本文档介绍如何评估运行 Azure Service Fabric 应用程序所需的资源量(CPU、RAM 和磁盘存储空间)。 资源要求经常会随着时间而变化。 开发/测试服务时需要的资源通常很少,之后进入生产环境且应用程序受欢迎度提高时需要的资源会更多。 设计应用程序时,应仔细规划长期要求并做出选择,以便到时服务可以缩放以应对较高的客户需求。
创建 Service Fabric 群集时,请确定构成群集的虚拟机 (VM) 类型。 每个 VM 附带有限数量的资源,包括 CPU(核心数和速度)、网络带宽、RAM 和磁盘存储空间。 服务随着时间而发展时,可以升级到可提供更多资源的 VM 和/或将更多 VM 添加到群集。 若要采用后一种措施,最初必须架构好服务,使它可以利用动态添加到群集的新 VM。
某些服务本身只能管理 VM 上的少量数据或无法管理任何数据。 因此,这些服务的容量规划应注重于性能,这意味着要选择适当的 VM CPU(核心和速度)。 此外,应该考虑网络带宽,包括发生网络传输的频率以及要发送的数据量。 随着服务使用量的增加,如果服务需要运行良好,则可以将更多 VM 添加到群集,并跨所有 VM 来负载均衡网络请求。
针对管理 VM 上大量数据的服务,容量规划应该注重于大小。 因此,应仔细考虑 VM 的 RAM 和磁盘存储容量。 Windows 中的虚拟内存管理系统可让应用程序代码将磁盘空间视为 RAM。 此外,Service Fabric 运行时提供智能分页,只将热数据保留在内存中,将冷数据移到磁盘。 因此,应用程序可以使用比 VM 上实际可用数量更多的内存。 增加 RAM 会提高性能,因为 VM 可以在 RAM 中保留更多磁盘存储空间。 选择的 VM 要有够大的磁盘空间来存储想要放在 VM 上的数据。 同样,VM 也要有足够的 RAM,可提供所需的性能。 如果服务随着时间而发展,可以将更多 VM 添加到群集,并跨所有 VM 分区数据。
确定需要多少个节点
将服务分区可以扩展服务的数据。 有关分区的详细信息,请参阅对 Service Fabric 进行分区。 必须将每个分区放入单个 VM,但也可以将多个(小型)分区放入单个 VM。 因此,相比少量的大型磁盘分区,大量小型分区可提供更大的弹性。 缺点是增加分区会增大 Service Fabric 的负担,并且无法跨分区执行事务操作。 如果服务代码经常需要访问位于不同分区的数据片段,则还可能会产生更多的网络流量。 设计服务时,应该仔细考虑这些优缺点,以实现有效的分区策略。
假设应用程序包含单个有状态服务,该服务的存储大小在一年内预期会增加到 DB_Size GB。 在这种情况下,会想要添加更多的应用程序(与分区),以应对该年度后的存储增长。 复制因数 (RF),确定服务的副本数对 DB_Size 总计的影响。 复制因数乘以 DB_Size 即为所有副本的 DB_Size 总计。 Node_Size 表示想要用于服务的每节点磁盘空间/RAM。 为了获得最佳性能,应该使 DB_Size 适应各群集的内存量,并使 Node_Size 大约等于所选 VM 的 RAM 容量。 通过分配大于 RAM 容量的 Node_Size,可以依赖于 Service Fabric 运行时提供的分页。 因此,如果整个数据都被视为热数据(因为从那时起数据进入分页/移出分页),性能就可能无法达到最佳。 但是,对于只有一部分数据是热数据的许多服务而言,还是具有很高的成本效益。
为了获得最大性能所需的节点数目可根据以下公式计算:
Number of Nodes = (DB_Size * RF)/Node_Size
考虑增长
除了最初使用的 DB_Size,可能需要根据预期服务增长的 DB_Size 来计算节点。 然后,随服务发展增加节点数量,这样就不会过度预配节点数量。 但是,分区数目应该基于以最大增长率运行服务时所需的节点数。
最好随时准备几台额外的计算机,以便可以处理任何意外的高峰或故障(例如,一些 VM 停机)。 尽管额外的容量要使用预期高峰来确定,但一开始可以多预留几个 VM(额外准备 5-10%)。
上面假设只有一个有状态服务。 如果有多个有状态服务,则必须将与其他服务关联的 DB_Size 添加到公式中。 或者,可以单独为每个有状态服务计算节点数。 服务可能包含不平衡的副本或分区。 请记住,有些分区的数据可能比其他分区要多。 有关分区的详细信息,请参阅分区最佳实践文章。 但是,上述公式不受分区或副本影响,因为 Service Fabric 可确保副本以优化方式分散在节点之间。
使用电子表格进行成本计算
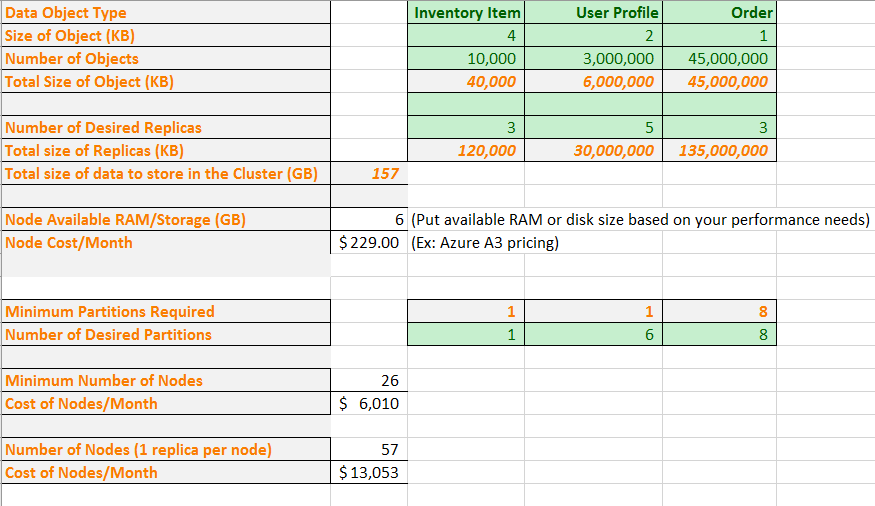
现在,让我们在公式中放入一些实际数字。 示例电子表格显示如何规划包含三种数据对象类型的应用程序的容量。 针对每个对象,我们将估算其大小以及预期需要的对象数。 我们还将选择对每个对象类型需要的副本数。 电子表格将计算要在群集中存储的内存量总计。
然后,输入 VM 大小和每月成本。 根据 VM 大小,电子表格将告诉你必须至少要提供多少个分区才能拆分数据,使其能够实际包含在节点中。 可能需要大量的分区才能应对应用程序的特定计算和网络流量需求。 电子表格显示目前管理用户配置文件对象的分区数已从 1 个增加到 6 个。
现在,根据所有这些信息,电子表格会显示你实际可以获取包含 26 个节点的群集上所需分区和副本的所有数据。 但是,此群集将密集压缩,因此,可能想要添加一些节点来应对节点故障和升级。 电子表格还显示,节点数超过 57 个不会带来任何附加价值,因为这会出现空节点。 不过,可能仍然想要配置超过 57 个节点,以应对节点故障和升级。 可以根据应用程序的特定需求调整电子表格。
后续步骤
查看 Service Fabric 服务分区,了解有关对服务进行分区的详细信息。