Synapse Apache Spark 诊断发射器扩展是一个库,通过该库,Apache Spark 应用程序能够将日志、事件日志和指标发送到一个或多个目标,包括 Azure Log Analytics、Azure 存储和 Azure 事件中心。
本教程介绍如何使用 Synapse Apache Spark 诊断发射器扩展将 Apache Spark 应用程序的日志、事件日志和指标发送到 Azure 存储帐户。
将日志和指标收集到存储帐户
步骤 1:创建存储帐户
若要将诊断日志和指标收集到存储帐户,可以使用现有的 Azure 存储帐户。 如果没有帐户,可以创建一个 Azure Blob 存储帐户,或创建一个用于 Azure Data Lake Storage Gen2 的存储帐户。
步骤 2:创建 Apache Spark 配置文件
创建一个 diagnostic-emitter-azure-storage-conf.txt 并将以下内容复制到文件中。 或下载 Apache Spark 池配置的示例模板文件。
spark.synapse.diagnostic.emitters MyDestination1
spark.synapse.diagnostic.emitter.MyDestination1.type AzureStorage
spark.synapse.diagnostic.emitter.MyDestination1.categories Log,EventLog,Metrics
spark.synapse.diagnostic.emitter.MyDestination1.uri https://<my-blob-storage>.blob.core.chinacloudapi.cn/<container-name>/<folder-name>
spark.synapse.diagnostic.emitter.MyDestination1.auth AccessKey
spark.synapse.diagnostic.emitter.MyDestination1.secret <storage-access-key>
在配置文件中填写以下参数:<my-blob-storage>、<container-name>、<folder-name>、<storage-access-key>。
有关参数的更多说明,可参阅 Azure 存储配置
步骤 3:将 Apache Spark 配置文件上传到 Synapse Studio 并在 Spark 池中使用它
- 打开 Apache Spark 配置页(“管理”->“Apache Spark 配置”)。
- 单击“导入”按钮,将 Apache Spark 配置文件上传到 Synapse Studio。
- 在 Synapse Studio 中导航到 Apache Spark 池(“管理”->“Apache Spark 池”)。
- 单击 Apache Spark 池右侧的“…”按钮并选择“Apache Spark 配置”。
- 可以在下拉菜单中选择刚上传的配置文件。
- 选择配置文件后,单击“应用”。
步骤 4:查看 Azure 存储帐户中的日志文件
将作业提交到配置的 Apache Spark 池后,你应该能够在目标存储帐户中查看日志和指标文件。
<workspaceName>.<sparkPoolName>.<livySessionId> 根据不同的应用程序,将日志置于相应的路径中。
所有日志文件都将采用 JSON 行格式(也称为换行符分隔的 JSON,简称 ndjson),非常便于数据处理。
“可用配置”
| 配置 | 说明 |
|---|---|
spark.synapse.diagnostic.emitters |
必需。 诊断发射器以逗号分隔的目标名称。 例如: MyDest1,MyDest2 |
spark.synapse.diagnostic.emitter.<destination>.type |
必需。 内置目标类型。 若要启用 Azure 存储目标,此字段中需要包含 AzureStorage。 |
spark.synapse.diagnostic.emitter.<destination>.categories |
可选。 以逗号分隔的选定日志类别。 可用的值包括 DriverLog、ExecutorLog、EventLog、Metrics。 如果未设置,则默认值为“所有”类别。 |
spark.synapse.diagnostic.emitter.<destination>.auth |
必需。 AccessKey 表示使用存储帐户访问密钥授权。 SAS 表示共享访问签名授权。 |
spark.synapse.diagnostic.emitter.<destination>.uri |
必需。 目标 Blob 容器文件夹 URI。 应匹配模式 https://<my-blob-storage>.blob.core.chinacloudapi.cn/<container-name>/<folder-name>。 |
spark.synapse.diagnostic.emitter.<destination>.secret |
可选。 机密(AccessKey 或 SAS)内容。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault |
如果未指定 .secret,则是必需的。 存储机密(AccessKey 或 SAS)的 Azure Key Vault 名称。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.secretName |
如果指定了 .secret.keyVault,则该参数是必需的。 存储机密(AccessKey 或 SAS)的 Azure Key Vault 机密名称。 |
spark.synapse.diagnostic.emitter.<destination>.secret.keyVault.linkedService |
可选。 Azure Key Vault 链接服务名称。 在 Synapse 管道中启用时,必须从 AKV 中获取机密。 (请确保 MSI 对 AKV 具有读取权限)。 |
spark.synapse.diagnostic.emitter.<destination>.filter.eventName.match |
可选。 以逗号分隔的 Spark 事件名称,你可指定要收集的事件。 例如: SparkListenerApplicationStart,SparkListenerApplicationEnd |
spark.synapse.diagnostic.emitter.<destination>.filter.loggerName.match |
可选。 以逗号分隔的 log4j 记录器名称,你可指定要收集的日志。 例如: org.apache.spark.SparkContext,org.example.Logger |
spark.synapse.diagnostic.emitter.<destination>.filter.metricName.match |
可选。 以逗号分隔的 Spark 指标名称后缀,你可指定要收集的指标。 例如:jvm.heap.used |
日志数据示例
下面是 JSON 格式的示例日志记录:
{
"timestamp": "2021-01-02T12:34:56.789Z",
"category": "Log|EventLog|Metrics",
"workspaceName": "<my-workspace-name>",
"sparkPool": "<spark-pool-name>",
"livyId": "<livy-session-id>",
"applicationId": "<application-id>",
"applicationName": "<application-name>",
"executorId": "<driver-or-executor-id>",
"properties": {
// The message properties of logs, events and metrics.
"timestamp": "2021-01-02T12:34:56.789Z",
"message": "Registering signal handler for TERM",
"logger_name": "org.apache.spark.util.SignalUtils",
"level": "INFO",
"thread_name": "main"
// ...
}
}
启用了数据外泄防护功能的 Synapse 工作区
Azure Synapse Analytics 工作区支持对工作区启用数据外泄保护。 借助外泄防护功能,日志和指标不能直接发送到目标终结点。 在这种情况下,你可以为不同的目标终结点创建相应的托管专用终结点或创建 IP 防火墙规则。
导航到“Synapse Studio”>“管理”>“托管专用终结点”,单击“新建”按钮,选择“Azure Blob 存储”或“Azure Data Lake Storage Gen2”,然后选择“继续”。
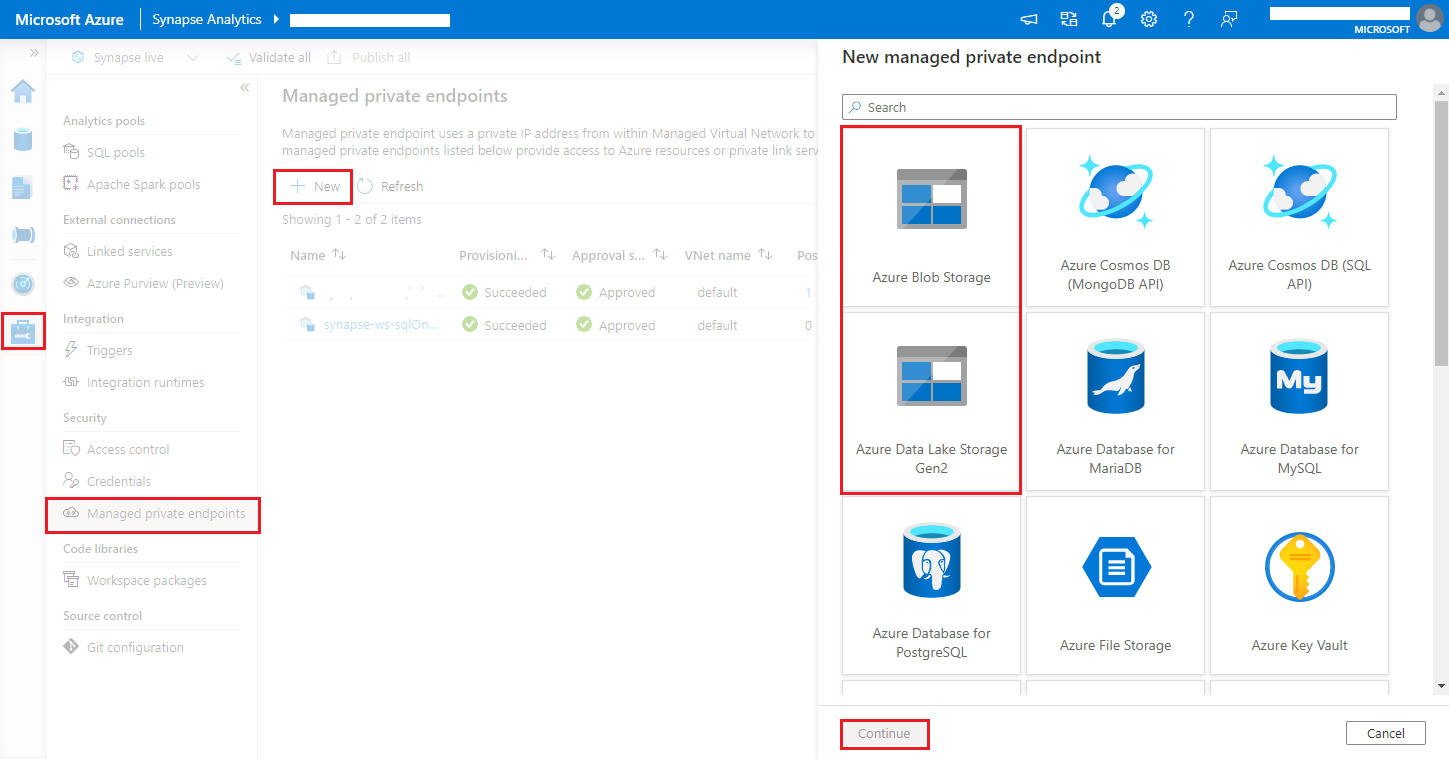
注意
我们可以同时支持 Azure Blob 存储和 Azure Data Lake Storage Gen2。 但是,我们无法分析“abfss://”格式。 Azure Data Lake Storage Gen2 终结点的格式应设置为 Blob URL:
https://<my-blob-storage>.blob.core.chinacloudapi.cn/<container-name>/<folder-name>在“存储帐户名称”中选择你的 Azure 存储帐户,然后单击“创建”按钮 。
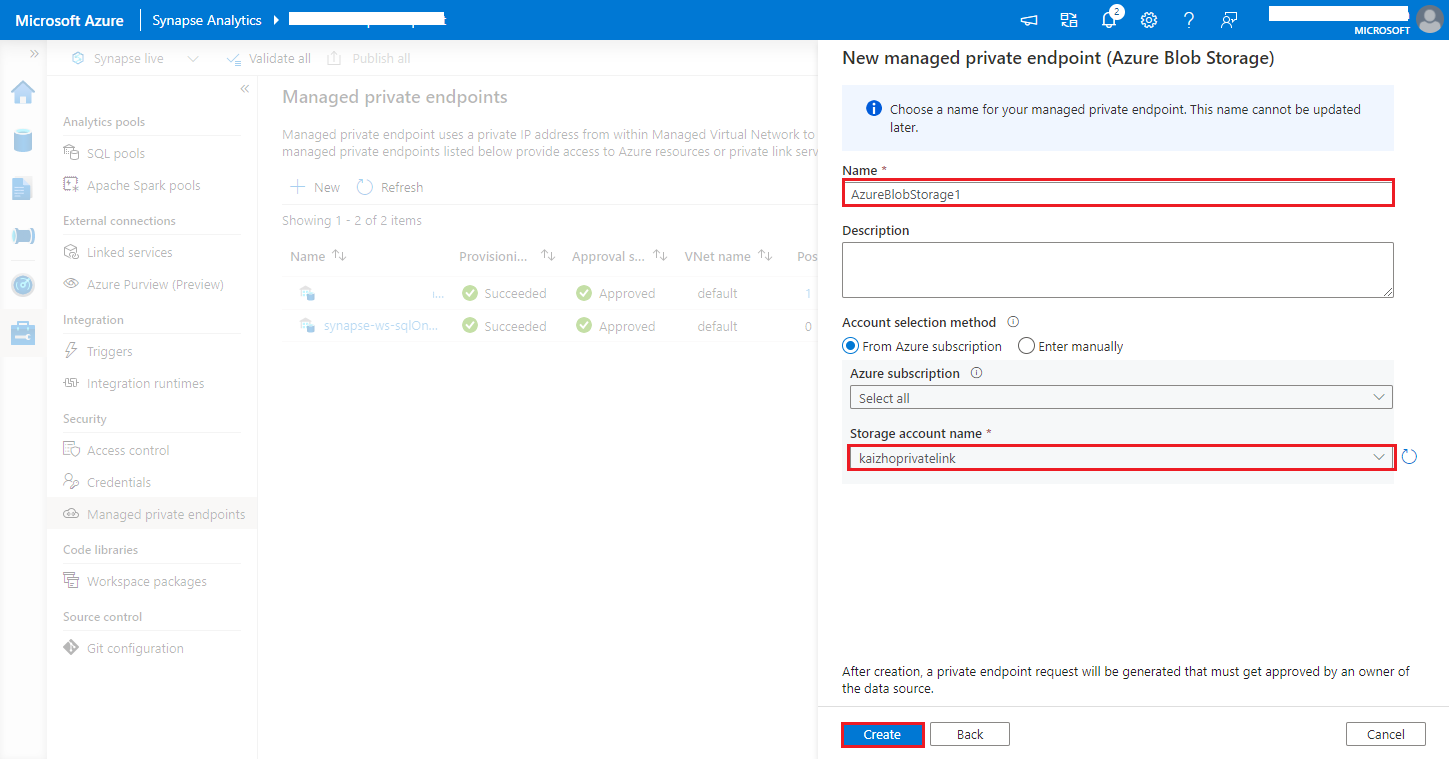
预配专用终结点期间请耐心等待。
在 Azure 门户中导航到你的存储帐户,在“网络”>“专用终结点连接”页面上,选择预配的连接,然后选择“批准”。