适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure 机器学习与 Azure Synapse Analytics 的集成实现了对分布式计算功能(由 Azure Synaps 提供支持)的轻松访问,可以在 Azure 机器学习上缩放 Apache Spark 作业。
在本文中,你会了解如何通过几个简单的步骤,使用 Azure 机器学习无服务器 Spark 计算、Azure Data Lake Storage (ADLS) Gen 2 存储帐户和用户标识传递来提交 Spark 作业。
有关 Azure 机器学习中 Apache Spark 概念的详细信息,请访问此资源。
先决条件
- 一个 Azure 订阅;如果没有 Azure 订阅,请在开始前创建试用版订阅。
- Azure 机器学习工作区。 有关详细信息,请访问创建工作区资源。
- Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 有关详细信息,请访问创建 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。
- 创建 Azure 机器学习计算实例。
- 安装 Azure 机器学习 CLI。
在 Azure 存储帐户中添加角色分配
在提交 Apache Spark 作业之前,必须确保输入和输出数据路径是可访问的。 将“参与者”和“存储 Blob 数据参与者”角色分配给已登录用户的用户标识,以启用读取和写入访问权限。
要为用户标识分配适当的角色,请执行以下操作:
打开 Azure 门户。
搜索并选择“存储帐户”服务。

在“存储帐户”页面,从列表中选择 Azure Data Lake Storage (ADLS) Gen 2 存储帐户。 此时会打开显示存储帐户 概述 的页面。
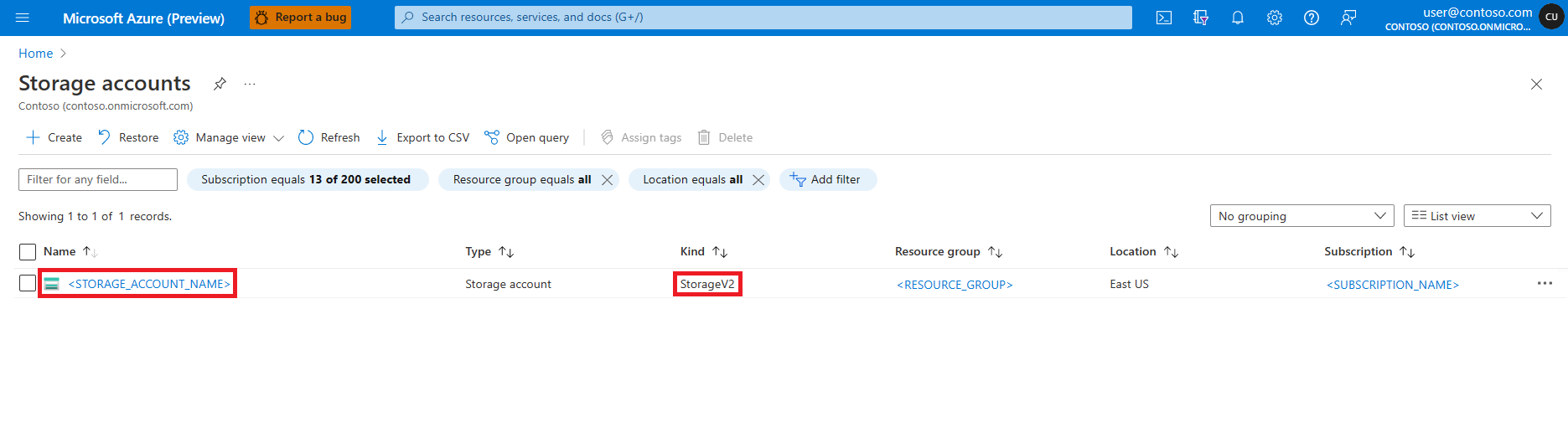
从左窗格中选择“访问控制(标识和访问管理)”。
选择“添加角色分配”。
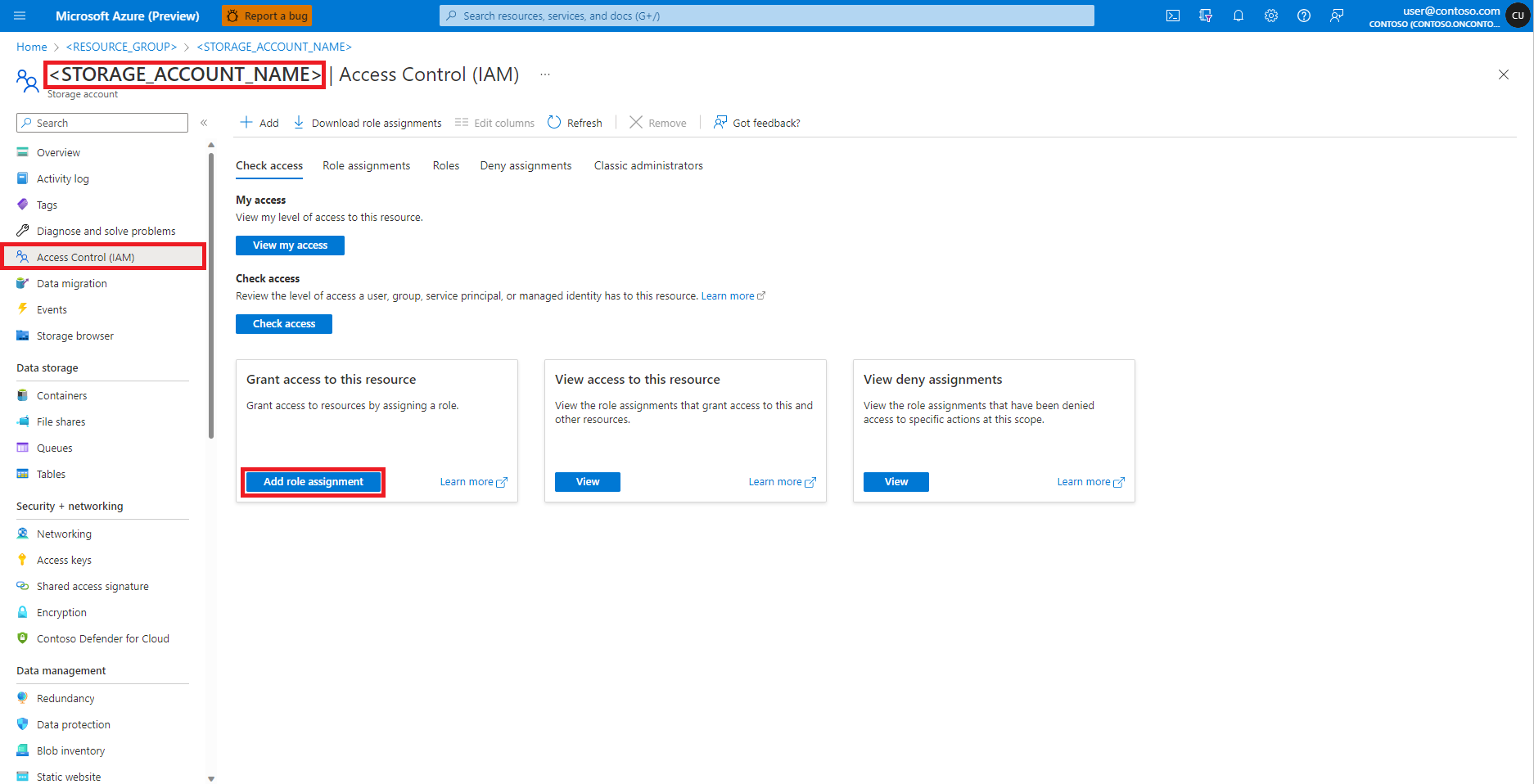
搜索“存储 Blob 数据参与者”角色。
选择“存储 Blob 数据参与者”角色。
选择下一步。
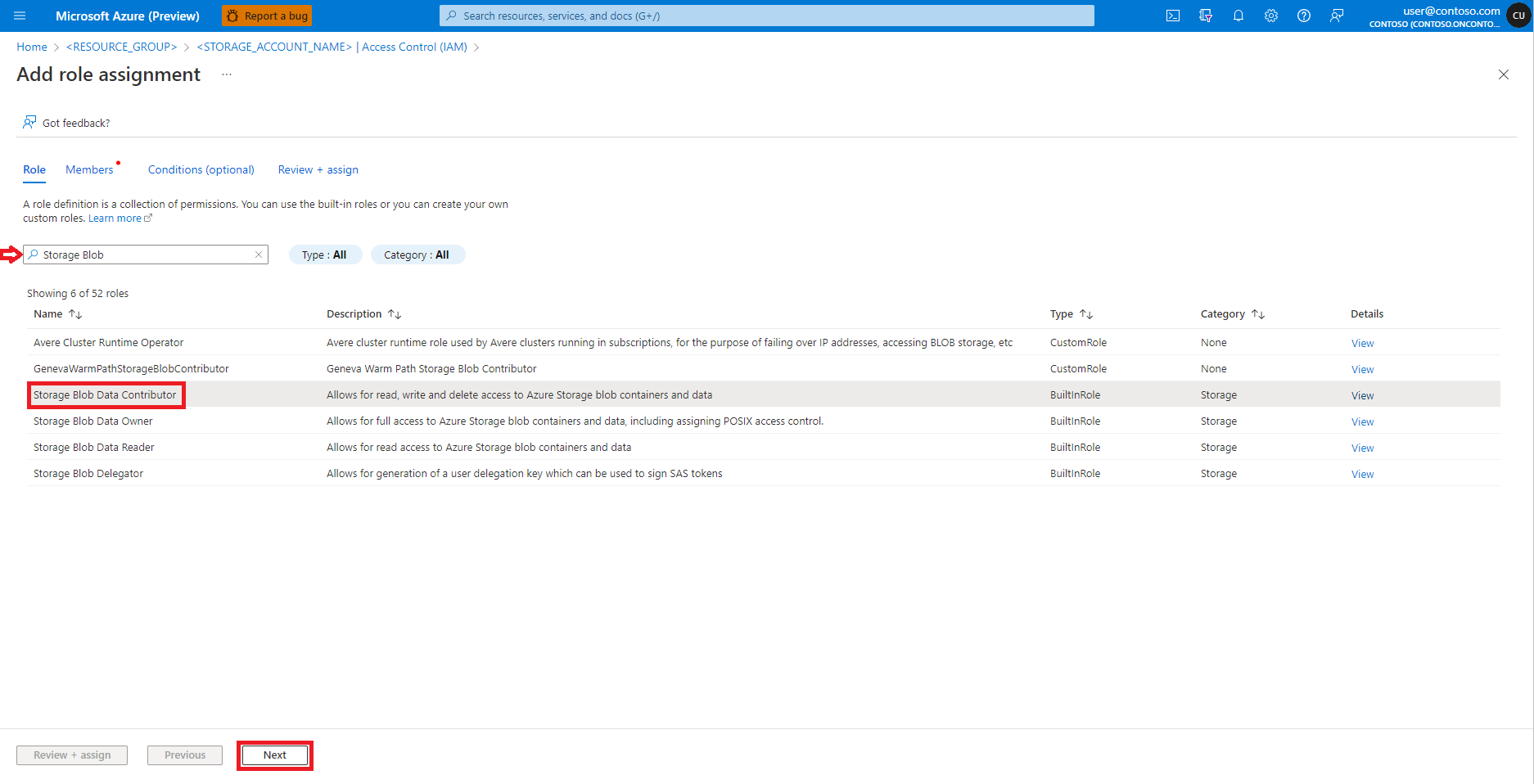
选择“用户、组或服务主体”。
选择“+ 选择成员”。
在“选择”下的文本框中,搜索用户标识。
从列表中选择该用户标识,以便它显示在“所选成员”下。
选择适当的用户标识。
选择下一步。
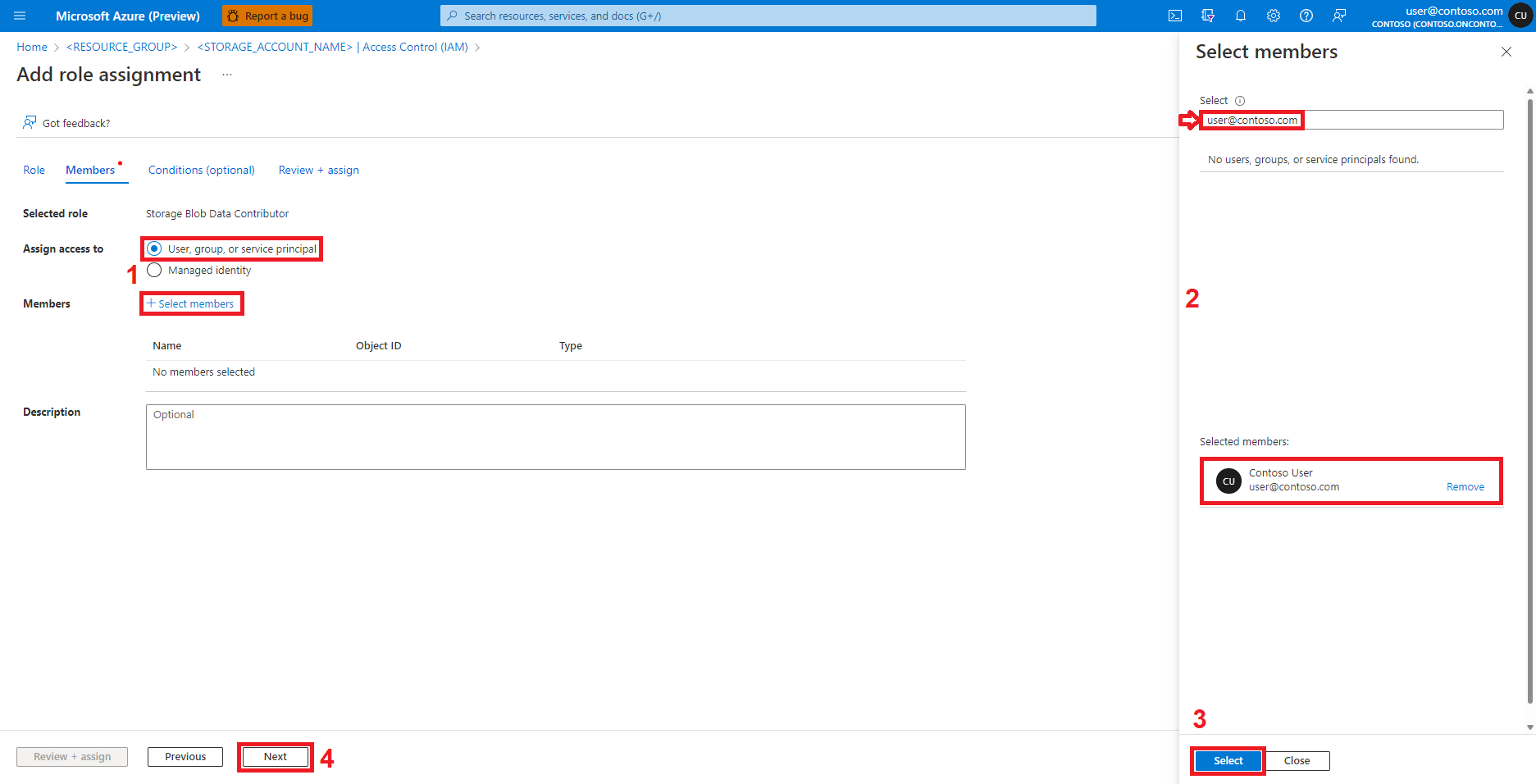
选择“查看 + 分配”。
对“存储 Blob 参与者”角色分配重复执行步骤 2-13。






用户标识分配有相应角色后,Azure Data Lake Storage (ADLS) Gen 2 存储帐户中的数据应立即可供访问。
创建参数化 Python 代码
Spark 作业需要接受参数的 Python 脚本。 要生成此脚本,可以修改通过交互式数据整理开发的 Python 代码。 此处显示了一个示例 Python 脚本:
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
注意
- 此 Python 代码示例使用了
pyspark.pandas,它仅支持 Spark 运行时版本 3.2。 - 请确保将
titanic.py文件上传到名为src的文件夹。src文件夹应位于创建 Python 脚本/笔记本或定义独立 Spark 作业的 YAML 规范文件的同一目录中。
该脚本采用两个参数: --titanic_data 和 --wrangled_data。 这些参数分别传递输入数据路径和输出文件夹。 该脚本使用 titanic.csv 文件(在此处提供)。 将此文件上传到在 Azure Data Lake Storage (ADLS) Gen 2 存储帐户中创建的容器。
提交独立的 Spark 作业
提示
可从以下位置提交 Spark 作业:
- Azure 机器学习计算实例终端。
- 连接到 Azure 机器学习计算实例的 Visual Studio Code 终端。
- 安装了 Azure 机器学习 CLI 的本地计算机。
此示例 YAML 规范显示了一个独立的 Spark 作业。 它使用 Azure 机器学习无服务器 Spark 计算、用户标识传递,以及输入/输出数据 URI,其格式为 abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.chinacloudapi.cn/<PATH_TO_DATA>。 此处,<FILE_SYSTEM_NAME> 与容器名称匹配。
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./src
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.chinacloudapi.cn/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.chinacloudapi.cn/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.2"
在上述 YAML 规范文件中:
-
code属性定义了包含参数化titanic.py文件的文件夹的相对路径。 -
resource属性定义了instance_type和无服务器 Spark 计算使用的 Apache Sparkruntime_version值。 目前支持以下实例类型值:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
显示的 YAML 文件可以在带有 az ml job create 参数的 --file 命令中使用,以创建独立的 Spark 作业,如下所示:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
提示
Azure Synapse 工作区中可能有现有的 Synapse Spark 池。 要使用现有的 Synapse Spark 池,请按照说明 在 Azure 机器学习工作区中附加 Synapse Spark 池。