本文讨论 Azure Site Recovery 部署规划器为 VMware 到 Azure 方案生成的 Excel 报表中包含的工作表。
若要生成成本报表,请参阅 运行部署规划器并生成 VMware 灾难恢复的成本报告。
本地摘要
“本地部署摘要”工作表提供了经过分析的 VMware 环境的概览。
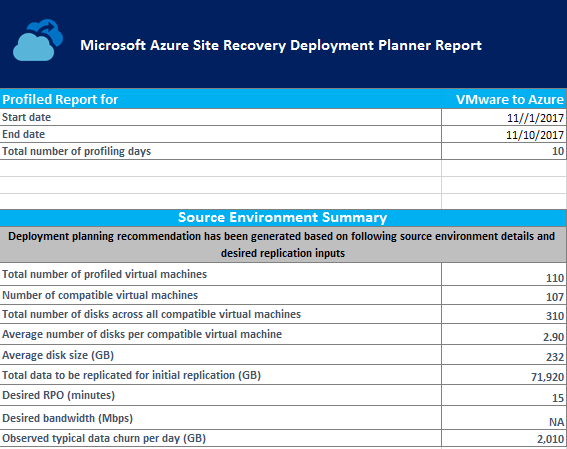
开始日期和结束日期:生成报告时要考虑的分析数据的开始和结束日期。 默认情况下,开始日期是开始分析的日期,结束日期是停止分析的日期。 如果报表是使用这些参数生成的,则这可以是 StartDate 和 EndDate 值。
分析总天数:要生成报告的开始和结束日期之间的分析总天数。
兼容虚拟机的数量:计算所需网络带宽、所需存储帐户数、Azure 核心数、配置服务器和额外进程服务器的兼容虚拟机总数。
所有兼容虚拟机的磁盘总数:此数字用作输入之一,用于确定要在部署中使用的配置服务器和额外进程服务器的数目。
每台兼容虚拟机的平均磁盘数:根据所有兼容虚拟机计算的平均磁盘数。
平均磁盘大小 (GB):根据所有兼容虚拟机计算的平均磁盘大小。
所需 RPO(分钟):这是用于估算所需带宽的默认恢复点目标,或者是报告生成时传递给 DesiredRPO 参数的具体值。
所需带宽 (Mbps):在生成报告时为了估算可实现的 RPO 为 Bandwidth 参数传递的值。
每日观察到的典型数据变动量(GB) :在所有分析日期观察到的平均数据变动量。 此数字用作输入之一,用于确定要在部署中使用的配置服务器和额外进程服务器的数目。
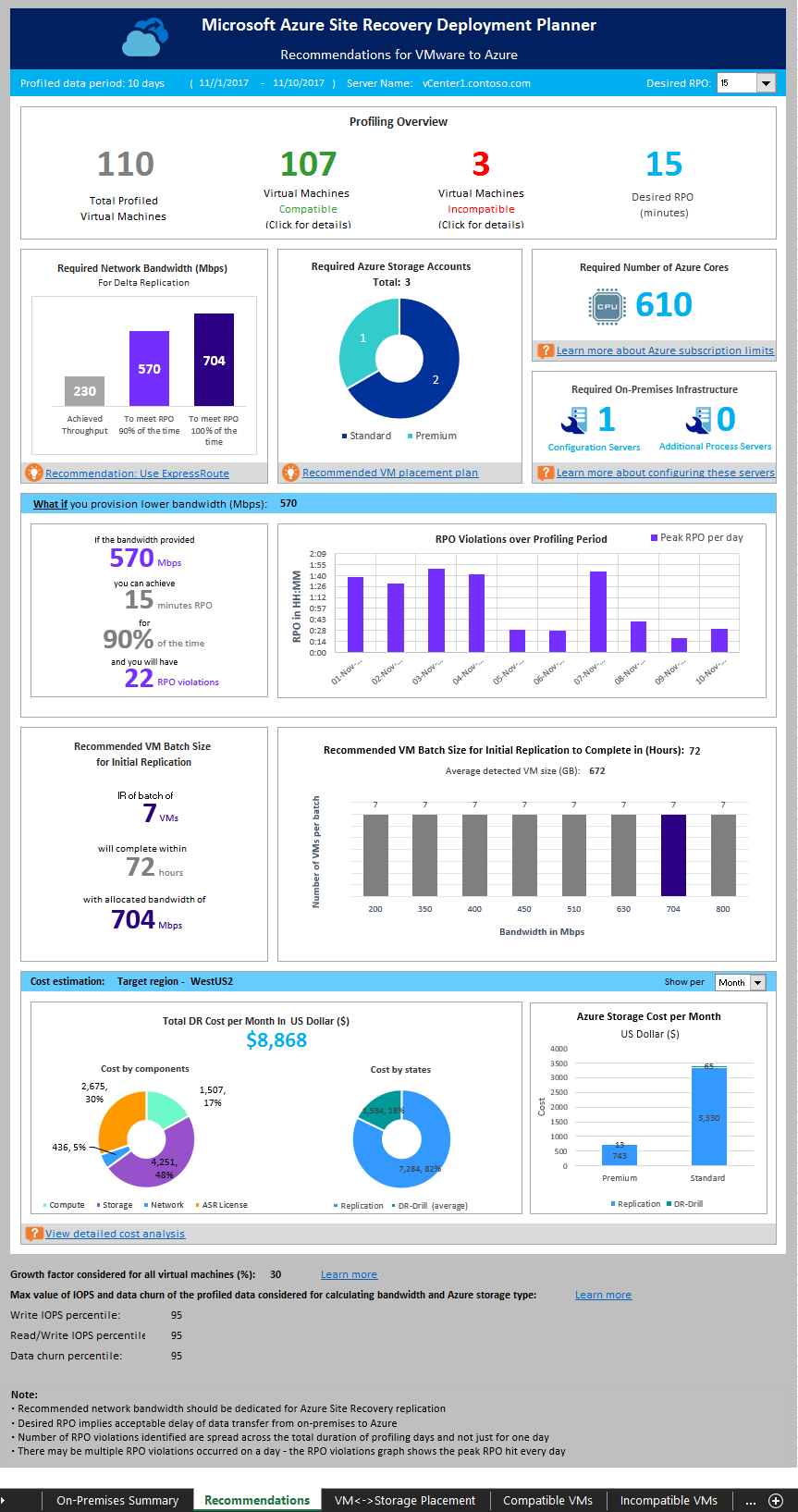
建议
VMware 到 Azure 报表的建议表根据选定的所需 RPO 提供以下详细信息:
概要的数据

数据剖析期:在此期间运行了剖析。 默认情况下,该工具会在计算中包括所有被分析的数据,除非它在生成报告期间使用 StartDate 和 EndDate 选项生成特定时间段的报告。
服务器名称:要生成虚拟机报告的 VMware vCenter 或 ESXi 主机的名称或 IP 地址。
所需 RPO:部署的恢复点目标。 默认情况下,所需网络带宽是根据 RPO 值为 15、30 和 60 分钟计算的。 根据所做的选择,受影响的值会在工作表中更新。 如果生成报告时使用了 DesiredRPOinMin 参数,该值会显示在“所需 RPO”结果中。
性能分析概述

所分析虚拟机总数:其分析数据可用的虚拟机总数。 如果 VMListFile 具有未分析的任何虚拟机的名称,则报表生成会排除这些虚拟机,并且不会将它们计入被分析虚拟机的总数。
兼容虚拟机:可以使用 Site Recovery 在 Azure 中保护的虚拟机数。 所需网络带宽、存储帐户、Azure 核心、配置服务器和其他进程服务器的计算基于兼容虚拟机的总数。 “兼容虚拟机”部分提供了每台兼容虚拟机的详细信息。
不兼容虚拟机:与使用 Site Recovery 进行保护不兼容的被分析虚拟机数。 “不兼容虚拟机”部分说明了不兼容的原因。 如果 VMListFile 中包含任何未分析虚拟机的名称,则将从不兼容虚拟机计数中排除这些虚拟机。 这些虚拟机在“不兼容虚拟机”部分的末尾列出为“找不到数据”。
所需 RPO:以分钟为单位的所需恢复点目标。 针对以下三个 RPO 值生成报告:15 分钟(默认值)、30 分钟和 60 分钟。 会根据你在工作表右上方“所需 RPO”下拉列表中所做的选择来更改报告中的带宽建议。 如果结合某个自定义值使用“-DesiredRPO”参数生成了报告,此自定义值会在“所需 RPO”下拉列表中显示为默认值。
所需的网络带宽 (Mbps)
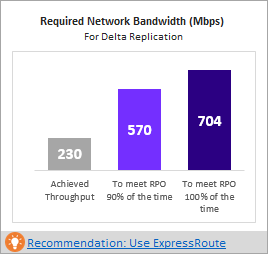
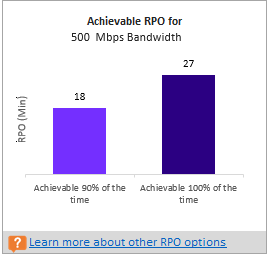
为了在 100% 的时间内满足 RPO:建议分配以 Mbps 为单位的带宽,以便在 100% 的时间内满足所需的 RPO。 这种带宽量必须专门用于执行所有兼容虚拟机的稳态增量复制,以避免任何 RPO 违反。
在 90% 的时间内满足 RPO:如果宽带定价或其他因素阻止你设置在 100% 时间内实现所需 RPO 的必要带宽,则可以选择较低的带宽设置,以在 90% 的时间内实现所需的 RPO。 为了理解设置较低带宽的影响,报告提供了一项关于预期 RPO 违规数目和持续时间的 what-if 假设分析。
实现的吞吐量:从运行 GetThroughput 命令的服务器到存储帐户所在的 Azure 区域的吞吐量。 此吞吐量数字指示了在配置服务器或进程服务器的存储和网络特征与运行该工具的服务器保持相同的前提下,使用 Site Recovery 保护兼容虚拟机时可实现的估计级别。
对于复制,你应设置建议的带宽以确保始终满足 RPO。 在设置带宽后,如果工具所报告的已实现吞吐量没有增长,请执行以下操作:
查看是否有任何网络服务质量 (QoS) 限制了 Site Recovery 吞吐量。
查看 Site Recovery 保管库是否位于从物理上来说最近的受支持 Microsoft Azure 区域,以尽量降低网络延迟。
检查本地存储特征,确定能否改进硬件(例如,从 HDD 升级到 SSD)。
更改进程服务器中的 Site Recovery 设置,增大用于复制的网络带宽量。
如果你是在已保护虚拟机的配置服务器或进程服务器上运行该工具,则请多次运行该工具。 实现的吞吐量数字会发生变化,具体取决于当时处理的数据变动量。
对于所有企业型 Site Recovery 部署,建议使用 ExpressRoute。
所需的存储帐户
下图显示了保护所有兼容虚拟机所需的存储帐户(标准和高级)总数。 要了解每台虚拟机使用哪个存储帐户,请参阅“VM 存储放置”部分。 如果使用部署规划器 v2.5,则此建议仅显示复制所需的标准缓存存储帐户数,因为数据直接写入托管磁盘。

所需的 Azure 核心数
此结果是在对所有兼容虚拟机进行故障转移或测试故障转移之前要设置的核心数量总和。 如果订阅中可用的核心太少,则在执行测试故障转移或故障转移时,Site Recovery 将无法创建虚拟机。

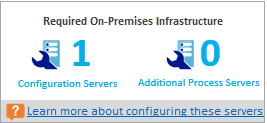
所需的本地基础结构
此图显示的是要配置的配置服务器和额外进程服务器总数,以足以保护所有兼容的虚拟机。 根据所支持的配置服务器大小建议,该工具可能会建议使用额外的服务器。 该建议取决于每日流失量和最大受保护虚拟机数目(假设每台虚拟机平均三个磁盘)哪一个更大,即在配置服务器或附加进程服务器上最先达到两者中的哪一个。 在“本地摘要”部分可以找到每天总变动量和受保护磁盘总数的详细信息。
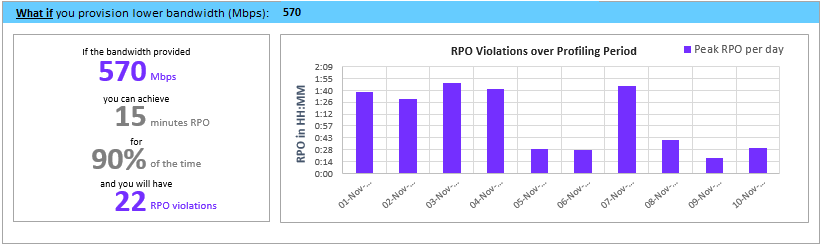
假设分析
此项分析概述了如果设置较低的带宽,导致只能在 90% 的时间内满足所需 RPO,则在分析期间可能会发生多少项违规。 在任何给定的日期可能会发生一项或多项 RPO 违规。 下图显示了一天的峰值 RPO。 根据此分析,您可以决定在使用指定的较低带宽的情况下,所有天数的 RPO 违规次数以及每日 RPO 峰值是否可以接受。 如果可以接受,则可为复制分配较低的带宽,否则,应根据建议分配更高的带宽来满足 100% 时间的所需 RPO。
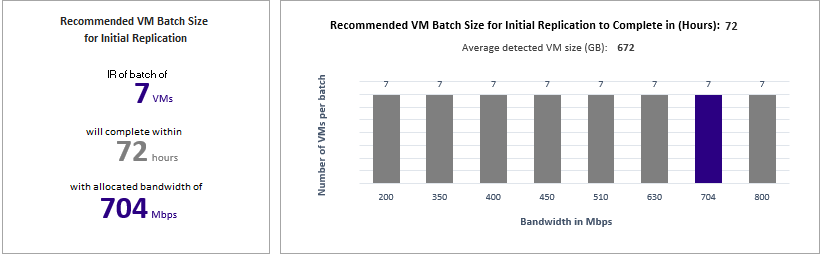
建议用于初始复制的虚拟机批大小
在本部分,我们建议了可以并行保护的虚拟机数量,以便在 72 小时内使用建议的带宽完成初始复制,从而在所有情况下始终满足所设定的所需 RPO。 此值是可以配置的值。 若要在生成报告时对其进行更改,请使用“GoalToCompleteIR” 参数。
此处图中显示了用于根据所有兼容虚拟机上检测到的平均虚拟机大小,在 72 小时内完成初始复制的一系列带宽值和计算出的虚拟机批大小计数。
在公共预览版状态下,报告不会指定应在批中包含哪些虚拟机。 可以使用“兼容虚拟机”部分显示的磁盘大小查找每台虚拟机的大小,并选择它们加入批次,也可以根据已知的工作负载特征选择虚拟机。 初始复制的完成时间会根据实际虚拟机磁盘大小、已用磁盘空间和可用的网络吞吐量按比例更改。
按组件成本:总 DR 成本分为四个部分:计算成本、存储成本、网络成本和 Azure Site Recovery 许可证成本。 成本计算基于在复制期间以及 DR 演练时产生的使用量,涵盖计算、存储(高级和标准)、在本地站点与 Azure 之间配置的 ExpressRoute/VPN 以及 Azure Site Recovery 许可证。
按州分类的成本:总灾难恢复 (DR) 成本是基于两种不同状态进行分类的——复制和DR演练。
复制成本:复制期间产生的成本, 涵盖存储成本、网络成本、Azure Site Recovery 许可证成本。
DR 演练成本:测试性故障转移期间产生的成本。 Azure Site Recovery 会在测试性故障转移期间启动虚拟机。 DR 演练成本涵盖虚拟机运行中的计算和存储成本。
每月/年的 Azure 存储成本 显示针对高级和标准存储进行复制和灾难恢复 (DR) 演练时产生的总存储成本。
增长系数和使用的百分位值
工作表底部的此部分显示用于已分析虚拟机的所有性能计数器的百分位值(默认为第 95 百分位),以及所有计算中使用的增长系数(默认为 30%)。

以可用带宽作为输入的推荐方案

可能会遇到一种情况,您知道无法为 Site Recovery 复制设置超过 x Mbps 的带宽。 在该工具中可以输入可用带宽(生成报告时使用 -Bandwidth 参数),在数分钟内就能获得可实现的 RPO。 使用这个可实现的 RPO 值,可以确定是需要设置额外的带宽,还是可以接受可实现此 RPO 的灾难恢复解决方案。
虚拟机存储分配策略
注意
部署规划器v2.5及更高版本推荐计算机的存储位置,以便直接复制到托管磁盘。
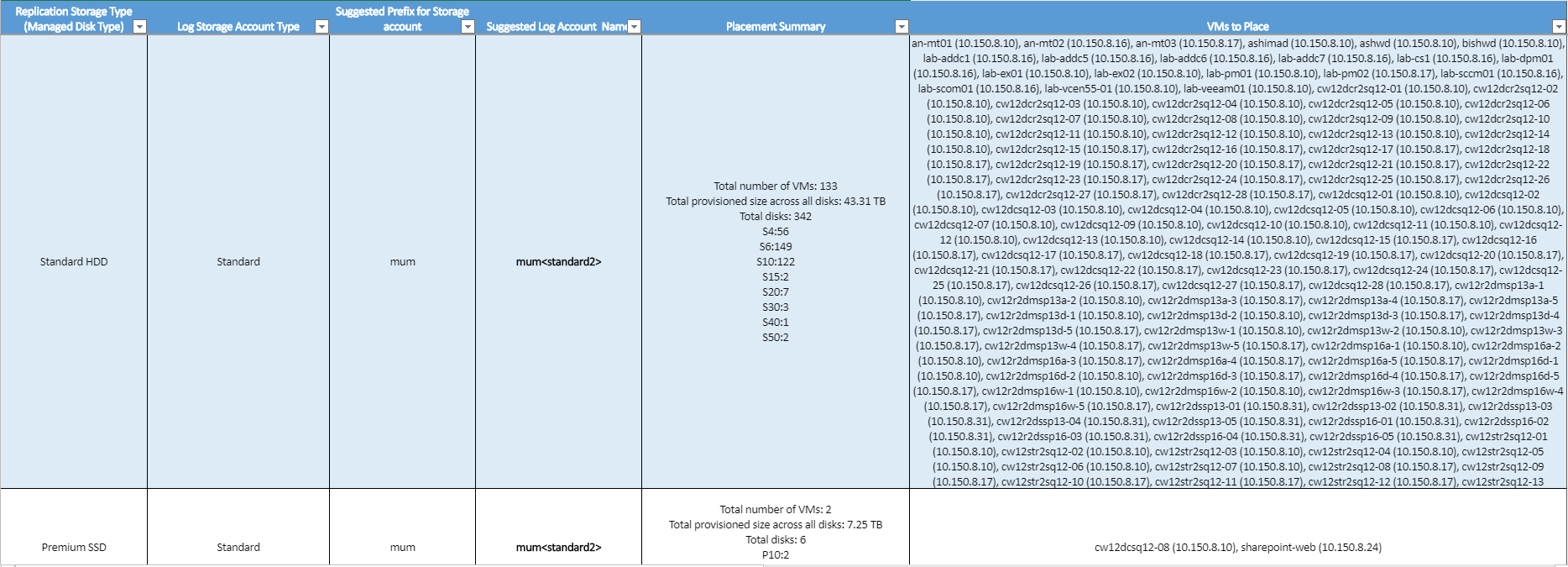
复制存储类型:标准或高级托管磁盘,用于复制“要放置的虚拟机”列中提及的所有相应虚拟机。
日志存储帐户类型:所有复制日志存储在标准存储帐户中。
建议的存储帐户前缀:建议的三字符前缀,可用于缓存存储帐户的命名。 可以使用自己的前缀,而该工具的建议则遵循存储帐户的分区命名约定。
建议的日志帐户名称:在使用建议的前缀后出现的存储帐户名称。 将尖括号(< 和 >)中的名称替换为自定义输入。
概述:按存储类型列出的被保护的虚拟机所需的磁盘摘要。 它包括虚拟机总数、所有磁盘上预配的总大小,以及磁盘总数。
要放置的虚拟机:应在给定存储帐户上放置以实现最佳性能和用法的所有虚拟机的列表。
兼容虚拟机
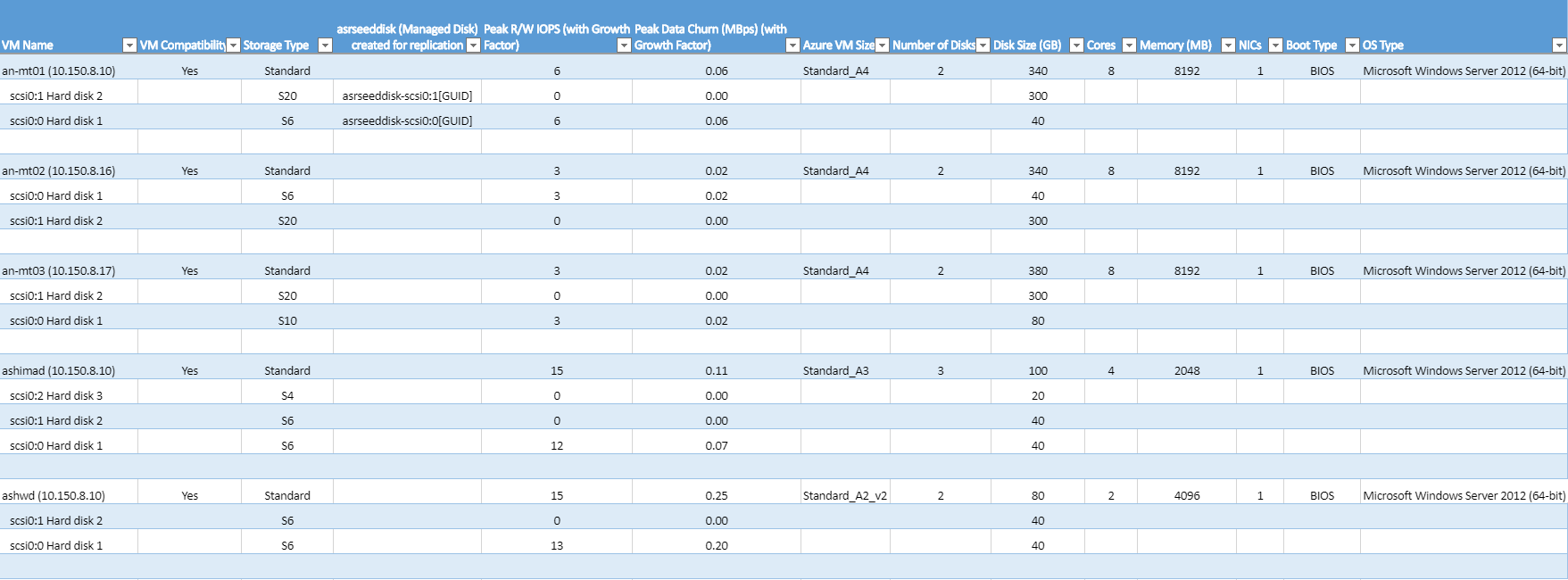
虚拟机名称:生成报表时在 VMListFile 中使用的虚拟机名称或 IP 地址。 此列还列出了附加到虚拟机的磁盘 (VMDK)。 为了区分使用重复名称或 IP 地址的 vCenter 虚拟机,这些名称包含了 ESXi 主机名称。 列出的 ESXi 主机是工具在分析期间发现虚拟机时放置虚拟机的主机。
虚拟机兼容性:值为 “是”和“是*”。 是* 用于虚拟机适合 高级 SSD 的情况。 在这里,所分析的高频读写或每秒输入输出操作 (IOPS) 磁盘适合 P20 或 P30 类别,但由于磁盘大小,它被向下映射到 P10 或 P20 类别。 存储帐户根据磁盘的大小来决定将其映射到哪种高级存储磁盘类型。 例如:
- <128 GB 为 P10。
- 128 GB 到 256 GB 为 P15
- 256 GB 到 512 GB 为 P20。
- 512 GB 到 1024 GB 为 P30。
- 1025 GB 到 2048 GB 为 P40。
- 2049 GB 到 4095 GB 为 P50。
例如,如果某个磁盘按工作负载特征应归入 P20 或 P30 类别,但磁盘大小将其向下映射到较低的高级存储磁盘类型,则此工具会将该虚拟机标记为“是”。 工具还建议您要么更改源磁盘大小以适应推荐的高级存储磁盘类型,要么在故障转移后更改目标磁盘类型。
存储类型:标准或高级。
为复制创建的 Asrseeddisk (托管磁盘):启用复制时创建的磁盘的名称。 它将数据及其快照存储在 Azure 中。
峰值读/写 IOPS (包括增长系数) :磁盘上的峰值工作负荷读/写 IOPS(默认为第 95 百分位),包括将来的增长系数(默认为 30%)。 虚拟机的读/写 IOPS 总数并非总是该虚拟机各个磁盘的读/写 IOPS 之和,因为在分析期间的每一分钟内,该虚拟机读/写 IOPS 峰值都是其各个磁盘的读/写 IOPS 之和的峰值。
以 Mbps 为单位的峰值数据变动量(包括增长系数) :磁盘上的峰值变动率(默认为第 95 百分位),包括将来的增长系数(默认为 30%)。 虚拟机的总数据流失量并非总是虚拟机各个磁盘的数据流失量之和,因为虚拟机的峰值数据流失量是该虚拟机在分析期间每分钟内各个磁盘流失量之和的峰值。
Azure 虚拟机大小:Azure 云服务虚拟机的最佳对应大小,用于此本地虚拟机。 映射基于本地虚拟机的内存、磁盘/核心/NIC 数以及读/写 IOPS。 建议始终使用与所有本地虚拟机特征匹配的最低 Azure 虚拟机大小。
磁盘数:虚拟机上的虚拟机磁盘 (VMDK) 总数。
磁盘大小 (GB):VM 所有磁盘的总安装大小。 该工具还会显示虚拟机中各个磁盘的磁盘大小。
核心数:虚拟机上的 CPU 核心数。
内存 (MB):虚拟机上的 RAM。
NIC:虚拟机上的 NIC 数。
启动类型:虚拟机的启动类型。 它可以是 BIOS 或 EFI。 目前,Azure Site Recovery 支持 Windows Server EFI 虚拟机(Windows Server 2012、2012 R2 和 2016),前提是启动盘中的分区数小于 4,引导扇区大小为 512 字节。 要保护 EFI 虚拟机,Azure Site Recovery 移动服务版本必须为 9.13 或更高版本。 EFI 虚拟机只支持故障转移功能。 不支持故障回复。
OS 类型:即虚拟机的 OS 类型。 它可以是 Windows、Linux 或其他操作系统,具体取决于创建虚拟机时从 VMware vSphere 中选择的模板。
不兼容的虚拟机
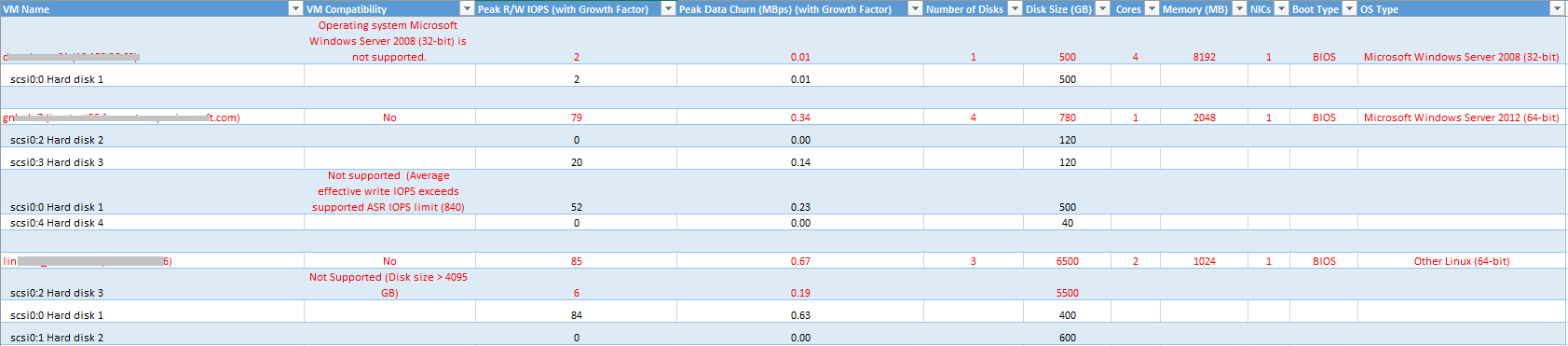
虚拟机名称:生成报表时在 VMListFile 中使用的虚拟机名称或 IP 地址。 此列还列出了附加到虚拟机的 VMDK。 为了区分使用重复名称或 IP 地址的 vCenter 虚拟机,这些名称包含了 ESXi 主机名称。 列出的 ESXi 主机是工具在分析期间发现虚拟机时放置虚拟机的主机。
虚拟机兼容性:指示给定的虚拟机无法与 Azure Site Recovery 兼容使用的原因。 针对虚拟机的每个不兼容磁盘,都说明了原因,并且根据已发布的存储限制,可能是以下情况之一:
数据磁盘大小错误或 OS 磁盘大小错误。 查看支持限制。
虚拟机总大小(复制 + TFO)超出了系统支持的存储帐户大小限制 (35 TB)。 当虚拟机中单个磁盘的性能特征超出了标准存储支持的最高 Azure 或 Site Recovery 限制时,通常会发生此类不兼容情况。 此类实例会将虚拟机推送到高级存储区域。 但高级存储帐户支持的最大大小为 35 TB,并且无法跨多个存储帐户保护单个受保护的虚拟机。 另请注意,当在受保护的虚拟机上执行测试性故障转移时,它会在正在进行复制的同一存储帐户中运行。 在这种情况下,请将磁盘大小设置为原来的两倍,以确保复制进程顺利推进,并使测试故障转移成功并行进行。
源 IOPS 超出了每个磁盘支持的存储 IOPS 限制,即 7500。
源 IOPS 超出了每台虚拟机支持的存储 IOPS 限制 80,000。
平均数据变动量超出了磁盘支持的 Site Recovery 数据变动量限制:平均 I/O 大小不能超过 20 MB/秒。
虚拟机中所有磁盘的峰值数据流失量超出了每台虚拟机支持的最大 Site Recovery 峰值数据流失量限制,即 54 MB/秒。
平均有效写入 IOPS 超出了磁盘支持的 Site Recovery IOPS 限制,即 840。
计算出的快照存储超出了支持的快照存储限制,即 10 TB。
每日总数据变动量超出了进程服务器支持的每日变动量限制,即 2 TB。
峰值读/写 IOPS (包括增长系数) :磁盘上的峰值工作负荷 IOPS(默认为第 95 百分位),包括将来的增长系数(默认为 30%)。 虚拟机的读/写 IOPS 总数并非总是该虚拟机各个磁盘的读/写 IOPS 之和,因为在分析期间的每一分钟内,该虚拟机读/写 IOPS 峰值都是其各个磁盘的读/写 IOPS 之和的峰值。
以 Mbps 为单位的峰值数据变动量(包括增长系数) :磁盘上的峰值变动率(默认为第 95 百分位),包括将来的增长系数(默认为 30%)。 虚拟机的总数据流失量并非总是虚拟机各个磁盘的数据流失量之和,因为虚拟机的峰值数据流失量是该虚拟机在分析期间每分钟内各个磁盘流失量之和的峰值。
磁盘数:虚拟机上 VMDK 的总数。
磁盘大小 (GB):VM 所有磁盘的总安装大小。 该工具还会显示虚拟机中各个磁盘的磁盘大小。
核心数:虚拟机上的 CPU 核心数。
内存 (MB):虚拟机上的 RAM 数量。
NIC:虚拟机上的 NIC 数。
启动类型:虚拟机的启动类型。 它可以是 BIOS 或 EFI。 目前,Azure Site Recovery 支持 Windows Server EFI 虚拟机(Windows Server 2012、2012 R2 和 2016),前提是启动盘中的分区数小于 4,引导扇区大小为 512 字节。 要保护 EFI 虚拟机,Azure Site Recovery 移动服务版本必须为 9.13 或更高版本。 EFI 虚拟机只支持故障转移功能。 不支持故障回复。
OS 类型:即虚拟机的 OS 类型。 它可以是 Windows、Linux 或其他操作系统,具体取决于创建虚拟机时从 VMware vSphere 中选择的模板。
Azure Site Recovery 限制
下表提供了 Azure Site Recovery 限制。 这些限制基于我们的测试,但无法涵盖所有可能的应用程序 I/O 组合。 实际结果可能因应用程序 I/O 组合而异。 为了获得最佳结果,即使在规划部署后,我们始终建议进行广泛的应用程序测试,通过故障转移测试来获得应用程序真实性能的全面视图。
| 用于复制的存储目标 | 平均源磁盘 I/O 大小 | 平均源磁盘数据变动量 | 每天的总源磁盘数据变动量 |
|---|---|---|---|
| 标准存储 | 8 KB | 2 MB/秒 | 每个磁盘 168 GB |
| 高级 P10 或 P15 磁盘 | 8 KB | 2 MB/秒 | 每个磁盘 168 GB |
| 高级 P10 或 P15 磁盘 | 16 KB | 4 MB/秒 | 每个磁盘 336 GB |
| 高级 P10 或 P15 磁盘 | 至少 32 KB | 8 MB/秒 | 每个磁盘 672 GB |
| 高级 P20、P30、P40 或 P50 磁盘 | 8 KB | 5 MB/秒 | 每个磁盘 421 GB |
| 高级 P20、P30、P40 或 P50 磁盘 | 至少 16 KB | 20 MB/秒 | 每个磁盘 1684 GB |
| 源数据变动量 | 最大限制 |
|---|---|
| 虚拟机上所有磁盘的峰值数据流失量 | 54 MB/秒 |
| 进程服务器支持的每日最大数据变动量 | 2兆字节 |
这是在假设存在 30% 的 I/O 重叠的情况下给出的平均数。 Site Recovery 能够根据重叠率、较大的写入大小和实际工作负载的 I/O 行为,处理更高的吞吐能力。 通常情况下,上述数字假设存在大约 5 分钟的积压。 也就是说,数据在上传后会在 5 分钟内进行处理并创建恢复点。