适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
本文介绍如何使用 SweepJob 类通过 Azure 机器学习 SDK v2 和 CLI v2 自动执行高效的超参数优化。
- 定义参数搜索空间
- 选择采样算法
- 设置优化目标
- 配置提前终止策略
- 设置清扫作业限制
- 提交实验
- 可视化训练作业
- 选择最佳配置
什么是超参数优化?
超参数 是控制模型训练的可调整设置。 例如,对于神经网络,可以选择隐藏层数和每个层的节点数。 模型性能在很大程度上取决于这些值。
超参数优化 (或 超参数优化)是查找产生最佳性能的超参数配置的过程。 此过程通常计算成本高昂且手动。
Azure 机器学习使你能够自动执行超参数优化,并且并行运行试验以有效地优化超参数。
定义搜索空间
通过探索针对每个超参数定义的值范围来优化超参数。
超参数可以是离散的,也可以是连续的,并且可以具有用 参数表达式表示的值分布。
离散超参数
离散超参数将指定为离散值中的一个 Choice。
Choice 可以是:
- 一个或多个逗号分隔值
-
range对象 - 任意
list对象
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
引用:
在这种情况下, batch_size 采用 [16, 32, 64, 128] 中的一个,采用 number_of_hidden_layers [1, 2, 3, 4] 之一。
也可以使用一个分布来指定以下高级离散超参数:
-
QUniform(min_value, max_value, q)- 返回类似于 round(Uniform(min_value, max_value) / q) * q 的值 -
QLogUniform(min_value, max_value, q)- 返回类似于 round(exp(Uniform(min_value, max_value)) / q) * q 的值 -
QNormal(mu, sigma, q)- 返回类似于 round(Normal(mu, sigma) / q) * q 的值 -
QLogNormal(mu, sigma, q)- 返回类似于 round(exp(Normal(mu, sigma)) / q) * q 的值
连续超参数
连续超参数表示为在连续值范围上的分布:
-
Uniform(min_value, max_value)- 返回在 min_value 和 max_value 之间均匀分布的值 -
LogUniform(min_value, max_value)- 返回根据 exp(Uniform(min_value, max_value)) 绘制的值,使返回值的对数均匀分布 -
Normal(mu, sigma)- 返回正态分布的实际值,包括平均值 μ 和标准方差 σ -
LogNormal(mu, sigma)- 返回根据 exp(Normal(mu, sigma)) 绘制的值,使返回值的对数呈正态分布
参数空间定义的示例:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
引用:
此代码定义具有两个参数(learning_rate 和 keep_probability)的搜索空间。
learning_rate 包含平均值为 10、标准偏差为 3 的正态分布。
keep_probability 包含最小值为 0.05、最大值为 0.1 的均匀分布。
对于 CLI,请使用 扫描作业 YAML 架构 定义搜索空间:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
超参数空间采样
指定超参数空间的采样方法。 Azure 机器学习支持:
- 随机采样
- 网格采样
- 贝叶斯采样
随机采样
随机采样支持离散和连续超参数,并支持提前终止低性能作业。 许多用户从随机采样开始,以识别有希望的区域,然后进行优化。
在随机采样中,从定义的搜索空间均匀地(或通过指定的随机规则)抽取值。 创建命令作业后,使用 sweep 定义采样算法。
from azure.ai.ml.entities import CommandJob
from azure.ai.ml.sweep import RandomSamplingAlgorithm, SweepJob, SweepJobLimits
command_job = CommandJob(
inputs=dict(kernel="linear", penalty=1.0),
compute=cpu_cluster,
environment=f"{job_env.name}:{job_env.version}",
code="./scripts",
command="python scripts/train.py --kernel $kernel --penalty $penalty",
experiment_name="sklearn-iris-flowers",
)
sweep = SweepJob(
sampling_algorithm=RandomSamplingAlgorithm(seed=999, rule="sobol", logbase="e"),
trial=command_job,
search_space={"ss": Choice(type="choice", values=[{"space1": True}, {"space2": True}])},
inputs={"input1": {"file": "top_level.csv", "mode": "ro_mount"}}, # type:ignore
compute="top_level",
limits=SweepJobLimits(trial_timeout=600),
)
引用:
Sobol
Sobol 是一个准随机序列,可改善空间填充和可重现性。 提供种子并在rule="sobol"上设置RandomSamplingAlgorithm。
from azure.ai.ml.sweep import RandomSamplingAlgorithm
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomSamplingAlgorithm(seed=123, rule="sobol"),
...
)
网格采样
网格采样支持离散超参数。 如果你的预算允许在搜索空间中彻底进行搜索,请使用网格采样。 支持提前终止低性能作业。
网格采样对所有可能的值进行简单的网格搜索。 网格采样只能与 choice 超参数一起使用。 例如,以下空间有 6 个样本:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
参考: 选择
贝叶斯采样
Bayesian 采样(贝伊斯优化)根据先前的结果选择新样本,以有效地改进主要指标。
如果你有足够的预算来探索超参数空间,则建议使用贝叶斯采样。 为获得最佳结果,建议最大作业次数大于或等于正在优化的超参数数目的 20 倍。
并发作业的数目会影响优化过程的有效性。 数目较小的并发作业可能带来更好的采样收敛,因为较小的并行度会增加可从先前完成的作业中获益的作业数量。
贝伊斯采样支持 choice、 uniform分布和 quniform 分布。
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
引用:
指定扫描的目标
通过指定希望超参数优化的主要指标和目标,定义扫描作业的目标。 将根据此主要指标评估每个训练作业。 提前终止策略使用主要指标来识别低性能作业。
-
primary_metric:主要指标的名称需要与训练脚本记录的指标的名称完全匹配。 -
goal:可以是Maximize或Minimize,用于确定评估作业时主要指标是最大化还是最小化。
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
引用:
此示例最大程度地提高了“准确度”。
记录用于超参数优化的指标
训练脚本 必须 用扫描作业预期的确切名称记录主指标。
使用以下示例代码片段在训练脚本中记录主要指标:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
训练脚本会计算 val_accuracy,并将其记录为主要指标“准确度”。 每次记录指标时,超参数优化服务都会收到该指标。 你需要确定报告频率。
有关为训练作业记录值的详细信息,请参阅在 Azure 机器学习训练作业中启用日志记录。
指定提前终止策略
提前结束表现不佳的工作以提高效率。
你可以配置以下参数来控制何时应用该策略:
-
evaluation_interval:应用策略的频率。 每次训练脚本都会将主要指标计数记录为一个间隔。 如果evaluation_interval为 1,则训练脚本每次报告主要指标时,都会应用策略。 如果evaluation_interval为 2,则会每隔一次应用该策略。 如果未指定,则默认将evaluation_interval设置为 0。 -
delay_evaluation:将第一个策略评估延迟指定的间隔数。 这是一个可选参数,可让所有配置运行最小间隔数,避免训练作业过早终止。 如果已指定,则每隔大于或等于 delay_evaluation 的 evaluation_interval 倍数应用策略。 如果未指定,则默认将delay_evaluation设置为 0。
Azure 机器学习支持以下提前终止策略:
老虎机策略
强盗策略 使用松懈因子或金额加评估间隔。 当作业的主要指标偏离最佳作业所允许的指标范围时,它将结束作业。
指定以下配置参数:
slack_factor或slack_amount:与最佳任务的允许差异。slack_factor是比率;slack_amount是绝对值。例如,假设以间隔 10 应用老虎机策略。 另外,假设性能最佳的作业以间隔 10 报告了主要指标 0.8,目标是最大化主要指标。 如果策略指定的
slack_factor为 0.2,则间隔为 10 时其最佳指标小于 0.66 (0.8/(1+slack_factor)) 的任何训练作业都会被终止。evaluation_interval:(可选)应用策略的频率delay_evaluation:(可选)将第一个策略评估延迟指定的间隔数
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
参考: BanditPolicy
在此示例中,指标报告时将在每个间隔应用提前终止策略,从评估间隔 5 开始。 其最佳指标小于最佳性能作业的 (1/(1+0.1) 或 91% 的任何作业将被终止。
中间值停止策略
中值停止是基于作业报告的主要指标的运行平均值的提前终止策略。 该策略计算所有训练作业的运行平均值,并终止其主要指标值低于平均值中值的作业。
此策略采用以下配置参数:
-
evaluation_interval:应用策略的频率(可选参数)。 -
delay_evaluation:将第一个策略评估延迟指定的间隔数(可选参数)。
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
在此示例中,将在每个间隔应用提前终止策略,从评估间隔 5 开始。 如果某个作业的最佳主要指标比所有训练运行中间隔 1:5 的运行平均值的中间值更差,则会在间隔 5 处终止该作业。
截断选择策略
截断选择在每个评估间隔取消给定百分比的性能最差的作业。 使用主要指标对作业进行比较。
此策略采用以下配置参数:
-
truncation_percentage:要在每个评估间隔终止的性能最低的作业百分比。 一个介于 1 到 99 之间的整数值。 -
evaluation_interval:(可选)应用策略的频率 -
delay_evaluation:(可选)将第一个策略评估延迟指定的间隔数 -
exclude_finished_jobs:指定在应用策略时是否排除已完成的作业
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
在此示例中,将在每个间隔应用提前终止策略,从评估间隔 5 开始。 如果某个作业采用间隔 5 时的性能在采用间隔 5 的所有作业中处于 20% 的性能最低范围内,则会在间隔 5 处终止该作业,并将在应用策略时排除已完成的作业。
无终止策略(默认设置)
如果未指定策略,则超参数优化服务将让所有训练作业一直执行到完成。
sweep_job.early_termination = None
参考: SweepJob
选择提前终止策略
- 对于既可以节省成本又不会终止有前景的作业的保守策略,请考虑使用
evaluation_interval为 1 且delay_evaluation为 5 的中间值停止策略。 这属于保守的设置,可以提供大约 25%-35% 的节省,且不会造成主要指标损失(基于我们的评估数据)。 - 如果想节省更多成本,则可以使用老虎机策略或截断选择策略,因为前者的可用可宽延时间更短,后者的截断百分比更大。
为扫描作业设置限制
通过设置扫描作业的限制来控制资源预算。
-
max_total_trials:试用作业的最大数量。 必须是介于 1 到 1000 之间的整数。 -
max_concurrent_trials:(可选)可以并发运行的最大试用作业数。 如果未指定此项,则 max_total_trials 个作业将并行启动。 如果指定了此项,则它必须是介于 1 和 1000 之间的整数。 -
timeout:允许整个扫描作业运行的最长时间(秒)。 达到此限制后,系统将取消扫描作业,包括其所有试用。 -
trial_timeout:允许每个试用运行作业运行的最长时间(秒)。 达到此限制后,系统会取消试用。
注意
如果同时指定了 max_total_trials 和 timeout,则当达到这两个阈值中的第一个阈值时,超参数优化实验将终止。
注意
并发试用作业数根据指定计算目标中的可用资源进行限制。 请确保计算目标能够为所需的并发性提供足够的可用资源。
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
此代码将超参数优化实验配置为总共最多使用 20 个试用作业,一次运行 4 个试用作业,整个扫描作业的超时时间为 1,200 秒。
配置超参数优化试验
若要配置超参数优化试验,请提供以下信息:
- 所定义的超参数搜索空间
- 采样算法
- 你的提前终止策略
- 目标
- 资源限制
- CommandJob 或 CommandComponent
- SweepJob
SweepJob 可以对 Command 或 CommandComponent 运行超参数扫描。
注意
sweep_job 中使用的计算目标必须具有足够的资源来满足你的并发级别。 有关计算目标的详细信息,请参阅计算目标。
配置超参数优化试验:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.chinacloudapi.cn/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
引用:
该 command_job 函数被调用为函数,以便可以应用参数表达式。 该 sweep 函数配置了 trial采样算法、目标、限制和计算。 该代码片段来自示例笔记本 在 Command 或 CommandComponent 上运行超参数扫描。 在此示例中,learning_rate 和 boosting 被调整。 提前停止由 MedianStoppingPolicy 驱动,该组件会停止那些主要指标低于所有作业运行平均值的中位数的作业(请参阅 MedianStoppingPolicy 参考)。
要了解如何接收、分析参数值并将其传递给要优化的训练脚本,请参阅此代码示例
重要
每次超参数扫描作业都会从头开始重启训练,包括重新生成模型和所有数据加载器。 可以通过使用 Azure 机器学习管道或手动过程在训练作业之前尽可能多地准备数据来最大程度降低该成本。
提交超参数优化试验
定义超参数优化配置后,请提交作业:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
引用:
可视化超参数优化作业
在 Azure 机器学习工作室中可视化超参数优化作业。 有关详细信息,请参阅 工作室中的“查看作业记录”。
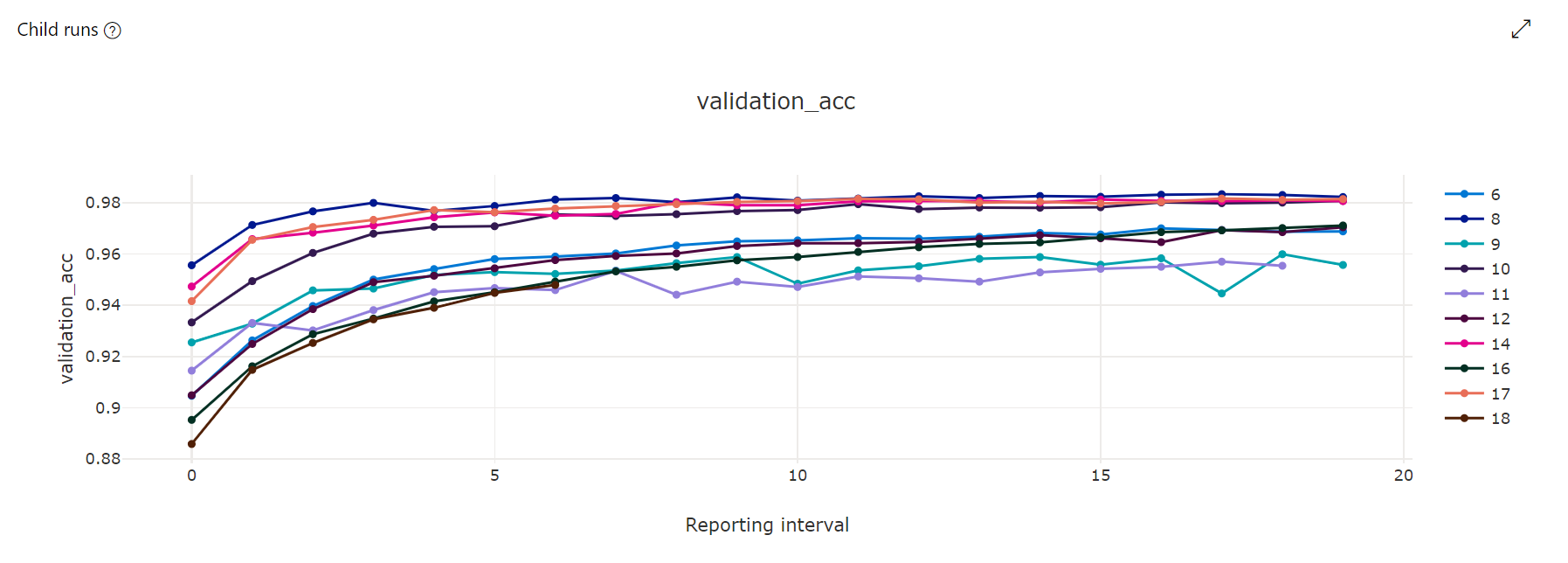
指标图表:此可视化效果跟踪在超参数优化期间为每个超驱动器子作业记录的指标。 每行表示一个子作业,每个点在运行时的迭代中度量主要指标值。
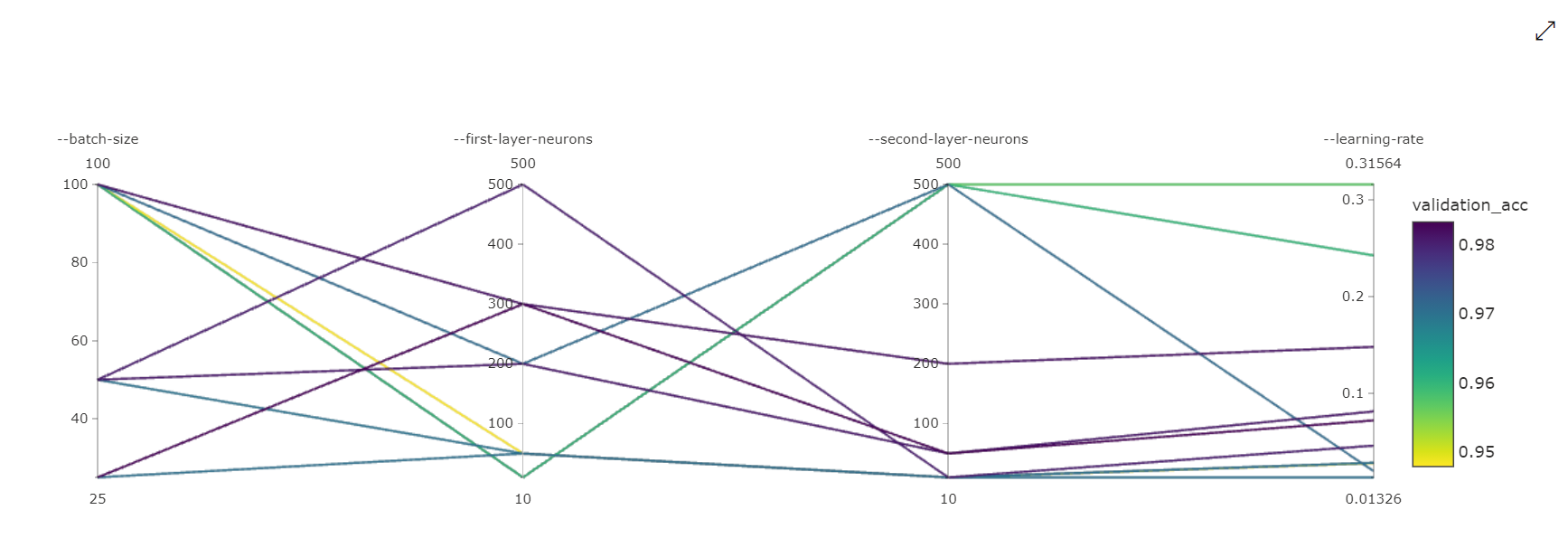
并行坐标图:此可视化效果显示主要指标性能与单个超参数值之间的关联。 该图表通过轴的移动(通过轴标签选择并拖动)和突出显示单个轴上的值(沿单个轴垂直选择并拖动以突出显示所需值的范围)进行交互。 在并行坐标图表的图表最右侧有一个轴,上面绘制了与为该作业实例设置的超参数相对应的最佳指标值。 提供此轴是为了以更可读的方式将图表渐变图例投影到数据上。
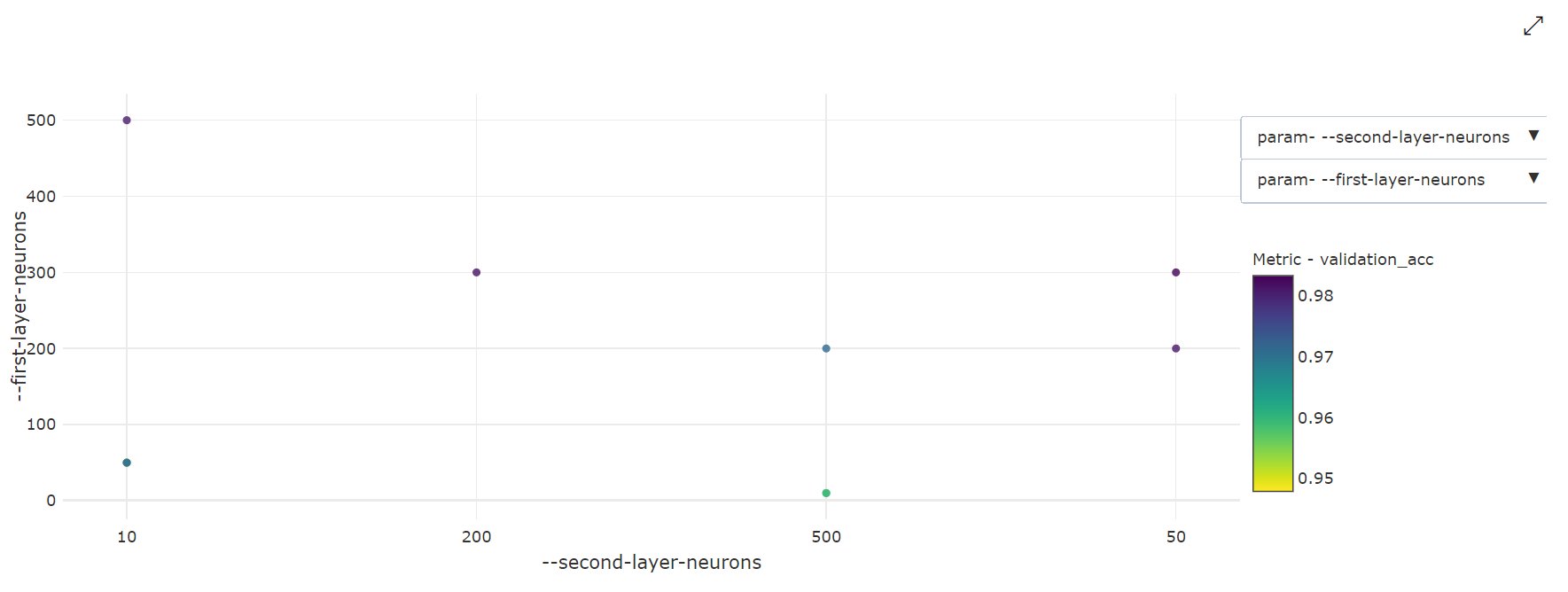
二维散点图:此可视化效果显示任意两个单独的超参数之间的关联以及它们对应的主要指标值。
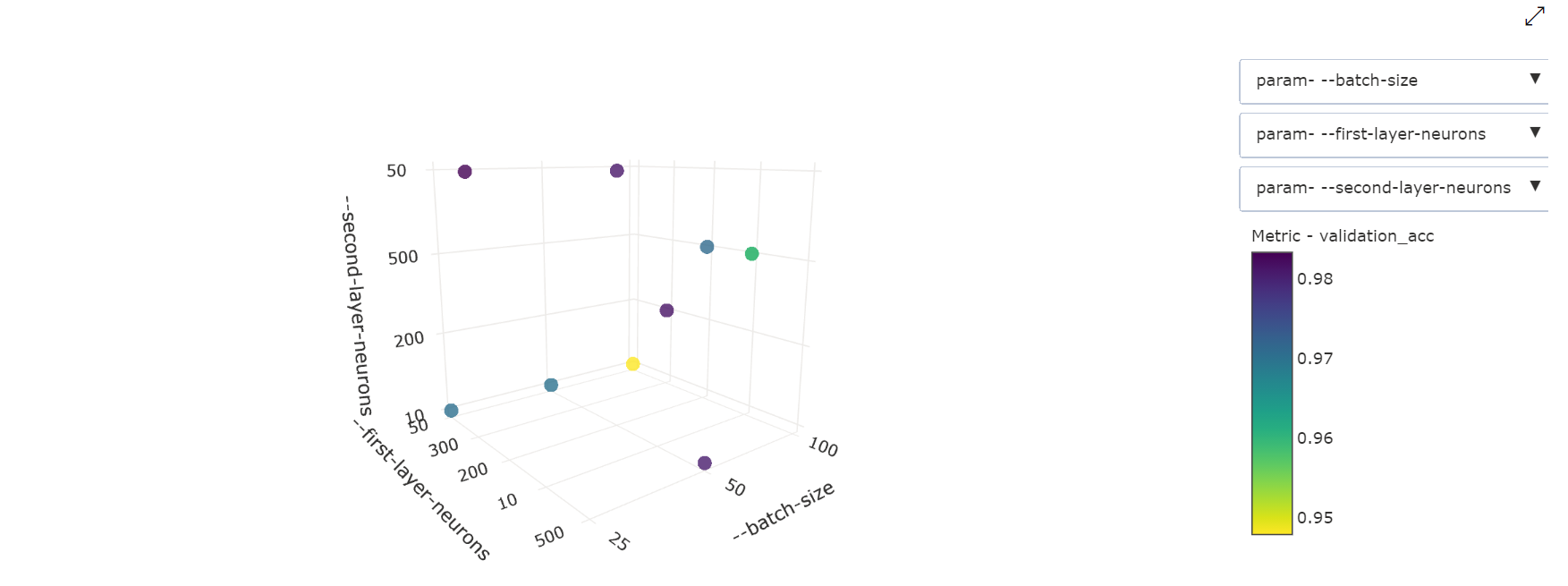
三维散点图:此可视化效果与二维散点图相同,但可以显示三个超参数维度的关联和主要指标值。 也可以选择并拖动来重新定位图表,以查看三维空间中的不同相关性。
查找最佳试用作业
完成所有优化作业后,检索最佳试用输出:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
引用:
可以使用 CLI 下载最佳试用作业的所有默认和命名输出以及扫描作业的日志。
az ml job download --name <sweep-job> --all
(可选)仅下载最佳试用输出:
az ml job download --name <sweep-job> --output-name model