本文介绍 Azure Service Fabric Reliable Services 分区的基本概念。 使用分区可以将数据存储在本地计算机上,以便数据和计算可以一起扩展。
提示
GitHub 上提供了本文中代码的完整示例。
分区
分区并不是 Service Fabric 所独有的。 事实上,它是构建可缩放服务的核心模式。 从更广泛的意义来说,可将分区视为将状态(数据)和计算划分为更小的可访问单元,以提高可伸缩性和性能的一种概念。 数据分区是一种众所周知的分区形式,也称为分片。
Service Fabric 分区无状态服务
对于无状态服务,可以将分区视为包含服务的一个或多个实例的逻辑单元。 图 1 显示一个无状态服务,其五个实例使用一个分区在群集中分布。
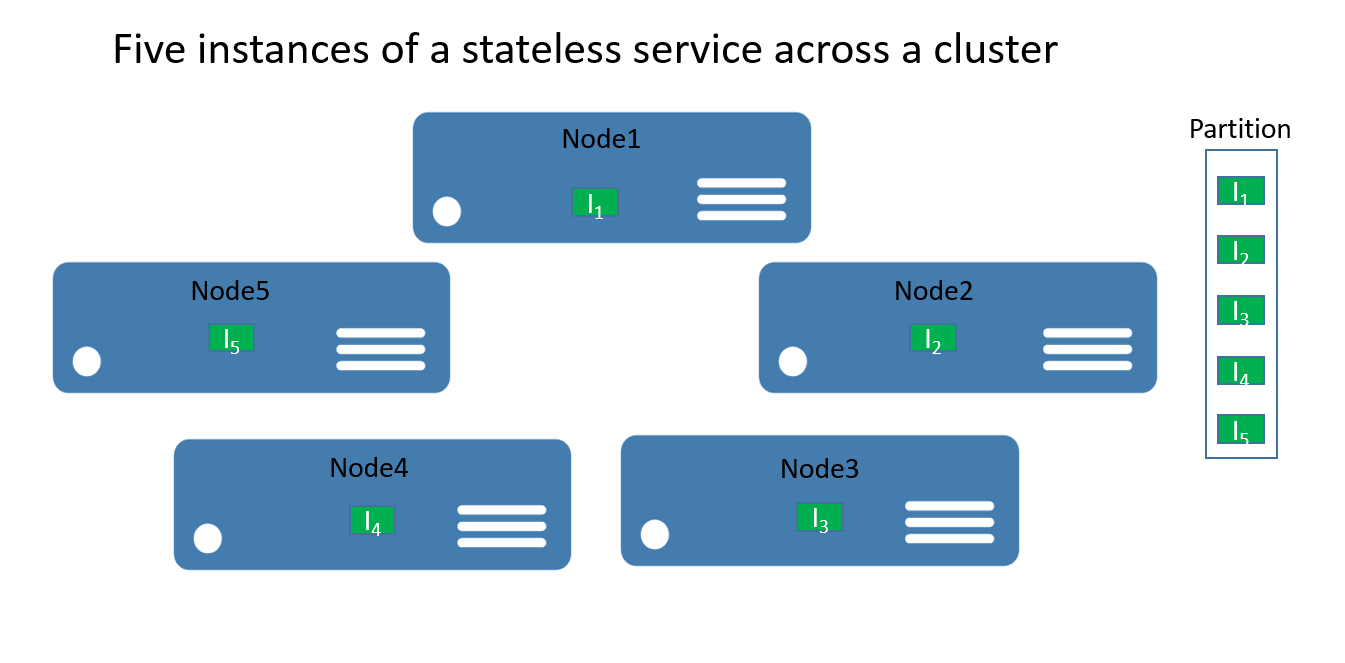
实际上有两种类型的无状态服务解决方案。 第一种是在外部(例如在 Azure SQL 数据库中的数据库中)保持其状态的服务(如存储会话信息和数据的网站)。 第二个服务是纯计算服务(如计算器或图像缩略图生成),不管理任何持久状态。
在任一情况下,对无状态服务进行分区是一种罕见的方案-可伸缩性和可用性通常通过添加更多实例来实现。 对于无状态服务实例要考虑多个分区的唯一情况是在需要满足特殊路由请求时。
例如,考虑以下这种情况:ID 处于特定范围内的用户只应该由特定服务实例提供服务。 可以分区无状态服务的另一个示例是,当您拥有真正分区的后端(例如 SQL 数据库中的分片数据库)时,并且希望控制哪个服务实例应写入数据库分片,或者在无状态服务中执行其他准备工作,而这些准备工作需要使用与后端相同的分区信息。 这些类型的方案也可以以不同的方式解决,不一定需要服务分区。
本演练的其余部分侧重于有状态服务。
分区 Service Fabric 有状态服务
Service Fabric 提供了一种一流的状态(数据)分区方式,使得开发可扩展的有状态服务变得更加容易。 从概念上讲,可以将有状态服务的分区视为一种使用分布并在群集中的节点之间平衡的副本实现高度可靠性的伸缩单位。
在 Service Fabric 有状态服务的上下文中进行分区是指确定特定服务分区负责服务完整状态的某个部分的过程。 (如前所述,分区是一组副本)。 Service Fabric 的一大优点是它将分区置于不同节点上。 这使它们可以增长到节点的资源上限。 随着数据需求的增长,分区也会增长,Service Fabric 会在节点间重新平衡分区。 这可确保硬件资源的持续高效使用。
例如,假设开始时拥有一个 5 节点群集,以及一个配置为具有 10 个分区并且目标为 3 个副本的服务。 在这种情况下,Service Fabric 会在群集间均衡分布副本,最终每个节点会有两个主副本。 如果现在需要将群集扩大到 10 个节点,则 Service Fabric 会在所有 10 个节点间重新均衡主副本。 同样,如果重新缩小为 5 个节点,则 Service Fabric 会在 5 个节点间重新平衡所有副本。
图 2 显示缩放群集之前和之后的 10 个分区的分布。
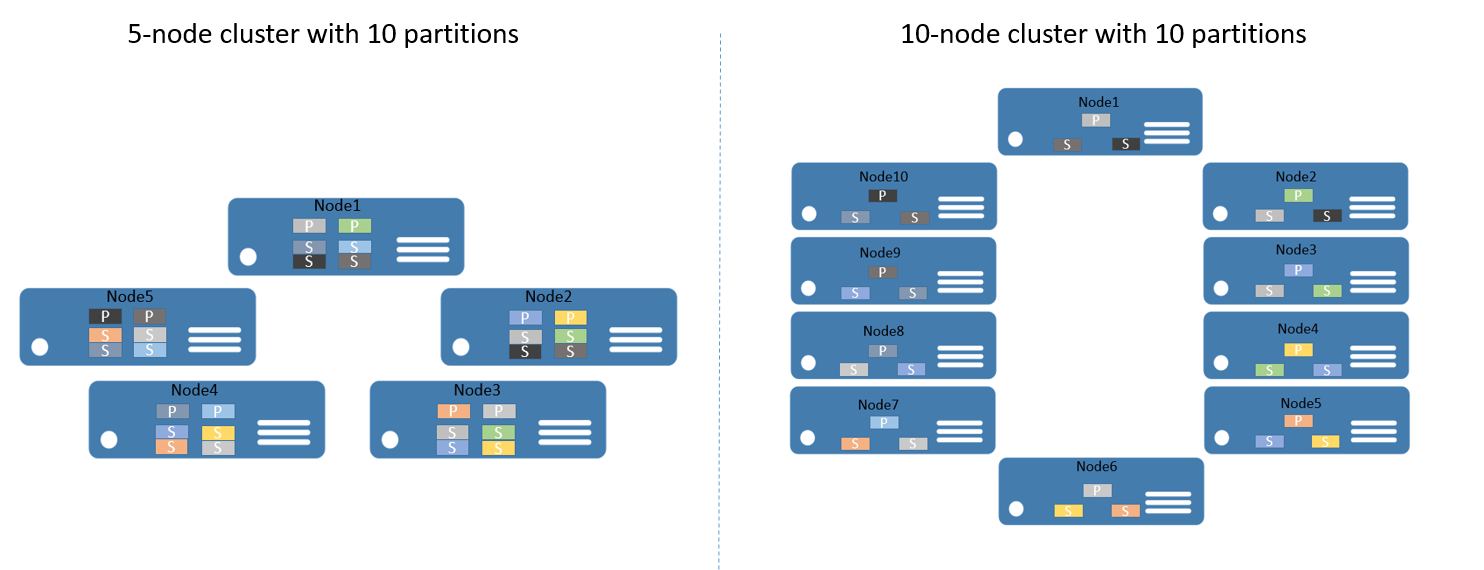
因此,通过将来自客户端的请求分布到多台计算机,实现了水平扩展,提升了应用程序的整体性能,并减少了对数据块的资源竞争。
为分区进行规划
实现服务之前,应始终考虑扩大所需的分区策略。可使用不同方式,但所有方式都注重应用程序需要实现的功能。 由于本文的背景,我们来考虑一些更重要的方面。
一个不错的方法是首先思考需要分区的状态结构。
让我们探讨一个示例。 如果要为全县投票生成一个服务,则可以为县内的每个城市创建一个分区。 随后可以在对应于该城市的分区中为城市中的每个人存储投票。 图 3 显示一组人及其所在的城市。
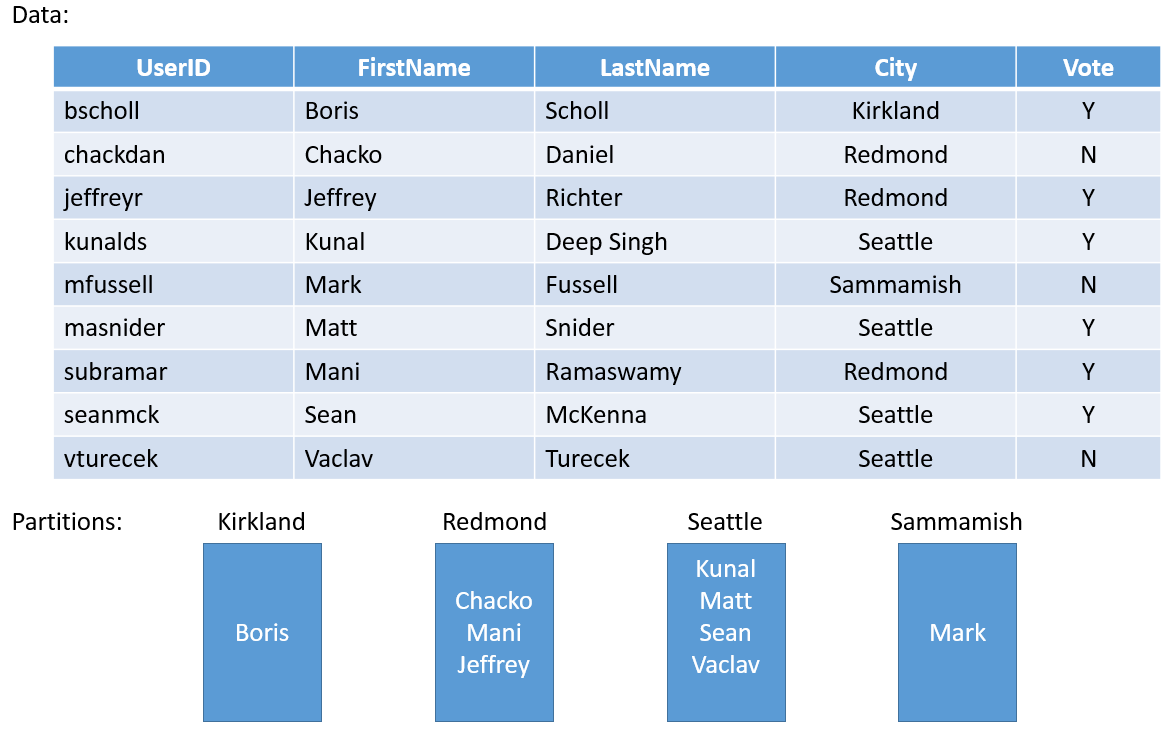
随着城市人口变化很大,最终可能会有一些分区包含大量数据(例如西雅图)和其他几乎没有州(例如柯克兰)的分区。 那么分区具有不均匀的状态数量会有什么影响呢?
如果再次考虑该示例,便可以很容易地发现为西雅图保存投票的分区获得的流量会多于柯克兰的相应分区。 默认情况下,Service Fabric 可确保每个节点上的主副本和辅助副本数量大致相同。 因此,最后可能会有一些节点存放的副本处理较多流量,而其他节点处理较少流量。 最好在群集中避免出现这样的热点和冷点。
为避免出现这种情况,从分区的角度来看,应做两件事:
- 尝试对状态进行分区,使其均匀分布在所有分区中。
- 从服务的各个副本提供负载信息。 (有关操作方法的信息,请查看这篇有关指标和负载的文章)。 Service Fabric 可以报告服务消耗的负载,例如内存量或记录数。 根据报告的指标,Service Fabric 会检测到某些分区处理的负载高于其他分区,并通过将副本移动到更合适的节点来重新平衡群集,以便在整体上不会有节点超载。
有时,你不知道给定分区中的数据量。 因此,常规建议是执行以下两种操作:首先是采用在分区间均匀分布数据的分区策略,其次是报告负载。 第一种方法可防止投票示例中描述的情况,而第二种方法可帮助随时间推移而消除访问或负载的中的临时差异。
分区规划的另一个方面是选择开始时要采用的正确分区数。 从 Service Fabric 的角度来看,没有什么能阻止你从比方案预期更多的分区开始。 事实上,采用最大数量的分区是一种有效方法。
在极少数情况下,您最终可能需要比最初选择的分区更多。 由于此时不能更改分区计数,因此需要应用一些高级分区方法,例如创建同一服务类型的新服务实例。 您还需要实现一些客户端逻辑,该逻辑会基于客户端代码必须维护的知识,将请求路由到正确的服务实例。
分区规划的另一个注意事项是可用计算机资源。 由于需要访问和存储状态,因此你必须遵循以下各项:
- 网络带宽限制
- 系统内存限制
- 磁盘存储限制
那么,如果在正在运行的群集中遇到资源限制时会发生什么情况呢? 答案是只需简单地扩大群集即可,以适应新需求。
容量规划指南提供有关如何确定群集需要的节点数的指导。
开始进行分区
本部分介绍如何开始对服务进行分区。
Service Fabric 提供了三个分区方案可供选择:
- 按范围分区(也称为 UniformInt64Partition)。
- 命名的分区 使用此模型的应用程序通常具有可以在有限集合中分桶的数据。 用作命名分区键的数据字段的一些常见示例是区域、邮政编码、客户组或其他业务边界。
- 单独分区。 当服务不需要任何其他路由时,通常会使用单例分区。 例如,无状态服务在默认情况下使用此分区方案。
命名和单独分区方案是范围分区的特殊形式。 默认情况下,Service Fabric 的 Visual Studio 模板使用范围分区,因为它是最常见的和有用的分区。 本文余下部分将重点讨论范围分区方案。
范围分区方案
此方案用于指定整数范围(由低键和高键标识)和分区数目 (n)。 它会创建 n 个分区,每个分区负责整个分区键范围的未重叠子范围。 例如,一个采用低键 0、高键 99 和计数 4 的范围分区方案会创建如下所示的 4 个分区。
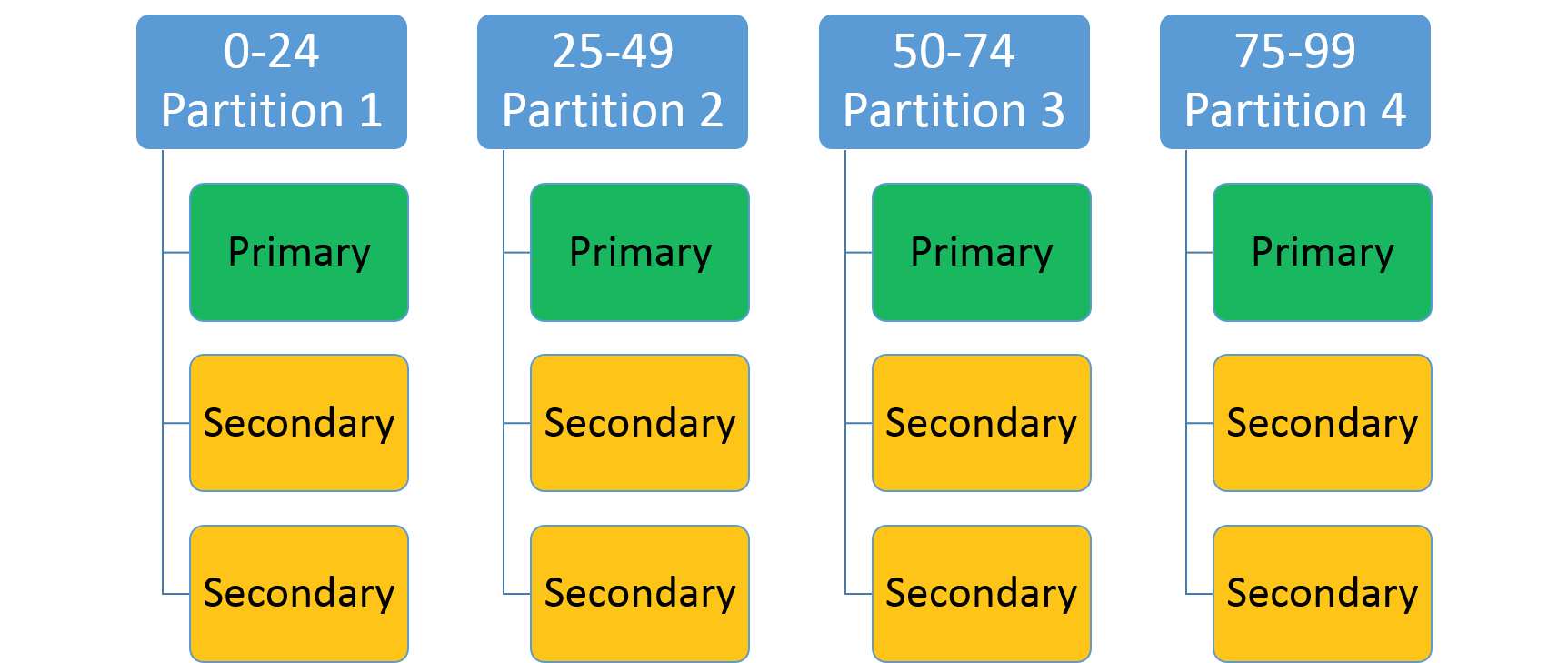
一种常见方法是基于数据集中的唯一键创建哈希。 一些常见的键示例有:车辆识别号 (VIN)、员工 ID 或唯一字符串。 随后使用此唯一键生成一个哈希代码,并对其进行键范围的取模运算,以用作您的键。 可以指定所允许键范围的上限和下限。
选择哈希算法
哈希法的重要部分是选择哈希算法。 一个考虑事项是:目标是否是对相邻的类似键进行分组(局部敏感哈希法)— 或者活动是否应广泛分布在所有分区上(分发哈希法),后者更加常见。
良好的分发哈希算法的特征是易于计算,几乎没有冲突,并且均匀地分发键。 高效的哈希算法的一个很好示例是 FNV-1
哈希算法。
有关选择常规哈希代码算法的一个很好的资源是哈希函数的维基百科网页
。
生成具有多个分区的有状态服务
让我们创建您的第一个具有多个分区的可靠有状态服务。 在此示例中,会生成一个非常简单的应用程序,在其中要以相同字母开头的所有姓氏存储在相同分区中。
编写任何代码之前,需要考虑分区和分区键。 需要 26 个分区(每个字母对应一个分区),那么低键和高键又如何处理呢? 由于我们确实想要为每个字母设置一个分区,所以可以选择使用0作为低键,25作为高键,因为每个字母都是自己的键。
注意
这是简化方案,因为在现实情况下分布是不均匀的。 以字母“S”或“M”开头的姓氏比以“X”或“Y”开头的姓氏更常见。
打开 Visual Studio>文件>新建>项目。
在“新建项目”对话框中,选择 Service Fabric 应用程序。
将项目命名为“AlphabetPartitions”。
在“创建服务”对话框中,选择“有状态”服务,并将其命名为“Alphabet.Processing”。
设置分区数。 打开 AlphabetPartitions 项目的 ApplicationPackageRoot 文件夹中的 ApplicationManifest.xml 文件,然后将参数 Processing_PartitionCount 更新为 26,如下所示。
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />还需要更新 ApplicationManifest.xml 中 StatefulService 元素的 LowKey 和 HighKey 属性,如下所示。
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>此外,为了使服务可访问,需要在服务的某个端口上开启一个终结点。为实现这一点,请在 PackageRoot 文件夹中的 ServiceManifest.xml 文件中添加 Alphabet.Processing 服务的终结点元素,如下所示:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />现在服务已配置为侦听具有 26 个分区的内部终结点。
接下来,您需要重写 Processing 类的
CreateServiceReplicaListeners()方法。注意
对于此示例,我们假定使用一个简单的HTTP通信侦听器。 有关 Reliable Service 通信的详细信息,请参阅 Reliable Service 通信模型。
副本所侦听的 URL 的建议格式为以下格式:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}。 因此,要将通信侦听器配置为正确的终结点进行监听,并采用该模式。可以在同一台计算机上托管此服务的多个副本,因此此地址需要是副本独有的。 这就是 URL 中包含分区 ID 和副本 ID 的原因。 HttpListener 可以在同一端口上侦听多个地址,只要 URL 前缀是唯一的。
额外的GUID用于高级场景,其中辅助副本也会侦听只读请求。 如果出现这种情况,您需要确保在从主系统转换到辅助系统时使用新的唯一地址,以便强制客户端重新解析该地址。 “+”在此处用作地址,以便副本在所有可用主机(IP、FQDN、localhost 等)上进行侦听下面的代码演示一个示例。
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }此外,值得注意的是已发布的 URL 与侦听 URL 前缀略有不同。 监听 URL 被指定给 HttpListener。 发布的 URL 是发布到 Service Fabric 命名服务(用于服务发现)的 URL。 客户端会通过该发现服务请求此地址。 客户端获取的地址需要具有节点的实际 IP 或 FQDN 才能连接。 因此需要将“+”替换为节点的 IP 或 FQDN,如上所示。
最后一步是将处理逻辑添加到服务,如下所示。
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequest会读取用于调用分区的查询字符串参数值,并调用AddUserAsync将姓氏添加到可靠字典dictionary。让我们将一个无状态服务添加到项目,以查看如何调用特定分区。
此服务可用作简单 Web 界面,它接受姓氏作为查询字符串参数,确定分区键,并将它发送到 Alphabet.Processing 服务进行处理。
在“创建服务”对话框中,选择“无状态”服务并将它称为“Alphabet.Web”,如下所示 。
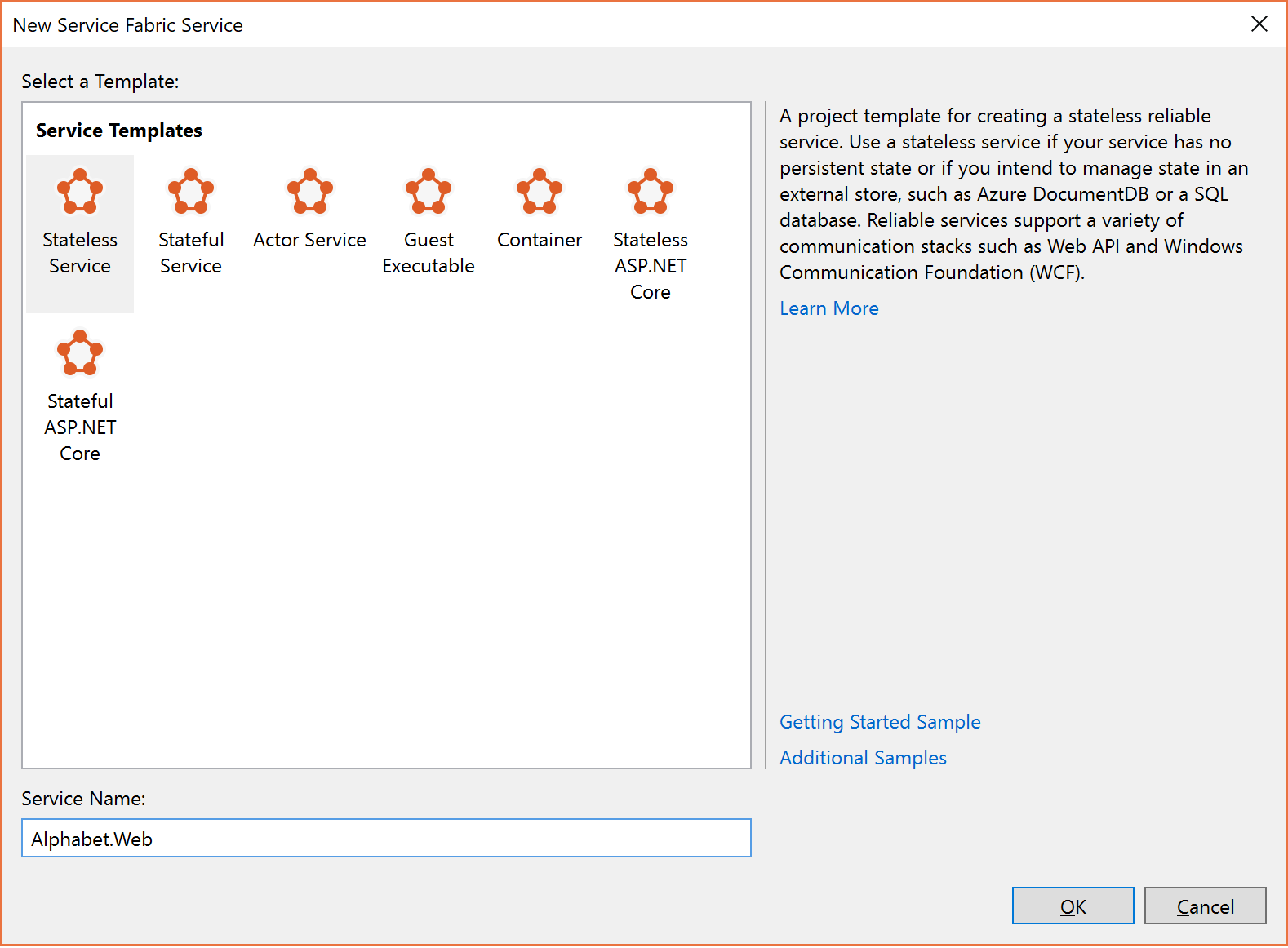 .
.在 Alphabet.WebApi 服务的 ServiceManifest.xml 中更新终结点信息,以打开端口,如下所示。
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>需要在 Web 类中返回 ServiceInstanceListeners 的集合。 同样,您可以选择实现一个简单的 HttpCommunicationListener。
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }现在需要实现处理逻辑。 HttpCommunicationListener 在请求进入时调用
ProcessInputRequest。 让我们添加下面的代码。private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }让我们逐步演练其步骤。 此代码将查询字符串参数
lastname的第一个字母读入一个字符中。 然后,通过从姓氏第一个字母的十六进制值中减去A的十六进制值,确定该字母的分区键。string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');请记住,对于此示例,我们在使用 26 个分区,其中每个分区有一个分区键。 接下来,通过对
partition对象使用ResolveAsync方法,获取此键的服务分区servicePartitionResolver。servicePartitionResolver定义为private readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();ResolveAsync方法采用服务 URI、分区键和取消标记作为参数。 处理服务的服务 URI 为fabric:/AlphabetPartitions/Processing。 接下来,我们会获取分区的终结点。ResolvedServiceEndpoint ep = partition.GetEndpoint()最后,我们会生成终结点 URL 以及查询字符串,并调用处理服务。
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);处理完成之后,我们会将输出写回。
最后一步是测试服务。 Visual Studio 将应用程序参数用于本地和云部署。 要在本地测试具有 26 个分区的服务,需要在 AlphabetPartitions 项目的 ApplicationParameters 文件夹中更新
Local.xml文件,如下所示:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>完成部署之后,可以在 Service Fabric Explorer 中检查服务及其所有分区。
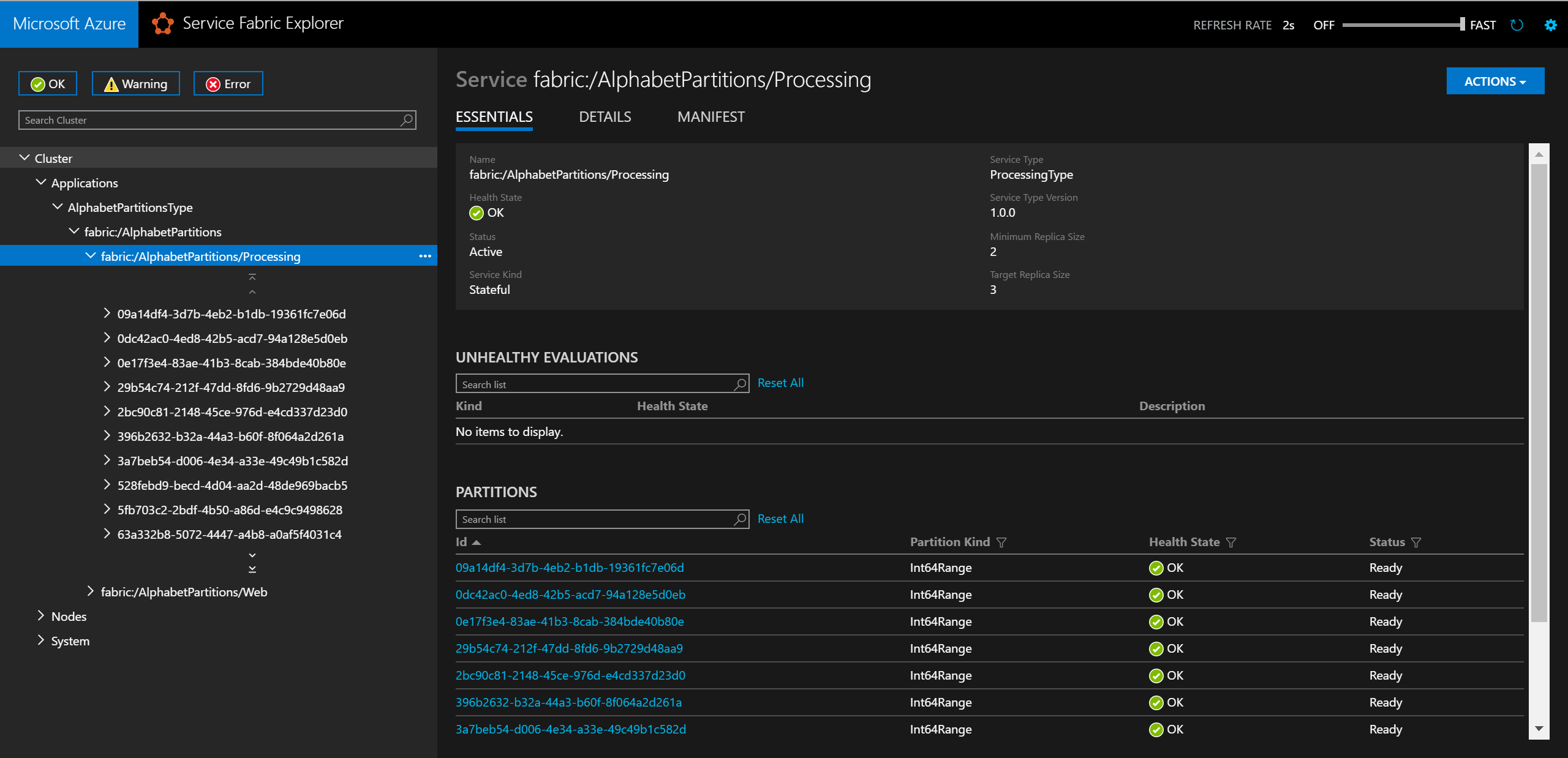
在浏览器中,可以输入
http://localhost:8081/?lastname=somename来测试分区逻辑。 会看到以相同字母开头的每个姓氏都存储在相同分区中。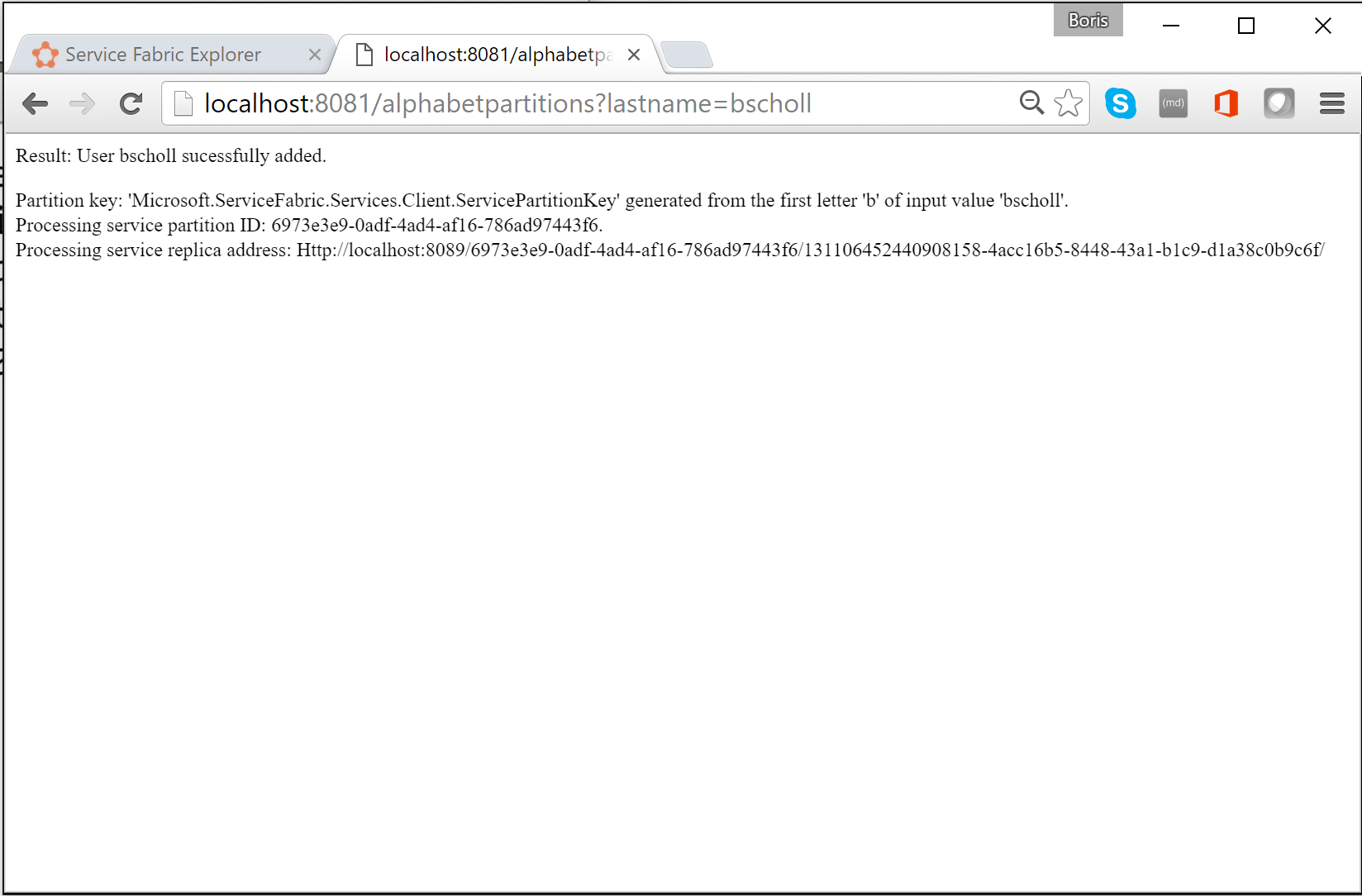
本文中使用的代码的完整解决方案可在此获取: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions 。
后续步骤
了解 Service Fabric 服务的详细信息: