Azure AI Search支持将多个数据源中的数据导入、分析和索引到单个合并的搜索索引中。
本 C# 教程使用 Azure。search.Documents Azure SDK 中的客户端库,以便.NET从Azure Cosmos DB实例为示例酒店数据编制索引。 然后将数据与从Azure Blob Storage文档绘制的酒店房间详细信息合并。 结果是包含酒店文档的综合酒店搜索索引,其中房间作为一种复杂的数据类型。
在本教程中,你将:
- 将示例数据上传到数据源
- 标识文档密钥
- 定义和创建索引
- 从Azure Cosmos DB为酒店数据编制索引
- 合并来自Blob Storage的酒店房间数据
概述
本教程使用 Azure。Search.Documents 创建和运行多个索引器。 将示例数据上传到两个Azure数据源,并配置一个索引器,该索引器从两个源提取以填充单个搜索索引。 这两个数据集必须有一组相同的值才支持合并。 在本教程中,该字段是 ID。 只要有一个用于支持映射的字段,索引器就可以合并不同资源中的数据:来自Azure SQL的结构化数据、来自Blob Storage的非结构化数据,或者Azure上支持的数据源的任意组合。
可以在以下项目中找到本教程中代码的完成版本:
先决条件
- 具有活动订阅的Azure帐户。 创建试用版订阅。
- Azure Cosmos DB的NoSQL帐户。
- Azure Storage 帐户。
- Azure AI Search 服务。
- Visual Studio。
注意
可在本教程中使用免费搜索服务。 免费层限制为三个索引、三个索引器和三个数据源。 本教程将为每个类别创建一个实例。 在开始之前,请确保服务上有空间以接受新资源。
准备服务
本教程使用 Azure AI Search 进行索引和查询,使用 Azure Cosmos DB 作为第一个数据集,并使用 Azure Blob Storage 作为第二个数据集。
如果可能,请在同一区域和资源组中创建所有服务,使它们相互靠近并易于管理。 在实践中,服务可位于任意区域。
此示例使用两组描述七家虚构酒店的小数据集。 一组描述酒店本身,并将加载到Azure Cosmos DB数据库中。 另一组包含酒店房间详细信息,并作为要上传到Azure Blob Storage的七个单独的 JSON 文件提供。
从Azure Cosmos DB开始
在 Azure 门户中转到 Azure Cosmos DB 帐户。
在左窗格中,选择Data Explorer。
选择 “新建容器>新数据库”。
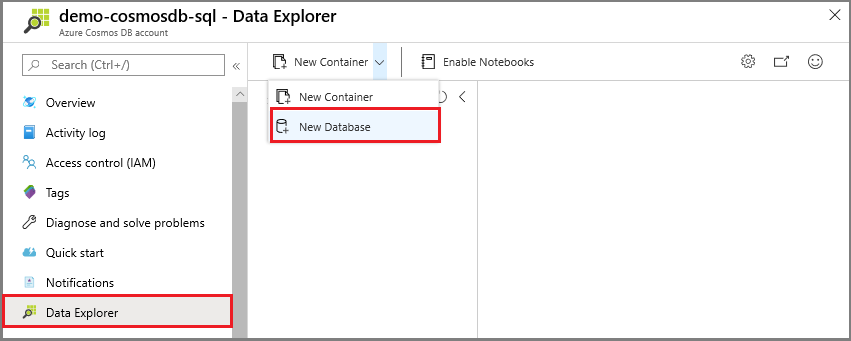
输入 hotel-room-db 以获取名称。 接受其余设置的默认值。
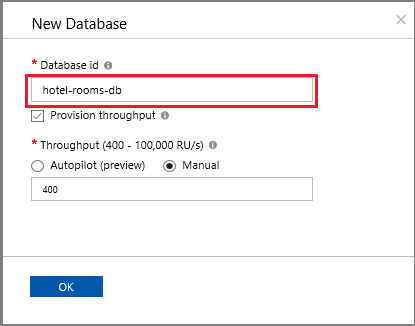
创建面向之前创建的数据库的容器。 输入 hotels 作为容器名称,/HotelId 作为分区键。
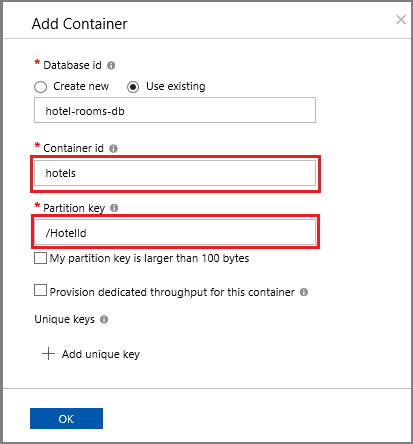
选择 hotels>Items,然后选择命令栏上的 “上传项目 ”。
-
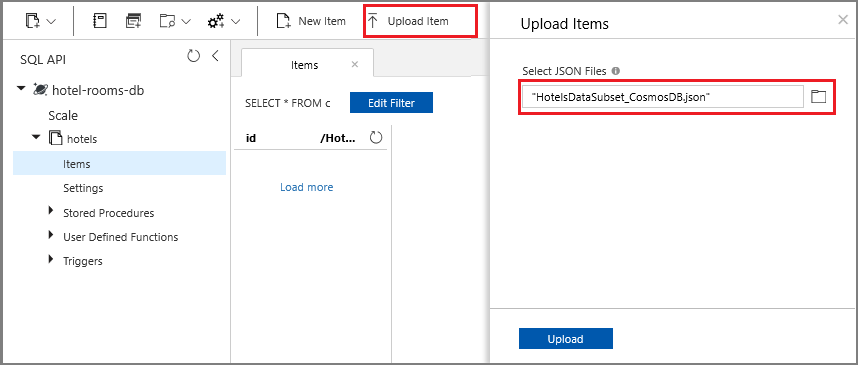
使用刷新按钮更新您对酒店集合中项目的视图。 此时应会列出七个新数据库文档。
在左窗格中,选择“设置”“密钥”。>
请记下连接字符串。 在后面的步骤中,需要将此值用于 appsettings.json。 如果您没有使用建议的hotel-rooms-db数据库名称,请同时复制该数据库名称。
Azure Blob 存储
在 Azure 门户中转到 Azure Storage 帐户。
在左窗格中,选择 “数据存储>容器”。
创建 blob 容器,名为“hotel-rooms” ,用于存储示例酒店房间 JSON 文件。 可以将访问级别设置为任何有效值。
打开容器,然后在命令栏上选择“ 上传 ”。
从
blob文件夹中上传七个 JSON 文件至 multiple-data-sources/v11。
在左窗格中,选择 “安全性 + 网络>访问密钥”。
记下帐户名称和连接字符串。 在后面的步骤中,需要将这两个值用于 appsettings.json。
Azure AI 搜索
第三个组件是Azure AI Search,可以在 Azure 门户中创建或在Azure资源中查找现有的搜索服务。
复制Azure AI Search的管理密钥和 URL
若要向搜索服务进行身份验证,需要服务 URL 和访问密钥。 在应用程序发送请求和服务处理请求时,每个请求都有一个有效密钥来建立信任。
在 Azure 门户中,转到你的搜索服务。
在左窗格中,选择“ 概述”。
记下 URL,应如下所示
https://my-service.search.azure.cn。在左窗格中,选择“设置”“密钥”。>
请记录下获得服务完整权限所需的管理员密钥。 有两个可交换的管理员密钥,为保证业务连续性而提供,以防需要滚动一个密钥。 可以对请求使用任一键来添加、修改和删除对象。
配置你的环境
在 Visual Studio 中从
AzureSearchMultipleDataSources.sln打开 文件。在解决方案资源管理器中,右键单击项目并选择管理解决方案的 NuGet 包...。
在 “浏览 ”选项卡上,找到并安装以下包:
Azure。Search.Documents (版本 11.0 或更高版本)
Microsoft.Extensions.Configuration
Microsoft.Extensions.Configuration.Json
在 Solution Explorer 中,使用在前面的步骤中收集的连接信息编辑
appsettings.json文件。{ "SearchServiceUri": "<YourSearchServiceURL>", "SearchServiceAdminApiKey": "<YourSearchServiceAdminApiKey>", "BlobStorageAccountName": "<YourBlobStorageAccountName>", "BlobStorageConnectionString": "<YourBlobStorageConnectionString>", "CosmosDBConnectionString": "<YourCosmosDBConnectionString>", "CosmosDBDatabaseName": "hotel-rooms-db" }
映射键字段
合并内容要求两个数据流必须针对搜索索引中的相同的文档。
在Azure AI Search中,键字段唯一标识每个文档。 每个搜索索引必须只有一个类型为 Edm.String 的键字段。 必须为添加到索引中的每个数据源文档设置键字段。 (事实上,它是唯一的必填字段。)
为来自多个数据源的数据编制索引时,请确保每个传入行或文档都包含一个通用文档键。 这样,就可以将数据从两个物理上不同的源文档合并到合并索引中的新搜索文档中。
它通常需要一些前期规划来标识索引的有意义的文档密钥,并确保它存在于这两个数据源中。 在此演示中,Azure Cosmos DB 中的每个酒店都有相应的 HotelId 密钥,并且这些密钥也存在于 Blob Storage 中的房间 JSON blob 中。
Azure AI Search索引器可以使用字段映射在索引过程中重命名甚至重新格式化数据字段,以便将源数据定向到正确的索引字段。 例如,在 Azure Cosmos DB 中,酒店标识符称为 HotelId,但在酒店房间的 JSON blob 文件中,酒店标识符命名为 Id。 程序通过将 Blob 中的 Id 字段映射到索引器中的 HotelId 密钥字段来处理此差异。
注意
在大多数情况下,自动生成的文档键(如某些索引器默认创建的文档键)不会为组合索引提供良好的文档键。 一般情况下,请使用数据源中已存在的有意义的唯一键值,或者可以轻松添加。
浏览代码
当数据和配置设置到位时,示例程序 AzureSearchMultipleDataSources.sln 应准备好生成并运行。
这个简单的 C#/.NET 控制台应用执行以下任务:
- 基于 C# Hotel 类的数据结构创建新索引,该类也引用地址和房间类。
- 创建一个新的数据源和一个索引器,用于将Azure Cosmos DB数据映射到索引字段。 这些是Azure AI Search中的两个对象。
- 运行索引器从Azure Cosmos DB加载酒店数据。
- 创建另一个数据源以及用于将 JSON Blob 数据映射到索引字段的索引器。
- 运行第二个索引器,从Blob Storage加载酒店房间数据。
在运行程序之前,请花一分钟时间研究代码、索引定义和索引器定义。 相关代码在两个文件中:
-
Hotel.cs包含定义索引的架构。 -
Program.cs包含创建Azure AI Search索引、数据源和索引器的函数,并将合并的结果加载到索引中。
创建索引
此示例程序使用 CreateIndexAsync 定义和创建Azure AI Search索引。 它利用 FieldBuilder 类,从 C# 数据模型类来生成索引结构。
数据模型由“酒店”类定义,该类还包含对“地址”和“房间”类的引用。 FieldBuilder 向下钻取多个类定义,从而为索引生成复杂的数据结构。 元数据标记用于定义每个字段的属性,例如字段是否可搜索或可排序。
如果想要多次运行此示例,程序在创建新索引之前会删除同名的任何现有索引。
以下代码段来自文件 Hotel.cs,显示了单个字段,紧接着引用了另一个数据模型类 Room[],该类在文件 Room.cs 中定义(未显示)。
. . .
[SimpleField(IsFilterable = true, IsKey = true)]
public string HotelId { get; set; }
[SearchableField(IsFilterable = true, IsSortable = true)]
public string HotelName { get; set; }
. . .
public Room[] Rooms { get; set; }
. . .
在 Program.cs 文件中,定义了一个 SearchIndex,它包含一个名称和由 FieldBuilder.Build 方法生成的字段集合,然后按如下所示创建:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address and Room classes are referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
创建Azure Cosmos DB数据源和索引器
主程序包括为酒店数据创建Azure Cosmos DB数据源的逻辑。
首先,它将 Azure Cosmos DB 数据库名称连接到连接字符串。 然后,它定义 SearchIndexerDataSourceConnection 对象。
private static async Task CreateAndRunCosmosDbIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
// Append the database name to the connection string
string cosmosConnectString =
configuration["CosmosDBConnectionString"]
+ ";Database="
+ configuration["CosmosDBDatabaseName"];
SearchIndexerDataSourceConnection cosmosDbDataSource = new SearchIndexerDataSourceConnection(
name: configuration["CosmosDBDatabaseName"],
type: SearchIndexerDataSourceType.CosmosDb,
connectionString: cosmosConnectString,
container: new SearchIndexerDataContainer("hotels"));
// The Azure Cosmos DB data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(cosmosDbDataSource);
创建数据源后,程序将设置名为 hotel-rooms-cosmos-indexer 的Azure Cosmos DB索引器。
程序更新任何名称相同的现有索引器,用之前代码的内容覆盖现有索引器。 它还包含重置和运行操作,因此你可以多次运行此示例。
以下示例定义索引器的计划,以便每天运行一次。 如果不希望索引器在将来再次自动运行,可以从该调用中删除该计划属性。
SearchIndexer cosmosDbIndexer = new SearchIndexer(
name: "hotel-rooms-cosmos-indexer",
dataSourceName: cosmosDbDataSource.Name,
targetIndexName: indexName)
{
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Indexers keep metadata about how much they have already indexed.
// If we already ran the indexer, it "remembers" and does not run again.
// To avoid this, reset the indexer if it exists.
try
{
await indexerClient.GetIndexerAsync(cosmosDbIndexer.Name);
// Reset the indexer if it exists.
await indexerClient.ResetIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404)
{
// If the indexer does not exist, 404 will be thrown.
}
await indexerClient.CreateOrUpdateIndexerAsync(cosmosDbIndexer);
Console.WriteLine("Running Azure Cosmos DB indexer...\n");
try
{
// Run the indexer.
await indexerClient.RunIndexerAsync(cosmosDbIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 429)
{
Console.WriteLine("Failed to run indexer: {0}", ex.Message);
}
此示例包含一个简单的 try-catch 块来报告执行过程中可能发生的任何错误。
运行Azure Cosmos DB索引器后,搜索索引包含一组完整的示例酒店文档。 但是,每个酒店的房间字段都是空数组,因为Azure Cosmos DB数据源省略房间详细信息。 接下来,程序从 Blob Storage 拉取以加载和合并房间数据。
创建Blob Storage数据源和索引器
为了获取会议室详细信息,程序首先设置一个Blob Storage数据源来引用一组单独的 JSON Blob 文件。
private static async Task CreateAndRunBlobIndexerAsync(string indexName, SearchIndexerClient indexerClient)
{
SearchIndexerDataSourceConnection blobDataSource = new SearchIndexerDataSourceConnection(
name: configuration["BlobStorageAccountName"],
type: SearchIndexerDataSourceType.AzureBlob,
connectionString: configuration["BlobStorageConnectionString"],
container: new SearchIndexerDataContainer("hotel-rooms"));
// The blob data source does not need to be deleted if it already exists,
// but the connection string might need to be updated if it has changed.
await indexerClient.CreateOrUpdateDataSourceConnectionAsync(blobDataSource);
创建数据源后,程序会设置一个名为 hotel-rooms-blob-indexerblob 索引器,如下所示。
JSON Blob 包含名为 Id 而不是 HotelId 的键字段。 该代码使用 FieldMapping 类来指示索引器将 Id 字段值定向到索引中的 HotelId 文档键。
Blob Storage索引器可以使用 IndexingParameters 指定分析模式。 应设置不同的分析模式,具体取决于 Blob 是表示同一 Blob 中的单个文档还是多个文档。 在此示例中,每个 blob 表示单个 JSON 文档,因此代码使用 json 解析模式。 有关 JSON blob 的索引器分析参数的详细信息,请参阅为 JSON blob 编制索引。
此示例定义索引器的计划,以便每天运行一次。 如果不希望索引器在将来再次自动运行,可以从该调用中删除该计划属性。
IndexingParameters parameters = new IndexingParameters();
parameters.Configuration.Add("parsingMode", "json");
SearchIndexer blobIndexer = new SearchIndexer(
name: "hotel-rooms-blob-indexer",
dataSourceName: blobDataSource.Name,
targetIndexName: indexName)
{
Parameters = parameters,
Schedule = new IndexingSchedule(TimeSpan.FromDays(1))
};
// Map the Id field in the Room documents to the HotelId key field in the index
blobIndexer.FieldMappings.Add(new FieldMapping("Id") { TargetFieldName = "HotelId" });
// Reset the indexer if it already exists
try
{
await indexerClient.GetIndexerAsync(blobIndexer.Name);
await indexerClient.ResetIndexerAsync(blobIndexer.Name);
}
catch (RequestFailedException ex) when (ex.Status == 404) { }
await indexerClient.CreateOrUpdateIndexerAsync(blobIndexer);
try
{
// Run the indexer.
await searchService.Indexers.RunAsync(blobIndexer.Name);
}
catch (CloudException e) when (e.Response.StatusCode == (HttpStatusCode)429)
{
Console.WriteLine("Failed to run indexer: {0}", e.Response.Content);
}
由于索引已填充Azure Cosmos DB数据库中的酒店数据,因此 blob 索引器将更新索引中的现有文档并添加房间详细信息。
注意
如果两个数据源中具有相同的非键字段,并且这些字段中的数据不匹配,索引将包含最近运行索引器的值。 在我们的示例中,这两个数据源都包含一个 HotelName 字段。 如果出于某种原因,此字段中的数据不同,对于具有相同键值的文档, HotelName 来自最近编制索引的数据源中的数据是存储在索引中的值。
搜寻
运行程序后,可以在Azure门户中使用 Search explorer 浏览填充的搜索索引。
在 Azure 门户中,转到你的搜索服务。
在左窗格中,选择 “搜索管理>索引”。
从索引列表中选择 酒店-房间示例 。
在 “搜索资源管理器 ”选项卡上,输入类似字词
Luxury的查询。你应该在结果中看到至少一个文档。 本文档应包含其
Rooms数组中的房间对象列表。
重置并重新运行
在开发初期的实验阶段,设计迭代的最实用方法是从Azure AI Search中删除对象,并允许代码重新生成它们。 资源名称是唯一的。 删除某个对象后,可以使用相同的名称重新创建它。
此示例代码将检查现有对象并将其删除或更新,使你能够重新运行程序。 还可以使用 Azure 门户删除索引、索引器和数据源。
清理资源
在自己的订阅中操作时,最好在项目结束时移除不再需要的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
可以使用左窗格中的“所有资源”或“资源组”链接在Azure门户中查找和管理资源。
后续步骤
熟悉从多个源引入数据后,请仔细了解索引器配置,从Azure Cosmos DB开始: