批量运行使用大型数据集来执行提示流,并为每行数据生成输出。 若要评估提示流在处理大型数据集时的性能,可以提交批处理运行并使用评估方法生成性能分数和指标。
批处理流完成后,评估方法会自动执行以计算分数和指标。 可以使用评估指标根据性能标准和目标评估流的输出。
本文介绍如何提交批处理运行,并使用评估方法来衡量流输出的质量。 你了解了如何查看评估结果和指标,学习了如何使用不同的方法或变体子集来开始新一轮的评估。
先决条件
若要使用评估方法运行批处理流,需要以下组件:
一个工作中的 Azure 机器学习提示流程,用于测试其性能。
用于批处理运行的测试数据集。
测试数据集必须采用 CSV、TSV 或 JSONL 格式,并且应具有与流的输入名称匹配的标题。 但是,可以在评估运行设置过程中将不同的数据集列映射到输入列。
创建和提交评估批处理运行
若要提交批处理运行,请选择用于测试流的数据集。 还可选择评估方法来计算流输出的指标。 如果不想使用评估方法,则可以跳过评估步骤,并在不计算任何指标的情况下运行批处理运行。 还可以稍后进行另一轮评估。
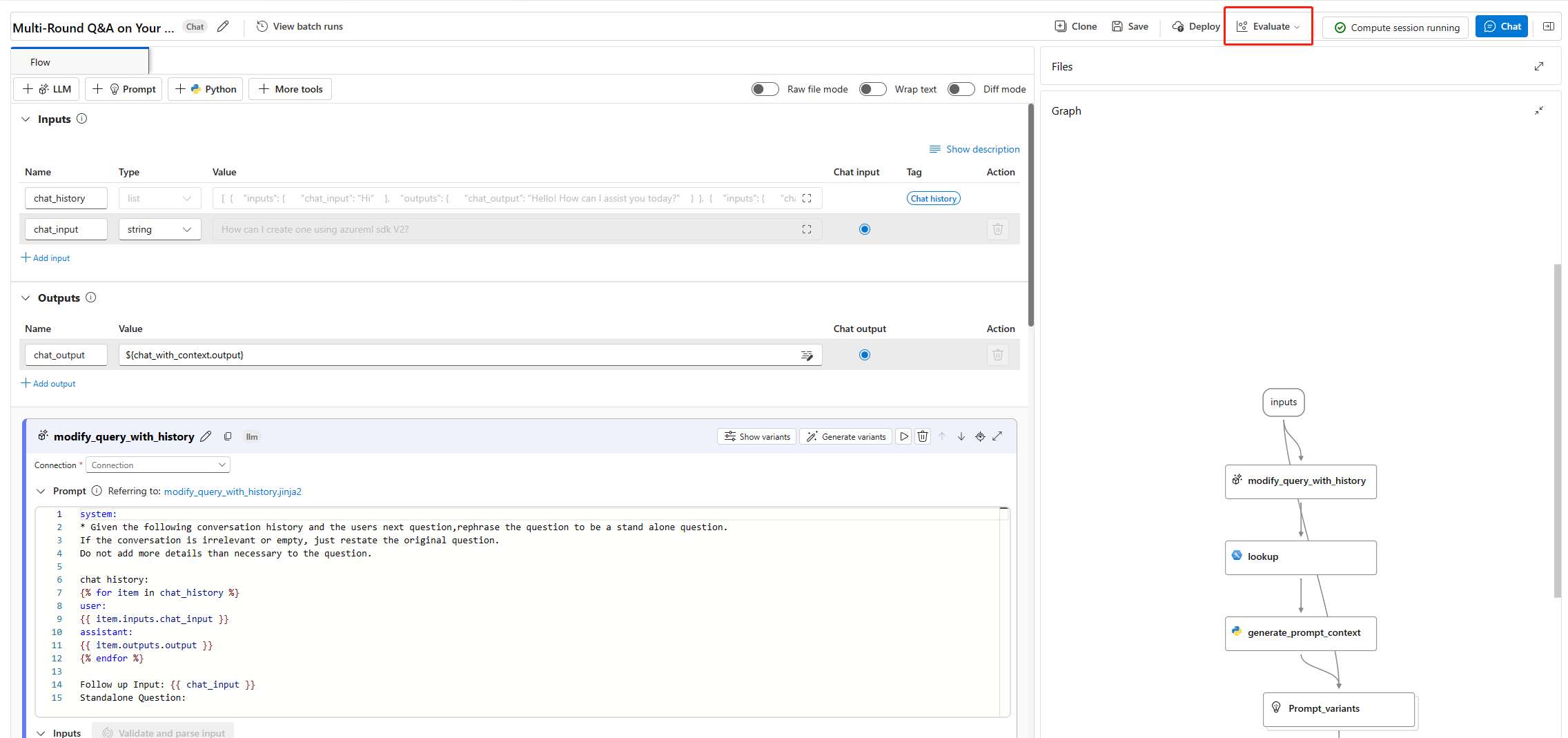
要开始批处理运行,不论是否需要评估,请在提示流页面顶部选择“评估”
。 
在批处理运行和评估向导的基本设置页面上,根据需要自定义运行显示名称,并可以选择提供运行说明和标记。 选择下一步。
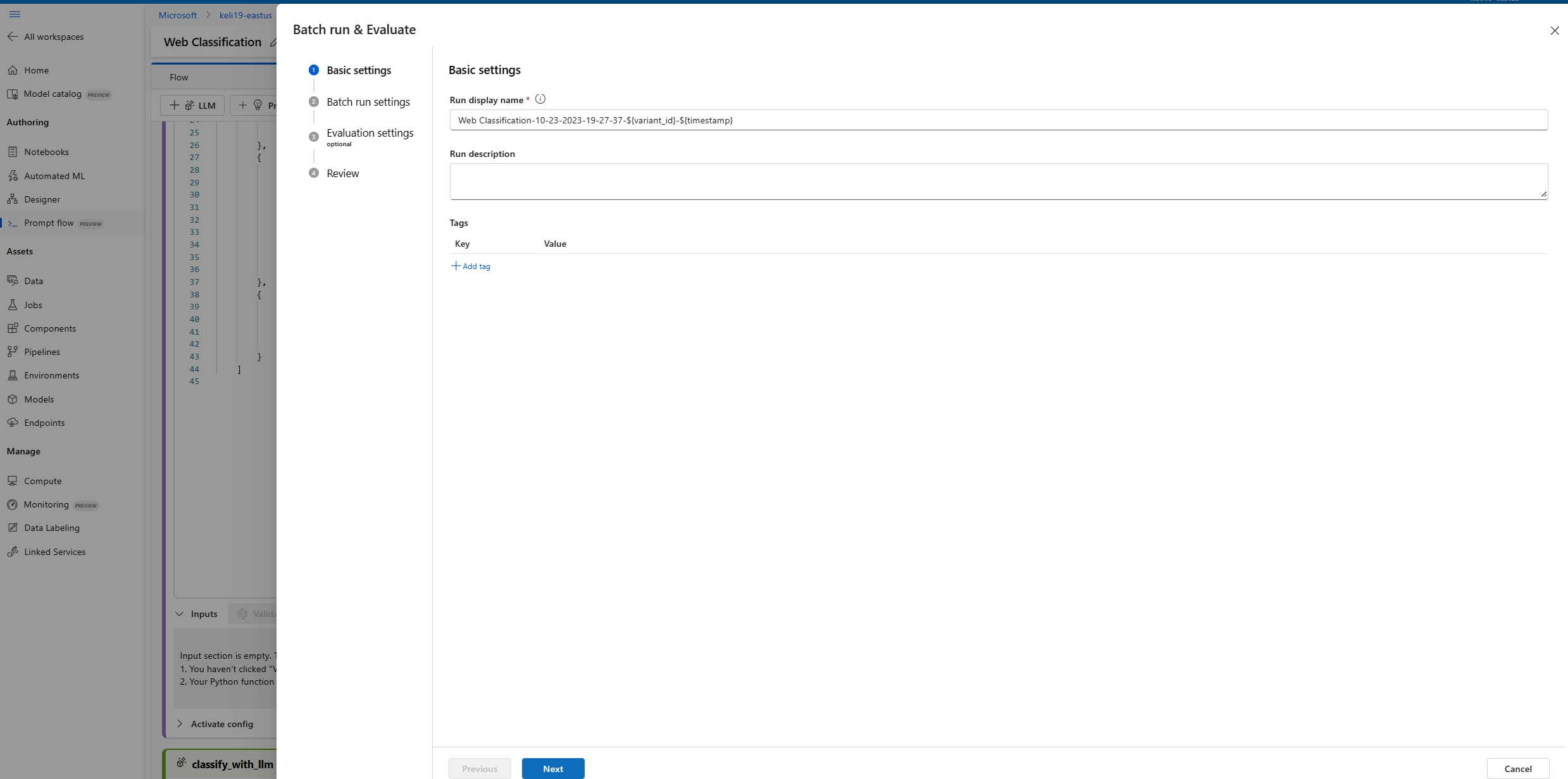
在“批处理运行设置”页上,选择要使用的数据集并配置输入映射。
提示流支持将流输入映射到数据集中的特定数据列。 可以使用
${data.<column>}将数据集列分配给特定输入。 如果要将常量值分配给输入,可以直接输入该值。
此时可以选择“查看 + 提交”,以跳过评估步骤并运行批处理运行,而无需使用任何评估方法。 然后,批处理运行将为数据集中的每个项生成单个输出。 可以手动检查输出,也可以导出输出供进一步分析。
否则,若要使用评估方法来验证此运行的性能,请选择“下一步”。 还可以将新一轮评估添加到已完成的批处理任务。
在“选择评估”页上,选择要运行的一个或多个自定义或内置评估。 可选择“查看详细信息”按钮,查看有关评估方法的详细信息,例如生成的指标及其所需的连接和输入。
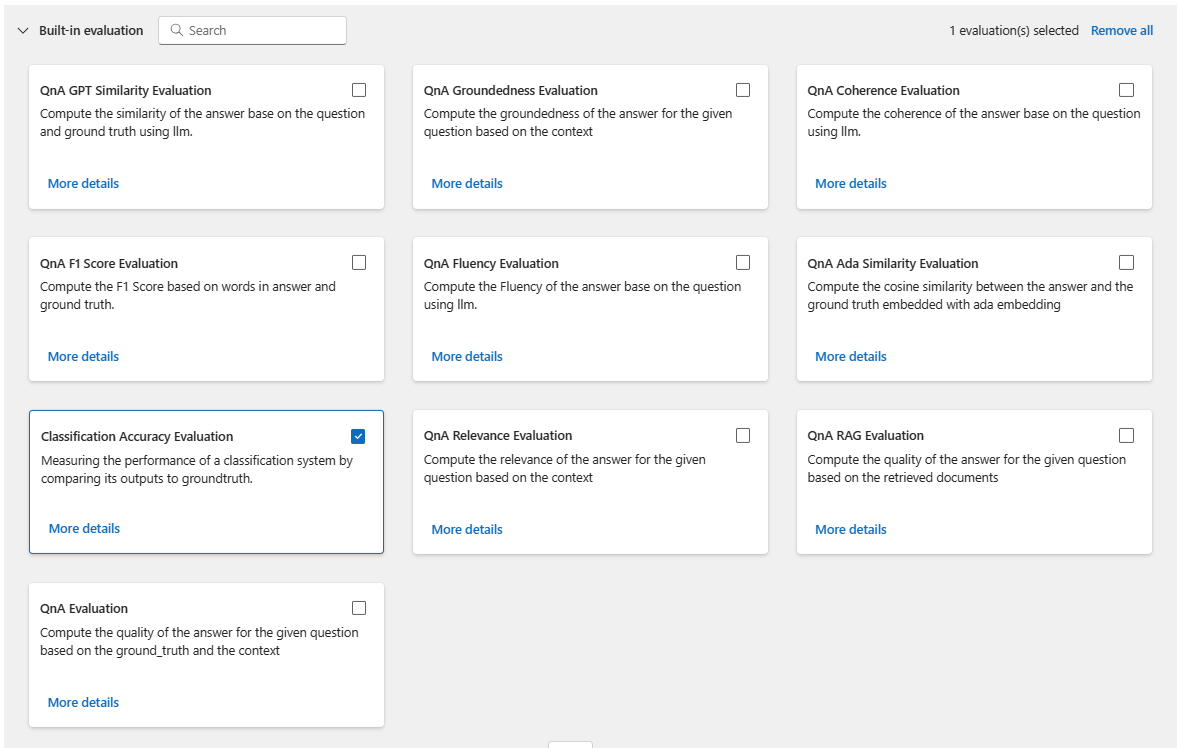
接着,在“配置评估”屏幕上,指定评估所需输入的源。 例如,基本事实列可能来自数据集。 默认情况下,评估使用与整个批处理运行相同的数据集。 但如果相应的标签或目标基准真值位于不同的数据集中,则可以使用该数据集。
注意
如果评估方法不需要数据集中的数据,则数据集选择是不影响评估结果的可选配置。 无需选择数据集,也无需引用输入映射部分中的任何数据集列。
在“评估输入映射”部分中,指示评估所需输入的源。
- 如果数据来自测试数据集,则将源设置为
${data.[ColumnName]}。 - 如果数据来自运行输出,则将源设置为
${run.outputs.[OutputName]}。
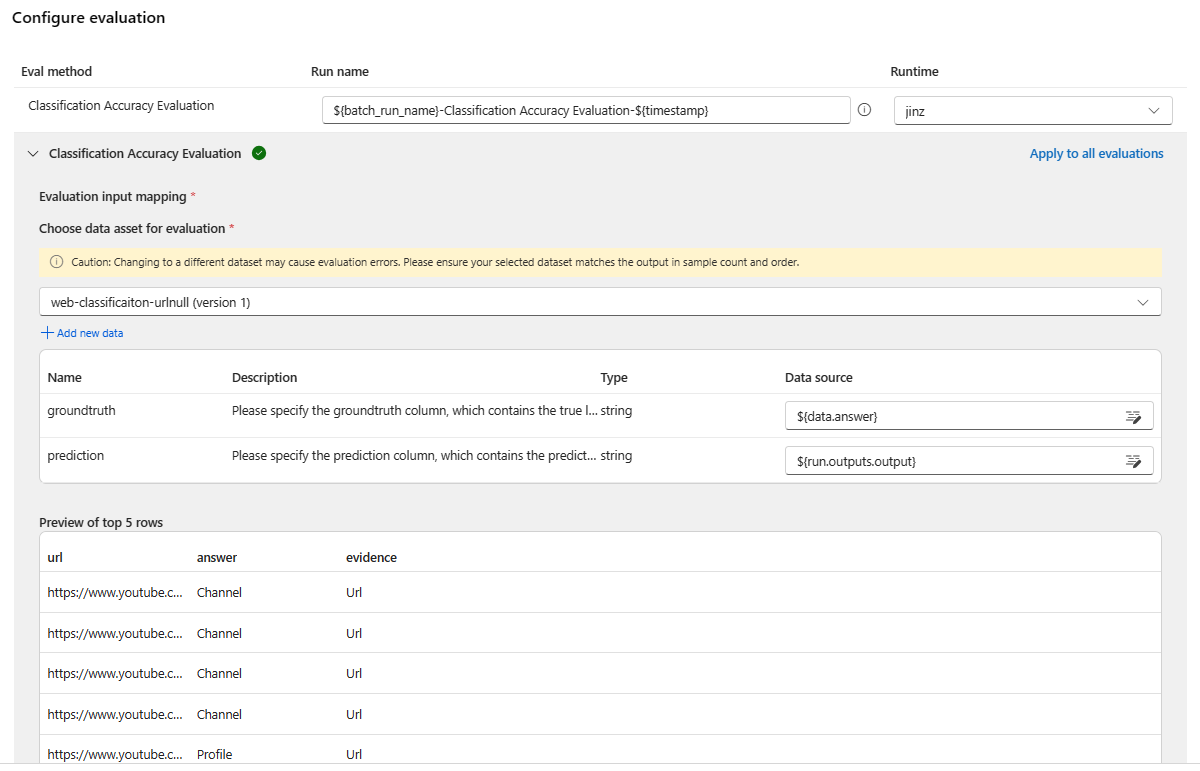
- 如果数据来自测试数据集,则将源设置为
某些评估方法需要大型语言模型(LLM),例如 GPT-4 或 GPT-3.5,或者需要其他连接才能使用凭据或密钥。 对于这些方法,您必须在此屏幕底部的连接部分输入连接数据,以便使用评估流程。

选择“查看 + 提交”以查看设置,然后选择“提交”以开始批处理运行并进行评估。






注意
- 某些评估过程使用大量令牌,因此建议使用可支持 >=16k 令牌的模型。
- 批处理运行的最大持续时间为 10 小时。 如果批处理运行超过此限制,它将会终止并显示为失败。 监视 LLM 容量以避免节流。 如有必要,请考虑减小数据的大小。 如果仍有问题,请提交反馈表或支持请求。
查看评估结果和指标
可以在 Azure 机器学习工作室“提示流”页的“运行”选项卡上找到已提交的批处理运行列表。
若要查看批处理运行的结果,请选择该运行,然后选择“可视化输出”。
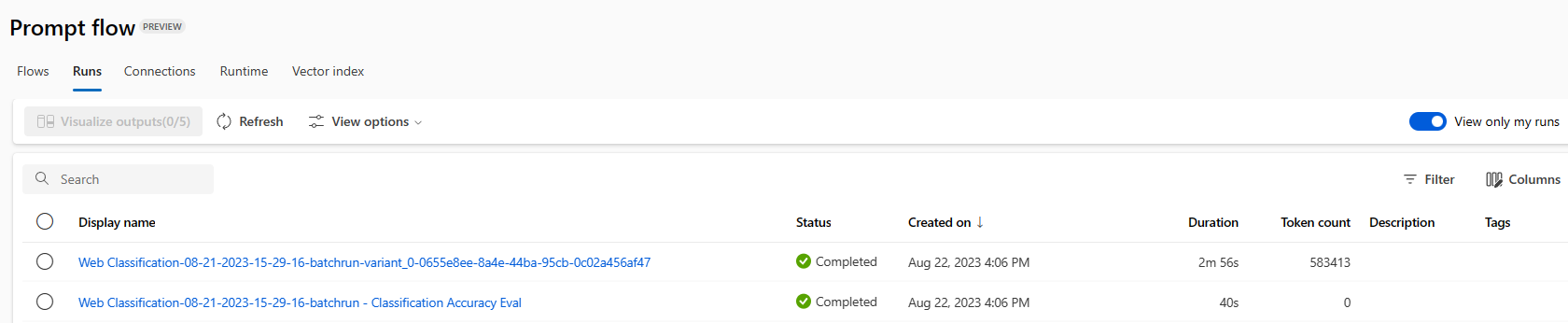
在“可视化输出”屏幕上,“运行和指标”部分显示批处理运行和评估运行的总体结果。 “输出”部分在结果表中逐行显示运行输入,包括行 ID、“运行”、“状态”和“系统指标”。
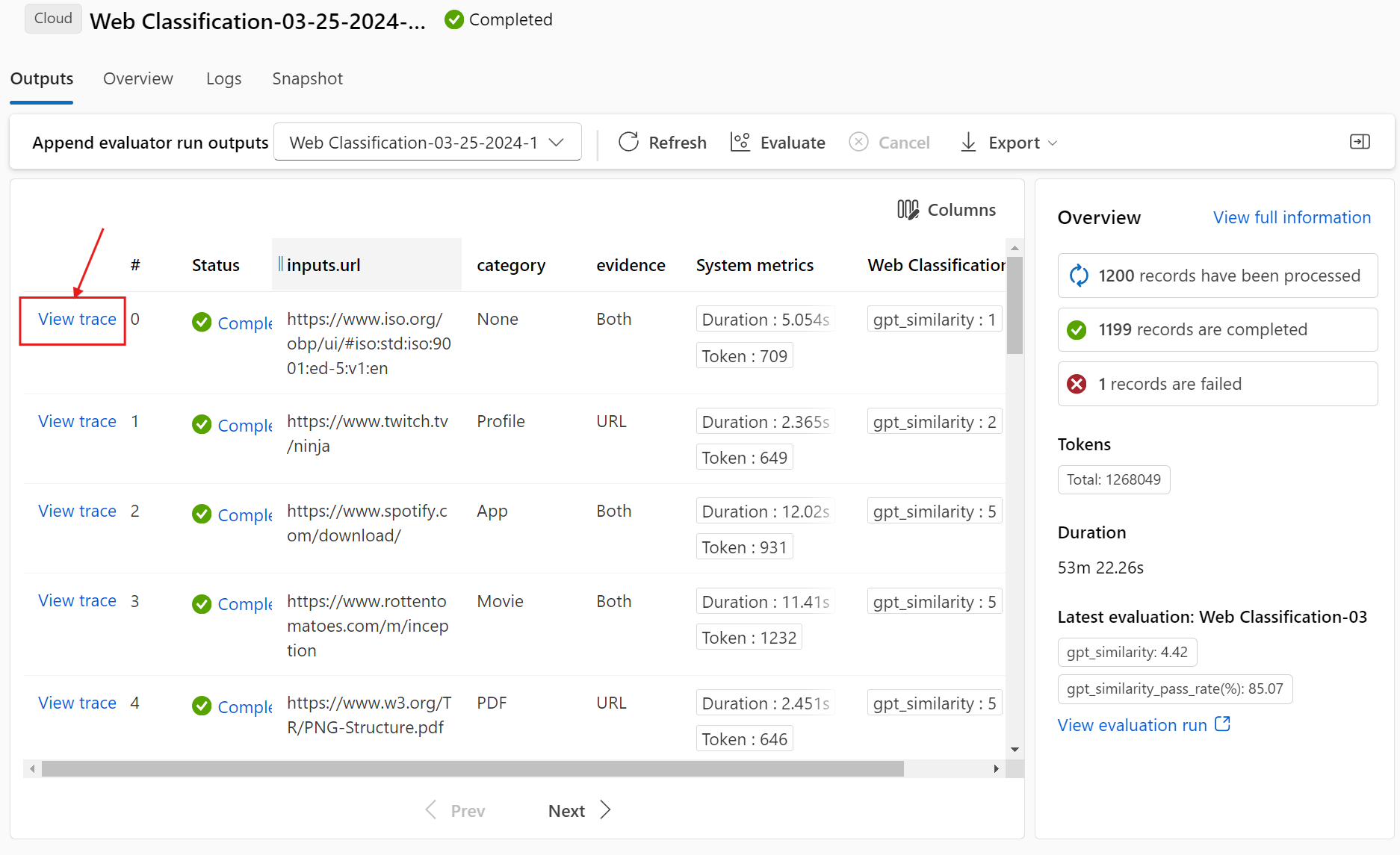
在“运行和指标”部分中,如果启用评估运行旁边的“查看”图标,则“输出”表还将显示每行的评估分数或成绩。
选择“输出”表中每行旁边的“查看详细信息”图标,观察和调试该测试用例的“跟踪视图”和“详细信息”。 “跟踪”视图显示此案例的“令牌数量”和“持续时间”等信息。 展开并选择任何步骤以查看该步骤的概述和输入。
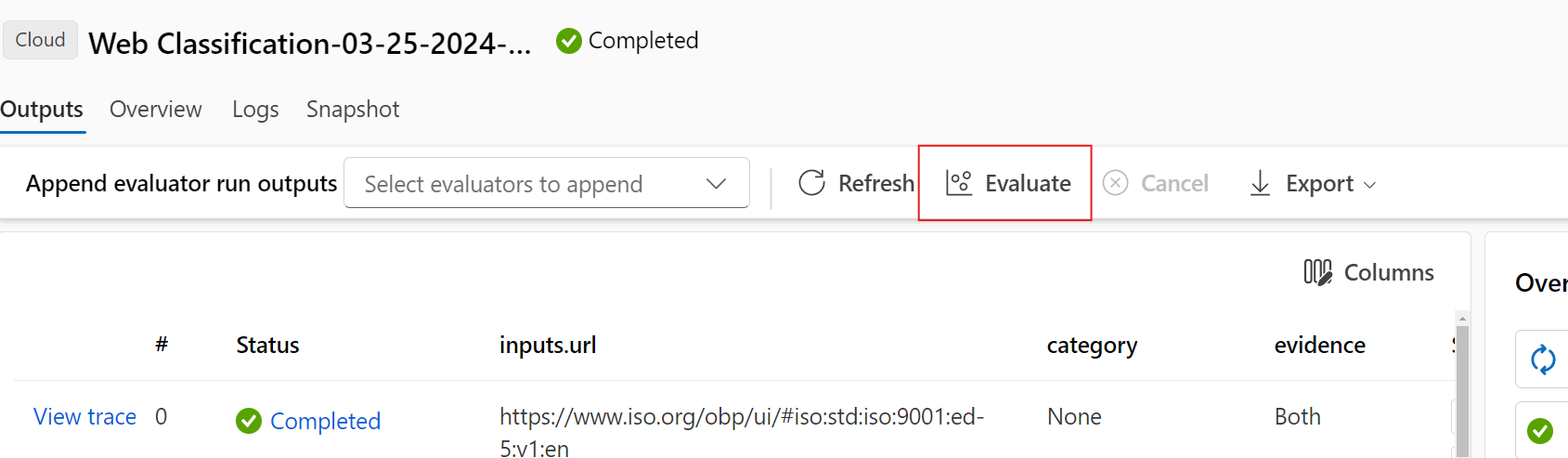




您还可以查看测试过的提示流中的评估运行结果。 在“查看批处理运行”下,选择“查看批处理运行”以查看流的批处理运行列表,或选择“查看最新批处理运行输出”以查看最新运行的输出。

在批处理运行列表中,选择一个批处理运行名称以打开该运行的流页。
在评估运行的流页上,选择“查看输出”或“详细信息”以查看流的详细信息。 还可以“克隆”流以创建新流,或“部署”流作为联机终结点。

在详细信息屏幕上:
“概述”选项卡显示有关此运行的完整信息,包括运行属性、输入数据集、输出数据集、标记和说明。
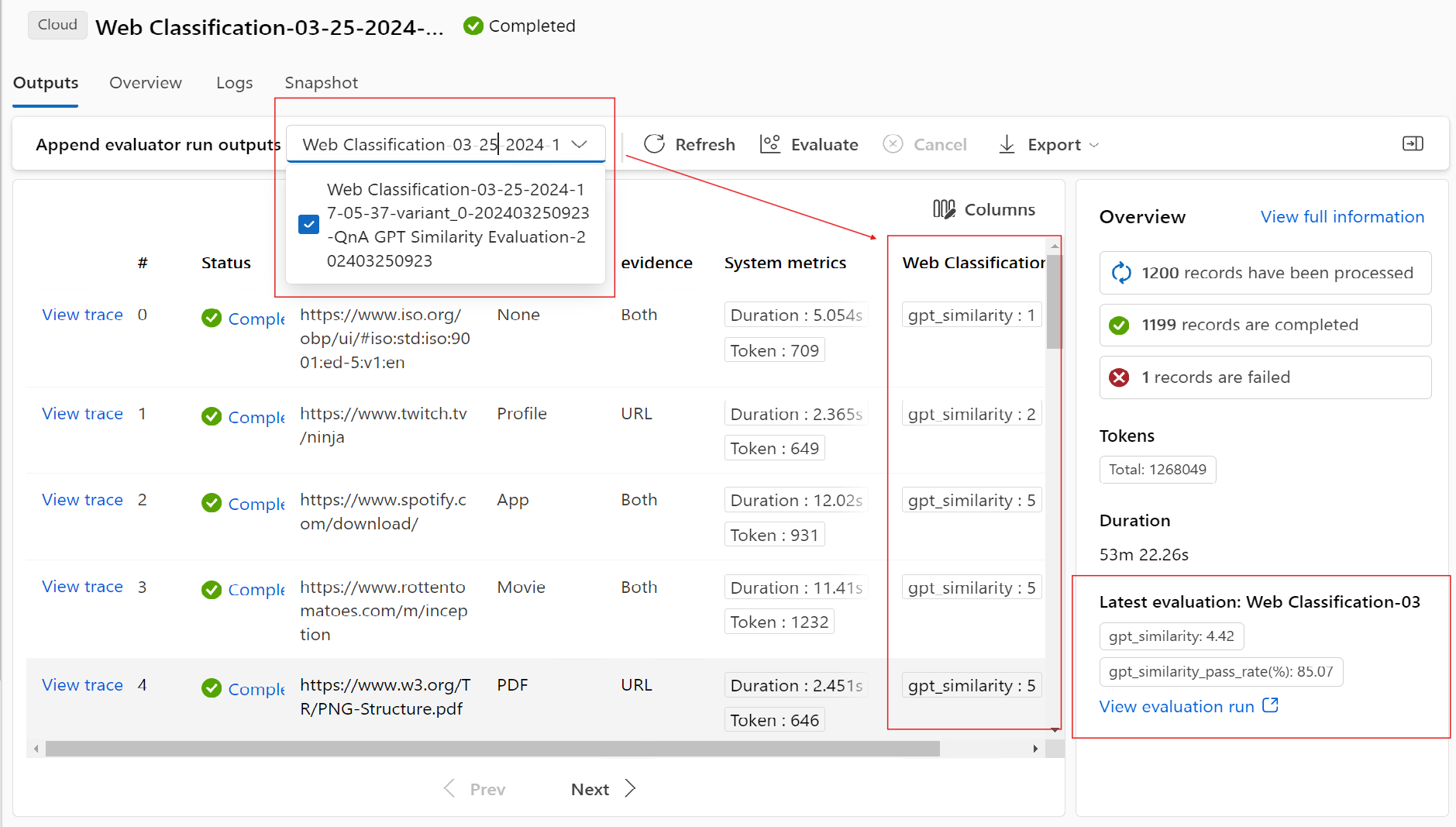
“输出”选项卡显示页面顶部的结果摘要,后跟批处理运行结果表。 如果选择“追加相关结果”旁边的评估运行,该表还会显示评估运行结果。
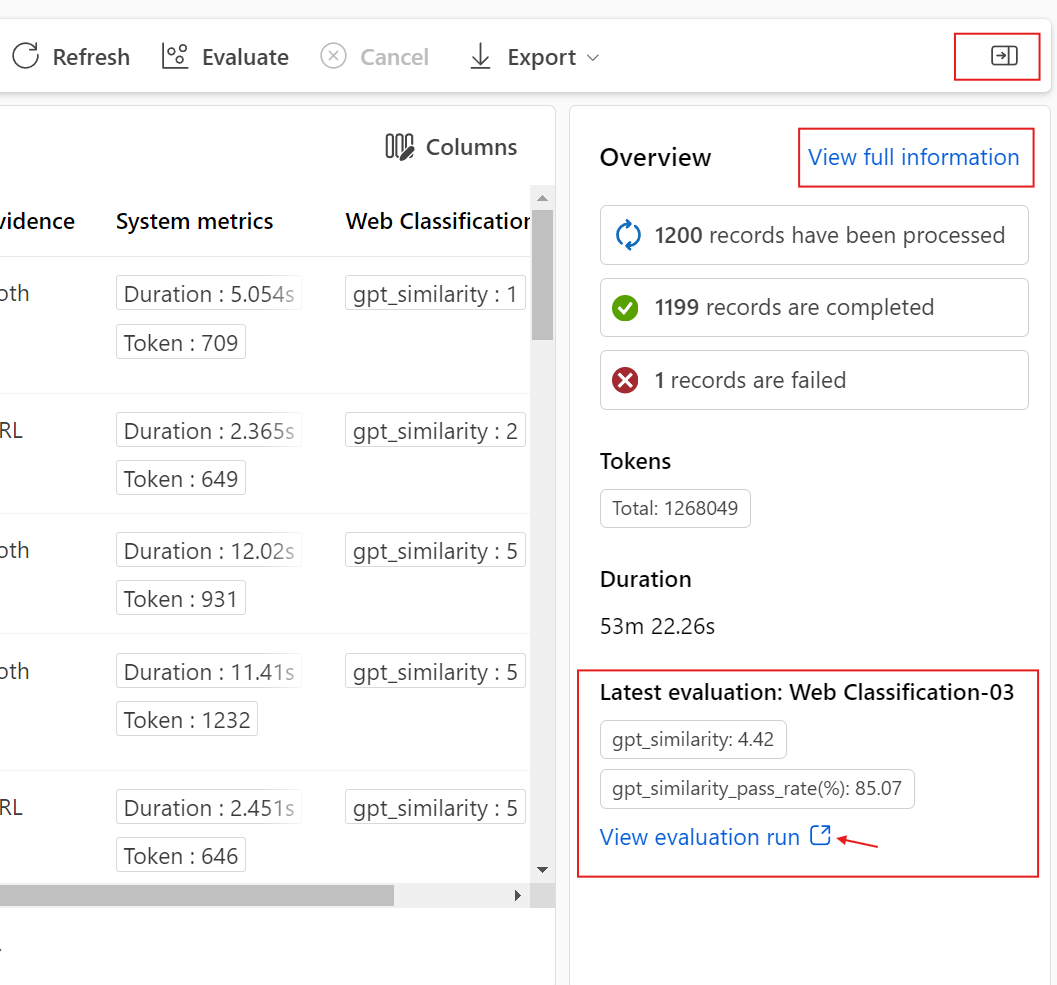
“日志”选项卡显示运行日志,这对于执行错误的详细调试非常有用。 可以下载日志文件。
“指标”选项卡提供指向运行指标的链接。
“跟踪”选项卡显示每个测试用例的详细信息,如令牌数量和持续时间。 展开并选择任意步骤以查看该步骤的概述和输入信息。
“快照”选项卡显示运行中的文件和代码。 可以查看 flow.dag.yaml 流定义并下载任何文件。
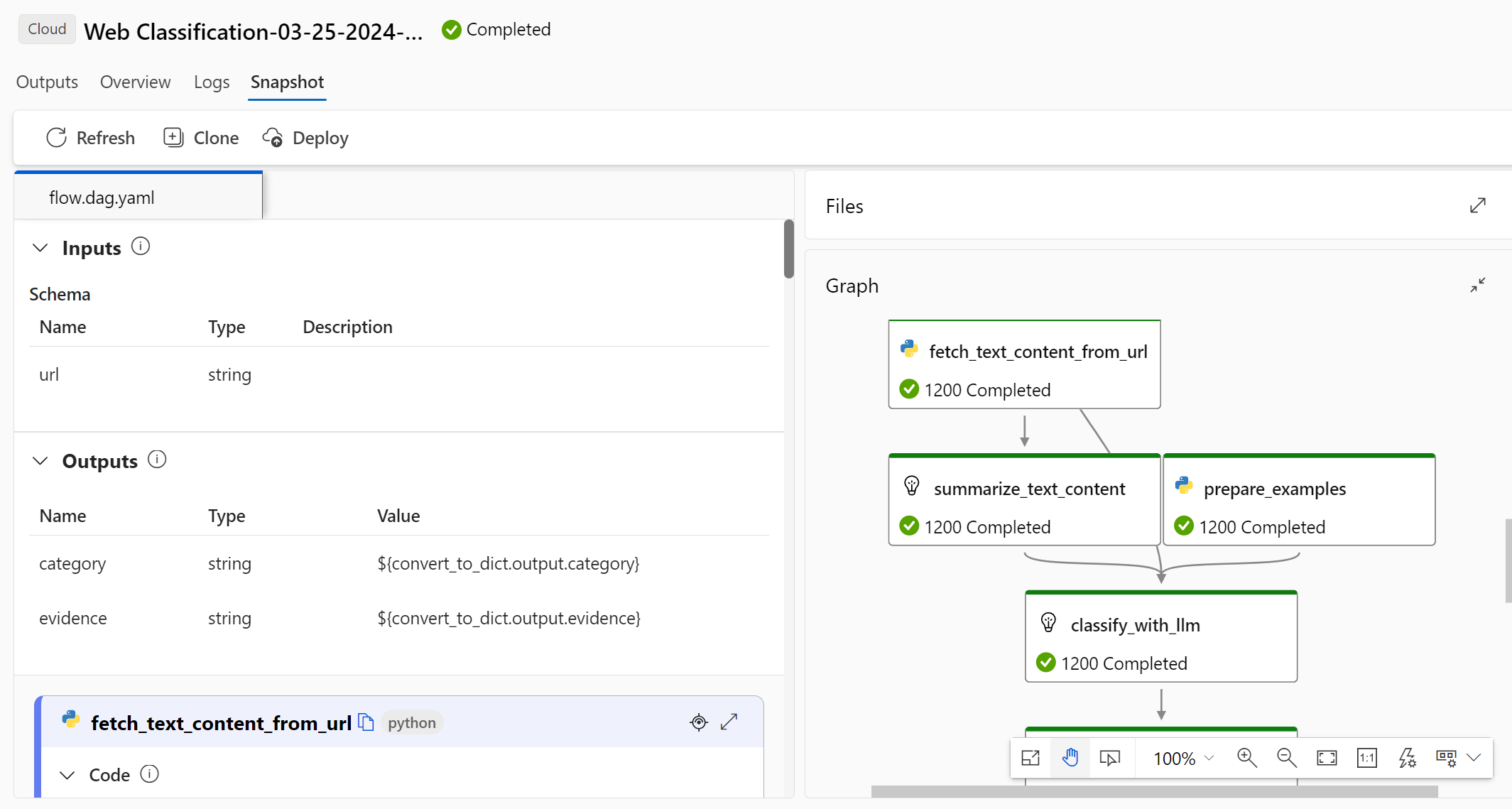


为同一运行启动新一轮评估
可以运行新一轮评估流程来计算已完成的批处理运行指标,而不需要再次启动流程。 此过程可节省重新运行流的成本,在以下场景中非常有用:
- 你在提交批处理运行时未选择评估方法,现在需要评估运行性能。
- 你使用了评估方法来计算特定的指标,现在需要计算其他指标。
- 之前的评估运行失败,但批处理运行已成功生成输出,你需要再次尝试评估。
若要启动另一轮评估,请选择批处理运行流页顶部的“评估”。 “新建评估”向导会打开“选择评估”屏幕。 完成设置并提交新的评估流程。
新运行将显示在提示流“运行”列表中,你可以在列表中选择多个行,然后选择“可视化输出”来比较输出和指标。
比较评估运行历史记录和指标
如果修改流以提高其性能,可以提交多个批处理运行来比较不同流版本的性能。 还可以比较由不同评估方法计算的指标,查看哪种方法更适合你的流。
若要查看流批处理运行历史记录,请选择流页顶部的“查看批处理运行”。 可以选择每个执行来查看详细信息。 还可以选择多个运行,并选择“可视化输出”,以比较这些运行的指标和输出。

了解内置评估指标
Azure 机器学习提示流提供了多种内置评估方法,可帮助衡量流输出的性能。 每种评估方法计算不同的指标。 下表描述可用的内置评估方法。
| 评估方法 | 度量 | 说明 | 是否需要连接? | 必需的输入 | 分数值 |
|---|---|---|---|---|---|
| 分类准确性评估 | 准确性 | 通过将分类系统的输出与真实值进行比较来衡量分类系统的性能 | 否 | 预测,实际值 | 在 [0, 1] 范围内 |
| QnA 依据性评估 | 扎实性 | 测量模型预测的答案在输入源中的真实程度。 即使 LLM 的响应是准确的,如果无法与来源对比验证,它们仍然是没有根据的。 | 是 | 问题、答案、上下文(没有基本事实) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA GPT 相似性评估 | GPT 相似性 | 衡量用户提供的基本事实答案与使用 GPT 模型的模型预测答案之间的相似性 | 是 | 问题、答案、基本事实(不需要上下文) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 相关性评估 | 相关性 | 衡量模型预测的答案与所提出的问题的相关程度 | 是 | 问题、答案、上下文(没有基本事实) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 一致性评估 | 一致性 | 衡量模型预测的答案中所有句子的质量,以及它们如何自然地组合在一起 | 是 | 问题、答案(没有基本事实或上下文) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA 流畅度评估 | 流畅度 | 衡量模型的预测答案的语法和语言正确性 | 是 | 问题、答案(没有基本事实或上下文) | 1 到 5,1 = 最差,5 = 最佳 |
| QnA F1 分数评估 | F1 分数 | 衡量模型预测与真实值之间的共享字词数的比率 | 否 | 问题、答案、基本事实(不需要上下文) | 在 [0, 1] 范围内 |
| QnA Ada 相似性评估 | Ada 相似性 | 使用 Ada 嵌入 API 计算句子(文档)级别的嵌入,以获得基本事实和预测,然后计算它们之间的余弦相似性(一个浮点数) | 是 | 问题、答案、基本事实(不需要上下文) | 在 [0, 1] 范围内 |
提高流性能
如果运行失败,请检查输出和日志数据并调试任何流故障。 若要修复流或提高性能,请尝试修改流提示、系统消息、流参数或流逻辑。