本文解答了有关提示流用法的常见问题。
流创作相关问题
更新流以实现代码优先体验时,发生“找不到包工具”错误
当更新流以获得代码优先体验时,如果流使用 Faiss 索引查找、矢量索引查找、矢量数据库查找或内容安全(文本)工具,则可能会遇到以下错误消息:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
若要解决该问题,你有两个选择:
选项 1
将计算会话更新到最新的基础映像版本。
选择“原始文件模式”以切换到原始代码视图。 然后打开 flow.dag.yaml 文件。

更新工具名称。
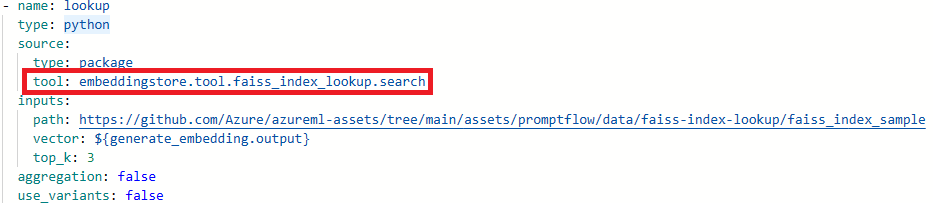
工具 新工具名称 Faiss 索引查找 promptflow_vectordb.tool.faiss_index_lookup.FaissIndexLookup.search 矢量索引查找 promptflow_vectordb.tool.vector_index_lookup.VectorIndexLookup.search 矢量数据库查找 promptflow_vectordb.tool.vector_db_lookup.VectorDBLookup.search Content Safety(文本) content_safety_text.tools.content_safety_text_tool.analyze_text 保存 flow.dag.yaml 文件。
方法 2
- 将计算会话更新到最新的基础映像版本
- 删除旧工具并重新创建新工具。
“没有此类文件或目录”错误
提示流依赖于文件共享存储来保存流的快照。 如果文件共享存储出现问题,可能会遇到以下问题。 下面是可以尝试的一些解决方法:
如果使用专用存储帐户,请参阅提示流中的网络隔离,以确保工作区可以访问存储帐户。
如果启用了存储帐户用于公共访问,请检查工作区中是否存在名为
workspaceworkingdirectory的数据存储。 它应该是文件共享类型。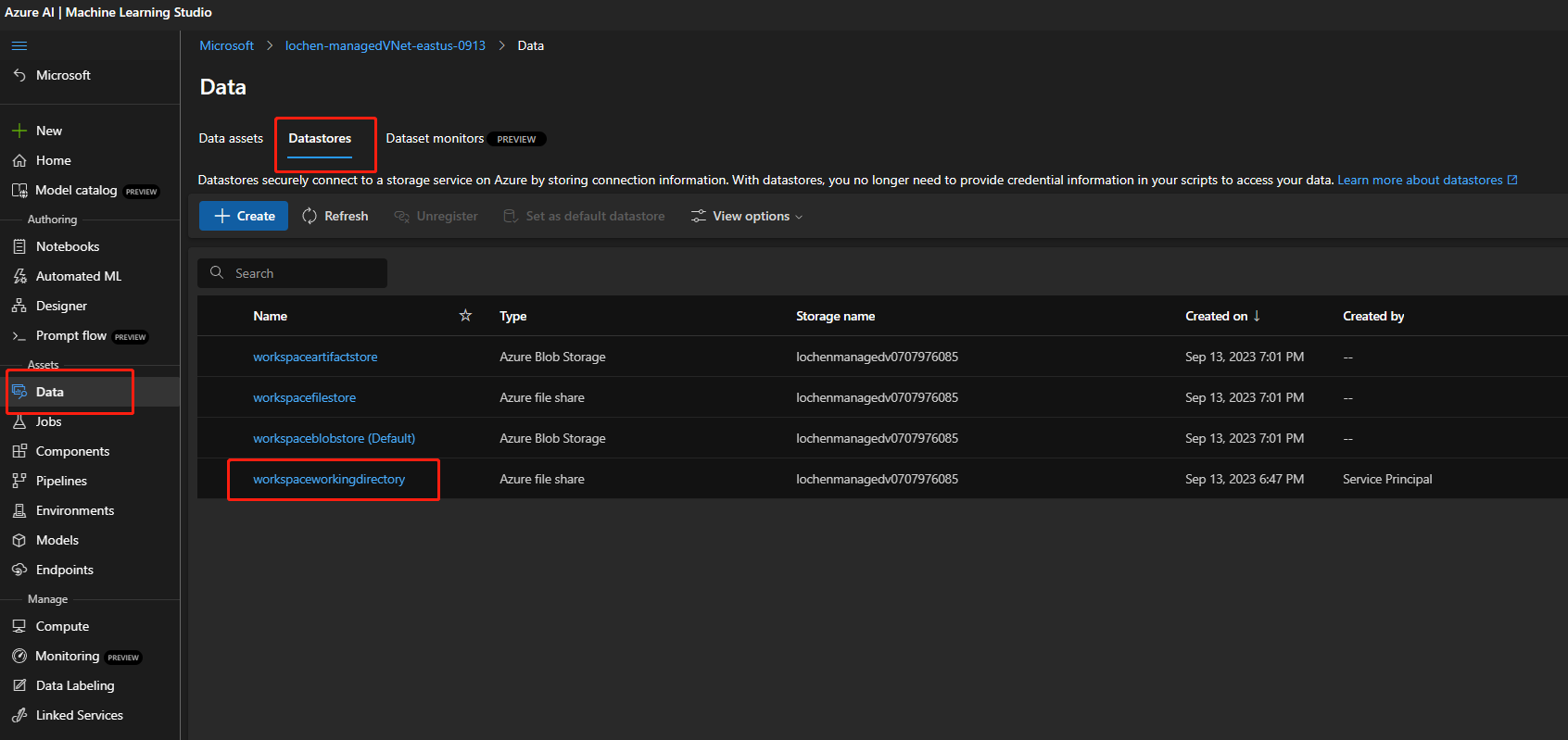

缺少流

此问题有几个可能的原因:
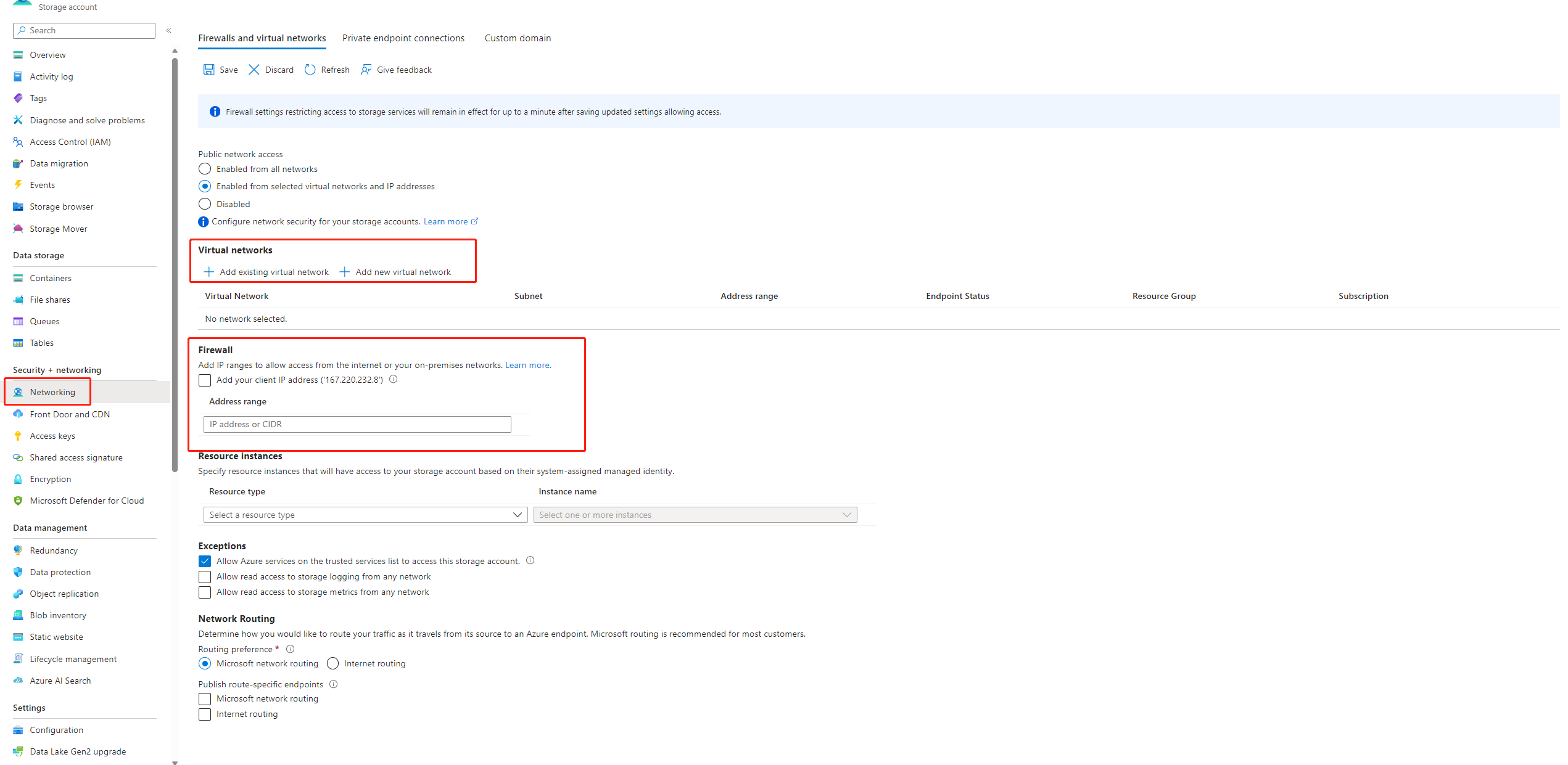
如果禁用了对存储帐户的公共访问,则必须通过将 IP 添加到存储防火墙或通过具有连接到存储帐户的专用终结点的虚拟网络来启用访问以确保访问。
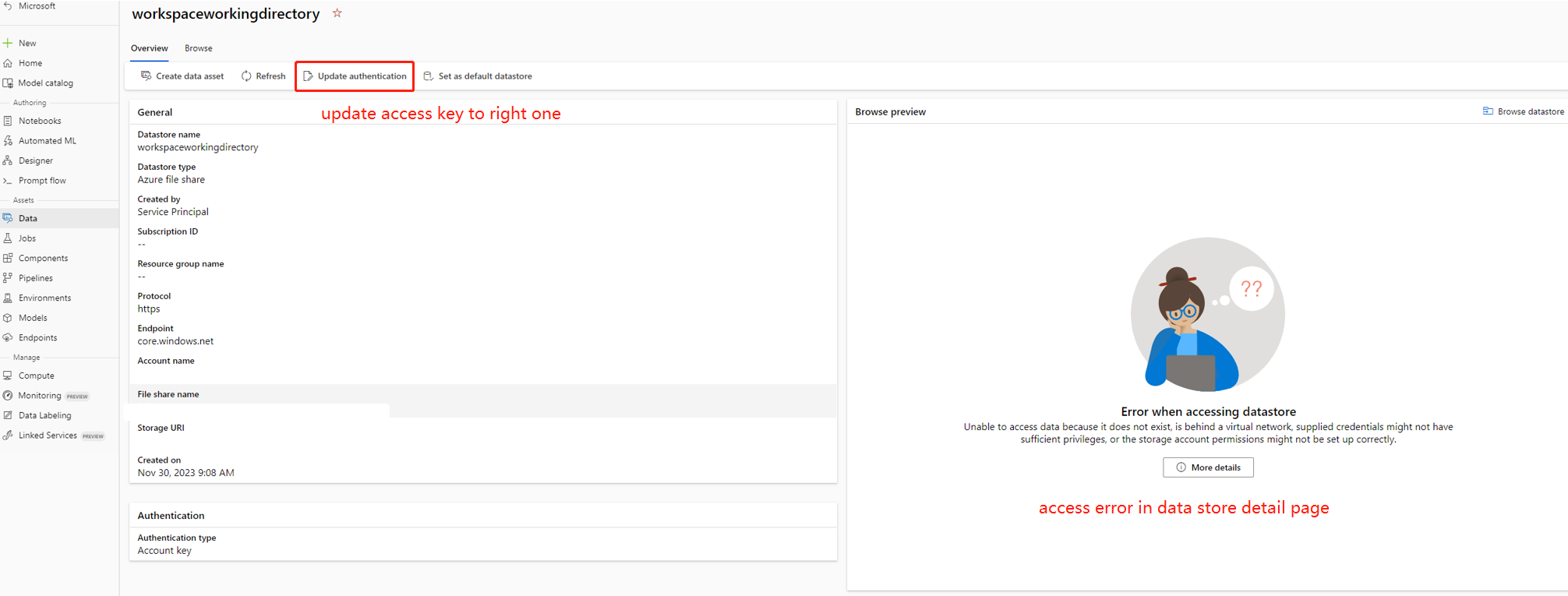
在某些情况下,数据存储中的帐户密钥与存储帐户不同步,可以尝试更新数据存储详细信息页中的帐户密钥以解决此问题。
如果使用 Microsoft Foundry,存储帐户需要设置 CORS 以允许 Foundry 访问存储帐户,否则会看到流缺失问题。 可以将以下 CORS 设置添加到存储帐户以解决此问题。
- 转到存储帐户页,选择
Resource sharing (CORS)下的“settings”,然后选择“File service”选项卡。 - 允许的源:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - 允许的方法:
DELETE, GET, HEAD, POST, OPTIONS, PUT
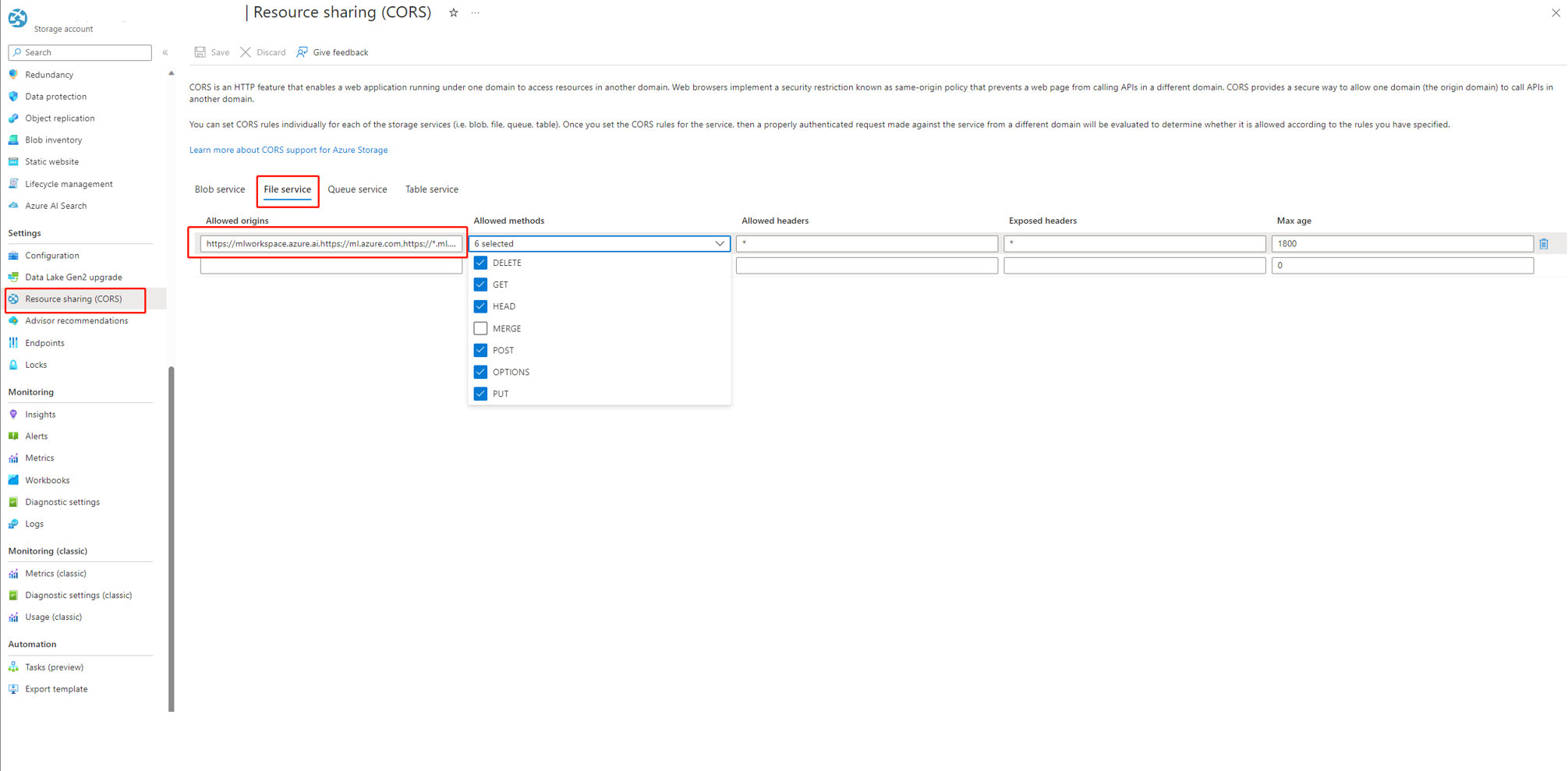
- 转到存储帐户页,选择



计算会话相关问题
运行失败,因为“没有名为 xxx 的模块”
此类与计算会话相关的错误缺少所需的包。 如果使用的是默认环境,请确保计算会话的映像使用的是最新版本。 如果使用的是自定义基础映像,请确保在 docker 上下文中安装了所有所需的包。 有关详细信息,请参阅为计算会话自定义基础映像。
在何处查找计算会话使用的无服务器实例?
可以在计算页下的“计算会话列表”选项卡中查看计算会话使用的无服务器实例。 详细了解如何管理无服务器实例。
使用自定义基础映像时计算会话失败
使用 requirements.txt 或自定义基础映像时计算会话启动失败
计算会话支持使用 requirements.txt 或 flow.dag.yaml 中的自定义基础映像以自定义映像。 建议对常见情况使用 requirements.txt,这将使用 pip install -r requirements.txt 安装包。 如果你不仅仅只依赖 python 包,则需要遵循自定义基础映像以在提示流基础映像的基础上创建新的映像。 然后,在 flow.dag.yaml 中使用它。 详细了解如何在计算会话中指定基础映像。
- 不能使用任意基础映像来创建计算会话,需要使用提示流提供的基础映像。
- 请勿在
promptflow中固定promptflow-tools和requirements.txt的版本,因为我们已将它们包含在基础映像中。 使用旧版promptflow和promptflow-tools可能会导致意外行为。
流运行相关问题
如何查找 LLM 工具的原始输入和输出以进一步调查?
在提示流中,在成功运行的流页面和运行详细信息页面上,可以在输出部分找到 LLM 工具的原始输入和输出。 选择 view full output 按钮以查看完整输出。

Trace 部分包括对 LLM 工具的每个请求和响应。 可以检查发送到 LLM 模型的原始消息和 LLM 模型的原始响应。

确定哪个节点消耗的时间最多
检查计算会话日志。
尝试查找以下警告日志格式:
{node_name} 已运行 {duration} 秒。
例如:
案例 1:Python 脚本节点运行时间过长。

在这种情况下,你会发现
PythonScriptNode运行时间过长(大约 300 秒)。 然后,可以检查该节点详细信息,查看问题出在哪里。案例 2:LLM 节点长时间运行。
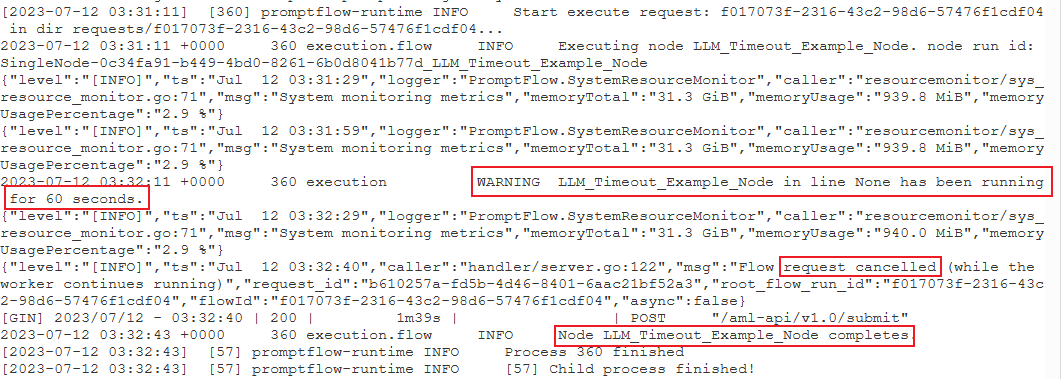
在这种情况下,如果在日志中找到消息
request canceled,可能是因为 OpenAI API 调用花费的时间太长,超出了超时限制。OpenAI API 超时可能是由网络问题或需要更多处理时间的复杂请求引起的。 有关详细信息,请参阅 OpenAI API 超时。
请等待几秒钟,然后重试请求。 此操作通常可以解决任何网络问题。
如果重试不起作用,请检查是否使用了较长的上下文模型,例如
gpt-4-32k,并为max_tokens设置了较大的值。 如果是这样的话,这是预期的行为,因为提示可能会生成长响应,所需时间超过交互模式的阈值上限。 在这种情况下,建议尝试Bulk test,因为此模式没有超时设置。
如果在日志中找不到任何内容表明它是特定的节点问题:
- 请与提示流团队 (promptflow-eng) 联系并提供日志。 我们会努力找出根本原因。


流部署相关问题
没有授权,无法执行操作“Microsoft.MachineLearningService/workspaces/datastores/read”
如果流包含索引查找工具,部署流后,终结点需要访问工作区数据存储来读取 MLIndex yaml 文件或包含区块和嵌入的 FAISS 文件夹。 因此,需要手动授予终结点标识权限才能执行此操作。
可以在工作区范围内授予终结点标识“AzureML 数据科学家”,也可以授予包含“MachineLearningService/workspace/datastore/reader”操作的自定义角色。
使用终结点时的上游请求超时问题
如果使用 CLI 或 SDK 部署流,可能会遇到超时错误。
request_timeout_ms 默认为 5000。 最多可以指定为 5 分钟,即 300000 毫秒。 下面的示例演示如何在部署 yaml 文件中指定请求超时。 若要了解详细信息,请参阅部署架构。
request_settings:
request_timeout_ms: 300000
OpenAI API 命中身份验证错误
如果重新生成 Azure OpenAI 密钥,并手动更新在提示流中使用的连接,在重新生成密钥之前调用现有终结点时,可能会遇到“未授权。 访问令牌缺失、无效、访问群体不正确或已过期”等错误。
这是因为终结点/部署中使用的连接不会自动更新。 部署中密钥或机密的任何更改都应通过手动更新来完成,目的是避免由于无意脱机操作而影响联机生产部署。
- 如果终结点部署在工作室 UI 中,则只需使用相同的部署名称将流重新部署到现有终结点。
- 如果使用 SDK 或 CLI 部署终结点,则需要对部署定义进行一些修改,例如添加虚拟环境变量,然后使用
az ml online-deployment update更新部署。
提示流部署中的漏洞问题
对于提示流运行时相关的漏洞,以下是有助于缓解的方法:
- 更新流文件夹中 requirements.txt 中的依赖项包。
- 如果使用流的自定义基础映像,则需要将提示流运行时更新为最新版本,并重新生成基础映像,然后重新部署该流。
对于托管联机部署的其他漏洞,Azure 机器学习每月修复问题。
“MissingDriverProgram 错误”或“在请求中找不到驱动程序程序”
如果部署流并遇到以下错误,可能与部署环境相关。
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
可通过两种方法解决此问题。
(建议)可以在自定义环境详细信息页面中找到容器映像 uri,并将其设置为 flow.dag.yaml 文件中的流基础映像。 在 UI 中部署流时,只需选择“使用当前流定义的环境”,后端服务将基于此基础映像和
requirement.txt为部署创建自定义环境。 了解有关流定义中指定的环境的详细信息。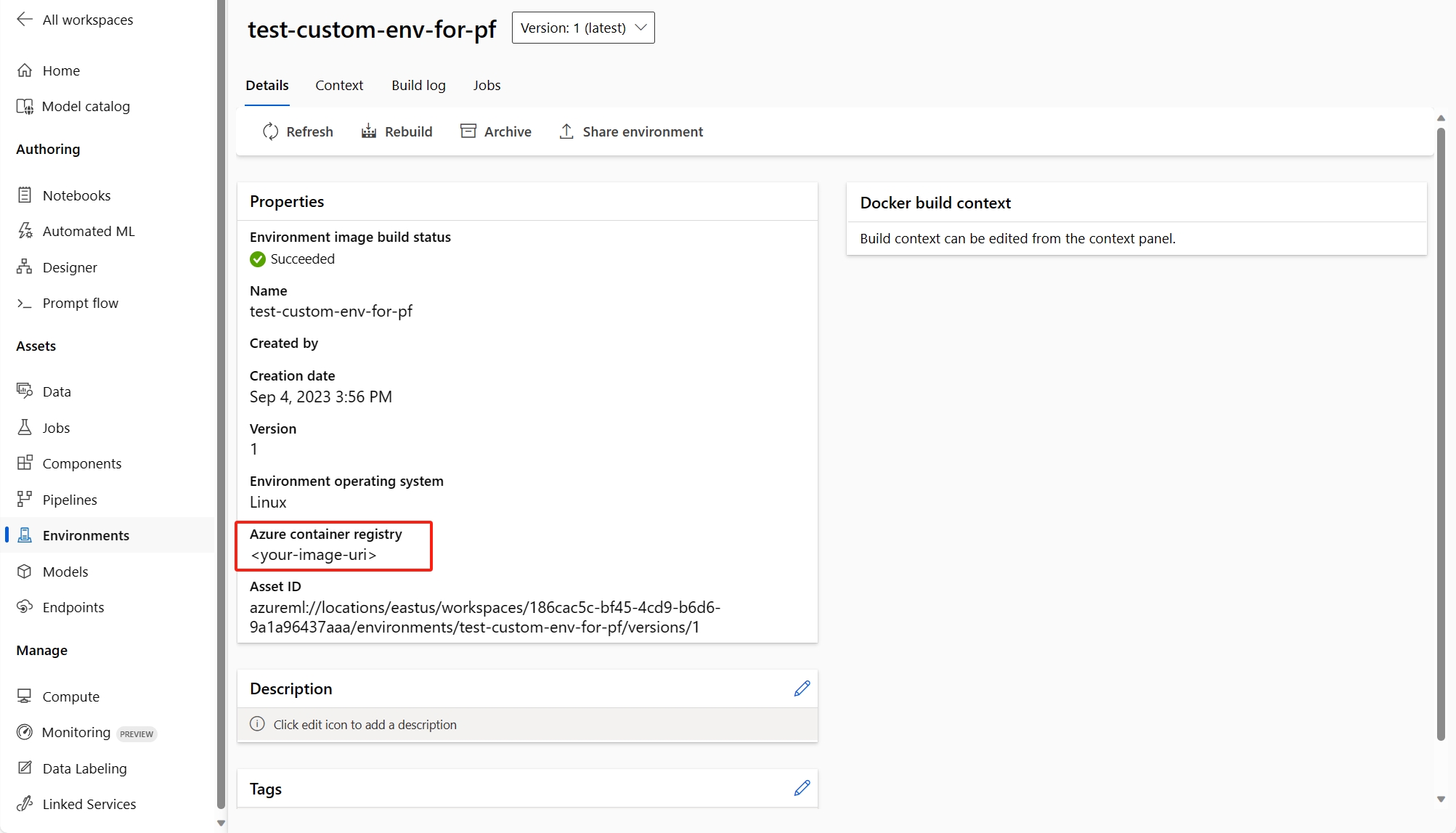
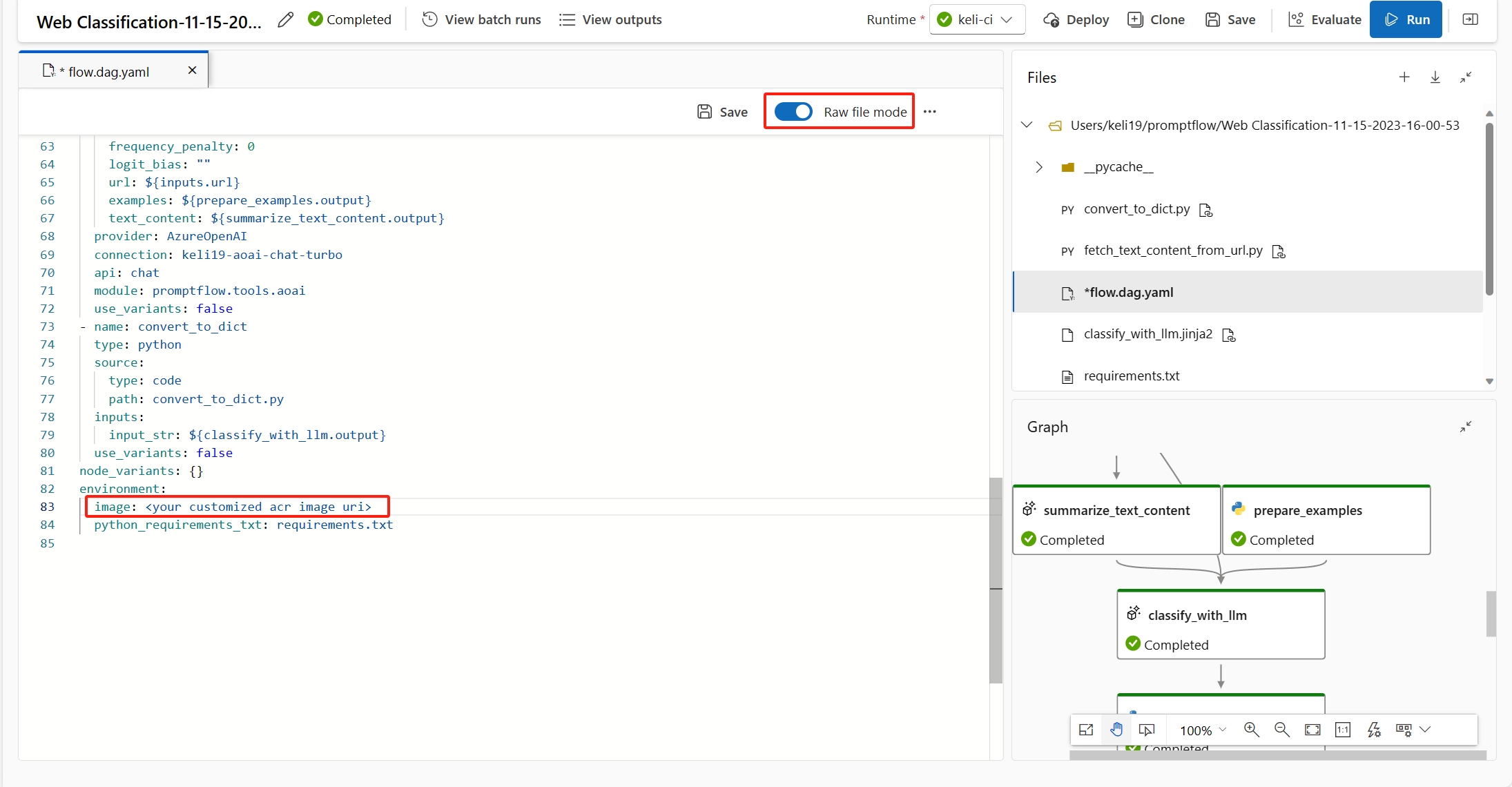
可以通过在自定义环境定义中添加
inference_config来修复此错误。以下是自定义环境定义的示例。


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
模型响应耗时太长
有时,你可能会注意到部署需要很长时间才能做出响应。 有几个可能的因素会导致这种情况发生。
- 流中使用的模型不够强大(例如:使用 GPT 3.5 而不是 text-ada)
- 索引查询未优化,且耗时过长
- 流有许多要处理的步骤
考虑根据上述考虑因素优化终结点以提高模型的性能。
无法提取部署架构
部署终结点后,想要在终结点详细信息页的“测试”选项卡中进行测试,如果“测试”选项卡显示“无法提取部署架构”(如下所示),可以尝试以下两种方法来缓解此问题:

- 请确保已授予对终结点标识的正确权限。 详细了解如何授予对终结点标识的权限。
- 这可能是因为你在旧版本的运行时中运行了流,然后部署了流,因此部署也使用了旧版本中的运行时环境。 若要更新运行时,按照更新 UI 上的运行时,并在最新的运行时中重新运行流,然后再次部署流。
拒绝访问以列出工作区机密
如果遇到“拒绝访问以列出工作区机密”之类的错误,请检查是否已授予对终结点标识的正确权限。 详细了解如何授予对终结点标识的权限。
身份验证和标识相关问题
如何在提示流中使用无凭据数据存储?
若要在 Foundry 门户中使用无凭据存储,需要基本执行以下作:
- 请将数据存储身份验证类型更改为“无”。
- 授予项目 MSI 和用户 blob/文件数据参与者对存储的权限。
将数据存储的身份验证类型更改为“无”
可以遵循基于标识的数据身份验证部分来实现无凭据数据存储。
需要将数据存储的身份验证类型更改为 None,这代表基于 meid_token 的身份验证。可以从数据存储详细信息页或 CLI/SDK 进行更改:https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

对于基于 Blob 的数据存储,可以更改身份验证类型,还允许工作区 MSI 访问存储帐户。

对于基于文件共享的数据存储,只能更改身份验证类型。

向用户标识或托管标识授予权限
要在提示流中使用无凭据数据存储,需要为用户标识或托管标识授予足够的权限,以便访问数据存储。
- 确保工作区系统分配的托管标识在存储帐户上具有
Storage Blob Data Contributor和Storage File Data Privileged Contributor,至少需要读/写(更好的还包括删除)权限。 - 如果在提示流中使用用户标识这一默认选项,则需要确保用户标识在存储帐户上具有以下角色:
- 存储帐户上的
Storage Blob Data Contributor,至少需要读取/写入(最好也包括删除)权限。 - 存储帐户上的
Storage File Data Privileged Contributor,至少需要读取/写入(最好也包括删除)权限。
- 存储帐户上的
- 如果使用用户分配的托管标识,则需要确保托管标识在存储帐户上具有以下角色:
- 存储帐户上的
Storage Blob Data Contributor,至少需要读取/写入(最好也包括删除)权限。 - 存储帐户上的
Storage File Data Privileged Contributor,至少需要读取/写入(最好也包括删除)权限。 - 同时,如果要使用提示流来编写和测试流,则需要至少为存储帐户分配用户标识
Storage Blob Data Read角色。
- 存储帐户上的
- 如果仍无法查看流详细信息页,且首次使用提示流的时间早于 2024-01-01,则需要将工作区 MSI 作为
Storage Table Data Contributor授予和工作区关联的存储帐户。