在本快速入门中,你将使用 导入数据 向导和有关虚构酒店的示例数据开始使用 全文搜索,也称为关键字搜索。 向导不需要任何代码来创建索引,有助于在几分钟内编写有趣的查询。
该向导在search service上创建多个对象,包括可搜索索引、索引器和数据源连接,以便自动检索数据。 在本快速入门指南结束时,您将检查每个对象。
先决条件
具有活动订阅的Azure帐户。 免费创建帐户。
Azure AI 搜索 服务。 本快速入门需要基本层或更高级别来支持托管身份。
Azure 存储 帐户。 在标准性能(常规用途 v2)帐户上使用Azure Blob 存储或Azure Data Lake Storage Gen2(具有分层命名空间的存储帐户)。 若要避免带宽费用,请使用与Azure AI 搜索相同的区域。
熟悉向导。 请参阅 Azure 门户中的 Import 数据向导。
检查网络访问
上述所有资源都必须启用公共访问,以便向导可以访问它们。 否则,向导将失败。 运行向导后,你可以为集成组件启用防火墙和专用终结点以确保安全。 有关详细信息,请参阅 导入向导中的安全连接。
检查空间
许多客户从免费的搜索服务开始,此搜索服务限制为三个索引、三个索引器和三个数据源。 本快速入门将创建每个对象之一,因此在开始之前,请确保为额外的对象留出空间。
在“ 概述 ”页上,选择“ 使用情况 ”以查看当前拥有的索引、索引器和数据源数。

配置访问权限
在开始之前,请确保你有权访问内容和操作。 本快速入门使用 Microsoft Entra ID 进行身份验证,并通过基于角色的访问控制实现授权。 你必须是 所有者 或 用户访问管理员 才能分配角色。 如果角色设置不可行,请改用基于密钥的身份验证方式。
若要为本快速入门配置访问权限,请执行以下步骤:
登录到 Azure 门户。
在 Azure AI 搜索 的服务上:
将以下角色分配给 用户帐户: 搜索服务参与者、 搜索索引数据参与者和 搜索索引数据读取者。
在 Azure 存储 帐户上,向您的搜索服务的托管标识分配 Storage Blob 数据读取器。
准备示例数据
本快速入门使用包含 50 家虚构酒店元数据的示例 JSON 文档,但也可以使用自己的文件。
若要为此快速入门准备示例数据,请执行以下操作:
在 Azure 门户访问 Azure 存储 帐户。
在左窗格中,选择Data storage>Containers。
创建名为 hotels-sample-data 的容器。
将 sample JSON 文档上传到容器。
启动向导
在 Azure 门户中,转到你的搜索服务。
在“ 概述 ”页上,选择“ 导入数据”。

选择数据源:Azure Blob 存储 或 Azure Data Lake Storage Gen2。

选择 关键字搜索。
Azure门户中的关键字搜索磁贴截图

运行向导
向导将引导你完成多个配置步骤。 本部分按顺序介绍每个步骤。
连接到数据源
Azure AI 搜索需要连接到数据源才能进行内容引入和索引编制。 在这种情况下,数据源是Azure 存储帐户。
连接到示例数据:
在连接到您的数据页面上,选择您的Azure订阅。
选择存储帐户,然后选择 hotels-sample-data 容器。
选择分析模式的 JSON 数组 。
选中“ 使用托管标识进行身份验证 ”复选框。 将标识类型保留为 系统分配。
Azure 门户中连接到您的数据页面的截图。 选择“下一步”。
跳过 AI 扩充
该向导支持在编制索引期间创建技能集和AI 扩充,而这些功能都超出了本快速入门的范围。 通过选择 “下一步”跳过此步骤。
提示
有关重点介绍 AI 增强的类似演练,请参阅 快速入门:在 Azure 门户中创建技能集。
配置索引
该向导根据示例数据推断搜索索引的架构。 索引至少需要名称和字段集合。 向导将扫描唯一的字符串字段,并将其中一个字段标记为文档键,该键唯一标识索引中的每个文档。
每个字段都有一个名称、 数据类型和属性,用于控制其使用方式。 例如, 可筛选 字段支持查询中的筛选表达式,而 可搜索 字段支持关键字搜索。 有关详细信息,请参阅 “配置字段定义”。
若要为本快速入门中的查询示例配置索引:
对于以下每个字段,请选择“ 配置”字段,然后设置相应的属性。
Fields 特性 HotelId键,可检索,可筛选,可排序,可搜索 HotelName、Category可检索、可筛选、可排序、可搜索 Description、Description_fr可检索、可搜索 Tags可检索、可筛选、可搜索 ParkingIncluded、IsDeleted可检索、可筛选、可分面 LastRenovationDate、Rating、Location可检索、可筛选、可排序 Address.StreetAddress、Rooms.Description、Rooms.Description_fr可检索、可搜索 Address.City、Address.StateProvince、Address.PostalCode、Address.Country可检索、可筛选、可分面、可搜索、可排序 Rooms.Type、Rooms.BedOptions、Rooms.Tags可检索、可筛选、可分面、可搜索 Rooms.BaseRate、Rooms.SleepsCount、Rooms.SmokingAllowed可检索、可筛选、可分面 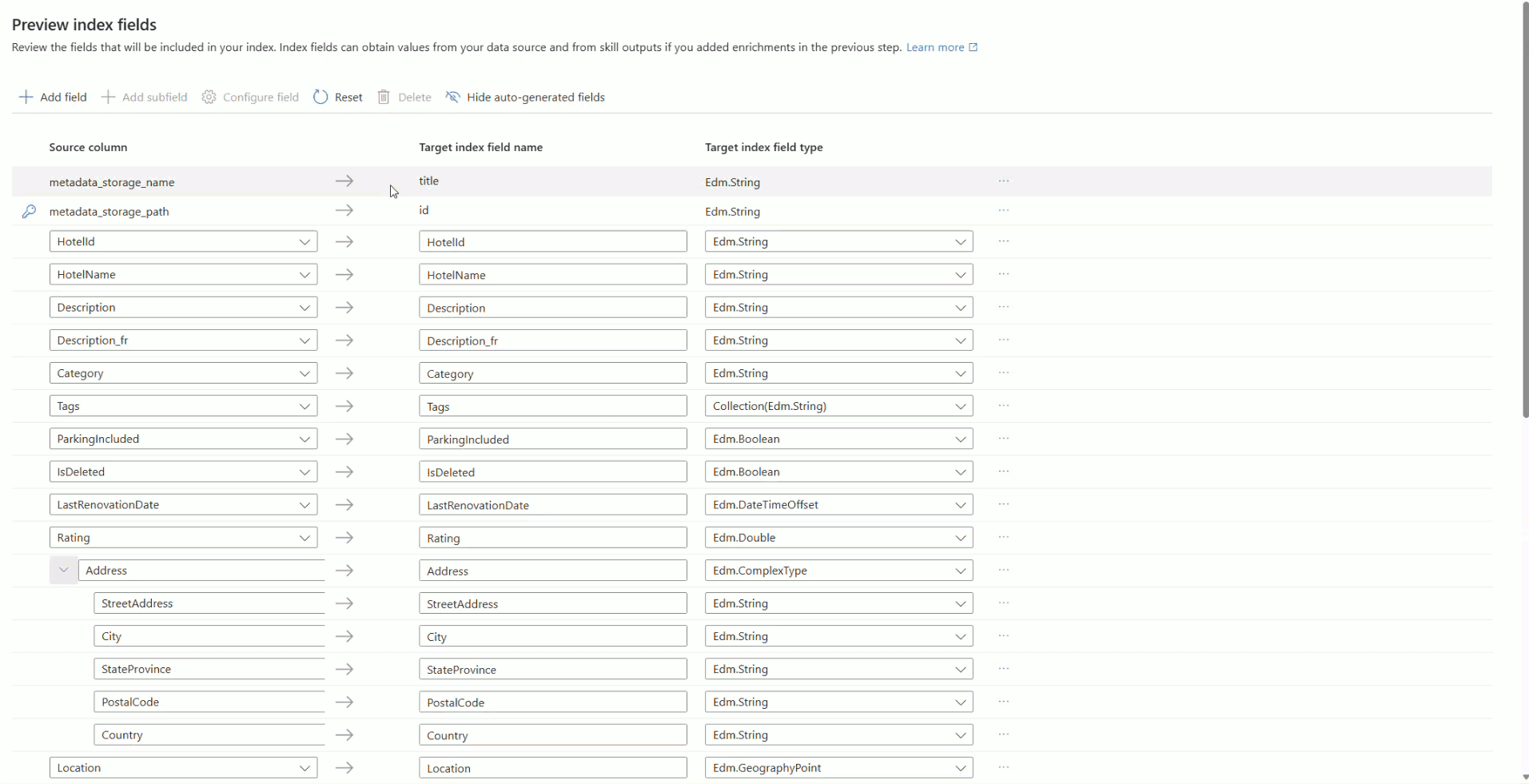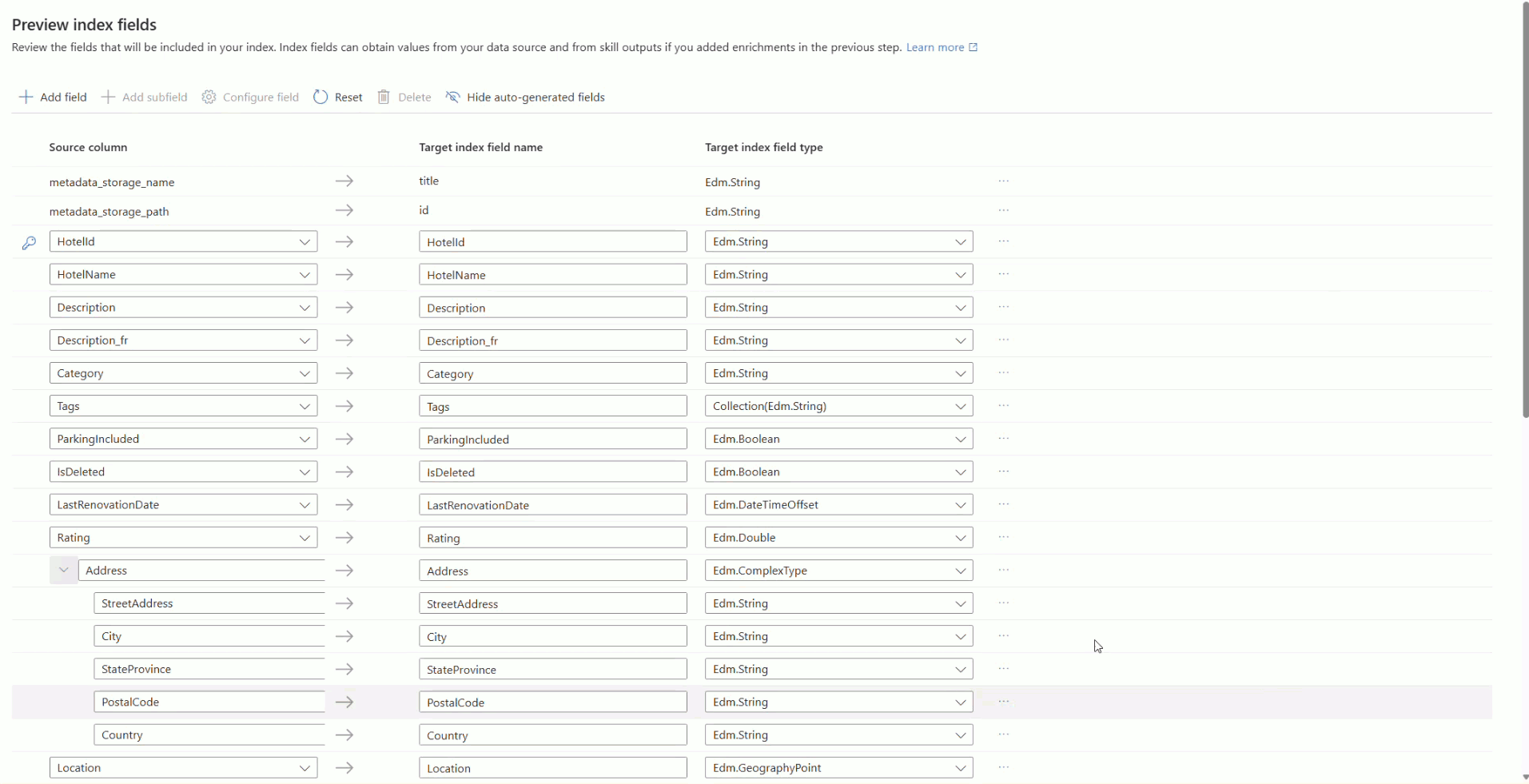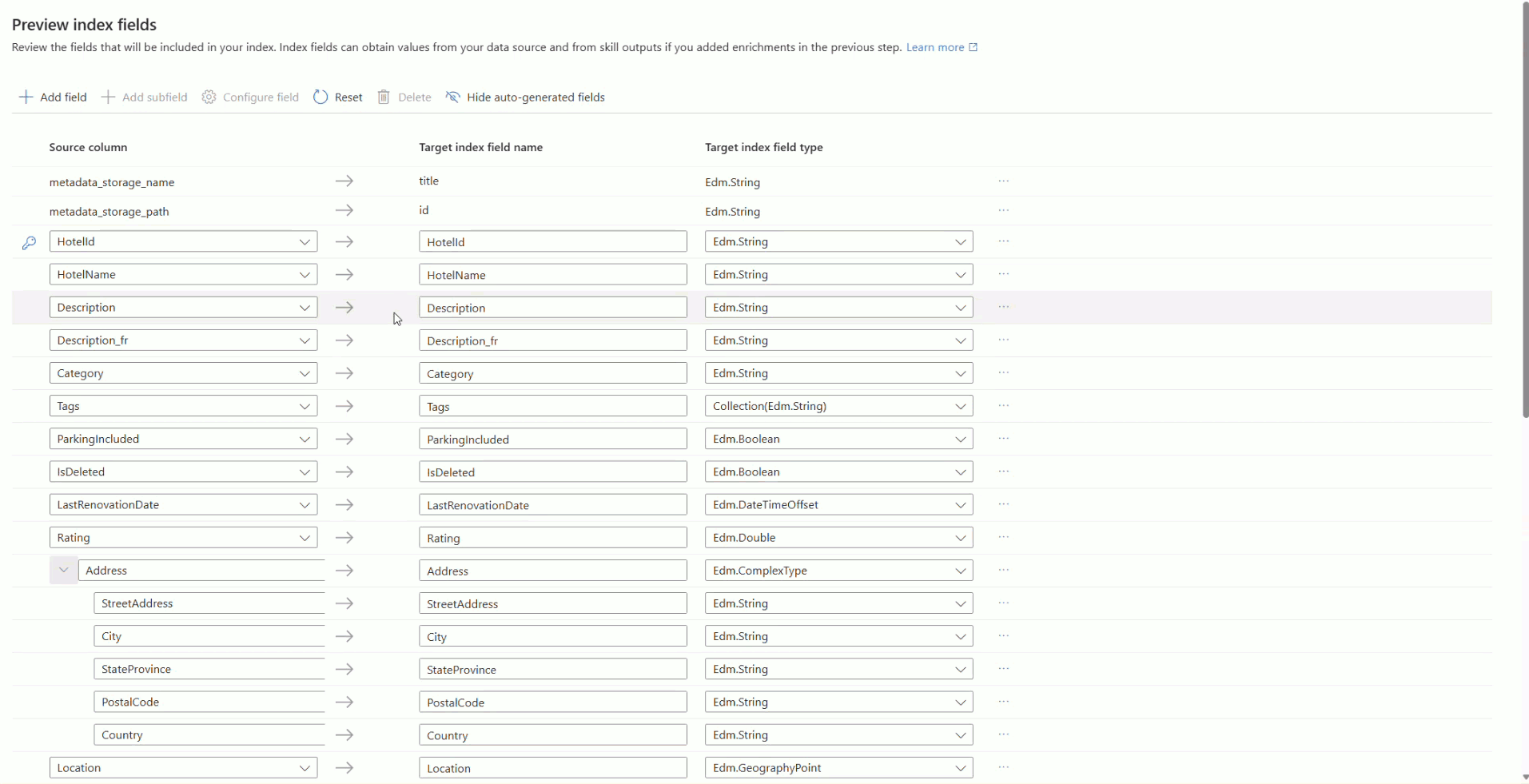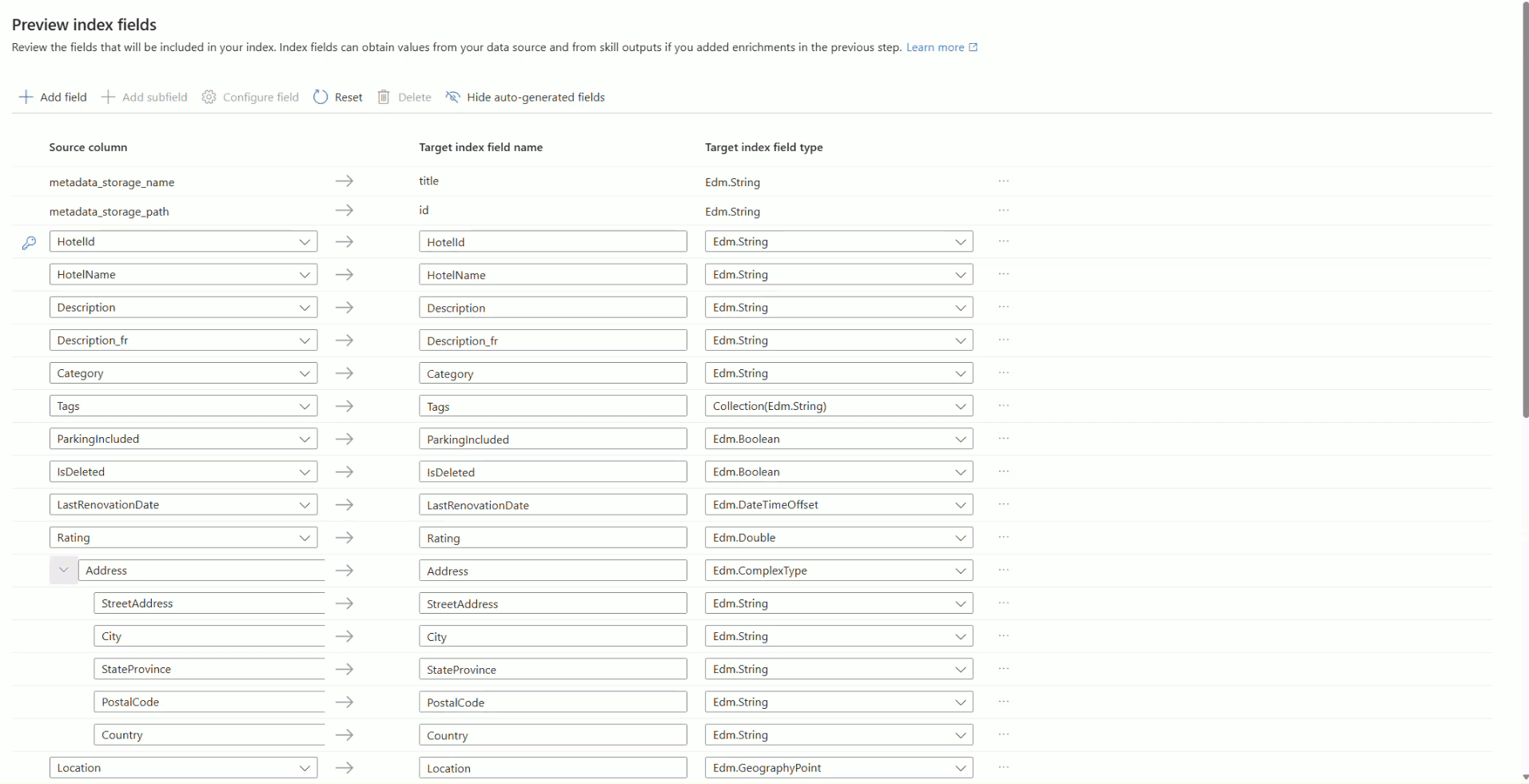
选择“下一步”。

跳过高级设置
该向导提供语义排名和索引计划的高级设置,这些设置超出了本快速入门的范围。 通过选择 “下一步”跳过此步骤。
完成该向导
最后一步是在搜索服务上查看配置并创建索引、索引器和数据源。 索引器自动执行从数据源提取内容并将其加载到索引的过程,从而启用关键字搜索。
若要完成向导,请执行以下操作:
将对象名称前缀更改为 hotels-sample。
查看对象配置。
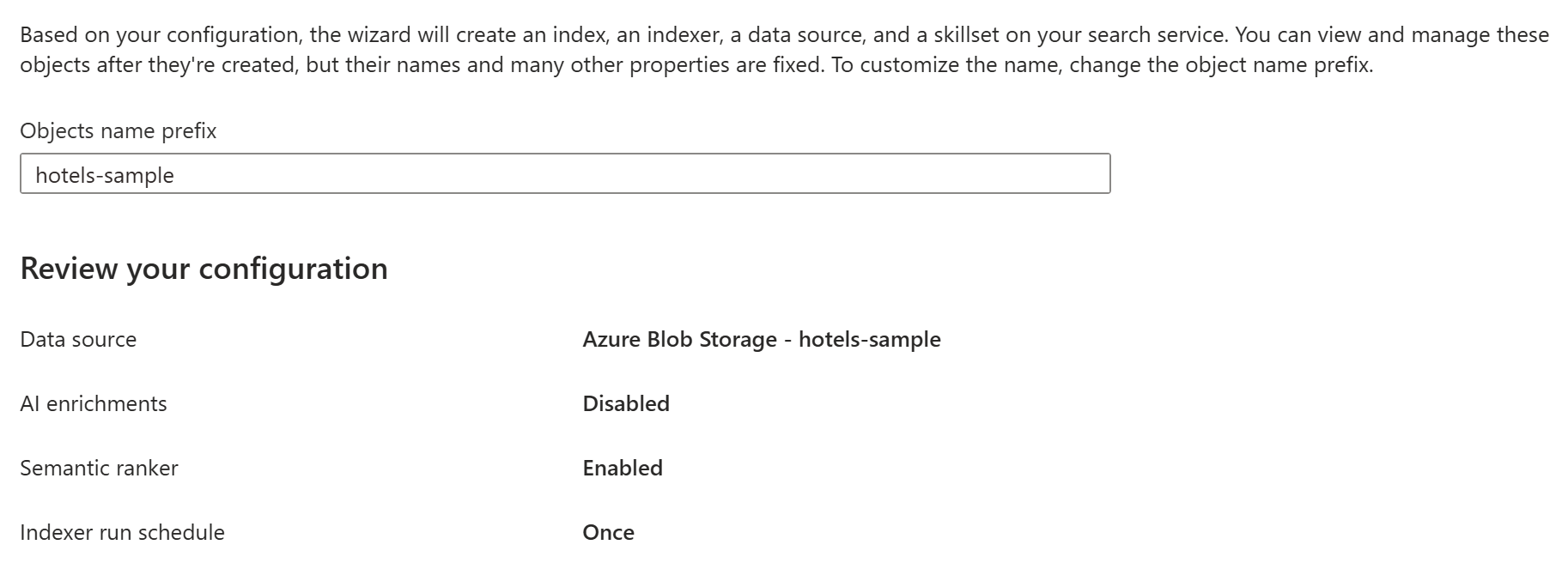
AI 扩充、语义排名器和索引器计划被禁用或设置为其默认值,因为你跳过了其向导步骤。
选择“ 创建 ”以同时创建对象并运行索引器。

检查索引器状态
在左窗格中,选择 “搜索管理>索引器”。
在列表中查找 hotels-sample-indexer 。
正在 Azure portal 中创建索引器的截图显示过程. 更新结果可能需要几分钟时间。 应会看到新创建的索引器,其状态为 “正在进行 ”或 “成功”。 该列表还显示已编制索引的文档数。
检查索引结果
在左窗格中,选择 “搜索管理>索引”。
选择hotels-sample。 如果索引包含零个文档或存储,请等待Azure门户刷新。

选择“字段”选项卡以查看索引架构。
截图,展示 Azure 门户中 Azure AI 搜索服务的索引架构定义。

添加或更改索引字段
在“ 字段 ”选项卡上,可以通过选择 “添加”字段 并指定名称、支持的数据类型和属性来创建字段。
更改现有字段会更加困难。 现有字段在搜索索引中具有物理表示形式,因此它们不可修改,即使在代码中也是如此。 若要从根本上更改现有字段,必须创建新字段以替换原始字段。 可以随时将其他构造(如计分配置文件和语义配置)添加到索引。
查看索引定义选项,了解在索引设计期间可以和无法编辑的内容。 如果某个选项显示为灰色,则无法修改或删除它。
查询索引
现在,可以使用 搜索资源管理器查询搜索索引,它发送符合 文档 - 搜索帖子(REST API)的 REST 调用。 此工具支持关键字搜索的简单查询语法和完整 Lucene 查询语法。
查询搜索索引:
在 “搜索资源管理器 ”选项卡上,输入查询词或字符串,例如
new york hotel with pool or gym。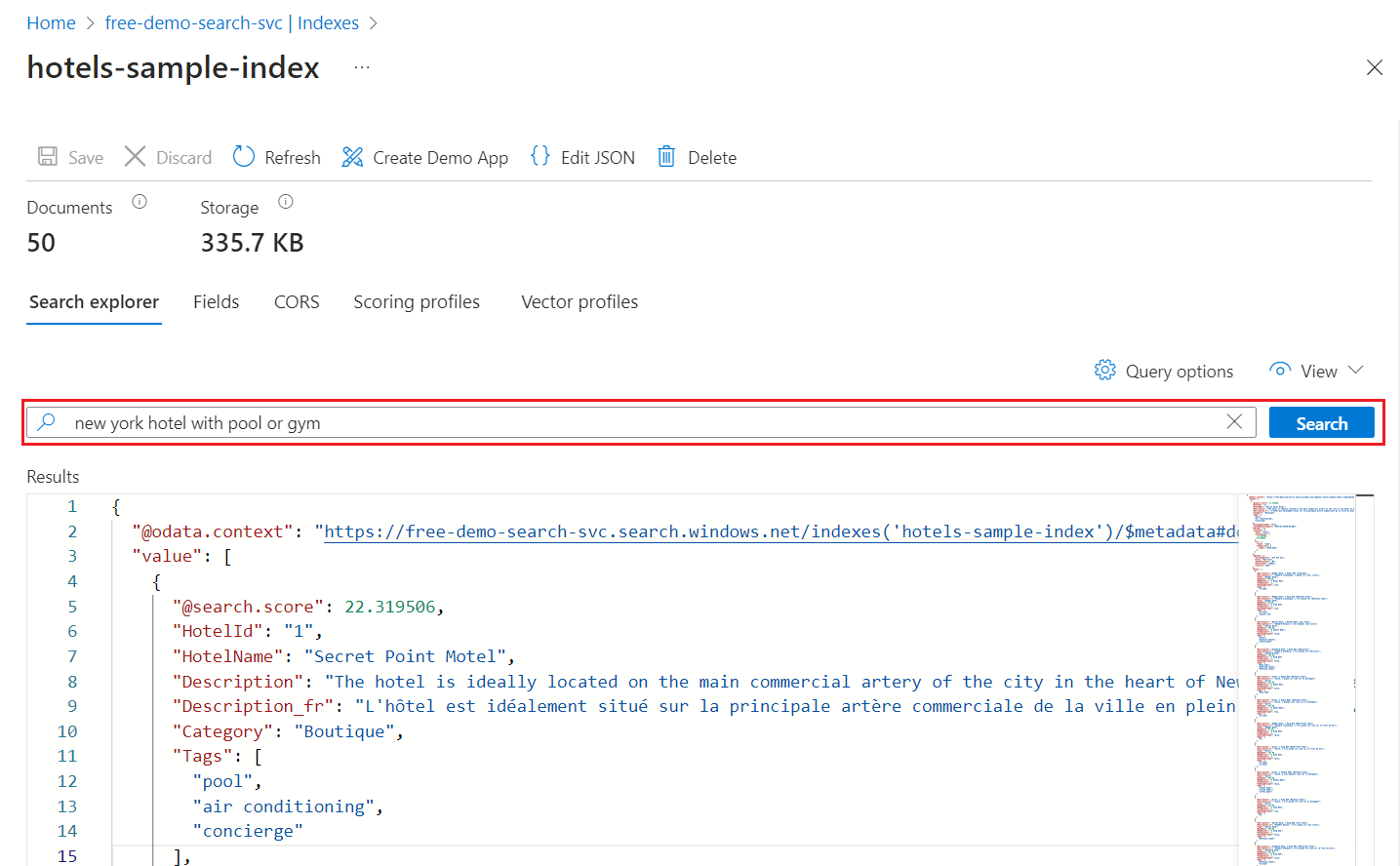
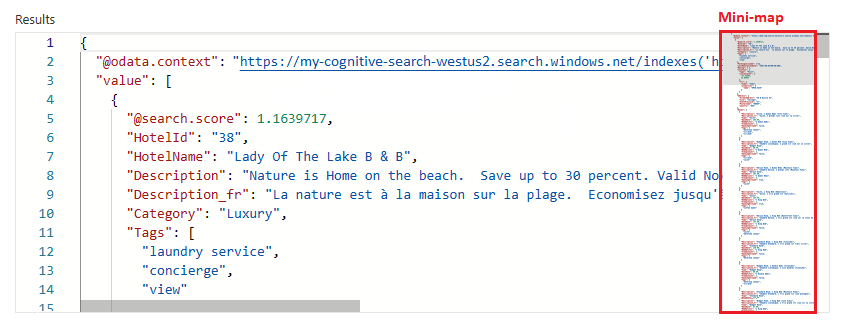
若要跳转到输出的非可见区域,请使用迷你地图。
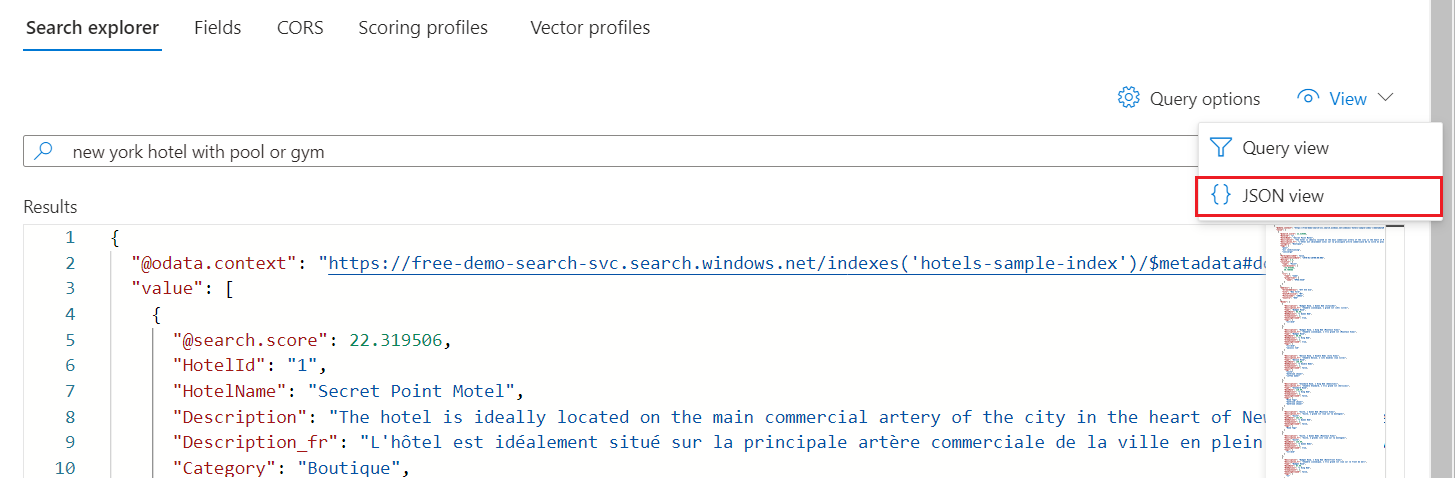
要指定语法,请切换到 JSON 视图。
运行以下查询示例,了解筛选和查询语法的工作原理。
提示
JSON 视图支持 IntelliSense 功能,用于补全参数名。 将光标置于 JSON 视图中,并输入空格字符以查看所有查询参数的列表。 还可以输入字母,例如
s,仅查看以该字母开头的查询参数。Intellisense 不会排除无效参数,因此请使用最佳判断。



筛选器示例
停车、标记、装修日期、评级和位置是可筛选的。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "Rating gt 4"
}
默认情况下,布尔筛选器假定为“true”。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "ParkingIncluded"
}
地理空间搜索基于筛选器。 该 geo.distance 函数可根据指定 Location 和 geography'POINT 坐标筛选位置数据的所有结果。 查询在纬度和经度坐标 -122.12 47.67的五公里范围内查找酒店,即“美国华盛顿雷德蒙德”。该查询显示具有酒店名称和地址位置的匹配 &$count=true 项总数。
{
"search": "*",
"select": "HotelName, Address/City, Address/StateProvince",
"count": true,
"top": 10,
"filter": "geo.distance(Location, geography'POINT(-122.12 47.67)') le 5"
}
完整的 Lucene 语法示例
默认语法是 简单的语法,但如果需要模糊搜索、字词提升或正则表达式,请指定 完整的语法。
{
"queryType": "full",
"search": "seatle~",
"select": "HotelId, HotelName,Address/City, Address/StateProvince",
"count": true
}
拼写错误的查询词(例如seatle而不是Seattle)在典型的搜索中不会返回匹配项。
queryType=full 参数调用完整的 Lucene 查询分析程序,它支持波形符 (~) 操作数。 使用这些参数时,查询对指定的关键字执行模糊搜索,并匹配类似但不完全匹配的字词。
有关这些示例的详细信息,请参阅 在 Azure AI 搜索中进行查询。
清理资源
在您自己的订阅计划中工作时,最好通过删除不再需要的资源来完成项目。 持续运行的资源可能会产生费用。
在Azure门户中,从左窗格中选择“所有资源或资源组以查找和管理资源。 可以单独删除资源,也可以删除资源组以一次性删除所有资源。
如果使用免费的搜索服务,请记住,您最多只能使用三个索引、索引器和数据源。 可以 删除门户中的各个项 ,以保持在限制之下。
后续步骤
尝试使用 Azure 门户向导生成在浏览器中运行的现成 Web 应用。 在本快速入门中创建的小型索引上使用此向导,或使用示例数据以获得更丰富的搜索体验。