可以在组织内的任何工作区的任何管道中使用该组件。 在注册表中创建组件可以十分方便地生成模块化的可重用实用工具或共享的训练任务,供组织中的不同团队在试验中使用。
有关组件的详细信息,请参阅以下文章:
请确保您位于文件夹 cli/jobs/pipelines-with-components/nyc_taxi_data_regression。 可以找到打包 Scikit Learn 训练脚本train.yml的组件定义文件train_src/train.py。 environment 中编辑 train.yml 字段,以使用在上一步中创建的 Scikit Learn 环境,或保留预设的环境。 组件定义文件 train.yml 类似于以下示例:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
# </component>
如果要从上一步使用自己的环境,而不是特选环境,请将 environment 字段更新为 azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1。
az ml component create运行以下命令以创建组件,如下所示。
az ml component create --file train.yml --registry-name <registry-name>
提示
同一 CLI 命令 az ml component create 可用于在工作区或注册表中创建组件。 结合 --workspace-name 命令运行该命令会在工作区中创建组件,而结合 --registry-name 运行该命令会在注册表中创建组件。
如果你不想要编辑 train.yml,可以在 CLI 中替代环境名称,如下所示:
az ml component create --file train.yml --registry-name <registry-name> --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
提示
如果出现错误提示注册表中已存在该组件名称,可以在 train.yml 中编辑版本,或者在 CLI 上使用随机版本来覆盖现有版本。
记下 name 命令输出中组件的 version 和 az ml component create,并将其与 az ml component show 命令结合使用,如下所示。 在工作区中创建和提交训练作业的下一部分时,你需要用到 name 和 version。
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
还可以使用 az ml component list --registry-name <registry-name> 列出注册表中的所有组件。
可以浏览Azure Machine Learning studio中的所有组件。 请务必导航到全局 UI 并查看注册表条目。

使用注册表中的组件在工作区中运行管道作业
在运行使用注册表中的组件的管道作业时,计算资源和训练数据位于工作区的本地。 有关运行作业的详细信息,请参阅以下文章:
我们使用在上一部分创建的 Scikit Learn 训练组件运行管道作业来训练模型。 请检查您是否在正确的文件夹cli/jobs/pipelines-with-components/nyc_taxi_data_regression中。 训练数据集位于 data_transformed 文件夹中。 编辑 component 文件中 train_job 节下的 single-job-pipeline.yml 节,以引用在上一部分创建的训练组件。 生成的 single-job-pipeline.yml 如下所示:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
一个关键方面是,此管道将在一个工作区中使用来自另一个特定工作区外的组件来运行。 该组件位于可与组织中的任何工作区一起使用的注册表中。 可以在您有访问权限的任何工作区中运行此训练作业,而不必担心如何让训练代码和环境在该工作区中可用。
警告
- 在运行管道作业之前,请确认运行作业的工作区位于创建组件的注册表支持的Azure区域中。
- 确认该工作区包含名为
cpu-cluster的计算群集,或使用你的计算名称编辑compute下的jobs.train_job.compute字段。
使用 az ml job create 命令运行管道作业。
az ml job create --file single-job-pipeline.yml
提示
如果没有按照先决条件部分中的说明配置默认工作区和资源组,则需要指定--workspace-name和--resource-group参数,以使az ml job create正常工作。
或者,可以不编辑 single-job-pipeline.yml,而是在 CLI 中替代 train_job 使用的组件名称。
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
由于训练作业中使用的组件是通过注册表共享的,因此你可以将作业提交到组织中access的任何工作区,即使在不同的订阅中也是如此。 例如,如果你有 dev-workspace、test-workspace 和 prod-workspace,在这三个工作区中运行训练作业就像运行三个 az ml job create 命令一样简单。
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
在Azure Machine Learning studio中,选择作业输出中的终结点链接以查看作业。 在此处,可以分析训练指标,验证作业是否使用注册表中的组件和环境,并查看已训练的模型。 记下输出中的作业name,或在 Azure Machine Learning Studio 的作业概述中找到相同的信息。 在接下来的“在模型注册表中创建模型”部分中,您将需要这些信息来下载训练好的模型。

在注册表中创建模型
你将了解如何在本部分中的注册表中创建模型。 查看 管理模型,详细了解 Azure Machine Learning 中的模型管理。 我们了解了在注册表中创建模型的两种不同的方法。 第一种是来自本地文件。 第二种方法是将工作区中注册的模型复制到注册表。
在这两个选项中,均使用 MLflow 格式创建模型,这有助于部署 此模型进行推理,而无需编写任何推理代码。
通过本地文件在注册表中创建模型
下载模型。可以在 train_job 的输出中找到该模型(请将 <job-name> 替换为上一部分所述的作业中的名称)。 模型及 MLflow 元数据文件应该可在 ./artifacts/model/ 中获取。
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
提示
如果没有按照先决条件部分中的说明配置默认工作区和资源组,则需要指定--workspace-name和--resource-group参数,以使az ml model create正常工作。
警告
az ml job list 的输出将传递给 sed。 这仅适用于 Linux shell。 如果使用的是 Windows,请运行 az ml job list --parent-job-name <job-name> --query [0].name ,并去掉训练作业名称中看到的任何引号。
如果无法下载模型,可以在 cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/ 文件夹中找到在上一部分的训练作业中训练的示例 MLflow 模型。
在注册表中创建模型:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
提示
- 如果有错误指出模型名称和版本已存在,请为
version参数使用随机数。 - 同一 CLI 命令
az ml model create可用于在工作区或注册表中创建模型。 结合--workspace-name命令运行该命令会在工作区中创建模型,而结合--registry-name运行该命令会在注册表中创建模型。
将模型从工作区共享到注册表
在此工作流中,首先在工作区中创建模型,然后将其共享到注册表。 如果你希望在共享模型之前先在工作区中对其进行测试,此工作流非常有用。 例如,将其部署到终结点,并尝试使用某些测试数据进行推理,然后在一切看起来正常的情况下将模型复制到注册表。 当你使用不同的技术、框架或参数开发一系列模型,并希望仅将其中一个模型作为生产候选项提升到注册表时,此工作流也可能很有用。
确保使用上一部分所述管道作业的名称,并在命令中替换该名称以提取训练作业名称。 然后,将训练任务输出的模型注册到工作区。 请注意,--path 参数如何使用 train_job 语法引用 azureml://jobs/$train_job_name/outputs/artifacts/paths/model 输出。
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
提示
- 如果收到有关模型名称和版本已存在的错误,请为
version参数使用随机数。 - 如果尚未按照先决条件部分的说明配置默认工作区和资源组,则需要指定
--workspace-name和--resource-group参数,以便az ml model create正常运行。
记下模型名称和版本。 可以通过在工作室 UI 中浏览模型或使用 az ml model show --name nyc-taxi-model --version $model_version 命令来验证该模型是否已注册到工作区。
接下来,将模型从工作区共享到注册表。
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
提示
- 如果在
az ml model create命令中更改了模型名称和版本,请确保使用正确的名称和版本。 -
--share-with-name和--share-with-version参数是必需的。 他们确定模型在注册表中的名称和版本。
记下 name 命令输出中模型的 version 和 az ml model create,并将其与 az ml model show 命令结合使用,如下所示。 在下一部分中将模型部署到在线端点用于推理时,需要 name 和 version。
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
还可以使用 az ml model list --registry-name <registry-name> 列出注册表中的所有模型或浏览Azure Machine Learning studio UI 中的所有组件。 请确保导航到全局用户界面并查看“注册表枢纽”。
以下屏幕截图显示了Azure Machine Learning studio注册表中的模型。 如果你从作业输出创建了一个模型,然后将该模型从工作区复制到了注册表,你将看到该模型带有一个指向训练了该模型的作业的链接。 可以使用该链接导航到训练作业,以查看用于训练模型的代码、环境和数据。
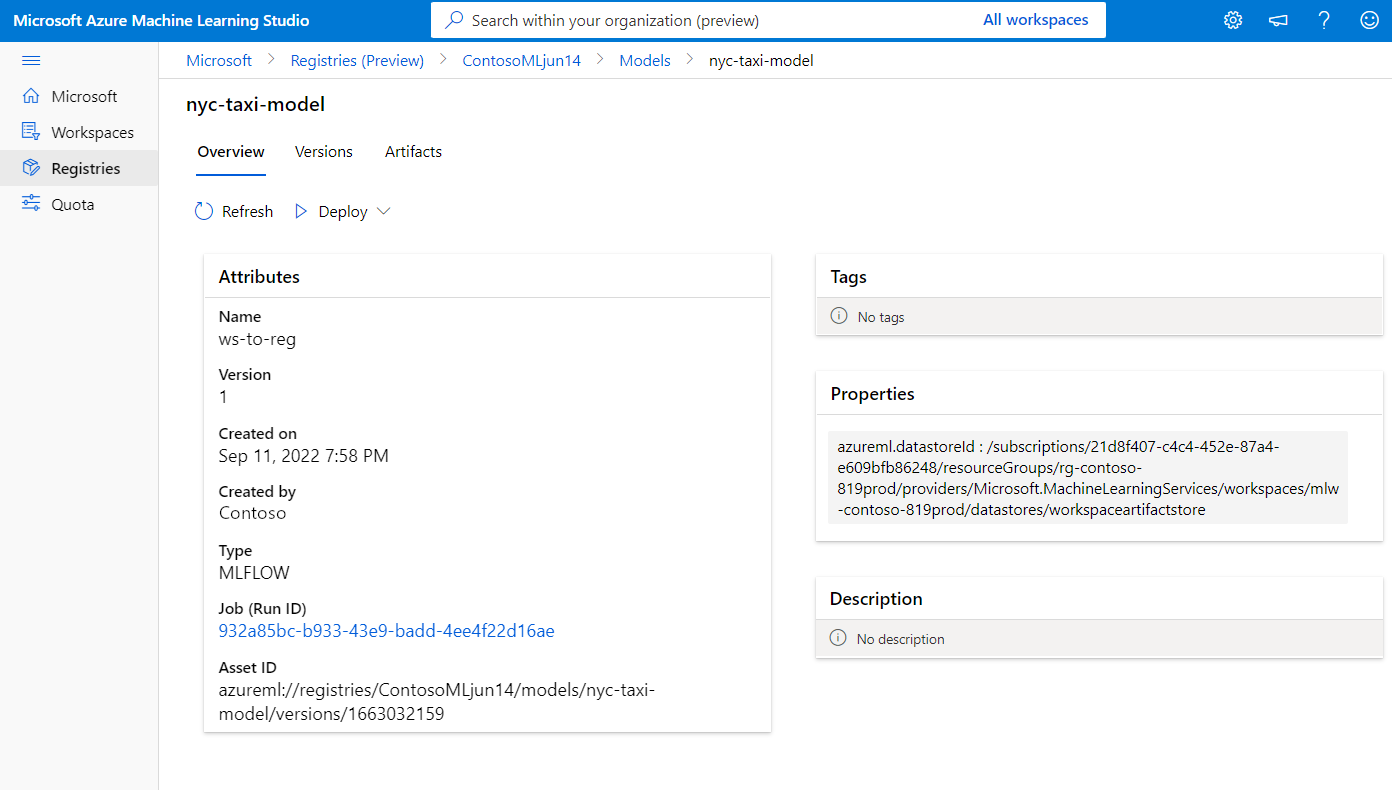
将模型从注册表部署到工作区中的联机终结点
最后一部分介绍如何将模型从注册表部署到工作区中的联机终结点。 您可以选择将您有权限访问的任何工作区部署到您的组织中,前提是该工作区的位置是注册表支持的位置之一。 如果你在 dev 工作区中训练了某个模型,现在需要将该模型部署到 test 或 prod 工作区,同时保留用于训练该模型的代码、环境和数据的相关世系信息,则此功能很有帮助。
联机终结点允许通过 REST API 部署模型和提交推理请求。 有关详细信息,请参阅 如何使用联机终结点部署和评分machine learning模型。
提示
此示例使用基于密钥的身份验证来简单起见。 对于生产部署,Microsoft建议 Microsoft Entra使用基于令牌的身份验证(aad_token),通过基于标识的访问控制提供增强的安全性。 有关详细信息,请参阅对联机终结点的客户端进行身份验证。
创建联机端点。
az ml online-endpoint create --name reg-ep-1234
更新 model: 文件夹中提供的 deploy.yml 行cli/jobs/pipelines-with-components/nyc_taxi_data_regression,以引用上一步中的模型名称和版本。 创建到联机终结点的联机部署。 下面显示了 deploy.yml 以供参考。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS3_v2
instance_count: 1
创建在线部署。 部署需要数分钟才能完成。
az ml online-deployment create --file deploy.yml --all-traffic
提取评分 URI 并提交示例评分请求。 评分请求的示例数据在 scoring-data.json 文件夹中的 cli/jobs/pipelines-with-components/nyc_taxi_data_regression 中可用。
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
重要
- 对于使用用户分配的标识创建的终结点,需要手动分配角色。 标识需要在订阅级别具有
ACRPull和Storage Blob Data Reader角色。
提示
-
curl命令只能在 Linux 上运行。 - 如果你尚未按照先决条件部分中所述配置默认工作区和资源组,则需要指定
--workspace-name和--resource-group参数,这样才能正常运行az ml online-endpoint和az ml online-deployment命令。
清理资源
如果你今后不再使用该部署,应将其删除以降低成本。 以下示例删除终结点以及所有基础部署:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait