了解如何使用 Azure Synapse Analytics 中的无服务器 Apache Spark 池,使用 Pandas 将数据读取/写入到 Azure Data Lake Storage Gen2 (ADLS)。 本教程中的示例演示了如何在 Synapse、Excel 和 Parquet 文件中通过 Pandas 读取 csv 数据。
本教程介绍以下操作:
- 使用 Pandas 在 Spark 会话中读取/写入 ADLS Gen2 数据。
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
先决条件
Azure Synapse Analytics 工作区,其中 Azure Data Lake Storage Gen2 存储帐户配置为默认存储(或主存储)。 你需要成为所使用的 Data Lake Storage Gen2 文件系统的存储 Blob 数据参与者。
Azure Synapse Analytics 工作区中的无服务器 Apache Spark 池。 有关详细信息,请参阅在 Azure Synapse 中创建 Spark 池。
配置辅助 Azure Data Lake Storage Gen2 帐户(此帐户不是 Synapse 工作区的默认选项)。 你需要成为所使用的 Data Lake Storage Gen2 文件系统的存储 Blob 数据参与者。
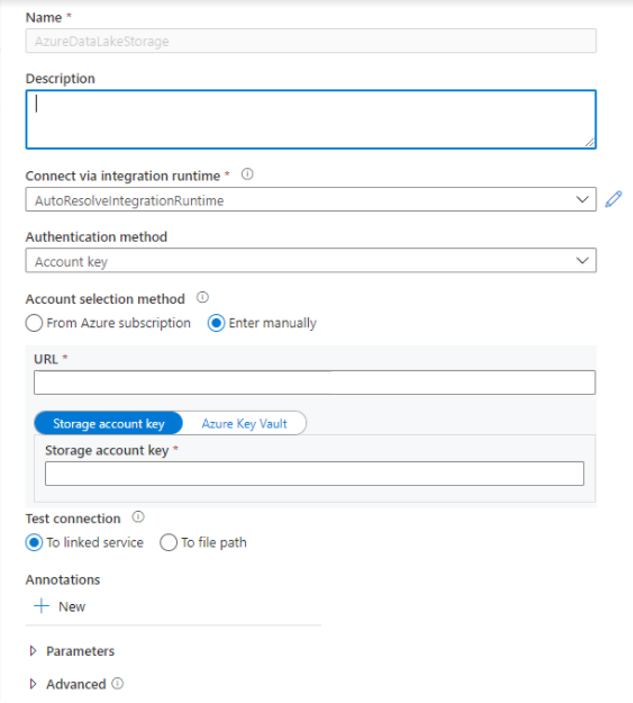
在 Azure Synapse Analytics 中创建链接服务。链接服务定义了您的服务连接信息。 在本教程中,你将添加 Azure Synapse Analytics 和 Azure Data Lake Storage Gen2 链接服务。
- 打开 Azure Synapse Studio 并选择“管理”选项卡。
- 在“外部连接”下,选择“链接服务”。
- 若要添加链接服务,请选择“新建”。
- 从列表中选择“Azure Data Lake Storage Gen2”磁贴,然后选择“继续”。
- 输入你的身份验证凭据。 帐户密钥、服务主体(SP)、凭据和托管服务标识(MSI)目前支持身份验证类型。 确保为 SP 和 MSI 的存储分配了“存储 Blob 数据参与者”角色,然后再选择它进行身份验证。 测试连接以验证你的凭据是否正确。 选择“创建”。
重要
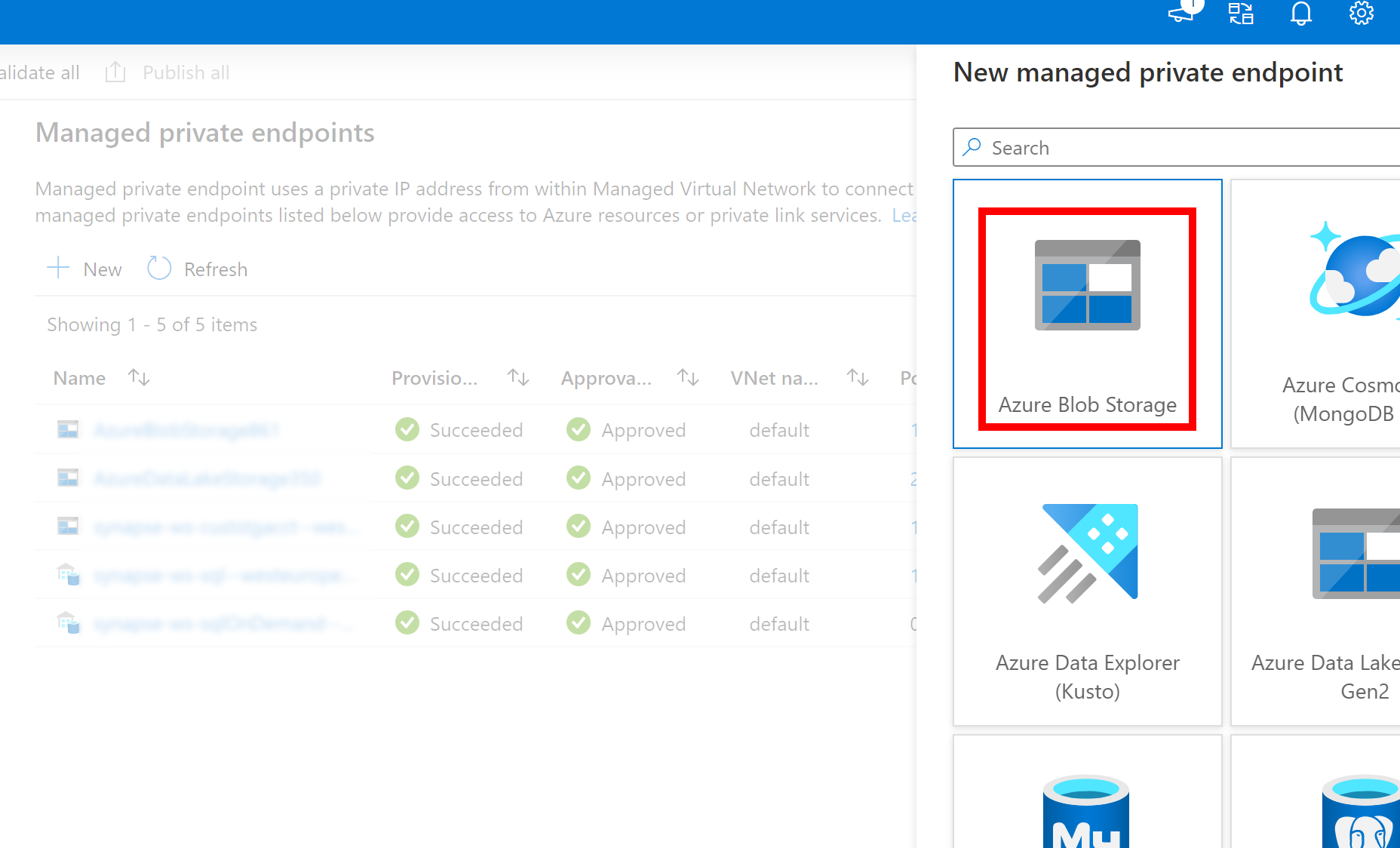
- 如果上面创建的到 Azure Data Lake Storage Gen2 的链接服务使用托管专用终结点(具有 dfs URI),则需要使用 Azure Blob 存储选项创建另一个辅助托管专用终结点(具有 blob URI),以确保内部 adlfs 代码可以使用 BlobServiceClient 接口进行连接。
- 如果未正确配置辅助托管专用终结点,我们将看到类似于“ServiceRequestError: 无法连接到主机 [storageaccountname].blob.core.chinacloudapi.cn:443 ssl:True [名称或服务未知]”的错误消息
注释
- Azure Synapse Analytics 中的 Python 3.8 和 Spark3 无服务器 Apache Spark 池支持 Pandas 功能。
- 支持以下版本:pandas 1.2.3、fsspec 2021.10.0、adlfs 0.7.7
- 能够支持 Azure Data Lake Storage Gen2 URI (abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/file_path)。
登录到 Azure 门户
登录到 Azure 门户。
将数据读取/写入到 Synapse 工作区的默认 ADLS 存储帐户
Pandas 可以通过指定默认 ADLS Gen 2 存储中的文件路径来直接读取/写入 ADLS 数据。
运行以下代码。
注释
在运行此脚本之前,请更新其中的文件 URL。
#Read data file from URI of default Azure Data Lake Storage Gen2
import pandas
#read csv file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/file_path')
print(df)
#write csv file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/file_path')
使用辅助 ADLS 帐户读取/写入数据
Pandas 可以读取/写入次级 ADLS 帐户数据。
- 使用链接服务(带有身份验证选项 - 存储帐户密钥、服务主体、管理服务标识和凭据)。
- 使用存储选项直接传递客户端 ID 和机密、SAS 密钥、存储帐户密钥和连接字符串。
运行以下代码。
注释
在运行之前,请更新此脚本中的文件 URL 和链接服务名称。
#Read data file from URI of secondary Azure Data Lake Storage Gen2
import pandas
#read data file
df = pandas.read_csv('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/ file_path', storage_options = {'linked_service' : 'linked_service_name'})
print(df)
#write data file
data = pandas.DataFrame({'Name':['A', 'B', 'C', 'D'], 'ID':[20, 21, 19, 18]})
data.to_csv('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/file_path', storage_options = {'linked_service' : 'linked_service_name'})
读取/写入 parquet 文件的示例
运行以下代码。
注释
在运行此脚本之前,请更新其中的文件 URL。
import pandas
#read parquet file
df = pandas.read_parquet('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/ parquet_file_path')
print(df)
#write parquet file
df.to_parquet('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/ parquet_file_path')
读取/写入 Microsoft Excel 文件的示例
运行以下代码。
注释
在运行此脚本之前,请更新其中的文件 URL。
import pandas
#read excel file
df = pandas.read_excel('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/ excel_file_path')
print(df)
#write excel file
df.to_excel('abfs[s]://file_system_name@account_name.dfs.core.chinacloudapi.cn/excel_file_path')