Apache Spark 诊断发出器扩展是一个库,它允许 Spark 应用程序将日志、事件日志和指标发送到目标,例如Azure 存储帐户、Azure Log Analytics和Azure 存储。
本教程介绍如何创建所需的Azure资源,并使用证书和服务主体配置 Spark 应用程序,以使用 Apache Spark 诊断发射器扩展向Azure 存储帐户发出日志、事件日志和指标。
先决条件
- 一个 Azure 订阅。 在开始之前,还可以 创建一个试用帐户 。
- Synapse Analytics 工作区。
- Azure 存储帐户。
- Azure 密钥保管库
- 应用注册
注意
若要完成本教程的步骤,需要有权访问为其分配有“所有者”角色的资源组。
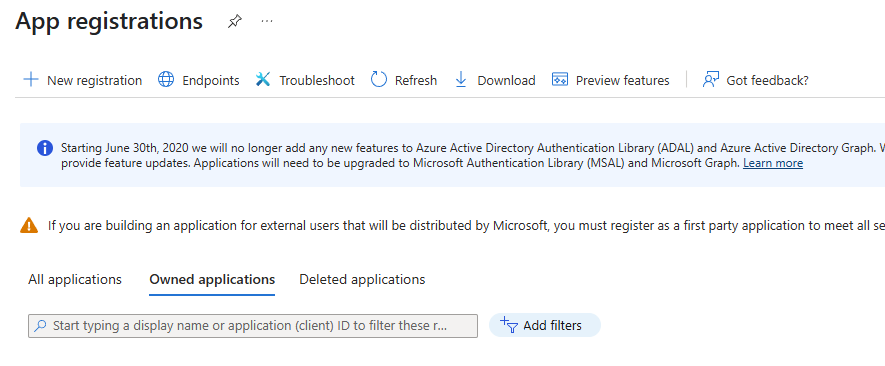
第 1 步。 注册应用程序
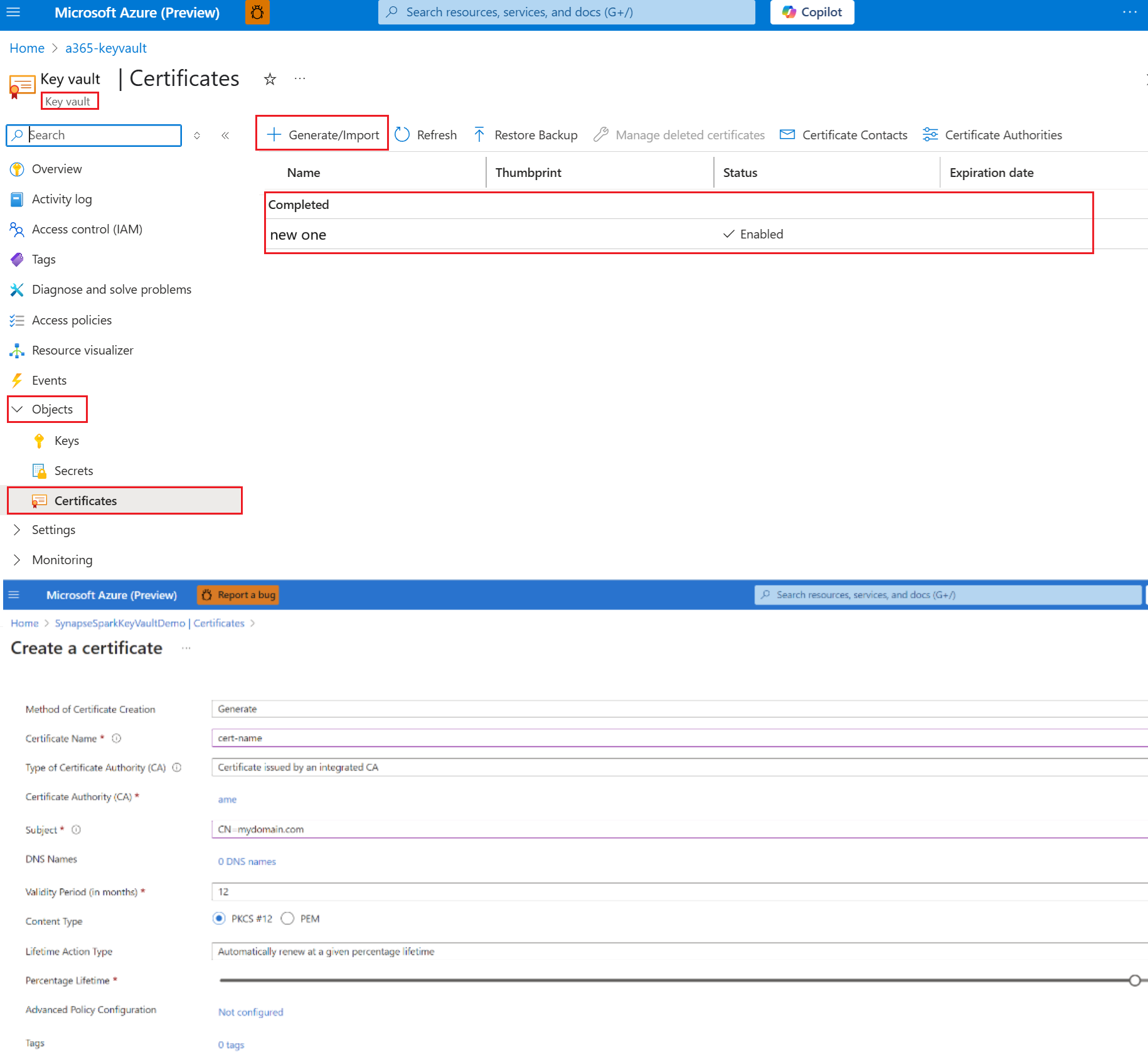
步骤 2. 在 密钥保管库 中生成证书
导航至密钥保管库 (密钥保管库)。
展开 对象,然后选择 “证书”。
单击“生成/导入”。
第 3 步: 信任应用程序中的证书
转到在步骤 1 >管理>清单中创建的应用。
将证书详细信息追加到清单文件以建立信任。
"trustedCertificateSubjects": [ { "authorityId": "00000000-0000-0000-0000-000000000001", "subjectName": "Your-Subject-of-Certificate", "revokedCertificateIdentifiers": [] } ]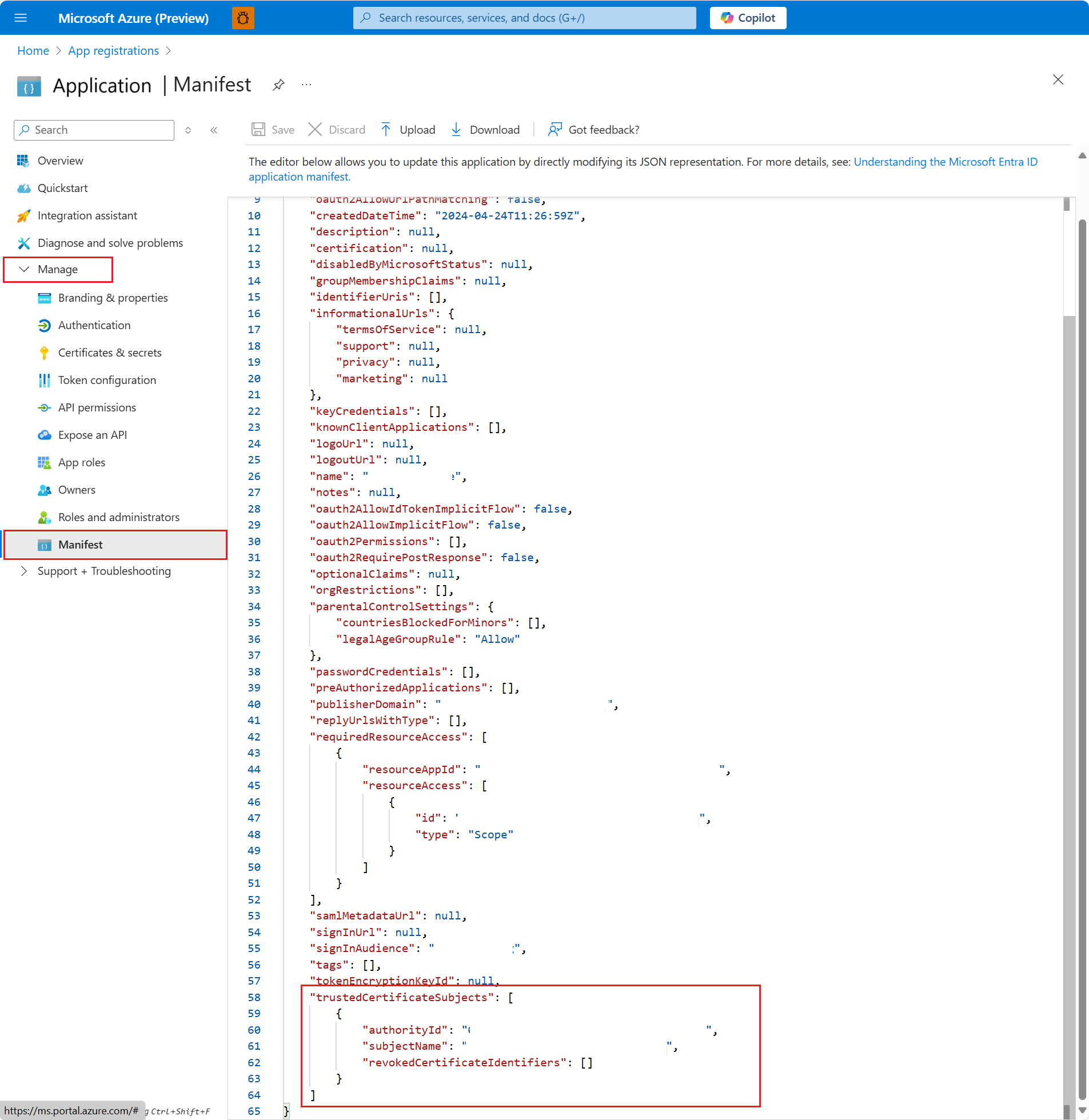
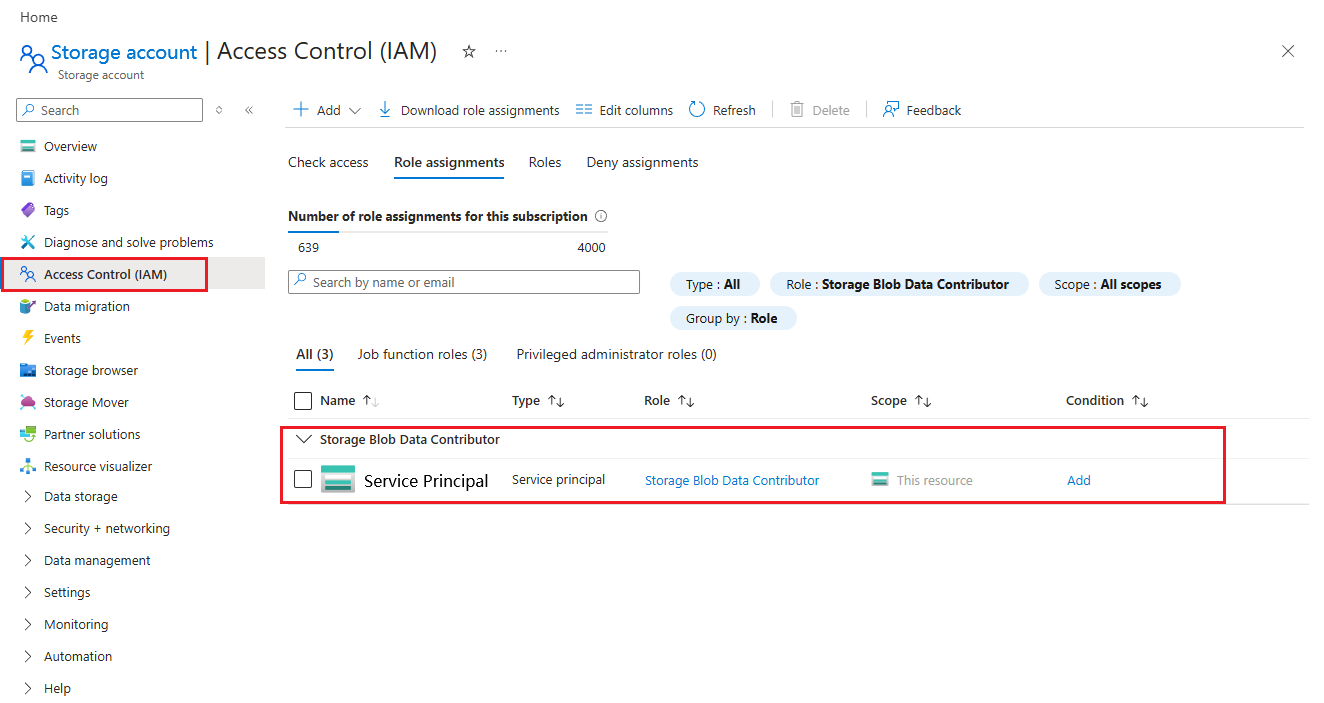
步骤 4. 分配存储 Blob 数据参与者角色
在Azure 存储帐户中,导航到访问控制(IAM)。
将 存储 Blob 数据贡献者 角色分配给应用程序(服务主体)。
步骤 5. 在 Synapse 中创建链接服务
在 Synapse Analytics 工作区中,转到 “管理>链接服务”。
在 Synapse 中创建新的 链接服务 以连接到 密钥保管库。
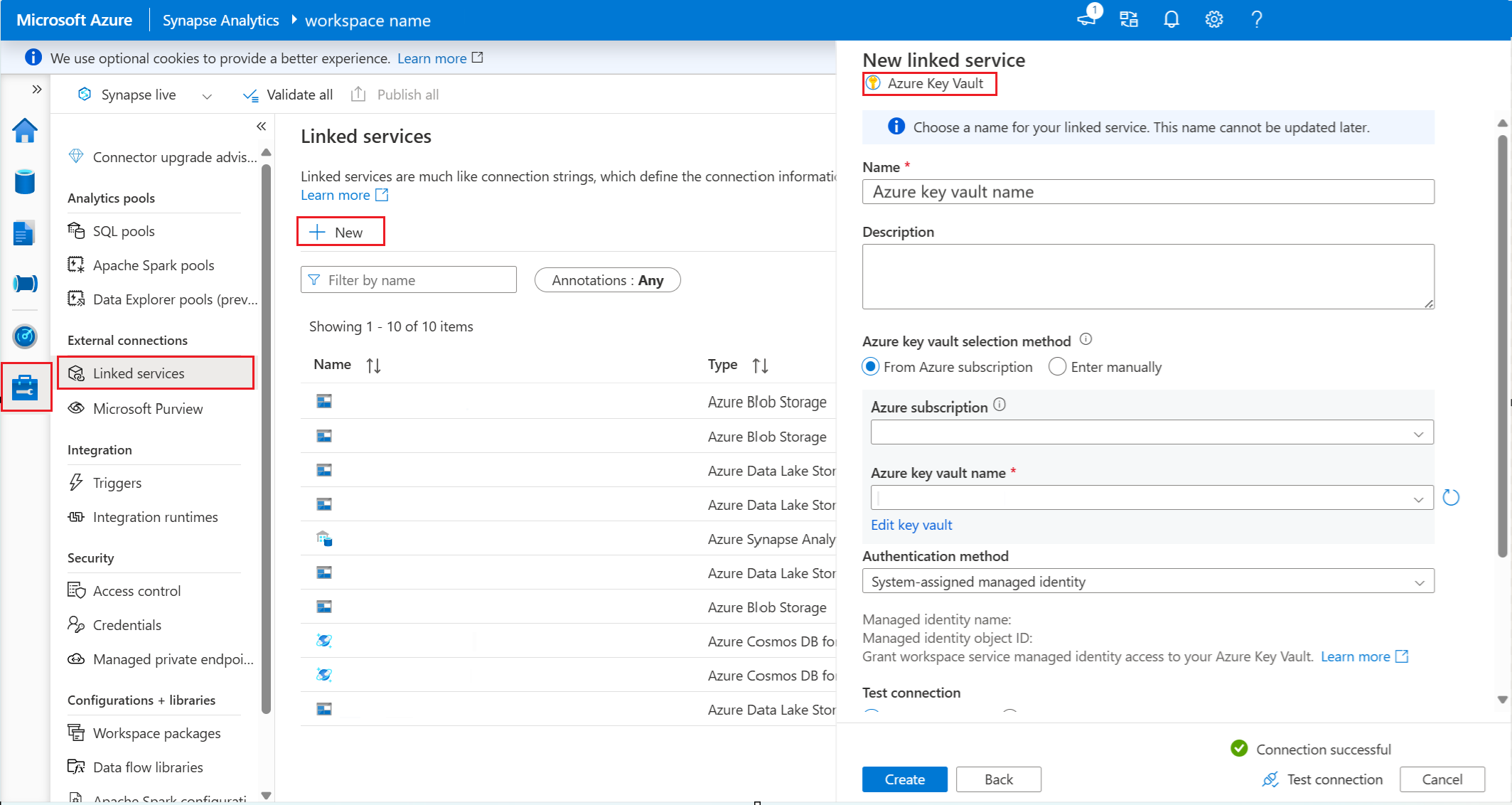
步骤 6。 在 密钥保管库 中为链接服务分配读取者角色
获取链接服务的工作区托管标识 ID。 链接服务的托管标识名称和对象 ID 位于“编辑链接服务”下。
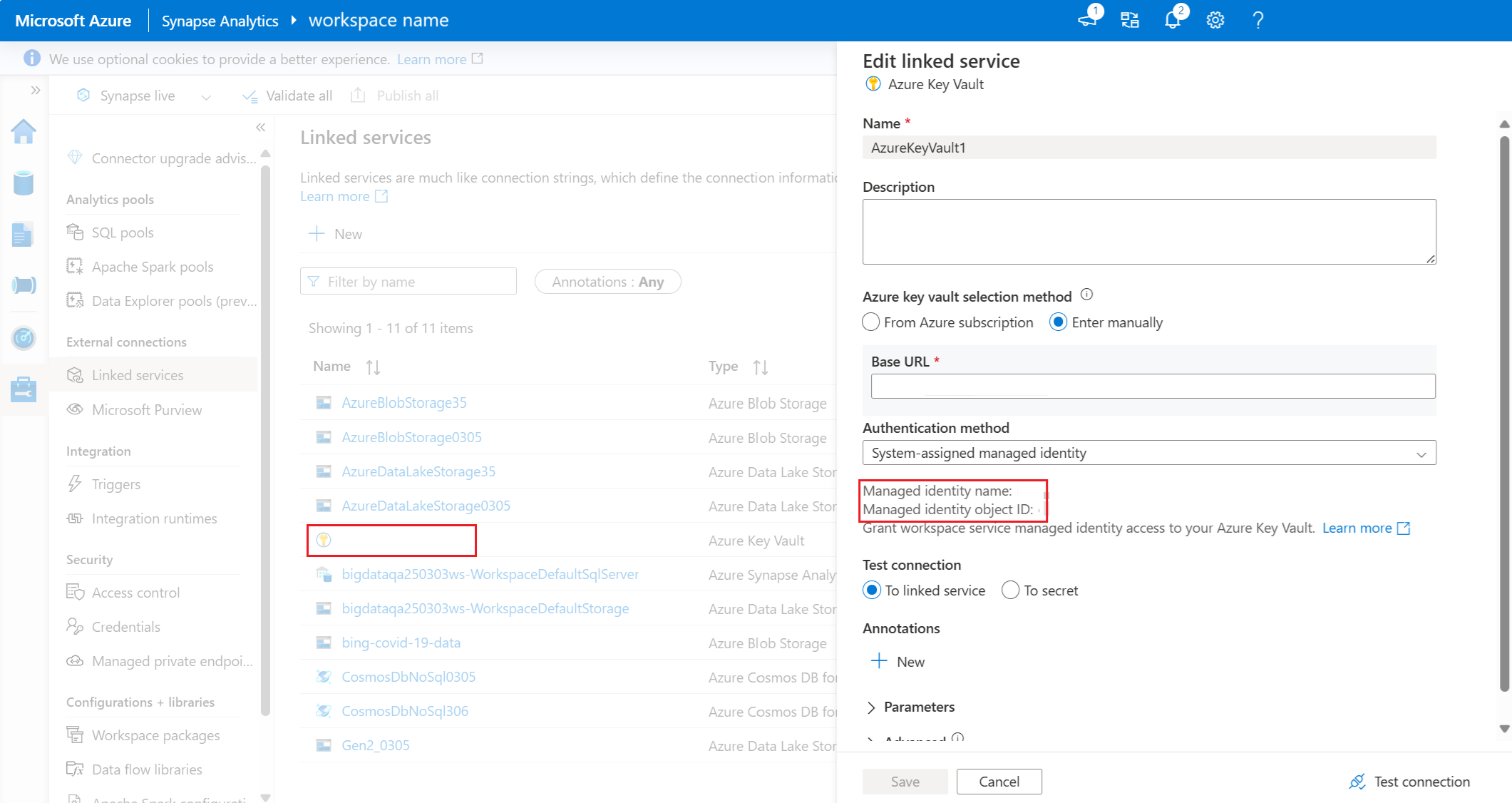
在 密钥保管库 中,为链接服务分配密钥保管库证书用户角色。
步骤 7. 配置链接服务
收集以下值并添加到 Apache Spark 配置。
- <EMITTER_NAME>:发射器的名称。
- < >CERTIFICATE_NAME:在密钥保管库中生成的证书名称。
- <LINKED_SERVICE_NAME>:Azure Key Vault 链接服务名称。
-
<STORAGE_URI>:Blob 存储目标路径(例如,
https://accountname.blob.core.chinacloudapi.cn/containername)。 - <SERVICE_PRINCIPAL_TENANT_ID>:服务主体租户 ID,可以在App 注册中的 >你的应用名称> 概述>目录(租户)ID查看。
- < >SERVICE_PRINCIPAL_CLIENT_ID:服务主体客户端 ID,可以在注册>应用名称>概述>应用程序(客户端)ID 中找到它
"spark.synapse.diagnostic.emitters": <EMITTER_NAME>,
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type": "AzureStorage",
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories": "DriverLog,ExecutorLog,EventLog,Metrics",
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.uri": "<STORAGE_URI>",
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.auth": "ServicePrincipalCert",
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName": <CERTIFICATE_NAME>",
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService": <LINKED_SERVICE_NAME>,
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId": <SERVICE_PRINCIPAL_TENANT_ID>,
"spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId": <SERVICE_PRINCIPAL_CLIENT_ID>
步骤 8。 提交 Apache Spark 应用程序并查看日志和指标
可以使用 Apache Log4j 库编写自定义日志。
Scala 的示例:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
PySpark 的示例:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")