Azure Database for PostgreSQL 中的业务连续性是指使企业能够面对中断(尤其是计算基础结构)继续运营的机制、策略和过程。 在大多数情况下,Azure Database for PostgreSQL 会处理云环境中可能发生的中断事件,并使应用程序和业务流程保持运行。 但是,有些事件无法自动处理,例如:
- 用户意外删除或更新了表中的某行。
- 地震导致断电和可用性区域或区域暂时性停止运营。
- 修复 bug 或安全问题所需的数据库修补。
Azure Database for PostgreSQL 提供的功能可保护数据,并缓解任务关键型数据库在计划内和计划外停机事件期间的停机时间。 Azure Database for PostgreSQL 基于提供可靠复原和可用性的 Azure 基础结构构建,提供另一种故障保护、解决恢复时间要求并减少数据丢失暴露的业务连续性功能。 在构建应用程序时,应考虑故障容错(恢复时间目标 (RTO))和数据丢失风险(恢复点目标 (RPO))。 例如,与测试数据库相比,业务关键数据库具有更严格的正常运行时间要求。
下表说明了 Azure Database for PostgreSQL 提供的功能。
| 功能 | 说明 | 考虑 |
|---|---|---|
| 自动备份 | Azure Database for PostgreSQL 灵活服务器实例会自动执行数据库文件的每日备份,并持续备份事务日志。 备份可以保留 7 天到 35 天。 可将数据库服务器还原到备份保留期内的任意时间点。 RTO 取决于要还原的数据的大小 + 执行日志恢复的时间。 从几分钟到 12 小时不等。 有关详细信息,请参阅 概念 - 备份和还原。 | 备份数据保留在该区域中。 |
| 区域冗余高可用性 | 可以使用区域冗余高可用性(HA)配置部署 Azure Database for PostgreSQL 灵活服务器实例,其中主服务器和备用服务器部署在区域中的两个不同的可用性区域中。 这种 HA 配置可防止数据库发生区域级故障,还有助于减少计划内和计划外停机事件期间的应用程序停机时间。 在同步模式下,主服务器中的数据将复制到备用副本。 如果主服务器发生任何中断,服务器将自动故障转移到备用副本。 大多数情况下,RTO 应小于 120 秒。 RPO 应为零(无数据丢失)。 有关详细信息,请参阅 概念 - 高可用性。 | 在常规用途和内存优化计算层中受支持。 仅可在提供多个区域的区域中使用。 |
| 同一区域高可用性 | 可以使用同一区域高可用性(HA)配置部署 Azure Database for PostgreSQL 灵活服务器实例,其中主服务器和备用服务器部署在区域中的同一可用性区域中。 这种 HA 配置可防止数据库发生节点级故障,还有助于减少计划内和计划外停机事件期间的应用程序停机时间。 在同步模式下,主服务器中的数据将复制到备用副本。 如果主服务器发生任何中断,服务器将自动故障转移到备用副本。 大多数情况下,RTO 应小于 120 秒。 RPO 应为零(无数据丢失)。 有关详细信息,请参阅 概念 - 高可用性。 | 在常规用途和内存优化计算层中受支持。 |
| 高级托管磁盘 | 数据库文件存储在高度持久且可靠的高级托管存储中。 这提供了数据冗余,在具有自动数据恢复功能的区域中存储三份副本。 有关详细信息,请参阅 托管磁盘文档。 | 存储在可用性区域中的数据。 |
| 区域冗余备份 | 如果区域支持可用性区域,Azure Database for PostgreSQL 灵活服务器实例备份会自动安全地存储在区域中的区域冗余存储中。 在预配了服务器的区域级别故障期间,如果未使用区域冗余配置服务器,你仍可以使用不同区域中的最新还原点来还原数据库。 有关详细信息,请参阅 概念 - 备份和还原。 | 只有在有多个区域可用的区域中才适用。 |
| 异地冗余备份 | Azure Database for PostgreSQL 灵活服务器实例备份将复制到远程区域。 这有助于在主服务器区域故障时进行灾难恢复。 | 此功能目前在选定区域已启用。 根据要还原的数据大小和要执行的恢复量,它需要更长的 RTO 和更高的 RPO。 |
| 只读副本 | 可以部署跨区域只读副本,以保护数据库免受区域级故障的影响。 只读副本使用 PostgreSQL 的物理复制技术进行异步更新,可能与主数据库之间存在延迟。 有关详细信息,请参阅概念 - 只读副本。 | 在常规用途和内存优化计算层中受支持。 |
下表比较了典型工作负荷方案中的 RTO 和 RPO:
| 能力 | 可突发 | 产品 SKU (通用型/内存优化型) |
|---|---|---|
| 从备份执行时间点还原 | 保留期内的任何还原点 RTO - 可变 RPO < 5 分钟 |
保留期内的任何还原点 RTO - 可变 RPO < 5 分钟 |
| 从异地复制的备份执行异地还原 | RTO - 可变 RPO < 1 小时 |
RTO - 可变 RPO < 1 小时 |
| 只读副本 | 不適用 | RTO - 几分钟* RPO - 通常范围为 30 秒到 5 分钟* |
| 高可用性 | 不適用 | RTO < 120 秒 RPO = 0 |
计划内故障事件
下面是一些计划内维护场景。 这些事件通常会导致长达几分钟的故障时间,但不会造成数据丢失。
| 情景 | 过程 |
|---|---|
| 计算缩放(由用户发起) | 在计算缩放操作期间,将允许处于活动状态的检查点完成,客户端连接将排空,所有未提交的事务将取消,存储将分离,然后它会被关闭。 使用缩放的计算配置预配了具有相同数据库服务器名称的新 Azure Database for PostgreSQL 灵活服务器实例。 然后,存储会连接到新服务器,而数据库也会启动,该数据库在接受客户端连接前会根据需要执行恢复。 |
| 扩展存储(由用户启动) | 当启动扩展存储操作时,将允许处于活动状态的检查点完成,客户端连接将排空,所有未提交的事务将取消。 之后,服务器将关闭。 存储将扩展到所需的大小,然后连接到新服务器。 如果需要,在接受客户端连接之前执行恢复。 请注意,不支持对存储大小进行缩减。 |
| 新软件部署(由 Azure 启动) | 新功能的推出或 bug 修复作为服务的计划内维护的一部分自动发生,你可以安排这些活动发生的时间。 有关详细信息,请查看 门户。 |
| 次要版本升级(由 Azure 启动) | Azure Database for PostgreSQL 会自动将数据库服务器修补到 Azure 确定的次要版本。 这在服务的计划内维护过程中发生。 数据库服务器将自动使用新的次要版本进行重启。 有关详细信息,请参阅 文档。 你还可以查看你的门户。 |
将 Azure Database for PostgreSQL 灵活服务器实例配置为 高可用性时,该服务首先对备用服务器执行缩放和维护作。 有关详细信息,请参阅 概念 - 高可用性。
缓解计划外停机
意外中断(如基础硬件故障、网络问题和软件 bug)可能会导致计划外停机。 如果配置了高可用性的数据库服务器意外关闭,则会激活备用副本,客户端可以继续执行其操作。 如果未配置高可用性 (HA),则在尝试重启失败时自动预配新的数据库服务器。 虽然无法避免计划外停机,但 Azure Database for PostgreSQL 无需人工干预即可自动执行恢复作,从而帮助缓解停机时间。
尽管我们不断努力提供高可用性,但有时 Azure Database for PostgreSQL 确实发生中断,导致数据库不可用,从而影响应用程序。 当我们的服务监视检测到导致广泛连接错误、故障或性能问题的问题时,服务会自动声明中断,以随时通知你。
服务中断
在发生 Azure Database for PostgreSQL 灵活服务器实例中断时,可以在以下位置查看与中断相关的更多详细信息:
- Azure 门户横幅:如果确定订阅受到影响,Azure 门户“通知”中将出现服务问题的中断警报。
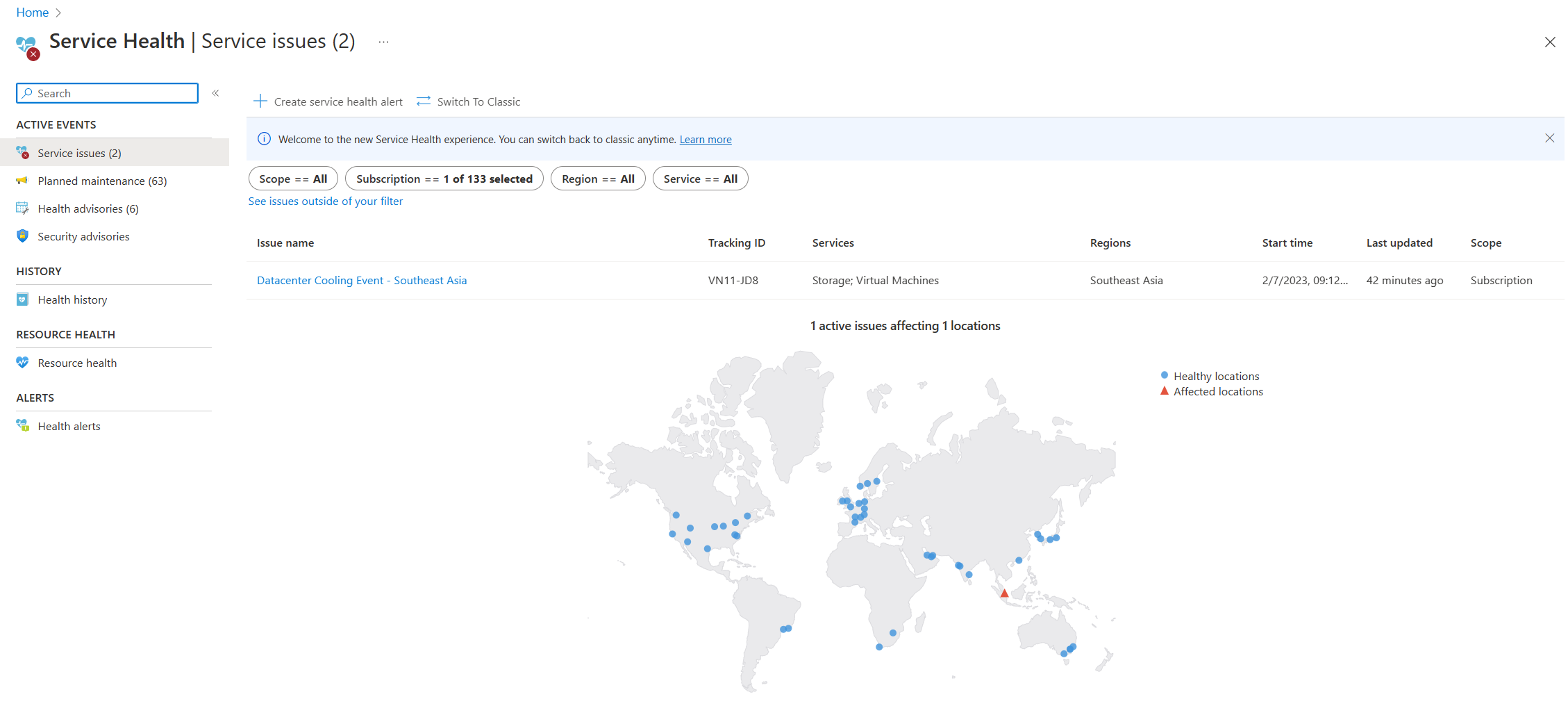
- 服务帮助:Azure 门户中的“服务运行状况”页包含有关 Azure 数据中心全局状态的信息。 在 Azure 门户搜索栏中搜索“服务运行状况”,然后在“活动事件”类别中查看“服务问题”。 还可以在“帮助”菜单下任何资源的 “资源运行状况 ”页中查看单个资源的运行状况。 下面显示了“服务运行状况”页的示例屏幕截图。
- 电子邮件通知:如果已设置警报,当服务中断影响订阅和资源时,你将收到电子邮件通知。 电子邮件发送自“azure-noreply@microsoft.com”。 电子邮件正文以“活动日志警报...由 Azure 订阅的服务问题触发...”开头。 有关服务运行状况警报的详细信息,请参阅 使用 Azure 门户在 Azure 服务通知上接收活动日志警报。
重要
顾名思义,PostgreSQL 中的临时表空间用于临时对象以及其他内部数据库操作,例如排序。 因此,不建议在临时表空间中创建用户架构对象,因为我们不保证在服务器重启、HA 故障转移等情况之后此类对象的持久性。
计划外停机:故障场景和服务恢复
下面是一些计划外故障场景和恢复过程。
| 情景 |
恢复过程 [未配置区域冗余 HA 的服务器] |
恢复过程 [配置了区域冗余 HA 的服务器] |
|---|---|---|
| 数据库服务器故障 | 如果数据库服务器已关闭,Azure 将尝试重启数据库服务器。 如果重启失败,数据库服务器将在另一个物理节点上重启。 恢复时间 (RTO) 取决于各种因素,包括发生故障时的活动,例如,在数据库服务器启动过程中需执行的大型事务和恢复量。 所构建的使用 PostgreSQL 数据库的应用程序需要能够检测并重试丢弃的连接和失败的事务。 |
如果检测到数据库服务器故障,服务器将故障转移到备用服务器,从而减少停机时间。 有关详细信息,请参阅 HA 概念页。 RTO 应为 60-120 s,且不会丢失数据。 |
| 存储失败 | 对于任何与存储相关的问题(例如磁盘故障或物理块损坏),应用程序看不到任何影响。 由于数据存储在三个副本中,因此将由未发生故障的存储提供数据的副本。 损坏的数据块会自动修复,数据的新副本会自动创建。 | 对于任何罕见错误和不可恢复的错误(如整个存储不可访问),Azure Database for PostgreSQL 灵活服务器实例会被故障转移到备用副本以减少停机时间。 有关详细信息,请参阅 HA 概念页。 |
| 逻辑/用户错误 | 若要从用户错误(如意外删除表或未正确更新数据)中恢复,则必须执行时间点还原 (PITR)。 在执行还原操作时,请指定自定义还原点,即发生错误之前的时间。 如果只想还原数据库或特定表的子集,而不是数据库服务器中的所有数据库,则可以在新实例中还原数据库服务器,通过 pg_dump导出表,然后使用 pg_restore 将这些表还原到数据库中。 |
这些用户错误不受高可用性保护,因为所有更改都同步复制到备用副本。 必须执行时间点还原,才能从此类错误中恢复。 |
| 可用性区域故障 | 若要从区域级别的故障中恢复,可以使用备份并选择具有还原最新数据的最新时间的自定义还原点来执行时间点还原。 新的 Azure Database for PostgreSQL 灵活服务器实例部署在另一个不受影响的区域中。 还原所需的时间取决于以前的备份和要恢复的事务日志量。 | Azure Database for PostgreSQL 灵活的服务器实例在 60-120 秒内自动故障转移到备用服务器,不会丢失任何数据。 有关详细信息,请参阅 HA 概念页。 |
| 区域故障 | 如果服务器配置了异地冗余备份,可以在配对区域执行异地还原。 将预配新服务器,并将其恢复到已复制到此区域的最新可用数据。 还可以使用跨区域只读副本。 发生区域故障时,可以通过将只读副本提升为独立的可读写服务器来执行灾难恢复操作。 RPO 预计最长为 5 分钟(可能会丢失数据),除非出现严重的区域性故障,此时 RPO 可能接近故障时的复制滞后时间。 |
相同的过程。 |
从区域故障恢复后配置数据库
- 在服务中断后,如果使用异地还原或异地恢复进行恢复,必须确保已正确配置与新服务器的连接,以便恢复正常的应用程序功能。 可以遵循还原后任务。
- 如果以前在原始服务器上设置了诊断设置,请确保在必要时在目标服务器上执行相同的作,如 Azure Database for PostgreSQL 中的“配置和访问日志”中所述。
- 设置遥测警报,需要确保更新现有的警报规则设置以映射到新的服务器。 有关警报规则的详细信息,请参阅 使用 Azure 门户针对 Azure Database for PostgreSQL 的指标设置警报。
重要
可以还原删除的服务器。 如果删除服务器,可以按照我们的指南 还原已删除的服务器 进行恢复。 使用 Azure 资源锁帮助防止意外删除服务器。