Azure Synapse Studio 团队在 Microsoft Spark 实用工具 (mssparkutils) 包中构建了两个新的装载/卸载 API。 你可以用这些API将远程存储(Azure Blob Storage、Azure Data Lake Storage Gen2或Azure File Share)附加到所有工作节点(驱动节点和工作节点)。 存储就位后,可以使用本地文件 API 访问数据,如同数据存储在本地文件系统中一样。 有关详细信息,请参阅 Microsoft Spark 实用工具简介。
本文演示如何在工作区中使用装载/卸载 API。 学习内容:
- 如何挂载Data Lake Storage Gen2、Blob Storage或Azure文件共享。
- 如何通过本地文件系统 API 访问装入点下的文件。
- 如何使用
mssparkutils fsAPI 访问装入点下的文件。 - 如何使用 Spark 读取 API 访问装入点下的文件。
- 如何卸载装入点。
装载存储
此部分说明如何逐步装载 Data Lake Storage Gen2,以此作为示例。 装载 Blob 存储和 Azure 文件共享的工作方式类似。
该示例假设你具有一个名为 storegen2 的 Data Lake Storage Gen2 帐户。 该帐户有一个名为 mycontainer 的容器,你要将该容器装载到 Spark 池中的 /test。
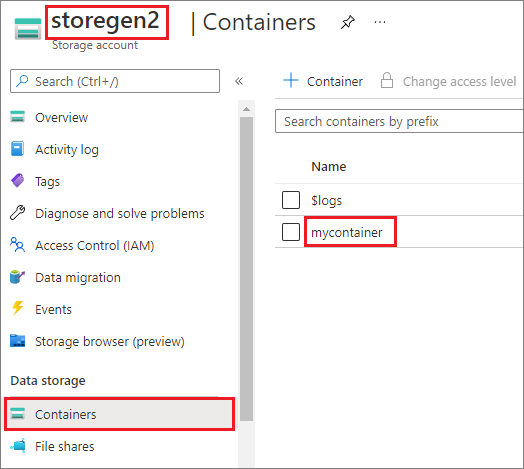
若要装载名为 mycontainer 的容器,mssparkutils 首先需要检查你是否具有访问该容器的权限。 目前,Azure Synapse Analytics 对触发器装载操作支持三种身份验证方法:linkedService、accountKey 和 sastoken。
使用链接服务进行装载(建议)
建议通过链接服务进行触发器装载。 此方法可避免安全泄漏,因为 mssparkutils 不会存储任何机密或身份验证值本身。 相反,mssparkutils 始终从链接服务提取身份验证值,以便从远程存储请求 Blob 数据。
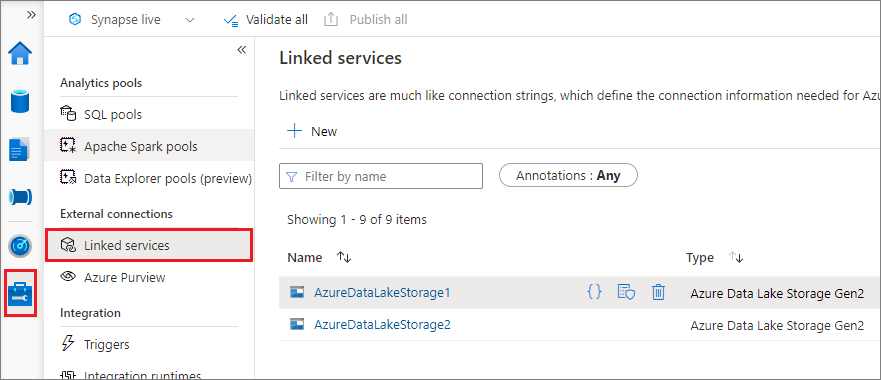
可以为 Data Lake Storage Gen2 或 Blob 存储创建链接服务。 目前,Azure Synapse Analytics 在创建链接服务时支持两种身份验证方法:
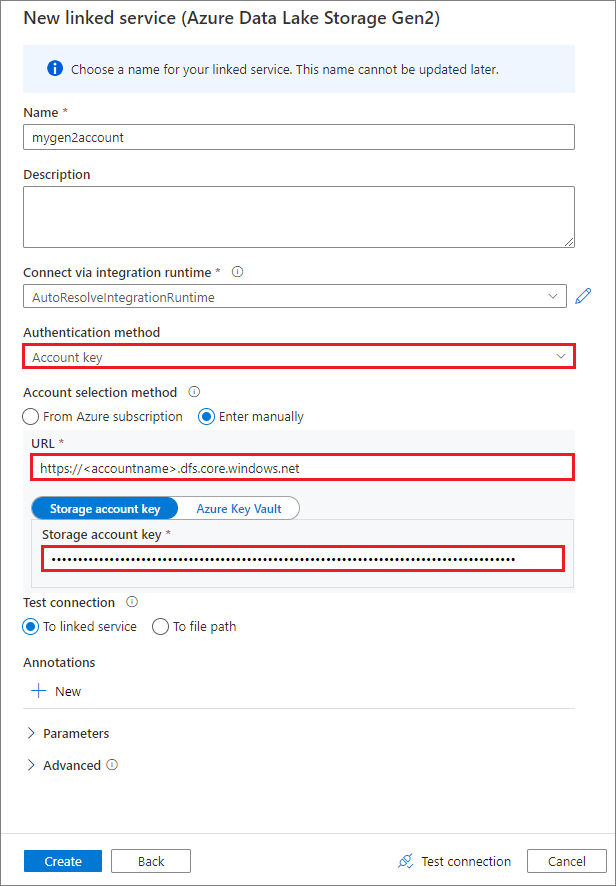
使用帐户密钥创建链接服务
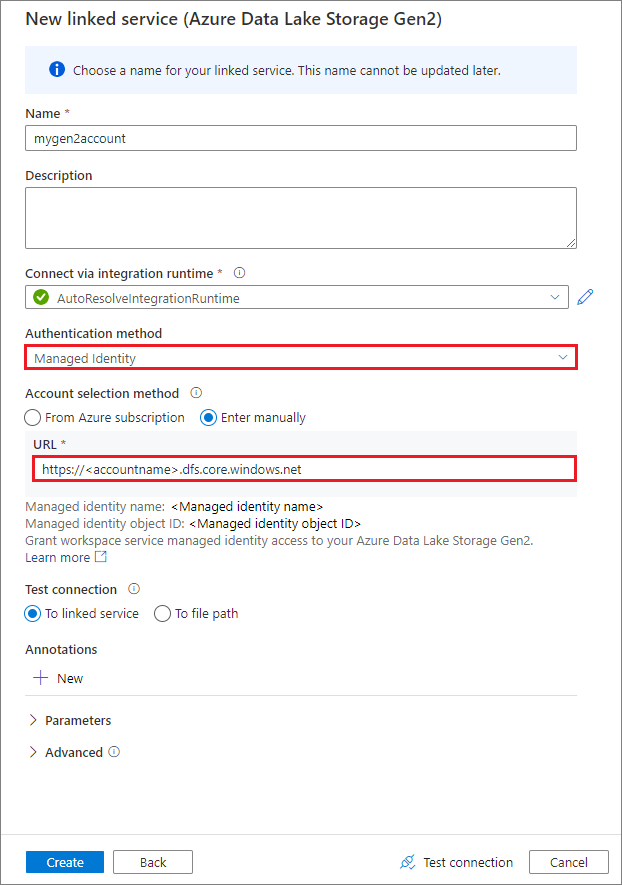
使用系统分配的托管标识创建链接服务
重要
- 如果上面创建的到 Azure Data Lake Storage Gen2 的链接服务使用托管专用终结点(具有 dfs URI),则需要使用 Azure Blob 存储选项创建另一个辅助托管专用终结点(具有 blob URI),以确保内部 adlfs 代码可以使用 BlobServiceClient 接口进行连接。
- 如果未正确配置辅助托管专用终结点,我们将看到类似于 ServiceRequestError: 无法连接到主机 [storageaccountname].blob.core.chinacloudapi.cn:443 ssl:True [名称或服务未知] 的错误消息
注意
如果使用托管标识作为身份验证方法来创建链接服务,请确保工作区 MSI 文件具有已装载容器的存储 Blob 数据参与者角色。
成功创建链接服务后,可以使用以下 Python 代码将容器轻松装载到 Spark 池:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.chinacloudapi.cn",
"/test",
{"linkedService": "mygen2account"}
)
注意
如果 mssparkutils 不可用,可能需要将它导入:
from notebookutils import mssparkutils
无论使用哪种身份验证方法,都不建议装载根文件夹。
装载参数:
- fileCacheTimeout:默认情况下,Blob 将在本地临时文件夹中缓存 120 秒。 在此期间,BlobFuse 不会检查文件是否为最新状态。 可以将参数设置为更改默认超时时间。 当多个客户端同时修改文件时,为了避免本地文件与远程文件之间的不一致,我们建议缩短缓存时间,甚至将其更改为 0,并始终从服务器获取最新文件。
- timeout:默认情况下,装载操作超时为 120 秒。 可以将参数设置为更改默认超时时间。 当执行程序过多或装载超时时,建议增加值。
- scope:范围参数用于指定装载的范围。 默认值为“job”。如果范围设置为“job”,则装载仅对当前群集可见。 如果范围设置为“workspace”,则装载对当前工作区中的所有笔记本都可见,如果不存在装入点,则会自动创建。 将相同的参数添加到卸载 API 以卸载装入点。 工作区级别装载仅支持链接服务身份验证。
可以使用如下所示的这些参数:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.chinacloudapi.cn",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
通过共享访问签名令牌或帐户密钥进行装载
除了通过链接服务进行装载外,mssparkutils 还支持显式传递帐户密钥或共享访问签名 (SAS) 令牌作为参数来装载目标。
出于安全原因,我们建议尽可能使用托管标识和Microsoft Entra身份验证,而不是帐户密钥或 SAS 令牌。 如果必须使用帐户密钥,请将它们存储在Azure Key Vault中(如以下示例屏幕截图所示)。 随后可以使用 mssparkutil.credentials.getSecret API 检索它们。 有关详细信息,请参阅 授权访问 Azure 存储中的数据。
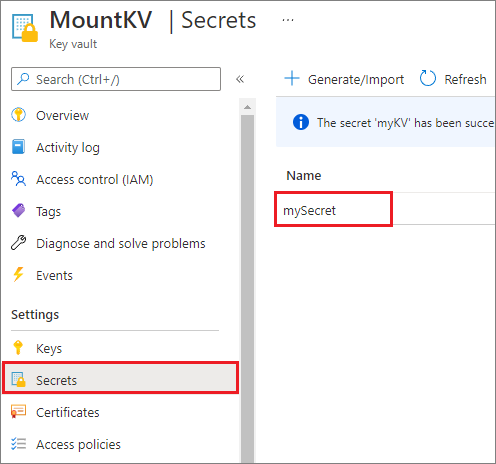
下面是示例代码:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.chinacloudapi.cn",
"/test",
{"accountKey":accountKey}
)
注意
出于安全原因,请勿在代码中存储凭据。
使用 mssparkutils fs API 访问装入点下的文件
装载操作的主要目的是让客户能够使用本地文件系统 API 访问远程存储帐户中存储的数据。 你也可以使用 mssparkutils fs API 以装载路径作为参数来访问数据。 此处使用的路径格式略有不同。
假设你已使用装载 API 将 Data Lake Storage Gen2 容器 mycontainer 装载到 /test。 通过本地文件系统 API 访问数据时:
- 对于 Spark 3.3 及更低版本,路径格式为
/synfs/{jobId}/test/{filename}。 - 对于 Spark 3.4 及更高版本,路径格式为
/synfs/notebook/{jobId}/test/{filename}。
建议使用 mssparkutils.fs.getMountPath() 来获取准确的路径:
path = mssparkutils.fs.getMountPath("/test")
注意
使用 workspace 范围装载存储时,装载点将在 /synfs/workspace 文件夹下创建。 需要使用 mssparkutils.fs.getMountPath("/test", "workspace") 来获取准确路径。
当你要使用 mssparkutils fs API 访问数据时,路径格式如下所示:synfs:/notebook/{jobId}/test/{filename}。 在本例中,你可以看到 synfs 用作架构,而不是装载路径的一部分。 当然,也可以使用本地文件系统架构来访问数据。 例如 file:/synfs/notebook/{jobId}/test/{filename}。
以下三个示例演示如何使用 mssparkutils fs 通过装入点路径访问文件。
列出目录:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')读取文件内容:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')创建目录:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
使用 Spark 读取 API 访问装入点下的文件
可以提供参数以通过 Spark 读取 API 访问数据。 此处的路径格式与使用 mssparkutils fs API 时相同。
从装载的 Data Lake Storage Gen2 存储帐户读取文件
以下示例假设已装载 Data Lake Storage Gen2 存储帐户,然后使用装载路径读取文件:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
注意
使用链接服务装载存储时,在使用 synfs 架构访问数据之前,应始终显式设置 Spark 链接服务配置。 有关详细信息,请参阅 ADLS Gen2 存储与链接服务。
从装载的 Blob 存储帐户中读取文件
如果装载了 Blob 存储帐户并且要使用 mssparkutils 或 Spark API 访问该帐户,则需要在使用装载 API 尝试装载容器之前通过 Spark 配置显式配置 SAS 令牌:
若要在进行触发器装载后使用
mssparkutils或 Spark API 访问 Blob 存储帐户,请更新 Spark 配置,如以下代码示例所示。 如果在装载后只想使用本地文件 API 访问 Spark 配置,则可以绕过此步骤。blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.chinacloudapi.cn', blob_sas_token)创建链接服务
myblobstorageaccount,并使用该链接服务装载 Blob 存储帐户:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.chinacloudapi.cn", "/test", Map("linkedService" -> "myblobstorageaccount") )装载 Blob 存储容器,然后通过本地文件 API 使用装载路径读取文件:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())通过 Spark 读取 API 从装载的 Blob 存储容器读取数据:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
卸载装入点
使用以下代码可卸载装入点(在此示例中为 /test):
mssparkutils.fs.unmount("/test")
已知限制
- 卸载机制不是自动进行的。 应用程序运行完成后,若要卸载装入点以释放磁盘空间,需要在代码中显式调用卸载 API。 否则,应用程序运行完成后,装入点仍会存在于节点中。