生成流并对其进行正确测试后,可能需要将其部署为终结点,以便可以调用该终结点进行实时推理。
本文介绍如何将流程部署为管理的在线终结点,用于实时推理。 要执行的步骤如下所示:
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 该预览版在提供时没有附带服务级别协议,建议不要将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Azure 预览版的使用条款。
先决条件
对托管联机终结点有基本的了解。 托管在线终结点在 Azure 中可与强大的 CPU 和 GPU 服务器协同工作,以可扩展、完全托管的方式运作,让您无需承担设置和管理底层部署基础设施的负担。 有关托管联机终结点的详细信息,请参阅用于实现实时推理的联机终结点和部署。
Azure基于角色的访问控制(Azure RBAC)用于授予对Azure Machine Learning中操作的访问权限。 若要能够在提示流中部署终结点,必须为用户帐户分配 AzureML 数据科学家或角色,并为 Azure Machine Learning 工作区分配更多权限。
具备对托管标识的基本了解。 详细了解托管身份。
注意
托管的在线终结点仅可用于托管虚拟网络。 如果你的工作区位于自定义 VNet 中,则你需要尝试其他部署选项,例如使用 CLI/SDK 部署到 Kubernetes 联机终结点,或部署到其他平台(例如 Docker)。
创建流并为部署做好准备
如果未完成本教程,就需要创建工作流。 建议的最佳做法是在部署前通过批运行和计算来正确测试流。
我们将以示例流“Web 分类”为例来演示如何部署流。 此示例流是标准流。 部署聊天流的过程类似。 评估流程不支持部署。
定义部署使用的环境
在 UI 中将提示流部署到托管联机终结点时,默认情况下,部署将使用基于流的 requirements.txt 中指定的最新提示流映像和依赖项创建的环境。 可以在 requirements.txt 中指定所需的额外包。 可以在流文件夹的根文件夹中找到 requirements.txt。

注意
如果在 Azure devops 中使用专用源,则需要先使用专用源生成映像,然后选择要在 UI 中部署的自定义环境。
创建联机部署
生成流并对其进行正确测试后,接下来可以创建联机终结点以进行实时推理。
提示流支持您从流程或批处理运行中部署端点。 建议的最佳做法是在部署前测试流。
在“流创作”页或“运行详细信息”页中,选择“部署”。
流编辑页面:

运行详情页:

出现一个用于配置终结点的向导,其中包含以下步骤。
基本设置

使用此步骤可以配置部署的基本设置。
| 属性 | 说明 |
|---|---|
| 端点 | 可以选择是要部署新终结点还是更新现有终结点。 如果选择“新建”,则需要指定终结点名称。 |
| 部署名称 | - 在同一终结点中,部署名称应是唯一的。 - 如果选择了现有终结点并输入了现有部署名称,则该部署将被新配置覆盖。 |
| 虚拟机 | 用于部署的 VM 大小。 有关支持的大小列表,请参阅托管联机终结点 SKU 列表。 |
| 实例计数 | 用于部署的实例数。 请指定您预期工作负载的值。 为实现高可用性,建议将值至少设置为 3。 我们保留额外的 20% 来执行升级。 有关详细信息,请参阅托管在线端点配额 |
完成基本设置后,可直接选择“查看 + 创建”以完成创建,或选择“下一步”以配置高级设置。
高级设置 - 终结点
可为终结点指定以下设置。

身份验证类型
终结点的身份验证方法。 基于密钥的身份验证提供不会过期的主密钥和辅助密钥。 Azure Machine Learning基于令牌的身份验证提供定期自动刷新的令牌。 有关身份验证的详细信息,请参阅向联机终结点进行身份验证。
标识类型
终结点需要访问 Azure 资源,例如 Azure 容器注册表或您的工作区连接,以进行推理工作。 可以通过授予其托管标识的权限,允许终结点权限访问Azure资源。
系统分配的标识将在创建终结点后自动创建,而用户分配的标识则由用户创建。 详细了解托管身份。
系统分配
请注意,有一个选项用于指定是否强制访问连接机密(预览版)。 如果流使用连接,则终结点需要访问连接才能执行推理。 默认情况下,此选项处于启用状态,如果具有连接机密读取者权限,则会向终结点授予Azure Machine Learning工作区连接机密读取者角色以自动访问连接。 如果禁用此选项,则你需要自行向系统分配的标识授予此角色,或向管理员寻求帮助。详细了解如何向终结点标识授予权限。
注意
对于系统分配的标识,会自动分配若干角色(包括 AcrPull、存储 Blob 数据读取器 和 AzureML 指标编写器)。 有关详细信息,请参阅 联机终结点的身份验证和授权。
用户指定
创建部署时,Azure尝试从工作区Azure Container Registry(ACR)拉取用户容器映像,并从工作区存储帐户将用户模型和代码项目装载到用户容器中。
如果使用用户分配的标识创建了关联的终结点,则在创建部署之前必须向用户分配的标识授予以下角色;否则,部署创建将会失败。
| Scope | 角色 | 为什么需要它 |
|---|---|---|
| Azure 机器学习工作区 | Azure Machine Learning 工作区连接机密读取角色 角色或 具有“Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action”权限的自定义角色 | 获取工作区连接 |
| 工作区容器注册表 | ACR 拉取 | 拉取容器映像 |
| 工作区默认存储 | 存储 Blob 数据读取者 | 从存储加载模型 |
| (可选)Azure Machine Learning工作区 | 工作区指标编写器 | 部署终结点后,如果要监视与终结点相关的指标(如 CPU/GPU/磁盘/内存利用率),则需要向标识授予此权限。 |
请参阅向终结点授予权限中有关如何向终结点标识授予权限的详细指导。
高级设置 - 部署
在此步骤中,除标记之外,还可指定部署使用的环境。

当前流定义的使用环境
默认情况下,部署将使用基于 flow.dag.yaml 中指定的基础映像和 requirements.txt 中指定的依赖项创建的环境。
可以通过选择流的
flow.dag.yaml来指定Raw file mode中的基础映像。 如果未指定映像,则默认的基础映像为最新的提示流基础映像。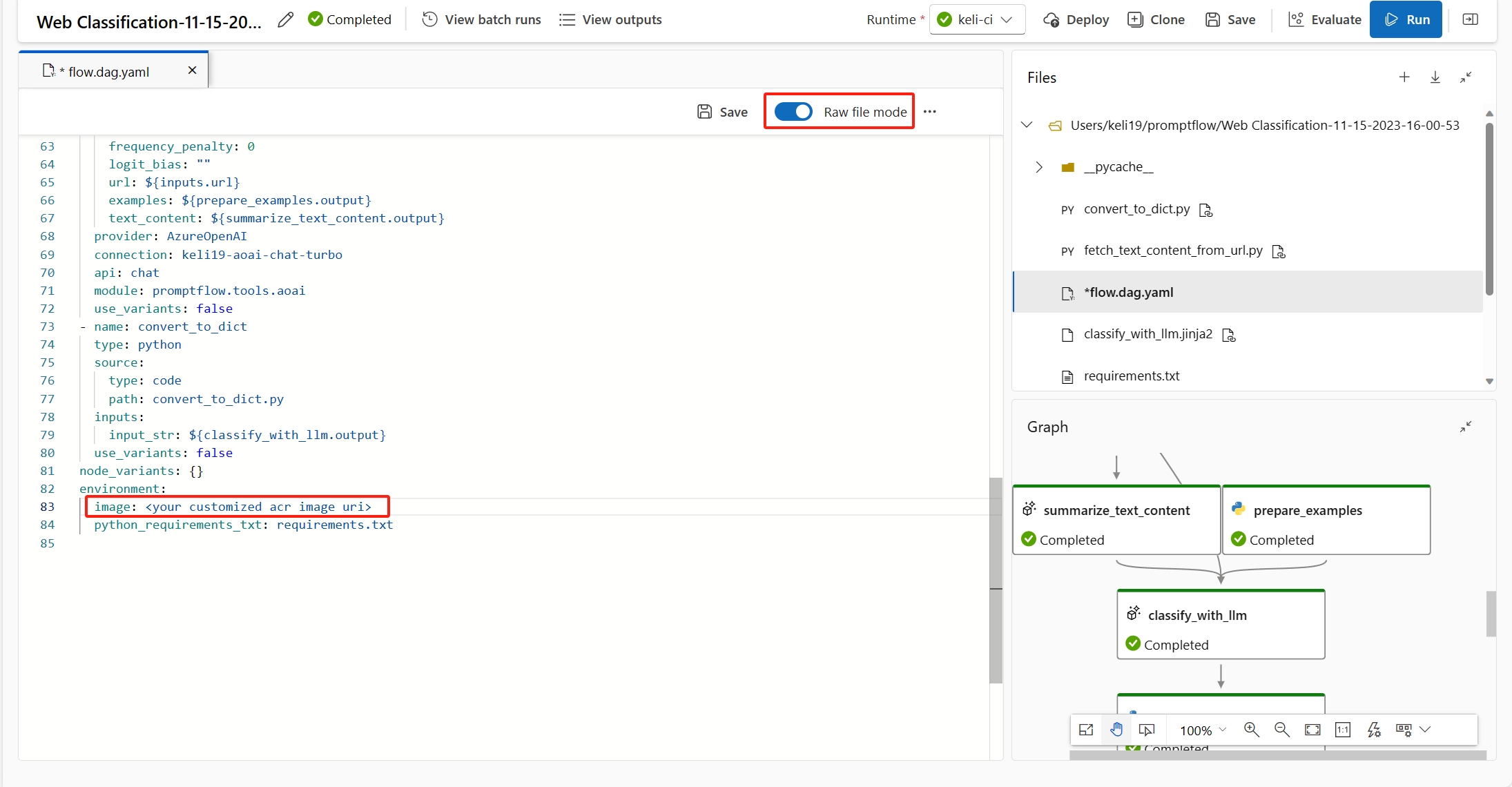
可以在流文件夹的根文件夹中找到
requirements.txt,并在其中添加依赖项。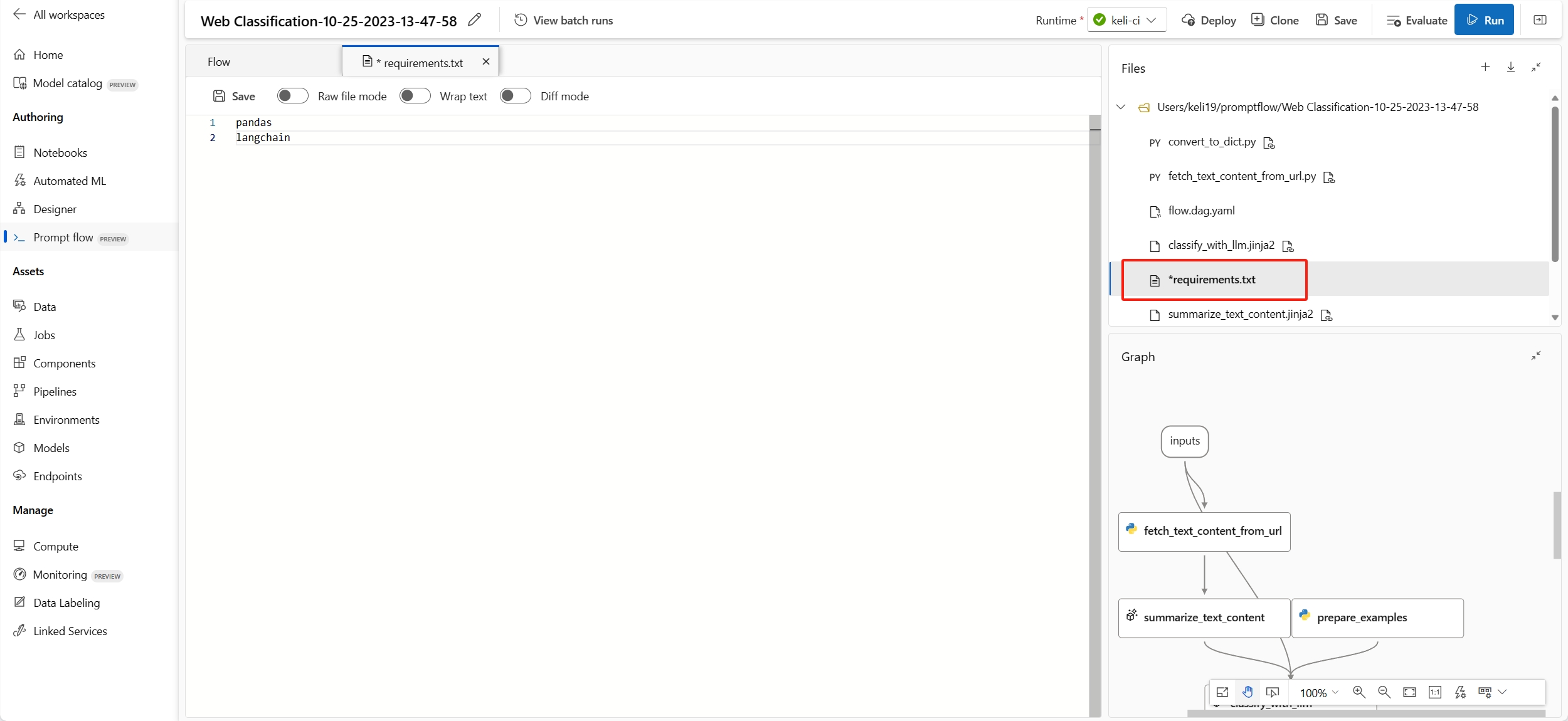

使用自定义环境
还可以创建自定义环境并将其用于部署。
注意
自定义环境必须满足以下要求:
- 必须基于提示流基础映像
mcr.microsoft.com/azureml/promptflow/promptflow-runtime-stable:<newest_version>创建 docker 映像。 可以在这里找到最新版本。 - 环境定义必须包括
inference_config。
以下是自定义环境定义的示例。
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
通过启用 Application Insights 诊断来开启跟踪(预览)
如果启用此功能,推理期间的跟踪数据和系统指标(如令牌计数、流延迟、流请求等)将收集到工作区链接的 Application Insights 中。 有关详细信息,请参阅提供跟踪数据和指标的提示流。
如果你要指定非工作区链接的 Application Insights,可以通过 CLI 进行配置。
高级设置 - 输出和连接
在此步骤中,你可以查看所有流输出,并指定将包含在所部署终结点的响应中的输出。 默认情况下,选择所有流输出。
还可指定终结点在执行推理时使用的连接。 默认情况下,它们从流程继承。
配置并查看上述所有步骤后,可以选择“查看 + 创建”以完成创建。
注意
终结点创建过程预计需要大约 15 分钟以上,因为此过程包含多个阶段,其中包括创建终结点、注册模型、创建部署等。
你可以通过提示流程部署启动的通知来了解部署创建的进度。

向终结点授予权限
重要
仅向特定Azure资源的 Owner 启用授予权限(添加角色分配)。 可能需要向 IT 管理员寻求帮助。 建议在创建部署之前向用户分配的标识授予角色。 授予的权限可能需要超过 15 分钟才能生效。
可以按照以下步骤在Azure门户 UI 中授予所有权限。
选择“访问控制”,然后选择“添加角色分配”。
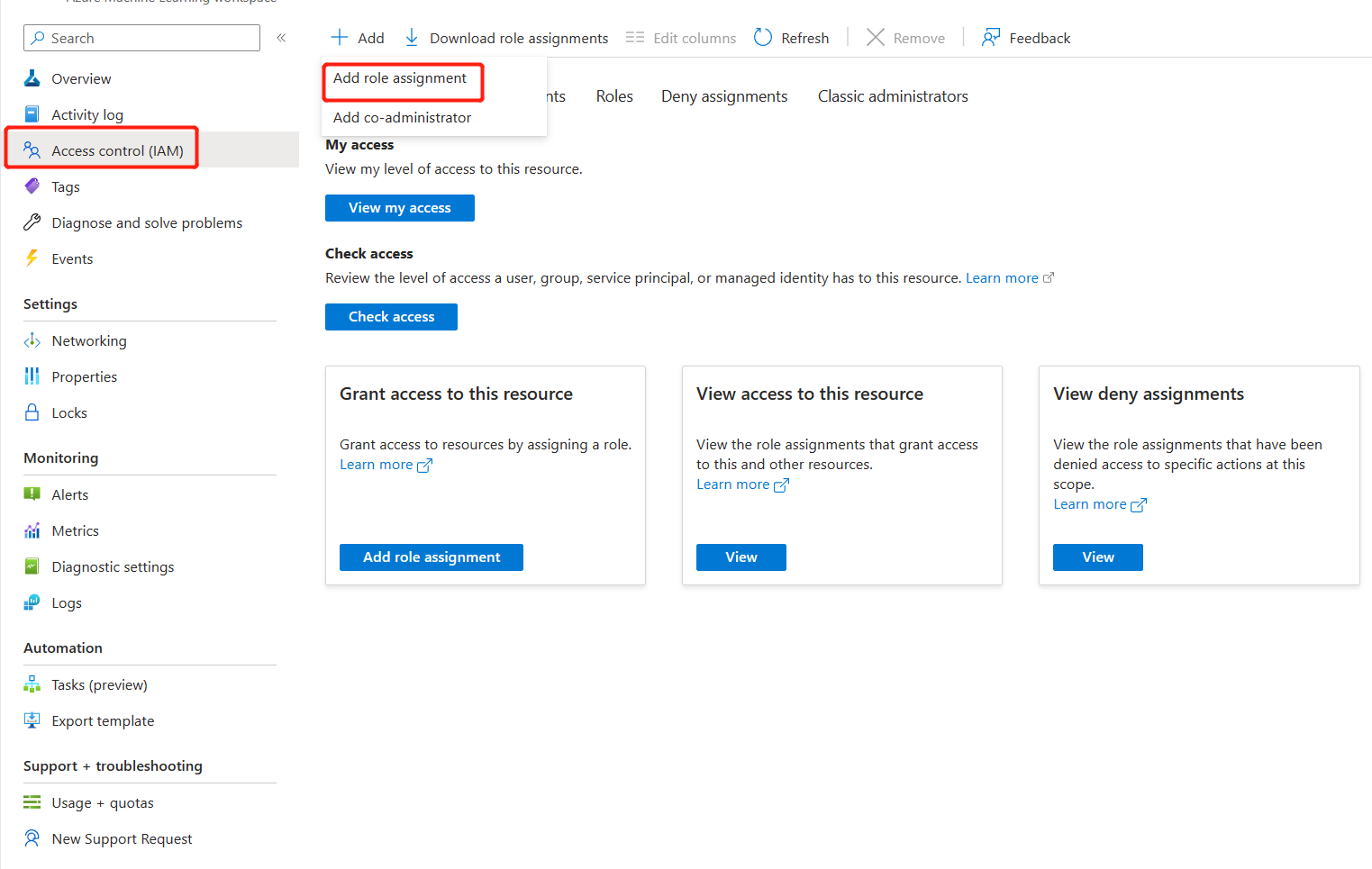
选择 Azure 机器学习工作区连接密钥读取器,然后转到 下一步。
注意
Azure Machine Learning工作区连接机密读取者是一个内置角色,有权获取工作区连接。
如果要使用自定义角色,请确保自定义角色具有“Microsoft.MachineLearningServices/workspaces/connections/listsecrets/action”权限。 详细了解如何创建自定义角色。
选择“托管标识”,然后选择成员。
对于系统分配的标识,在系统分配的托管身份下选择机器学习在线端点,然后按端点名称进行搜索。
对于“用户分配的标识”,请选择“用户分配的托管标识”,然后按标识名称进行搜索。
对于用户分配的标识,还需要向工作区容器注册表和存储帐户授予权限。 可以在Azure门户中的工作区概述页中找到容器注册表和存储帐户。
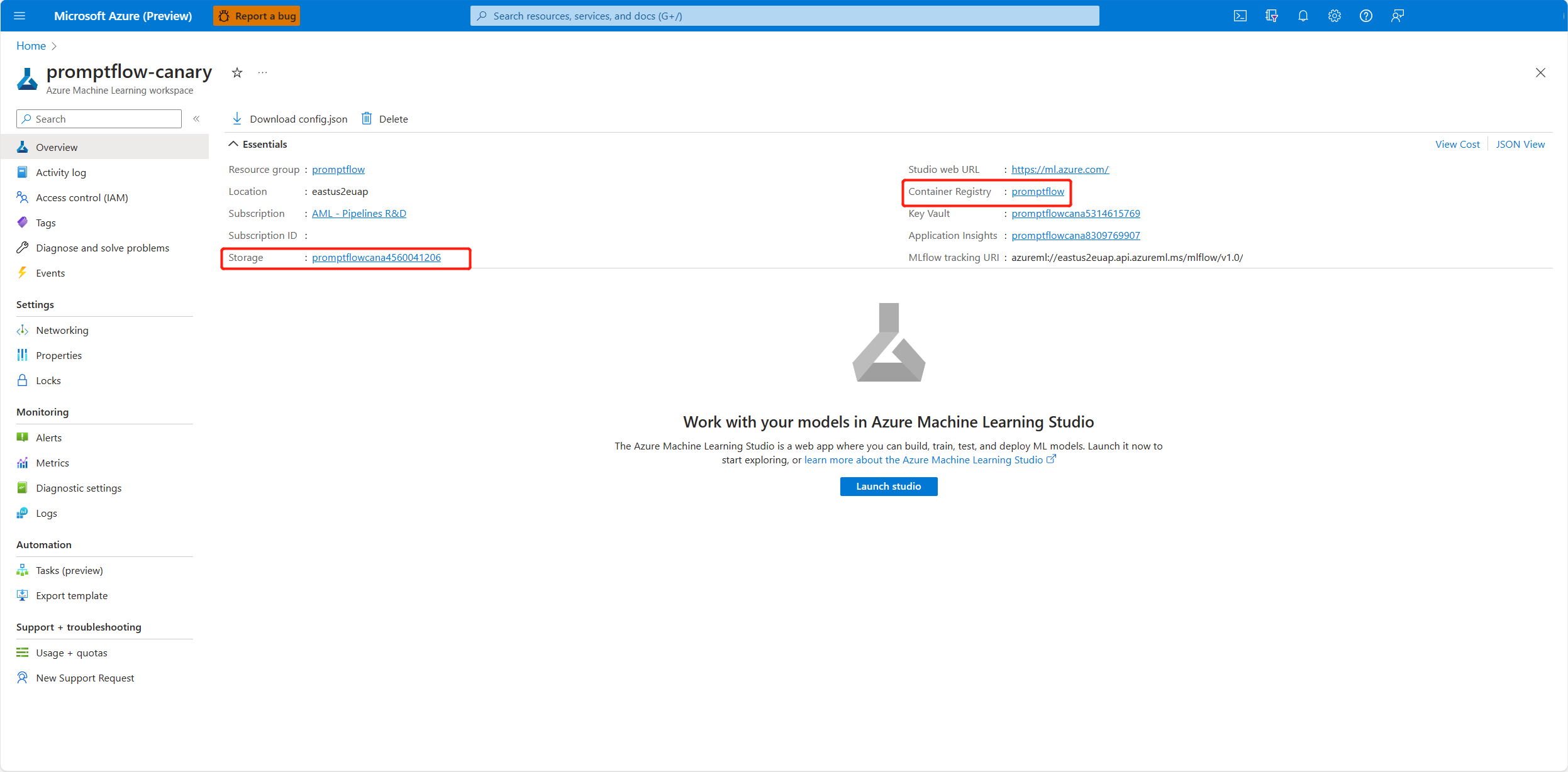
转到“工作区容器注册表概述”页,选择“访问控制”,选择“添加角色分配”,将“ACR 拉取 | 拉取容器映像”分配给终结点标识。
转到工作区默认存储概述页面,选择“访问控制”,然后选择“添加角色分配”,将“存储 Blob 数据读取者”角色分配给端点标识。
(可选)对于用户分配的身份,如果你要监视与终结点相关的指标(例如 CPU/GPU/磁盘/内存利用率),则还需要向该身份授予“工作区指标写入者”角色。


检查终结点的状态
完成部署向导后,将会有通知。 成功创建终结点和部署后,您可以在通知中选择“部署详细信息”以进入“终结点详细信息”页面。
也可以直接转到工作室中的“终结点”页,检查部署的终结点的状态。

使用示例数据测试终结点
在“终结点详细信息”页中,切换到“测试”选项卡。
可输入值并选择“测试”按钮。
测试结果如下所示:

测试从聊天流部署的端点
对于从聊天流部署的终结点,可以在沉浸式聊天窗口中对其进行测试。

在聊天流开发过程中设置了 chat_input。 可以在输入框中输入 chat_input 消息。 除 以外,右侧的“输入”面板还可用于指定其他输入的值。 详细了解如何开发聊天流。
调用终结点
在“终结点详细信息”页面中,切换到“使用”选项卡。在这里,您可以找到用于访问终结点的 REST 终结点和密钥/令牌。 还有示例代码供您使用不同编程语言来调用该端点。
请注意,需要根据流输入填充数据值。 以 Web 分类文中使用的示例流为例,需要在示例使用代码中指定 data = {"url": "<the_url_to_be_classified>"} 并填充密钥或令牌。

监视终结点
使用Azure Monitor查看托管联机终结点的常见指标(可选)
可以查看联机终结点及其部署的各种指标(请求数、请求延迟、网络字节数、CPU/GPU/磁盘/内存利用率等),方法是在工作室中查看终结点的详细信息页中的链接。 通过以下链接,可以访问终结点或部署Azure门户中的确切指标页。
注意
如果为终结点指定用户分配的标识,请确保已为用户分配的标识分配了 Workspace 指标编写器Azure Machine Learning Workspace。 否则,终结点将无法记录指标。

有关如何查看联机终结点指标的详细信息,请参阅监视联机终结点。
查看提示流终结点特定的指标和跟踪数据(可选)
如果在 UI 部署向导中启用Application Insights 诊断,跟踪数据和与提示流相关的特定指标将被收集到与工作区链接的 Application Insights 中。 请参阅有关为部署启用跟踪的详细信息。
排查从提示流部署的终结点的问题
缺少执行操作“Microsoft.MachineLearningService/workspaces/datastores/read”的授权。
如果流包含索引查找工具,部署流后,终结点需要访问工作区数据存储来读取 MLIndex yaml 文件或包含区块和嵌入的 FAISS 文件夹。 因此,需要手动授予终结点标识权限才能执行此操作。
可以在工作区范围内授予终结点标识AzureML Data Scientist,也可以授予包含“MachineLearningService/workspace/datastore/reader”操作的自定义角色。
驱动程序缺失错误
如果使用自定义环境部署流并遇到以下错误,可能是因为没有在自定义环境定义中指定 inference_config。
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
有 2 种方法可以修复此错误。
(建议)可以在自定义环境详细信息页面中找到容器映像 uri,并将其设置为 flow.dag.yaml 文件中的流基础映像。 在 UI 中部署流时,只需选择“使用当前流定义的环境”,后端服务将基于此基础映像和
requirement.txt为部署创建自定义环境。 了解有关流定义中指定的环境的详细信息。
可以通过在自定义环境定义中添加
inference_config来修复此错误。 了解有关如何使用自定义环境的更多信息。以下是自定义环境定义的示例。

$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
模型响应耗时太长
有时,你可能会注意到部署需要很长时间才能做出响应。 有几个可能的因素会导致这种情况发生。
- 模型不够强大(例如,可以考虑使用比 text-ada 更强大的 gpt)
- 索引查询未优化且耗时过长
- 流有许多要处理的步骤
考虑根据上述考虑因素优化终结点以提高模型的性能。
无法提取部署架构
部署终结点后,想要在终结点详细信息页的“测试”选项卡中进行测试,如果“测试”选项卡显示“无法提取部署架构(如下所示),可以尝试以下 2 种方法来缓解此问题:

- 请确保对终结点标识已授予正确权限。 详细了解为终结点标识授予权限的方法。
拒绝访问工作区机密列表
如果遇到“拒绝访问以列出工作区机密”之类的错误,请检查是否已授予对终结点标识的正确权限。 详细了解为终结点标识授予权限的方法。
清理资源
如果在完成此教程后你不打算使用终结点,则应该删除该终结点。
注意
完全删除可能需要大约 20 分钟。